多对多关系
多对多关系
两个表之间的多对多关系是通过添加一个关联表来实现的,它有两个外键——一个来自每个表的主键。此外,映射到这两个表的类具有一个属性,该属性具有其他关联表的对象集合,作为relationship() 函数的次要属性。
为此,我们将创建一个 SQLite 数据库 (mycollege.db),其中包含两个表 – 部门和员工。在这里,我们假设一个员工属于多个部门,一个部门有多个员工。这构成了多对多的关系。
映射到部门和员工表的员工和部门类的定义如下 –
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///mycollege.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key = True)
name = Column(String)
employees = relationship('Employee', secondary = 'link')
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key = True)
name = Column(String)
departments = relationship(Department,secondary='link')
我们现在定义一个 Link 类。它链接到链接表并包含分别引用部门和员工表的主键的department_id 和employee_id 属性。
class Link(Base):
__tablename__ = 'link'
department_id = Column(
Integer,
ForeignKey('department.id'),
primary_key = True)
employee_id = Column(
Integer,
ForeignKey('employee.id'),
primary_key = True)
在这里,我们必须注意,Department 类具有与 Employee 类相关的雇员属性。关系函数的次要属性被分配一个链接作为其值。
类似地,Employee 类具有与Department 类相关的departments 属性。关系函数的次要属性被分配一个链接作为其值。
所有这三个表都是在执行以下语句时创建的 –
Base.metadata.create_all(engine)
Python 控制台发出以下 CREATE TABLE 查询 –
CREATE TABLE department ( id INTEGER NOT NULL, name VARCHAR, PRIMARY KEY (id) ) CREATE TABLE employee ( id INTEGER NOT NULL, name VARCHAR, PRIMARY KEY (id) ) CREATE TABLE link ( department_id INTEGER NOT NULL, employee_id INTEGER NOT NULL, PRIMARY KEY (department_id, employee_id), FOREIGN KEY(department_id) REFERENCES department (id), FOREIGN KEY(employee_id) REFERENCES employee (id) )
我们可以通过使用 SQLiteStudio 打开 mycollege.db 来检查这一点,如下面的屏幕截图所示 –
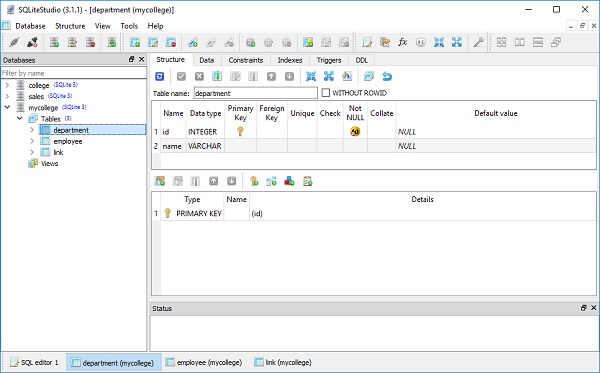
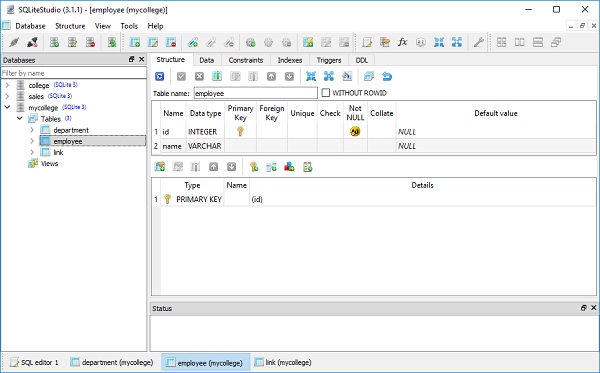
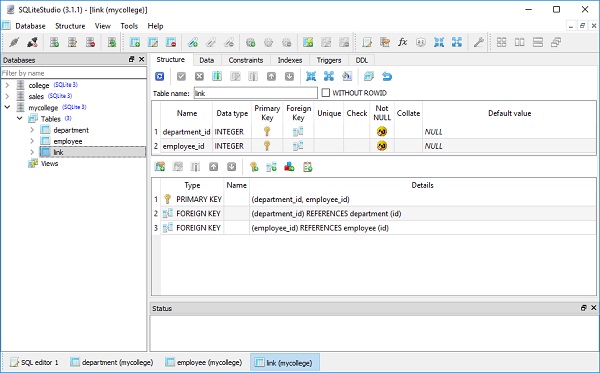
接下来我们创建 Department 类的三个对象和 Employee 类的三个对象,如下所示 –
d1 = Department(name = "Accounts") d2 = Department(name = "Sales") d3 = Department(name = "Marketing") e1 = Employee(name = "John") e2 = Employee(name = "Tony") e3 = Employee(name = "Graham")
每个表都有一个带有 append() 方法的集合属性。我们可以将 Employee 对象添加到 Department 对象的 Employees 集合中。同样,我们可以将 Department 对象添加到 Employee 对象的部门集合属性中。
e1.departments.append(d1) e2.departments.append(d3) d1.employees.append(e3) d2.employees.append(e2) d3.employees.append(e1) e3.departments.append(d2)
我们现在要做的就是设置一个会话对象,向其中添加所有对象并提交更改,如下所示 –
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind = engine) session = Session() session.add(e1) session.add(e2) session.add(d1) session.add(d2) session.add(d3) session.add(e3) session.commit()
以下 SQL 语句将在 Python 控制台上发出 –
INSERT INTO department (name) VALUES (?) ('Accounts',)
INSERT INTO department (name) VALUES (?) ('Sales',)
INSERT INTO department (name) VALUES (?) ('Marketing',)
INSERT INTO employee (name) VALUES (?) ('John',)
INSERT INTO employee (name) VALUES (?) ('Graham',)
INSERT INTO employee (name) VALUES (?) ('Tony',)
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 2), (3, 1), (2, 3))
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 1), (2, 2), (3, 3))
要检查上述操作的效果,请使用 SQLiteStudio 并查看部门、员工和链接表中的数据 –
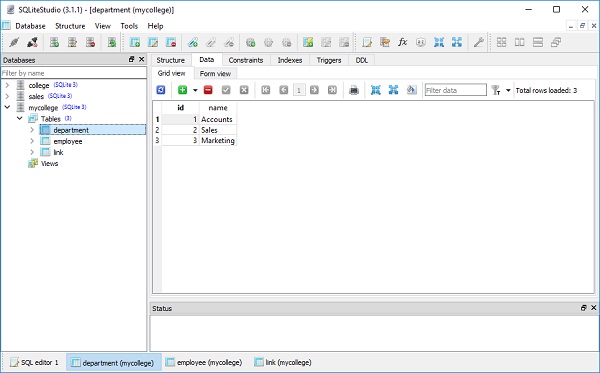
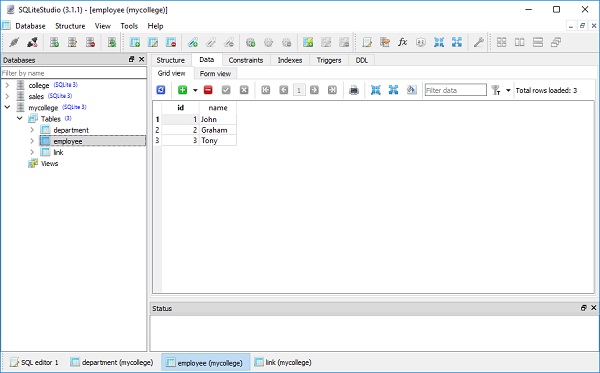
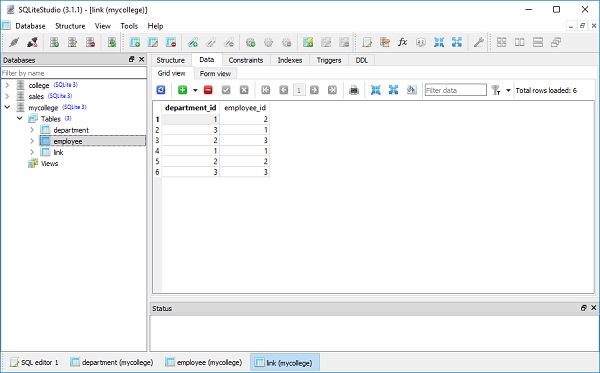
要显示数据,请运行以下查询语句 –
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for x in session.query( Department, Employee).filter(Link.department_id == Department.id,
Link.employee_id == Employee.id).order_by(Link.department_id).all():
print ("Department: {} Name: {}".format(x.Department.name, x.Employee.name))
根据我们示例中填充的数据,输出将显示如下 –
Department: Accounts Name: John Department: Accounts Name: Graham Department: Sales Name: Graham Department: Sales Name: Tony Department: Marketing Name: John Department: Marketing Name: Tony
