HBase – 概述
HBase – 概述
自 1970 年以来,RDBMS 是数据存储和维护相关问题的解决方案。大数据出现后,公司意识到处理大数据的好处,并开始选择像 Hadoop 这样的解决方案。
Hadoop 使用分布式文件系统存储大数据,MapReduce 对其进行处理。Hadoop 擅长存储和处理各种格式的海量数据,例如任意的、半结构的,甚至非结构化的。
Hadoop 的局限性
Hadoop只能进行批处理,数据只能按顺序访问。这意味着即使是最简单的工作也必须搜索整个数据集。
一个庞大的数据集在处理时会产生另一个庞大的数据集,也应该按顺序处理。此时,需要一个新的解决方案来在单个时间单位内访问任何数据点(随机访问)。
Hadoop 随机访问数据库
HBase、Cassandra、couchDB、Dynamo 和 MongoDB 等应用程序是一些存储大量数据并以随机方式访问数据的数据库。
什么是 HBase?
HBase 是一个构建在 Hadoop 文件系统之上的分布式面向列的数据库。它是一个开源项目,可横向扩展。
HBase 是一种类似于谷歌大表的数据模型,旨在提供对海量结构化数据的快速随机访问。它利用了 Hadoop 文件系统 (HDFS) 提供的容错能力。
它是 Hadoop 生态系统的一部分,提供对 Hadoop 文件系统中数据的随机实时读/写访问。
可以直接或通过 HBase 将数据存储在 HDFS 中。数据消费者使用 HBase 随机读取/访问 HDFS 中的数据。HBase 位于 Hadoop 文件系统之上,提供读写访问。
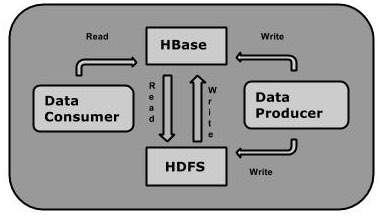
HBase 和 HDFS
| HDFS | HBase |
|---|---|
| HDFS is a distributed file system suitable for storing large files. | HBase 是一个建立在 HDFS 之上的数据库。 |
| HDFS does not support fast individual record lookups. | HBase 为较大的表提供快速查找。 |
| It provides high latency batch processing; no concept of batch processing. | 它提供对来自数十亿条记录的单行的低延迟访问(随机访问)。 |
| It provides only sequential access of data. | HBase 内部使用哈希表并提供随机访问,并将数据存储在索引的 HDFS 文件中以加快查找速度。 |
HBase 中的存储机制
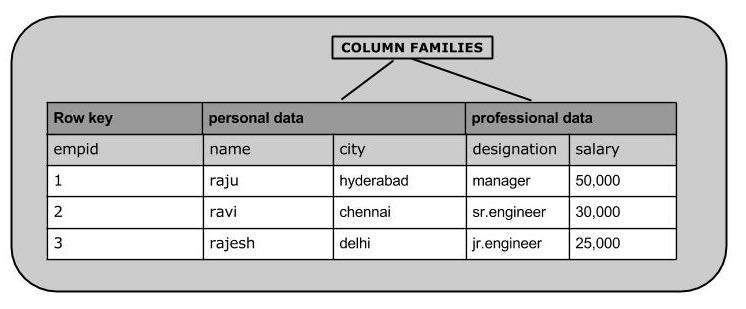
HBase 是一个面向列的数据库,其中的表是按行排序的。表模式只定义了列族,它们是键值对。一个表有多个列族,每个列族可以有任意数量的列。后续列值连续存储在磁盘上。表格的每个单元格值都有一个时间戳。简而言之,在 HBase 中:
- 表是行的集合。
- Row 是列族的集合。
- 列族是列的集合。
- 列是键值对的集合。
下面给出的是 HBase 中表的示例架构。
| Rowid | 列族 | 列族 | 列族 | 列族 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | 列2 | 第 3 列 | 第 1 列 | 列2 | 第 3 列 | 第 1 列 | 列2 | 第 3 列 | 第 1 列 | 列2 | 第 3 列 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
面向列和面向行
面向列的数据库是将数据表存储为数据列的部分而不是数据行的数据库。很快,他们将拥有列族。
| Row-Oriented Database | 面向列的数据库 |
|---|---|
| It is suitable for Online Transaction Process (OLTP). | 它适用于在线分析处理 (OLAP)。 |
| Such databases are designed for small number of rows and columns. | 面向列的数据库是为大表设计的。 |
下图显示了面向列的数据库中的列族:
HBase 和 RDBMS
| HBase | 关系型数据库管理系统 |
|---|---|
| HBase is schema-less, it doesn’t have the concept of fixed columns schema; defines only column families. | RDBMS 由其架构管理,架构描述了表的整个结构。 |
| It is built for wide tables. HBase is horizontally scalable. | 它很薄,适合小桌子。难以规模化。 |
| No transactions are there in HBase. | RDBMS 是事务性的。 |
| It has de-normalized data. | 它将具有标准化数据。 |
| It is good for semi-structured as well as structured data. | 它适用于结构化数据。 |
HBase 的特点
- HBase 是线性可扩展的。
- 它具有自动故障支持。
- 它提供一致的读取和写入。
- 它与 Hadoop 集成,作为源和目标。
- 它为客户端提供了简单的 Java API。
- 它提供跨集群的数据复制。
在哪里使用 HBase
-
Apache HBase 用于对大数据进行随机、实时的读/写访问。
-
它在商品硬件集群之上托管非常大的表。
-
Apache HBase 是仿照 Google Bigtable 建模的非关系型数据库。Bigtable 作用于 Google 文件系统,同样 Apache HBase 作用于 Hadoop 和 HDFS 之上。
HBase的应用
- 每当需要编写繁重的应用程序时都会使用它。
- 每当我们需要提供对可用数据的快速随机访问时,就会使用 HBase。
- Facebook、Twitter、Yahoo 和 Adobe 等公司在内部使用 HBase。
HBase 历史
| Year | 事件 |
|---|---|
| Nov 2006 | 谷歌发布了关于 BigTable 的论文。 |
| Feb 2007 | 最初的 HBase 原型是作为 Hadoop 的贡献而创建的。 |
| Oct 2007 | 第一个可用的 HBase 与 Hadoop 0.15.0 一起发布。 |
| Jan 2008 | HBase 成为 Hadoop 的子项目。 |
| Oct 2008 | HBase 0.18.1 发布。 |
| Jan 2009 | HBase 0.19.0 发布。 |
| Sept 2009 | HBase 0.20.0 发布。 |
| May 2010 | HBase 成为 Apache 顶级项目。 |
