使用 AQL 查询数据
使用 AQL 查询数据
在本章中,我们将讨论如何使用 AQL 查询数据。我们在之前的章节中已经讨论过,ArangoDB 已经开发了自己的查询语言,并且它的名称是 AQL。
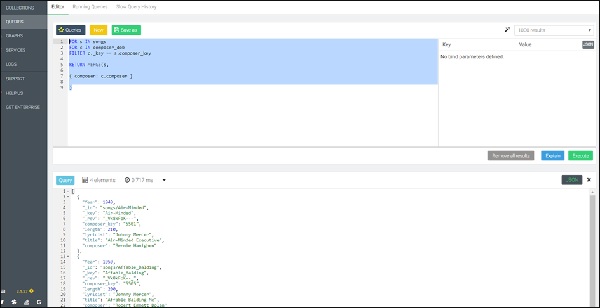
现在让我们开始与 AQL 交互。如下图所示,在 Web 界面中,按下位于导航栏顶部的AQL 编辑器选项卡。将出现一个空白的查询编辑器。
需要时,您可以通过单击右上角的查询或结果选项卡从结果视图切换到编辑器,反之亦然,如下图所示 –
除其他外,编辑器具有语法突出显示、撤消/重做功能和查询保存。详细参考可以看官方文档。我们将重点介绍 AQL 查询编辑器的一些基本和常用功能。
AQL基础
在 AQL 中,查询表示要实现的最终结果,而不是实现最终结果的过程。此功能通常称为语言的声明性属性。此外,AQL 可以查询也可以修改数据,因此可以通过结合这两个过程来创建复杂的查询。
请注意,AQL 完全符合 ACID。阅读或修改查询要么全部结束,要么根本不结束。即使读取文档的数据也会以一致的数据单元结束。
我们将两首新歌曲添加到我们已经创建的歌曲集中。您可以复制以下查询,而不是键入,并将其粘贴到 AQL 编辑器中 –
FOR song IN [
{
title: "Air-Minded Executive", lyricist: "Johnny Mercer",
composer: "Bernie Hanighen", Year: 1940, _key: "Air-Minded"
},
{
title: "All Mucked Up", lyricist: "Johnny Mercer", composer:
"Andre Previn", Year: 1974, _key: "All_Mucked"
}
]
INSERT song IN songs
按左下角的执行按钮。
它将在歌曲集中写入两个新文档。
此查询描述了 FOR 循环在 AQL 中的工作方式;它遍历 JSON 编码的文档列表,对集合中的每个文档执行编码操作。不同的操作可以是创建新结构、过滤、选择文档、修改或将文档插入数据库(请参阅即时示例)。本质上,AQL 可以高效地执行 CRUD 操作。
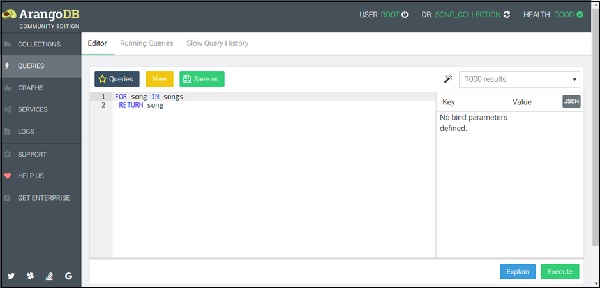
为了找到我们数据库中的所有歌曲,让我们再次运行以下查询,相当于一个SQL类型数据库的SELECT * FROM歌曲(因为编辑器记住了上次查询,按*New*按钮清理编辑器) –
FOR song IN songs RETURN song
结果集将显示到目前为止保存在歌曲集中的歌曲列表,如下面的屏幕截图所示。
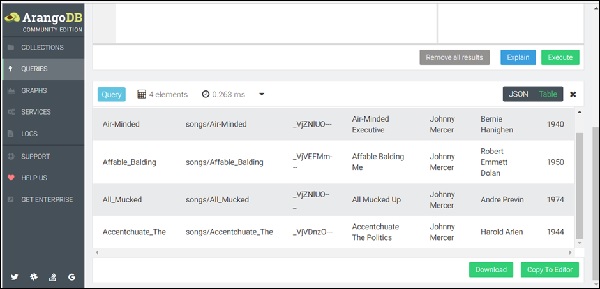
可以将FILTER、SORT和LIMIT等操作添加到For 循环体以缩小和排序结果。
FOR song IN songs FILTER song.Year > 1940 RETURN song
上述查询将在“结果”选项卡中提供 1940 年之后创建的歌曲(见下图)。
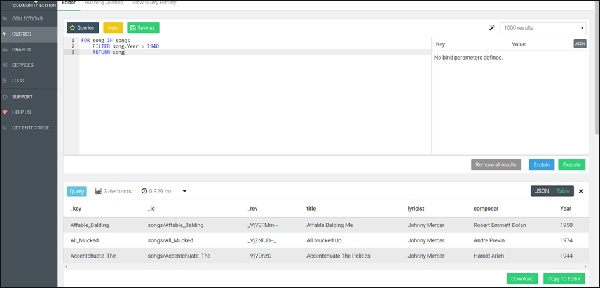
本示例中使用了文档键,但任何其他属性也可以用作过滤的等效项。由于保证文档键是唯一的,因此不会有多个文档与此过滤器匹配。对于其他属性,情况可能并非如此。要返回按名称升序排序的活动用户子集(由名为 status 的属性确定),我们使用以下语法 –
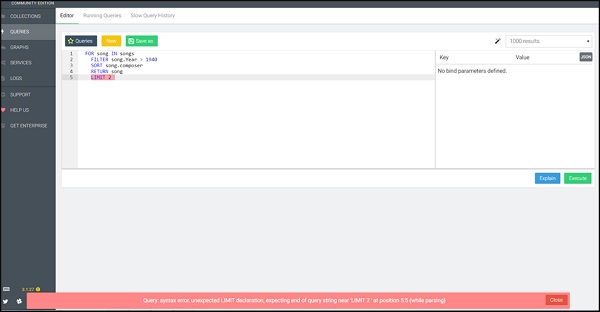
FOR song IN songs FILTER song.Year > 1940 SORT song.composer RETURN song LIMIT 2
我们特意包含了这个例子。在这里,我们观察到 AQL 以红色突出显示的查询语法错误消息。此语法突出显示错误,有助于调试您的查询,如下面的屏幕截图所示。
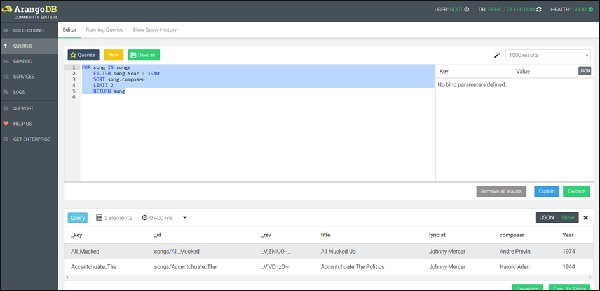
现在让我们运行正确的查询(注意更正) –
FOR song IN songs FILTER song.Year > 1940 SORT song.composer LIMIT 2 RETURN song
AQL 中的复杂查询
AQL 为所有支持的数据类型配备了多种功能。查询中的变量分配允许构建非常复杂的嵌套结构。通过这种方式,数据密集型操作更接近后端的数据,而不是客户端(例如浏览器)。为了理解这一点,让我们首先将任意持续时间(长度)添加到歌曲中。
让我们从第一个函数开始,即更新函数 –
UPDATE { _key: "All_Mucked" }
WITH { length: 180 }
IN songs
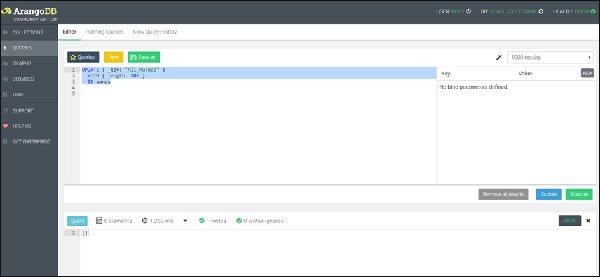
我们可以看到已经编写了一个文档,如上面的屏幕截图所示。
现在让我们也更新其他文件(歌曲)。
UPDATE { _key: "Affable_Balding" }
WITH { length: 200 }
IN songs
我们现在可以检查我们所有的歌曲是否都有一个新的属性长度–
FOR song IN songs RETURN song
输出
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_VkC5lbS---",
"title": "Air-Minded Executive",
"lyricist": "Johnny Mercer",
"composer": "Bernie Hanighen",
"Year": 1940,
"length": 210
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_VkC4eM2---",
"title": "Affable Balding Me",
"lyricist": "Johnny Mercer",
"composer": "Robert Emmett Dolan",
"Year": 1950,
"length": 200
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vjah9Pu---",
"title": "All Mucked Up",
"lyricist": "Johnny Mercer",
"composer": "Andre Previn",
"Year": 1974,
"length": 180
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_VkC3WzW---",
"title": "Accentchuate The Politics",
"lyricist": "Johnny Mercer",
"composer": "Harold Arlen",
"Year": 1944,
"length": 190
}
]
为了说明 AQL 的其他关键字(如 LET、FILTER、SORT 等)的使用,我们现在将歌曲的持续时间格式化为mm:ss格式。
询问
FOR song IN songs
FILTER song.length > 150
LET seconds = song.length % 60
LET minutes = FLOOR(song.length / 60)
SORT song.composer
RETURN
{
Title: song.title,
Composer: song.composer,
Duration: CONCAT_SEPARATOR(':',minutes, seconds)
}
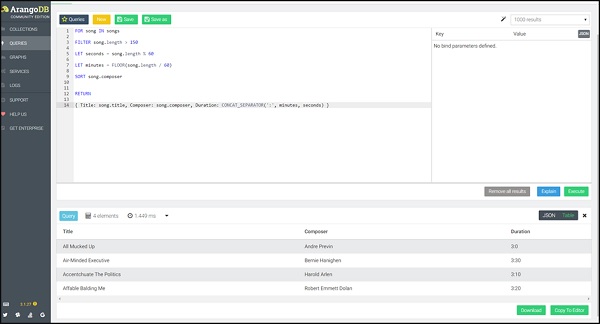
这次我们将返回歌曲名称和时长。该返回功能,您可以创建一个新的JSON对象返回为每个输入文件。
我们现在将讨论 AQL 数据库的“连接”功能。
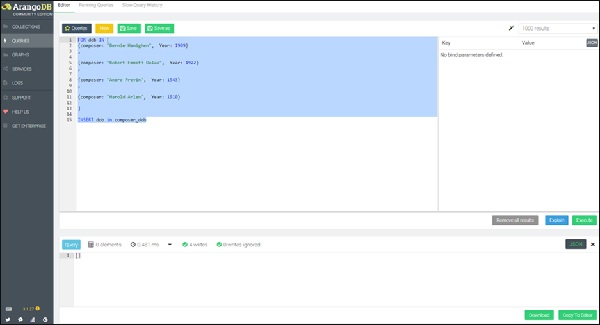
让我们从创建一个集合composer_dob开始。此外,我们将通过在查询框中运行以下查询来创建具有假设的作曲家出生日期的四个文档 –
FOR dob IN [
{composer: "Bernie Hanighen", Year: 1909}
,
{composer: "Robert Emmett Dolan", Year: 1922}
,
{composer: "Andre Previn", Year: 1943}
,
{composer: "Harold Arlen", Year: 1910}
]
INSERT dob in composer_dob
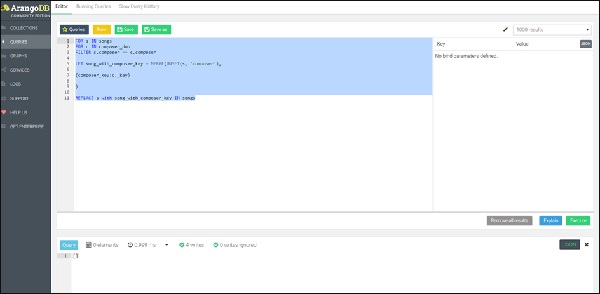
为了突出与 SQL 的相似性,我们在 AQL 中提出了一个嵌套的 FOR 循环查询,导致 REPLACE 操作,首先在内循环中迭代所有作曲家的 dob,然后在所有相关歌曲上,创建一个包含属性song_with_composer_key而不是歌曲属性。
这是查询 –
FOR s IN songs
FOR c IN composer_dob
FILTER s.composer == c.composer
LET song_with_composer_key = MERGE(
UNSET(s, 'composer'),
{composer_key:c._key}
)
REPLACE s with song_with_composer_key IN songs
现在让我们再次运行查询FOR song IN Song RETURN song以查看歌曲集是如何变化的。
输出
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_Vk8kFoK---",
"Year": 1940,
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive"
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_Vk8kFoK--_",
"Year": 1950,
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me"
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vk8kFoK--A",
"Year": 1974,
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up"
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"Year": 1944,
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics"
}
]
以上查询完成了数据迁移过程,为每首歌曲添加了composer_key。
现在下一个查询再次是一个嵌套的 FOR 循环查询,但这一次导致了 Join 操作,将相关作曲家的名字(在 `composer_key` 的帮助下挑选)添加到每首歌曲 –
FOR s IN songs
FOR c IN composer_dob
FILTER c._key == s.composer_key
RETURN MERGE(s,
{ composer: c.composer }
)
输出
[
{
"Year": 1940,
"_id": "songs/Air-Minded",
"_key": "Air-Minded",
"_rev": "_Vk8kFoK---",
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive",
"composer": "Bernie Hanighen"
},
{
"Year": 1950,
"_id": "songs/Affable_Balding",
"_key": "Affable_Balding",
"_rev": "_Vk8kFoK--_",
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me",
"composer": "Robert Emmett Dolan"
},
{
"Year": 1974,
"_id": "songs/All_Mucked",
"_key": "All_Mucked",
"_rev": "_Vk8kFoK--A",
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up",
"composer": "Andre Previn"
},
{
"Year": 1944,
"_id": "songs/Accentchuate_The",
"_key": "Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics",
"composer": "Harold Arlen"
}
]