DocumentDB SQL – 快速指南
DocumentDB SQL – 快速指南
DocumentDB SQL – 概述
DocumentDB 是 Microsoft 在 Azure 上运行的最新 NoSQL 文档数据库平台。在本教程中,我们将学习有关使用 DocumentDB 支持的特殊版本 SQL 查询文档的所有信息。
NoSQL 文档数据库
DocumentDB 是微软最新的 NoSQL 文档数据库,但是,当我们说 NoSQL 文档数据库时,我们所说的 NoSQL 和文档数据库究竟指的是什么?
-
SQL 的意思是结构化查询语言,它是关系数据库的传统查询语言。SQL 通常等同于关系数据库。
-
将 NoSQL 数据库视为非关系型数据库确实更有帮助,因此 NoSQL 真正意味着非关系型。
有不同类型的 NoSQL 数据库,其中包括键值存储,例如 –
- Azure 表存储
- 基于列的商店,如 Cassandra
- 图数据库,如 NEO4
- 文档数据库,如 MongoDB 和 Azure DocumentDB
为什么是 SQL 语法?
乍一看这听起来很奇怪,但在 NoSQL 数据库 DocumentDB 中,我们使用 SQL 进行查询。如上所述,这是一个基于 JSON 和 JavaScript 语义的特殊 SQL 版本。
-
SQL 只是一种语言,但它也是一种非常流行的语言,它丰富而富有表现力。因此,使用某种 SQL 方言而不是提出一种全新的表达查询的方式似乎是一个好主意,如果您想从数据库中获取文档,我们需要学习这种方式。
-
SQL 是为关系型数据库设计的,DocumentDB 是非关系型文档数据库。DocumentDB 团队实际上已经为文档数据库的非关系世界调整了 SQL 语法,这就是将 SQL 植根于 JSON 和 JavaScript 的含义。
-
该语言仍然读起来像熟悉的 SQL,但语义都是基于无模式 JSON 文档而不是关系表。在 DocumentDB 中,我们将使用 JavaScript 数据类型而不是 SQL 数据类型。我们将熟悉 SELECT、FROM、WHERE 等,但 JavaScript 类型仅限于数字和字符串、对象、数组、布尔值和 null 远远少于范围广泛的 SQL 数据类型。
-
类似地,表达式被评估为 JavaScript 表达式而不是某种形式的 T-SQL。例如,在非规范化数据的世界中,我们处理的不是行和列,而是具有包含嵌套数组和对象的分层结构的无模式文档。
SQL 是如何工作的?
DocumentDB 团队以多种创新方式回答了这个问题。其中很少列出如下 –
-
首先,假设您没有更改自动为文档中的每个属性编制索引的默认行为,您可以在查询中使用点分符号来导航到任何属性的路径,无论它在文档中嵌套多深。
-
您还可以执行文档内连接,其中嵌套数组元素与文档中的父元素连接,方式与关系世界中两个表之间执行连接的方式非常相似。
-
您的查询可以按原样从数据库返回文档,或者您可以根据所需的尽可能多或尽可能少的文档数据来投影任何您想要的自定义 JSON 形状。
-
DocumentDB 中的 SQL 支持许多常见的运算符,包括 –
-
算术和按位运算
-
AND 和 OR 逻辑
-
相等和范围比较
-
字符串连接
-
-
查询语言还支持许多内置函数。
DocumentDB SQL – 选择子句
Azure 门户有一个查询资源管理器,可让我们对 DocumentDB 数据库运行任何 SQL 查询。我们将使用查询资源管理器从最简单的查询开始演示查询语言的许多不同功能和特性。
步骤 1 – 打开 Azure 门户,然后在数据库边栏选项卡中,单击查询资源管理器边栏选项卡。
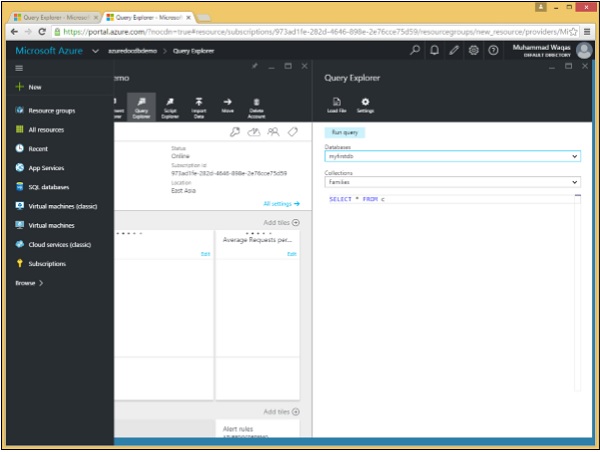
请记住,查询在集合范围内运行,因此 Query Explorer 允许我们在此下拉列表中选择集合。我们将其设置为包含三个文档的 Families 集合。让我们在这个例子中考虑这三个文档。
以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
查询资源管理器通过这个简单的查询 SELECT * FROM c 打开,它只是从集合中检索所有文档。尽管它很简单,但它与关系数据库中的等效查询仍有很大不同。
Step 2 – 在关系数据库中,SELECT * 表示在 DocumentDB 中返回所有列。这意味着您希望结果中的每个文档都完全按照它存储在数据库中的方式返回。
但是,当您选择特定的属性和表达式而不是简单地发出 SELECT * 时,您就会为结果中的每个文档投影一个您想要的新形状。
步骤 3 – 单击“运行”以执行查询并打开结果刀片。
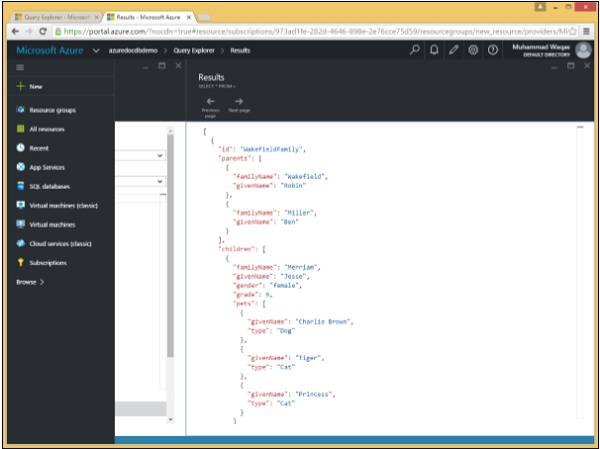
可以看出,检索到了 WakefieldFamily、SmithFamily 和 AndersonFamily。
以下是作为SELECT * FROM c查询结果检索的三个文档。
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
"givenName": "Fluffy",
"type": "Rabbit"
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]
但是,这些结果还包括系统生成的所有以下划线字符作为前缀的属性。
DocumentDB SQL – 来自子句
在本章中,我们将介绍 FROM 子句,它的工作方式与常规 SQL 中的标准 FROM 子句完全不同。
查询总是在特定集合的上下文中运行,并且不能跨集合内的文档进行连接,这让我们想知道为什么需要 FROM 子句。事实上,我们没有,但如果我们不包含它,那么我们将不会查询集合中的文档。
该子句的目的是指定查询必须操作的数据源。通常整个集合是源,但也可以指定集合的一个子集。FROM <from_specification> 子句是可选的,除非源在查询的后面被过滤或投影。
让我们再看一次同一个例子。以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
在上面的查询中,“ SELECT * FROM c ”表示整个 Families 集合是要枚举的源。
子文件
源也可以减少到更小的子集。当我们只想检索每个文档中的一个子树时,子根可以成为源,如以下示例所示。
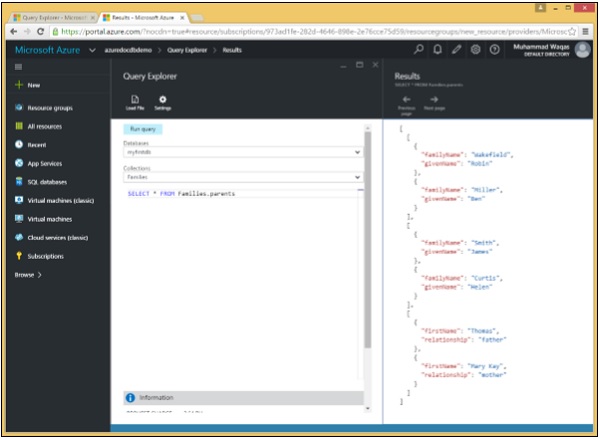
当我们运行以下查询时 –
SELECT * FROM Families.parents
将检索以下子文档。
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]
作为这个查询的结果,我们可以看到只检索到父子文档。
DocumentDB SQL – Where 子句
在本章中,我们将介绍 WHERE 子句,它与 FROM 子句一样也是可选的。它用于在以源提供的 JSON 文档形式获取数据时指定条件。任何 JSON 文档都必须将指定的条件评估为“真”才能考虑作为结果。如果满足给定的条件,则它才会以 JSON 文档的形式返回特定数据。我们可以使用 WHERE 子句来过滤记录并只获取必要的记录。
在此示例中,我们将考虑相同的三个文档。以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
让我们看一个使用 WHERE 子句的简单示例。

在此查询中,在 WHERE 子句中,指定了 (WHERE f.id = “WakefieldFamily”) 条件。
SELECT * FROM f WHERE f.id = "WakefieldFamily"
执行上述查询时,它将返回 WakefieldFamily 的完整 JSON 文档,如下面的输出所示。
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]
DocumentDB SQL – 操作员
运算符是保留字或字符,主要用于 SQL WHERE 子句中以执行操作,例如比较和算术运算。DocumentDB SQL 还支持多种标量表达式。最常用的是二元和一元表达式。
当前支持以下 SQL 运算符并可在查询中使用。
SQL 比较运算符
以下是 DocumentDB SQL 语法中可用的所有比较运算符的列表。
| S.No. | 运算符和说明 |
|---|---|
| 1 |
= 检查两个操作数的值是否相等。如果是,则条件变为真。 |
| 2 |
!= 检查两个操作数的值是否相等。如果值不相等,则条件变为真。 |
| 3 |
<> 检查两个操作数的值是否相等。如果值不相等,则条件变为真。 |
| 4 |
> 检查左操作数的值是否大于右操作数的值。如果是,则条件变为真。 |
| 5 |
< 检查左操作数的值是否小于右操作数的值。如果是,则条件变为真。 |
| 6 |
>= 检查左操作数的值是否大于或等于右操作数的值。如果是,则条件变为真。 |
| 7 |
<= 检查左操作数的值是否小于或等于右操作数的值。如果是,则条件变为真。 |
SQL 逻辑运算符
以下是 DocumentDB SQL 语法中可用的所有逻辑运算符的列表。
| S.No. | 运算符和说明 |
|---|---|
| 1 |
AND AND 运算符允许在 SQL 语句的 WHERE 子句中存在多个条件。 |
| 2 |
BETWEEN BETWEEN 运算符用于在给定最小值和最大值的情况下搜索一组值中的值。 |
| 3 |
IN IN 运算符用于将值与已指定的文字值列表进行比较。 |
| 4 |
OR OR 运算符用于在 SQL 语句的 WHERE 子句中组合多个条件。 |
| 5 |
NOT NOT 运算符颠倒了与它一起使用的逻辑运算符的含义。例如,NOT EXISTS、NOT BETWEEN、NOT IN 等。这是一个否定运算符。 |
SQL 算术运算符
以下是 DocumentDB SQL 语法中可用的所有算术运算符的列表。
| S.No. | 运算符和说明 |
|---|---|
| 1 |
+ 添加– 在运算符的任一侧添加值。 |
| 2 |
– 减法– 从左手操作数中减去右手操作数。 |
| 3 |
* 乘法– 将运算符两侧的值相乘。 |
| 4 |
/ 除法– 将左手操作数除以右手操作数。 |
| 5 |
% 模数– 将左手操作数除以右手操作数并返回余数。 |
在这个例子中,我们也将考虑相同的文档。以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
让我们看一个在 WHERE 子句中使用比较运算符的简单示例。
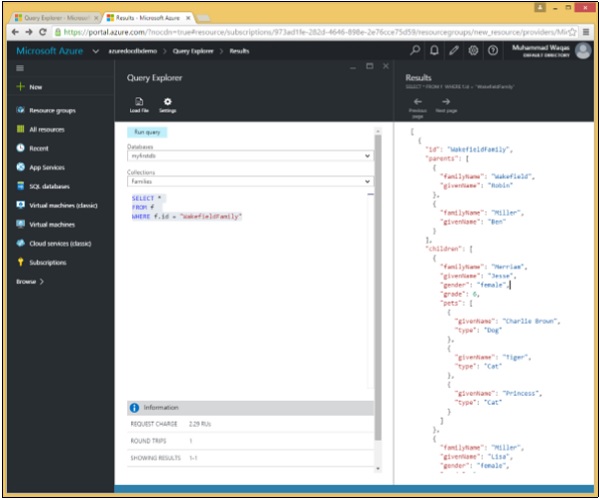
在这个查询中,在 WHERE 子句中,指定了 (WHERE f.id = “WakefieldFamily”) 条件,它将检索 id 等于 WakefieldFamily 的文档。
SELECT * FROM f WHERE f.id = "WakefieldFamily"
执行上述查询时,它将返回 WakefieldFamily 的完整 JSON 文档,如下面的输出所示。
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
}
]
让我们看另一个示例,其中查询将检索成绩大于 5 的孩子数据。
SELECT * FROM Families.children[0] c WHERE (c.grade > 5)
执行上述查询时,它将检索以下子文档,如输出所示。
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]
DocumentDB SQL – 关键字之间
BETWEEN 关键字用于表达对 SQL 中的值范围的查询。BETWEEN 可用于字符串或数字。在 DocumentDB 中使用 BETWEEN 和 ANSI SQL 之间的主要区别在于,您可以针对混合类型的属性表达范围查询。
例如,在某些文档中,您可能将“等级”作为数字,而在其他文档中,它可能是字符串。在这些情况下,两种不同类型结果之间的比较是“未定义的”,文档将被跳过。
让我们考虑上一个示例中的三个文档。以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
我们来看一个例子,其中查询返回第一个孩子的成绩在 1-5 之间(包括两者)的所有家庭文档。
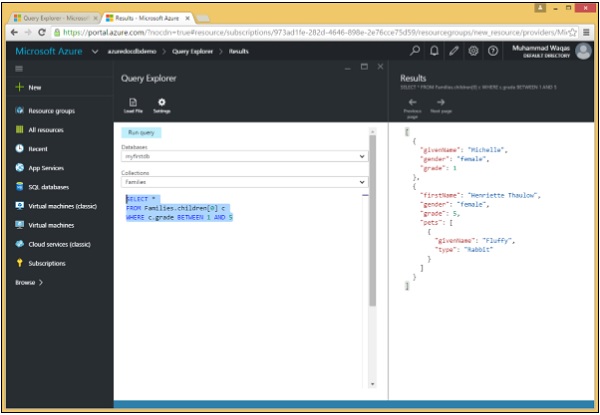
以下是使用 BETWEEN 关键字和 AND 逻辑运算符的查询。
SELECT * FROM Families.children[0] c WHERE c.grade BETWEEN 1 AND 5
执行上述查询时,会产生以下输出。
[
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
]
要显示上一个示例范围之外的成绩,请使用 NOT BETWEEN,如下面的查询所示。
SELECT * FROM Families.children[0] c WHERE c.grade NOT BETWEEN 1 AND 5
执行此查询时。它产生以下输出。
[
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
}
]
DocumentDB SQL – 关键字
IN 关键字可用于检查指定值是否与列表中的任何值匹配。IN 运算符允许您在 WHERE 子句中指定多个值。IN 相当于链接多个 OR 子句。
类似的三个文档被认为是在前面的例子中完成的。以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
我们来看一个简单的例子。
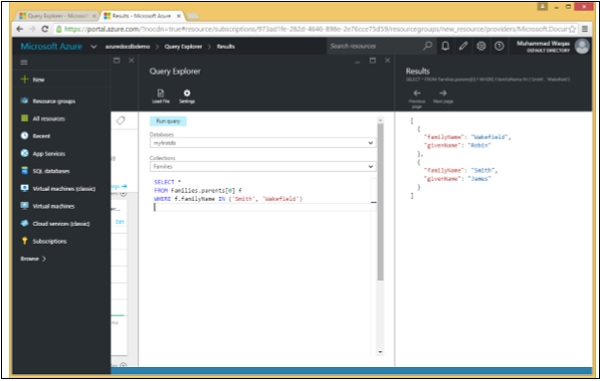
以下是将检索 familyName 为“Smith”或 Wakefield 的数据的查询。
SELECT *
FROM Families.parents[0] f
WHERE f.familyName IN ('Smith', 'Wakefield')
执行上述查询时,会产生以下输出。
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Smith",
"givenName": "James"
}
]
让我们考虑另一个简单的示例,其中将检索所有家庭文档,其中 id 是“SmithFamily”或“AndersenFamily”之一。以下是查询。
SELECT *
FROM Families
WHERE Families.id IN ('SmithFamily', 'AndersenFamily')
执行上述查询时,会产生以下输出。
[
{
"id": "SmithFamily",
"parents": [
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{
"givenName": "Tweetie",
"type": "Bird"
}
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEDAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEDAAAAAAAAAA==/",
"_etag": "\"00000600-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]
DocumentDB SQL – 值关键字
当您知道只返回一个值时,VALUE 关键字可以通过避免创建完整对象的开销来帮助生成更精简的结果集。VALUE 关键字提供了一种返回 JSON 值的方法。
我们来看一个简单的例子。
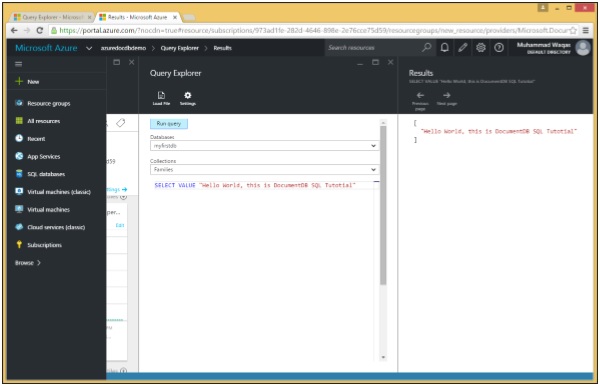
以下是带有 VALUE 关键字的查询。
SELECT VALUE "Hello World, this is DocumentDB SQL Tutorial"
执行此查询时,它会返回标量“Hello World,这是 DocumentDB SQL 教程”。
[ "Hello World, this is DocumentDB SQL Tutorial" ]
在另一个示例中,让我们考虑前面示例中的三个文档。
以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
以下是查询。
SELECT VALUE f.location FROM Families f
执行此查询时,它返回不带位置标签的返回地址。
[
{
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
{
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
{
"state": "WA",
"county": "King",
"city": "Seattle"
}
]
如果我们现在在没有 VALUE 关键字的情况下指定相同的查询,那么它将返回带有位置标签的地址。以下是查询。
SELECT f.location FROM Families f
执行此查询时,会产生以下输出。
[
{
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
}
},
{
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
},
{
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
}
}
]
DocumentDB SQL – 按子句排序
Microsoft Azure DocumentDB 支持使用 SQL over JSON 文档查询文档。您可以在查询中使用 ORDER BY 子句根据数字和字符串对集合中的文档进行排序。该子句可以包含一个可选的 ASC/DESC 参数来指定必须检索结果的顺序。
我们将考虑与前面示例中相同的文档。
以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
我们来看一个简单的例子。
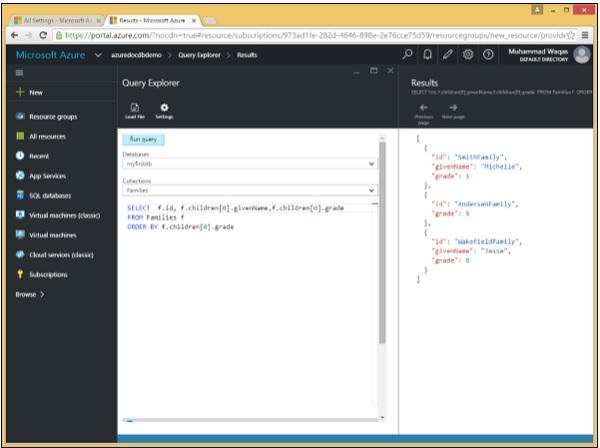
以下是包含 ORDER BY 关键字的查询。
SELECT f.id, f.children[0].givenName,f.children[0].grade FROM Families f ORDER BY f.children[0].grade
执行上述查询时,会产生以下输出。
[
{
"id": "SmithFamily",
"givenName": "Michelle",
"grade": 1
},
{
"id": "AndersenFamily",
"grade": 5
},
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]
让我们考虑另一个简单的例子。
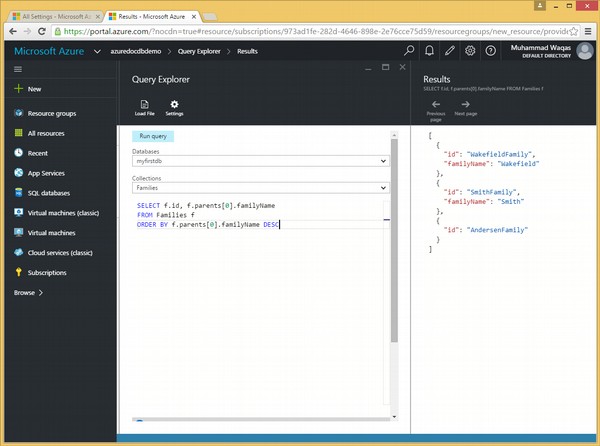
以下是包含 ORDER BY 关键字和 DESC 可选关键字的查询。
SELECT f.id, f.parents[0].familyName FROM Families f ORDER BY f.parents[0].familyName DESC
执行上述查询时,将产生以下输出。
[
{
"id": "WakefieldFamily",
"familyName": "Wakefield"
},
{
"id": "SmithFamily",
"familyName": "Smith"
},
{
"id": "AndersenFamily"
}
]
DocumentDB SQL – 迭代
在 DocumentDB SQL 中,Microsoft 添加了一个新结构,可与 IN 关键字一起使用以提供对 JSON 数组迭代的支持。FROM 子句中提供了对迭代的支持。
我们将再次考虑前面示例中类似的三个文档。
以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
让我们看一个在 FROM 子句中没有 IN 关键字的简单示例。
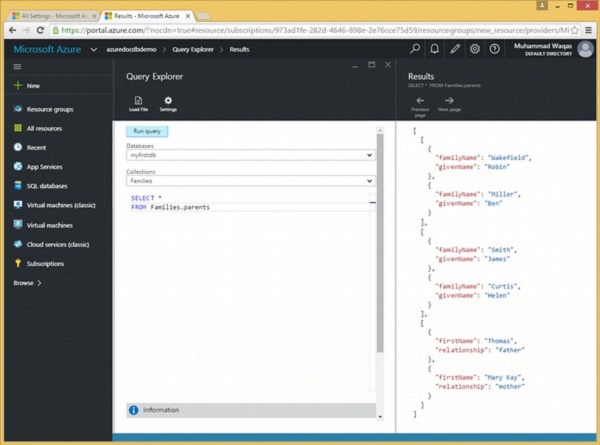
以下是将从 Families 集合中返回所有父项的查询。
SELECT * FROM Families.parents
执行上述查询时,会产生以下输出。
[
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
[
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
}
],
[
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
]
]
从上面的输出中可以看出,每个家庭的父母都显示在一个单独的 JSON 数组中。
让我们看一下同一个例子,但是这次我们将在 FROM 子句中使用 IN 关键字。
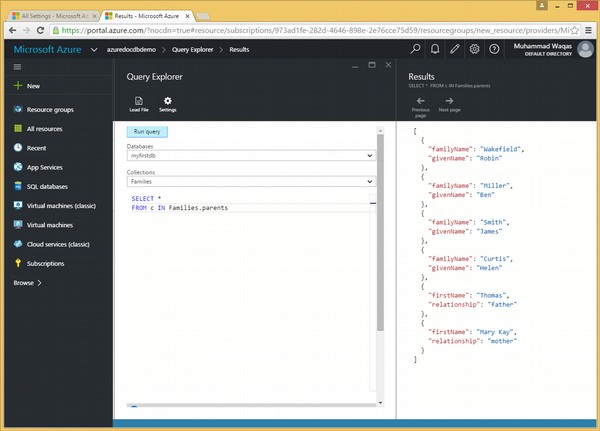
以下是包含 IN 关键字的查询。
SELECT * FROM c IN Families.parents
执行上述查询时,会产生以下输出。
[
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
},
{
"familyName": "Smith",
"givenName": "James"
},
{
"familyName": "Curtis",
"givenName": "Helen"
},
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
{
"id": "WakefieldFamily",
"givenName": "Jesse",
"grade": 6
}
]
在上面的例子中可以看出,通过迭代,对集合中的父项执行迭代的查询具有不同的输出数组。因此,每个家庭的所有父母都被添加到一个数组中。
DocumentDB SQL – 联接
在关系数据库中,Joins 子句用于合并来自数据库中两个或多个表的记录,在设计规范化模式时,跨表联接的需求非常重要。由于 DocumentDB 处理无模式文档的非规范化数据模型,因此 DocumentDB SQL 中的 JOIN 是“selfjoin”的逻辑等价物。
让我们考虑前面示例中的三个文档。
以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
让我们看一个例子来理解 JOIN 子句是如何工作的。

以下是将根连接到子文档的查询。
SELECT f.id FROM Families f JOIN c IN f.children
执行上述查询时,将产生以下输出。
[
{
"id": "WakefieldFamily"
},
{
"id": "WakefieldFamily"
},
{
"id": "SmithFamily"
},
{
"id": "SmithFamily"
},
{
"id": "AndersenFamily"
}
]
在上面的示例中,连接位于文档根和子根之间,这在两个 JSON 对象之间形成叉积。以下是一些需要注意的要点 –
-
在 FROM 子句中,JOIN 子句是一个迭代器。
-
前两个文档 WakefieldFamily 和 SmithFamily 包含两个子项,因此结果集还包含为每个子项生成单独对象的叉积。
-
第三个文档 AndersenFamily 只包含一个孩子,因此只有一个对象对应于这个文档。
让我们看一下同一个例子,但是这次我们也检索子名称以更好地理解 JOIN 子句。
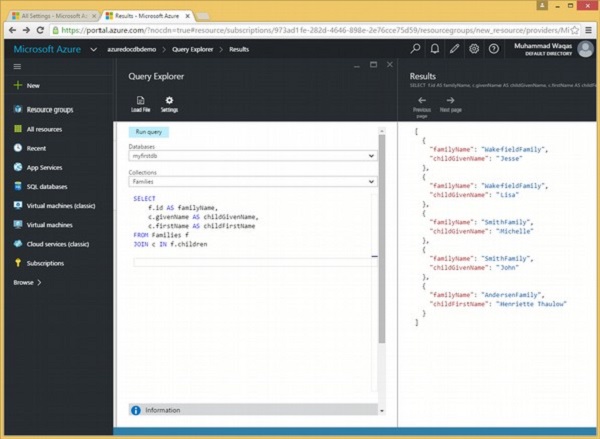
以下是将根连接到子文档的查询。
SELECT f.id AS familyName, c.givenName AS childGivenName, c.firstName AS childFirstName FROM Families f JOIN c IN f.children
执行上述查询时,会产生以下输出。
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]
DocumentDB SQL – 别名
在关系数据库中,SQL 别名用于临时重命名表或列标题。同样,在 DocumentDB 中,别名用于临时重命名 JSON 文档、子文档、对象或任何字段。
重命名是临时更改,实际文档不会更改。基本上,创建别名是为了使字段/文档名称更具可读性。对于别名,使用 AS 关键字,这是可选的。
让我们考虑三个与前面示例中使用的文档相似的文档。
以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
让我们看一个例子来讨论别名。
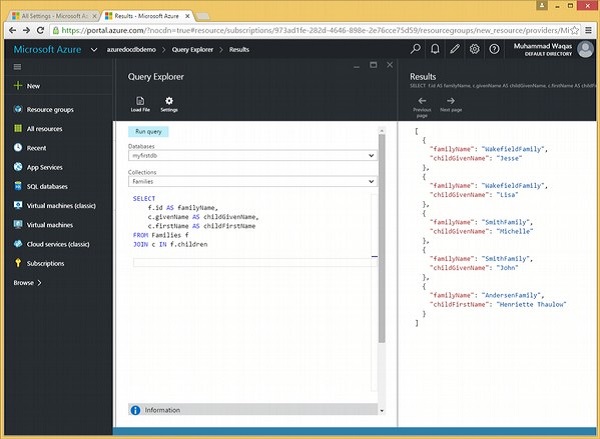
以下是将根连接到子文档的查询。我们有别名,例如 f.id AS familyName、c.givenName AS childGivenName 和 c.firstName AS childFirstName。
SELECT f.id AS familyName, c.givenName AS childGivenName, c.firstName AS childFirstName FROM Families f JOIN c IN f.children
执行上述查询时,会产生以下输出。
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]
上面的输出显示文件名发生了变化,但这是一个临时的变化,原始文档没有被修改。
DocumentDB SQL – 数组创建
在 DocumentDB SQL 中,微软添加了一个关键特性,借助它我们可以轻松创建数组。这意味着当我们运行查询时,结果它将创建一个类似于 JSON 对象的集合数组作为查询的结果。
让我们考虑与前面示例中相同的文档。
以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
让我们看一个例子。
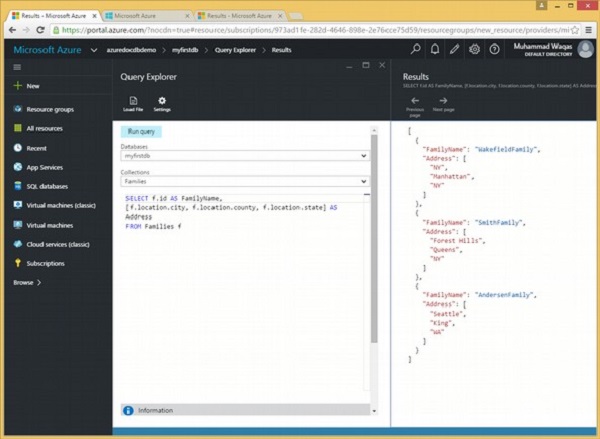
以下是将返回每个家庭的姓氏和地址的查询。
SELECT f.id AS FamilyName, [f.location.city, f.location.county, f.location.state] AS Address FROM Families f
可以看出,city、county 和 state 字段被括在方括号中,这将创建一个数组,该数组名为 Address。执行上述查询时,会产生以下输出。
[
{
"FamilyName": "WakefieldFamily",
"Address": [
"NY",
"Manhattan",
"NY"
]
},
{
"FamilyName": "SmithFamily",
"Address": [
"Forest Hills",
"Queens",
"NY"
]
},
{
"FamilyName": "AndersenFamily",
"Address": [
"Seattle",
"King",
"WA"
]
}
]
城市、县和州信息添加到上述输出的地址数组中。
DocumentDB SQL – 标量表达式
在 DocumentDB SQL 中,SELECT 子句还支持常量、算术表达式、逻辑表达式等标量表达式。通常,标量查询很少使用,因为它们实际上并不查询集合中的文档,它们只是对表达式求值。但是使用标量表达式查询来学习基础知识、如何在查询中使用表达式和塑造 JSON 仍然很有帮助,这些概念直接适用于您将针对集合中的文档运行的实际查询。
让我们看一个包含多个标量查询的示例。
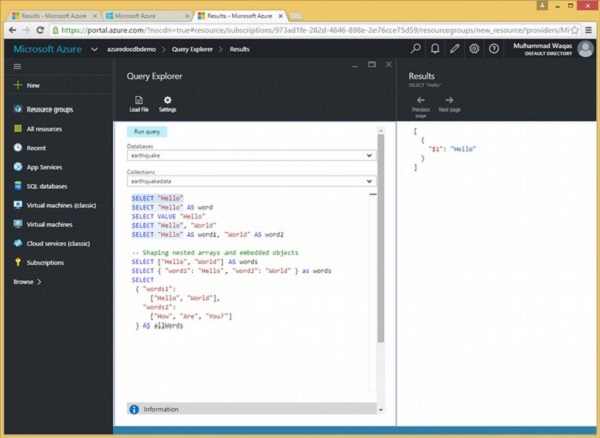
在查询资源管理器中,只选择要执行的文本,然后单击“运行”。让我们运行第一个。
SELECT "Hello"
执行上述查询时,会产生以下输出。
[
{
"$1": "Hello"
}
]
这个输出可能看起来有点混乱,所以让我们分解它。
-
首先,正如我们在上一个演示中看到的,查询结果总是包含在方括号中,因为它们是作为 JSON 数组返回的,即使是像这样只返回单个文档的标量表达式查询的结果。
-
我们有一个包含一个文档的数组,并且该文档中有一个属性用于 SELECT 语句中的单个表达式。
-
SELECT 语句不提供此属性的名称,因此 DocumentDB 使用 $1 自动生成一个。
-
这通常不是我们想要的,这就是为什么我们可以使用 AS 为查询中的表达式设置别名,在此示例中,它按照您希望的方式设置生成文档中的属性名称,即 word。
SELECT "Hello" AS word
执行上述查询时,会产生以下输出。
[
{
"word": "Hello"
}
]
同样,下面是另一个简单的查询。
SELECT ((2 + 11 % 7)-2)/3
该查询检索以下输出。
[
{
"$1": 1.3333333333333333
}
]
让我们看另一个塑造嵌套数组和嵌入对象的例子。
SELECT
{
"words1":
["Hello", "World"],
"words2":
["How", "Are", "You?"]
} AS allWords
执行上述查询时,会产生以下输出。
[
{
"allWords": {
"words1": [
"Hello",
"World"
],
"words2": [
"How",
"Are",
"You?"
]
}
}
]
DocumentDB SQL – 参数化
在关系数据库中,参数化查询是这样一种查询,其中使用占位符作为参数,并在执行时提供参数值。DocumentDB 也支持参数化查询,参数化查询中的参数可以用熟悉的@ 符号表示。使用参数化查询的最重要原因是为了避免 SQL 注入攻击。它还可以提供对用户输入的稳健处理和转义。
让我们看一下我们将使用 .Net SDK 的示例。以下是删除集合的代码。
private async static Task DeleteCollection(DocumentClient client, string collectionId) {
Console.WriteLine();
Console.WriteLine(">>> Delete Collection {0} in {1} <<<",
collectionId, _database.Id);
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};
DocumentCollection collection = client.CreateDocumentCollectionQuery(database.SelfLink,
query).AsEnumerable().First();
await client.DeleteDocumentCollectionAsync(collection.SelfLink);
Console.WriteLine("Deleted collection {0} from database {1}",
collectionId, _database.Id);
}
参数化查询的构造如下。
var query = new SqlQuerySpec {
QueryText = "SELECT * FROM c WHERE c.id = @id",
Parameters = new SqlParameterCollection { new SqlParameter { Name =
"@id", Value = collectionId } }
};
我们没有对 collectionId 进行硬编码,因此此方法可用于删除任何集合。我们可以使用“@”符号作为参数名称的前缀,类似于 SQL Server。
在上面的示例中,我们通过 Id 查询特定集合,其中 Id 参数在此 SqlParameterCollection 中定义,该 SqlParameterCollection 分配给此 SqlQuerySpec 的参数属性。然后,SDK 会为 DocumentDB 构建最终查询字符串,并将 collectionId 嵌入其中。我们运行查询,然后使用其 SelfLink 删除集合。
以下是 CreateDocumentClient 任务实现。
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM
c WHERE c.id = 'earthquake'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'myfirstdb'").AsEnumerable().First();
await DeleteCollection(client, "MyCollection1");
await DeleteCollection(client, "MyCollection2");
}
}
执行代码时,它会产生以下输出。
**** Delete Collection MyCollection1 in mydb **** Deleted collection MyCollection1 from database myfirstdb **** Delete Collection MyCollection2 in mydb **** Deleted collection MyCollection2 from database myfirstdb
让我们再看一个例子。我们可以编写一个以姓氏和地址状态作为参数的查询,然后根据用户输入对 lastname 和 location.state 的各种值执行它。
SELECT * FROM Families f WHERE f.lastName = @lastName AND f.location.state = @addressState
然后可以将此请求作为参数化 JSON 查询发送到 DocumentDB,如以下代码所示。
{
"query": "SELECT * FROM Families f WHERE f.lastName = @lastName AND
f.location.state = @addressState",
"parameters": [
{"name": "@lastName", "value": "Wakefield"},
{"name": "@addressState", "value": "NY"},
]
}
DocumentDB SQL – 内置函数
DocumentDB 支持许多可在查询中使用的常见操作的内置函数。有许多用于执行数学计算的函数,以及在处理不同模式时非常有用的类型检查函数。这些函数可以测试某个属性是否存在,以及它是数字还是字符串、布尔值还是对象。
我们还获得了这些用于解析和操作字符串的便捷函数,以及一些用于处理数组的函数,允许您执行诸如连接数组和测试以查看数组是否包含特定元素之类的操作。
以下是不同类型的内置函数 –
| S.No. | 内置功能和说明 |
|---|---|
| 1 | Mathematical Functions
数学函数执行计算,通常基于作为参数提供的输入值,并返回一个数值。 |
| 2 | Type Checking Functions
类型检查函数允许您检查 SQL 查询中表达式的类型。 |
| 3 | String Functions
字符串函数对字符串输入值执行操作并返回字符串、数字或布尔值。 |
| 4 | Array Functions
数组函数对数组输入值执行操作并以数值、布尔值或数组值的形式返回。 |
| 5 | Spatial Functions
DocumentDB 还支持用于地理空间查询的开放地理空间联盟 (OGC) 内置函数。 |
DocumentDB SQL – Linq 到 SQL 的翻译
在 DocumentDB 中,我们实际上使用 SQL 来查询文档。如果我们正在进行 .NET 开发,还有一个 LINQ 提供程序可以使用,它可以从 LINQ 查询生成适当的 SQL。
支持的数据类型
在 DocumentDB 中,DocumentDB .NET SDK 随附的 LINQ 提供程序支持所有 JSON 基元类型,如下所示 –
- 数字
- 布尔值
- 细绳
- 无效的
支持的表达式
DocumentDB .NET SDK 随附的 LINQ 提供程序支持以下标量表达式。
-
常量值 – 包括原始数据类型的常量值。
-
属性/数组索引表达式– 表达式是指对象或数组元素的属性。
-
算术表达式– 包括关于数字和布尔值的常见算术表达式。
-
字符串比较表达式– 包括将字符串值与某个常量字符串值进行比较。
-
对象/数组创建表达式– 返回复合值类型或匿名类型的对象或此类对象的数组。这些值可以嵌套。
支持的 LINQ 运算符
以下是 DocumentDB .NET SDK 中包含的 LINQ 提供程序中支持的 LINQ 运算符列表。
-
Select – 投影转换为 SQL SELECT,包括对象构造。
-
Where – 过滤器转换为 SQL WHERE,并支持 && 、 || 之间的转换 和 !到 SQL 运算符。
-
SelectMany – 允许将数组展开到 SQL JOIN 子句。可用于链接/嵌套表达式以过滤数组元素。
-
OrderBy 和 OrderByDescending – 转换为 ORDER BY 升序/降序。
-
CompareTo – 转换为范围比较。通常用于字符串,因为它们在 .NET 中不可比较。
-
Take – 转换为 SQL TOP 以限制查询结果。
-
数学函数– 支持从 .NET 的 Abs、Acos、Asin、Atan、Ceiling、Cos、Exp、Floor、Log、Log10、Pow、Round、Sign、Sin、Sqrt、Tan、Truncate 转换为等效的 SQL 内置函数。
-
字符串函数– 支持从 .NET 的 Concat、Concat、Contains、EndsWith、IndexOf、Count、ToLower、TrimStart、Replace、Reverse、TrimEnd、StartsWith、SubString、ToUpper 转换为等效的 SQL 内置函数。
-
Array Functions – 支持从 .NET 的 Concat、Contains 和 Count 转换为等效的 SQL 内置函数。
-
地理空间扩展函数– 支持从存根方法距离、内部、IsValid 和 IsValidDetailed 转换为等效的 SQL 内置函数。
-
User-DefinedFunctionProvider.Invoke支持从存根方法 UserDefinedFunctionProvider.Invoke 转换为相应的用户定义函数。
-
杂项– 支持合并和条件运算符的翻译。可以根据上下文将包含转换为字符串 CONTAINS、ARRAY_CONTAINS 或 SQL IN。
让我们看一下我们将使用 .Net SDK 的示例。以下是我们将在此示例中考虑的三个文档。
新客户 1
{
"name": "New Customer 1",
"address": {
"addressType": "Main Office",
"addressLine1": "123 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}
新客户 2
{
"name": "New Customer 2",
"address": {
"addressType": "Main Office",
"addressLine1": "678 Main Street",
"location": {
"city": "London",
"stateProvinceName": " London "
},
"postalCode": "11229",
"countryRegionName": "United Kingdom"
},
}
新客户 3
{
"name": "New Customer 3",
"address": {
"addressType": "Main Office",
"addressLine1": "12 Main Street",
"location": {
"city": "Brooklyn",
"stateProvinceName": "New York"
},
"postalCode": "11229",
"countryRegionName": "United States"
},
}
以下是我们使用 LINQ 进行查询的代码。我们已经在q 中定义了一个 LINQ 查询,但在我们对其运行 .ToList 之前它不会执行。
private static void QueryDocumentsWithLinq(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Query Documents (LINQ) ****");
Console.WriteLine();
Console.WriteLine("Quering for US customers (LINQ)");
var q =
from d in client.CreateDocumentQuery<Customer>(collection.DocumentsLink)
where d.Address.CountryRegionName == "United States"
select new {
Id = d.Id,
Name = d.Name,
City = d.Address.Location.City
};
var documents = q.ToList();
Console.WriteLine("Found {0} US customers", documents.Count);
foreach (var document in documents) {
var d = document as dynamic;
Console.WriteLine(" Id: {0}; Name: {1}; City: {2}", d.Id, d.Name, d.City);
}
Console.WriteLine();
}
SDK 会将我们的 LINQ 查询转换为 DocumentDB 的 SQL 语法,根据我们的 LINQ 语法生成一个 SELECT 和 WHERE 子句。
让我们从 CreateDocumentClient 任务调用上述查询。
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)) {
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE c.id =
'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'").AsEnumerable().First();
QueryDocumentsWithLinq(client);
}
}
执行上述代码时,会产生以下输出。
**** Query Documents (LINQ) **** Quering for US customers (LINQ) Found 2 US customers Id: 7e9ad4fa-c432-4d1a-b120-58fd7113609f; Name: New Customer 1; City: Brooklyn Id: 34e9873a-94c8-4720-9146-d63fb7840fad; Name: New Customer 1; City: Brooklyn
DocumentDB SQL – JavaScript 集成
如今,JavaScript 无处不在,而不仅仅是在浏览器中。DocumentDB 将 JavaScript 作为一种现代 T-SQL 包含在内,并在数据库引擎内部支持原生 JavaScript 逻辑的事务执行。DocumentDB 提供了一种编程模型,用于在存储过程和触发器方面直接在集合上执行基于 JavaScript 的应用程序逻辑。
让我们看一个示例,其中我们创建了一个简单的存储过程。以下是步骤 –
步骤 1 – 创建一个新的控制台应用程序。
第 2 步– 从 NuGet 添加 .NET SDK。我们在这里使用 .NET SDK,这意味着我们将编写一些 C# 代码来创建、执行和删除我们的存储过程,但存储过程本身是用 JavaScript 编写的。
步骤 3 – 右键单击解决方案资源管理器中的项目。
第 4 步– 为存储过程添加一个新的 JavaScript 文件并将其命名为 HelloWorldStoreProce.js
每个存储过程都只是一个 JavaScript 函数,因此我们将创建一个新函数,当然我们也会将此函数命名为HelloWorldStoreProce。如果我们给函数一个名字,这并不重要。DocumentDB 只会通过我们在创建它时提供的 ID 来引用这个存储过程。
function HelloWorldStoreProce() {
var context = getContext();
var response = context.getResponse();
response.setBody('Hello, and welcome to DocumentDB!');
}
存储过程所做的就是从上下文中获取响应对象并调用其setBody方法将字符串返回给调用者。在 C# 代码中,我们将创建存储过程,执行它,然后删除它。
存储过程的范围是每个集合,因此我们需要集合的 SelfLink 来创建存储过程。
第 5 步– 首先查询myfirstdb数据库,然后查询MyCollection集合。
创建存储过程就像在 DocumentDB 中创建任何其他资源一样。
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink, "SELECT * FROM
c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client.
CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client.ExecuteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Executed stored procedure; response = {0}", result.Response);
// Delete stored procedure
await client.DeleteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Deleted stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
}
}
第 6 步– 首先使用新资源的 Id 创建一个定义对象,然后调用DocumentClient对象上的 Create 方法之一。对于存储过程,定义包括 Id 和要传送到服务器的实际 JavaScript 代码。
步骤 7 – 调用File.ReadAllText从 JS 文件中提取存储过程代码。
步骤 8 – 将存储过程代码分配给定义对象的 body 属性。
就 DocumentDB 而言,我们这里在定义中指定的 Id 是存储过程的名称,而不管我们实际命名 JavaScript 函数的名称是什么。
然而,在创建存储过程和其他服务器端对象时,建议我们命名 JavaScript 函数,并且这些函数名称确实与我们在 DocumentDB 定义中设置的 Id 匹配。
第9步-呼叫CreateStoredProcedureAsync,传递SelfLink为MyCollection的收集和存储过程定义。这将创建DocumentDB 分配给它的存储过程和ResourceId。
步骤 10 – 调用存储过程。ExecuteStoredProcedureAsync采用您设置为存储过程返回值的预期数据类型的类型参数,如果您想要返回动态对象,您可以简单地将其指定为对象。这是一个对象,其属性将在运行时绑定。
在这个例子中,我们知道我们的存储过程只是返回一个字符串,所以我们调用ExecuteStoredProcedureAsync<string>。
以下是 Program.cs 文件的完整实现。
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DocumentDBStoreProce {
class Program {
private static void Main(string[] args) {
Task.Run(async () => {
await SimpleStoredProcDemo();
}).Wait();
}
private async static Task SimpleStoredProcDemo() {
var endpoint = "https://azuredocdbdemo.documents.azure.com:443/";
var masterKey =
"BBhjI0gxdVPdDbS4diTjdloJq7Fp4L5RO/StTt6UtEufDM78qM2CtBZWbyVwFPSJIm8AcfDu2O+AfV T+TYUnBQ==";
using (var client = new DocumentClient(new Uri(endpoint), masterKey)) {
// Get database
Database database = client
.CreateDatabaseQuery("SELECT * FROM c WHERE c.id = 'myfirstdb'")
.AsEnumerable()
.First();
// Get collection
DocumentCollection collection = client
.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'MyCollection'")
.AsEnumerable()
.First();
// Create stored procedure
var sprocBody = File.ReadAllText(@"..\..\HelloWorldStoreProce.js");
var sprocDefinition = new StoredProcedure {
Id = "HelloWorldStoreProce",
Body = sprocBody
};
StoredProcedure sproc = await client
.CreateStoredProcedureAsync(collection.SelfLink, sprocDefinition);
Console.WriteLine("Created stored procedure {0} ({1})", sproc
.Id, sproc.ResourceId);
// Execute stored procedure
var result = await client
.ExecuteStoredProcedureAsync<string>(sproc.SelfLink);
Console.WriteLine("Executed stored procedure; response = {0}",
result.Response);
// Delete stored procedure
await client.DeleteStoredProcedureAsync(sproc.SelfLink);
Console.WriteLine("Deleted stored procedure {0} ({1})",
sproc.Id, sproc.ResourceId);
}
}
}
}
执行上述代码时,会产生以下输出。
Created stored procedure HelloWorldStoreProce (Ic8LAMEUVgACAAAAAAAAgA==) Executed stored procedure; response = Hello, and welcome to DocumentDB!
如上面的输出所示,响应属性具有“您好,欢迎使用 DocumentDB!” 由我们的存储过程返回。
DocumentDB SQL – 用户定义的函数
DocumentDB SQL 提供对用户定义函数 (UDF) 的支持。UDF 只是您可以编写的另一种 JavaScript 函数,它们的工作方式与您期望的差不多。您可以创建 UDF 以使用可在查询中引用的自定义业务逻辑来扩展查询语言。
DocumentDB SQL 语法经过扩展以支持使用这些 UDF 的自定义应用程序逻辑。UDF 可以在 DocumentDB 中注册,然后作为 SQL 查询的一部分进行引用。
对于此示例,让我们考虑以下三个文档。
AndersenFamily文档如下。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
SmithFamily文档如下。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
WakefieldFamily文档如下。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
让我们看一个示例,在该示例中我们将创建一些简单的 UDF。
以下是CreateUserDefinedFunctions的实现。
private async static Task CreateUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** Create User Defined Functions ****");
Console.WriteLine();
await CreateUserDefinedFunction(client, "udfRegEx");
}
我们有一个 udfRegEx,在 CreateUserDefinedFunction 中,我们从本地文件中获取它的 JavaScript 代码。我们为新的 UDF 构造定义对象,并使用集合的 SelfLink 和 udfDefinition 对象调用 CreateUserDefinedFunctionAsync,如下面的代码所示。
private async static Task<UserDefinedFunction>
CreateUserDefinedFunction(DocumentClient client, string udfId) {
var udfBody = File.ReadAllText(@"..\..\Server\" + udfId + ".js");
var udfDefinition = new UserDefinedFunction {
Id = udfId,
Body = udfBody
};
var result = await client
.CreateUserDefinedFunctionAsync(_collection.SelfLink, udfDefinition);
var udf = result.Resource;
Console.WriteLine("Created user defined function {0}; RID: {1}",
udf.Id, udf.ResourceId);
return udf;
}
我们从结果的资源属性中取回新的 UDF,并将其返回给调用者。要显示现有的 UDF,以下是ViewUserDefinedFunctions的实现。我们调用CreateUserDefinedFunctionQuery并像往常一样循环遍历它们。
private static void ViewUserDefinedFunctions(DocumentClient client) {
Console.WriteLine();
Console.WriteLine("**** View UDFs ****");
Console.WriteLine();
var udfs = client
.CreateUserDefinedFunctionQuery(_collection.UserDefinedFunctionsLink)
.ToList();
foreach (var udf in udfs) {
Console.WriteLine("User defined function {0}; RID: {1}", udf.Id, udf.ResourceId);
}
}
DocumentDB SQL 不提供用于搜索子字符串或正则表达式的内置函数,因此下面的小单行填补了这一空白,它是一个 JavaScript 函数。
function udfRegEx(input, regex) {
return input.match(regex);
}
给定第一个参数中的输入字符串,使用 JavaScript 的内置正则表达式支持将第二个参数中的模式匹配字符串传入 . 匹配。我们可以运行一个子字符串查询来查找所有在lastName属性中包含单词 Andersen 的商店。
private static void Execute_udfRegEx(DocumentClient client) {
var sql = "SELECT c.name FROM c WHERE udf.udfRegEx(c.lastName, 'Andersen') != null";
Console.WriteLine();
Console.WriteLine("Querying for Andersen");
var documents = client.CreateDocumentQuery(_collection.SelfLink, sql).ToList();
Console.WriteLine("Found {0} Andersen:", documents.Count);
foreach (var document in documents) {
Console.WriteLine("Id: {0}, Name: {1}", document.id, document.lastName);
}
}
请注意,我们必须使用前缀udf限定每个 UDF 引用。我们只是像任何普通查询一样将 SQL 传递给CreateDocumentQuery。最后,让我们从CreateDocumentClient任务调用上述查询
private static async Task CreateDocumentClient() {
// Create a new instance of the DocumentClient
using (var client = new DocumentClient(new Uri(EndpointUrl), AuthorizationKey)){
database = client.CreateDatabaseQuery("SELECT * FROM c WHERE
c.id = 'myfirstdb'").AsEnumerable().First();
collection = client.CreateDocumentCollectionQuery(database.CollectionsLink,
"SELECT * FROM c WHERE c.id = 'Families'").AsEnumerable().First();
await CreateUserDefinedFunctions(client);
ViewUserDefinedFunctions(client);
Execute_udfRegEx(client);
}
}
执行上述代码时,会产生以下输出。
**** Create User Defined Functions **** Created user defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA== **** View UDFs **** User defined function udfRegEx; RID: kV5oANVXnwAlAAAAAAAAYA== Querying for Andersen Found 1 Andersen: Id: AndersenFamily, Name: Andersen
DocumentDB SQL – 复合 SQL 查询
复合查询使您能够组合来自现有查询的数据,然后在显示报告结果(显示组合数据集)之前应用过滤器、聚合等。复合查询检索关于现有查询的多个级别的相关信息,并将组合数据呈现为单个扁平化查询结果。
使用复合查询,您还可以选择 –
-
选择 SQL 修剪选项以根据用户的属性选择删除不需要的表和字段。
-
设置 ORDER BY 和 GROUP BY 子句。
-
将 WHERE 子句设置为复合查询结果集的过滤器。
可以组合上述运算符以形成更强大的查询。由于 DocumentDB 支持嵌套集合,因此组合可以串联或嵌套。
让我们考虑此示例的以下文档。
AndersenFamily文档如下。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
SmithFamily文档如下。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
WakefieldFamily文档如下。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
我们来看一个串联查询的例子。
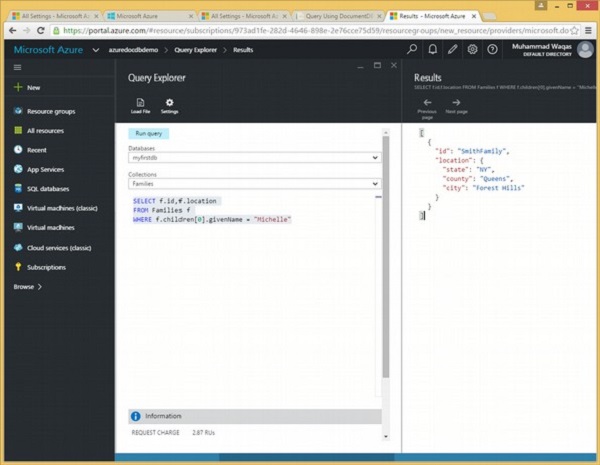
以下是将检索第一个孩子givenName是 Michelle的家庭的 id 和位置的查询。
SELECT f.id,f.location FROM Families f WHERE f.children[0].givenName = "Michelle"
执行上述查询时,会产生以下输出。
[
{
"id": "SmithFamily",
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
}
}
]
让我们考虑另一个串联查询的例子。
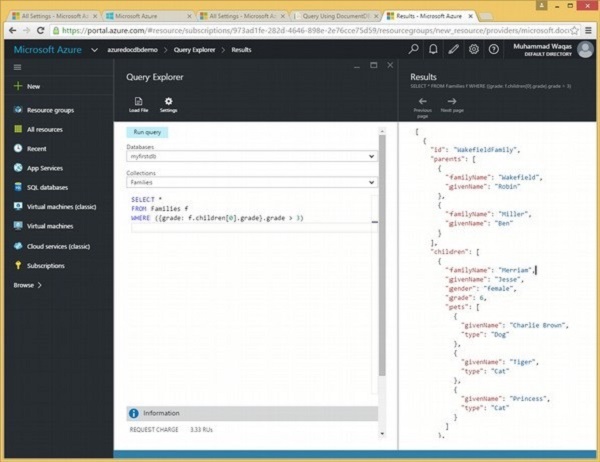
以下是将返回第一个孩子成绩大于 3 的所有文档的查询。
SELECT *
FROM Families f
WHERE ({grade: f.children[0].grade}.grade > 3)
执行上述查询时,会产生以下输出。
[
{
"id": "WakefieldFamily",
"parents": [
{
"familyName": "Wakefield",
"givenName": "Robin"
},
{
"familyName": "Miller",
"givenName": "Ben"
}
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{
"givenName": "Charlie Brown",
"type": "Dog"
},
{
"givenName": "Tiger",
"type": "Cat"
},
{
"givenName": "Princess",
"type": "Cat"
}
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{
"givenName": "Jake",
"type": "Snake"
}
]
}
],
"location": {
"state": "NY",
"county": "Manhattan",
"city": "NY"
},
"isRegistered": false,
"_rid": "Ic8LAJFujgECAAAAAAAAAA==",
"_ts": 1450541623,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/",
"_etag": "\"00000500-0000-0000-0000-567582370000\"",
"_attachments": "attachments/"
},
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{
"firstName": "Thomas",
"relationship": "father"
},
{
"firstName": "Mary Kay",
"relationship": "mother"
}
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [
{
"givenName": "Fluffy",
"type": "Rabbit"
}
]
}
],
"location": {
"state": "WA",
"county": "King",
"city": "Seattle"
},
"isRegistered": true,
"_rid": "Ic8LAJFujgEEAAAAAAAAAA==",
"_ts": 1450541624,
"_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/",
"_etag": "\"00000700-0000-0000-0000-567582380000\"",
"_attachments": "attachments/"
}
]
我们来看一个嵌套查询的例子。
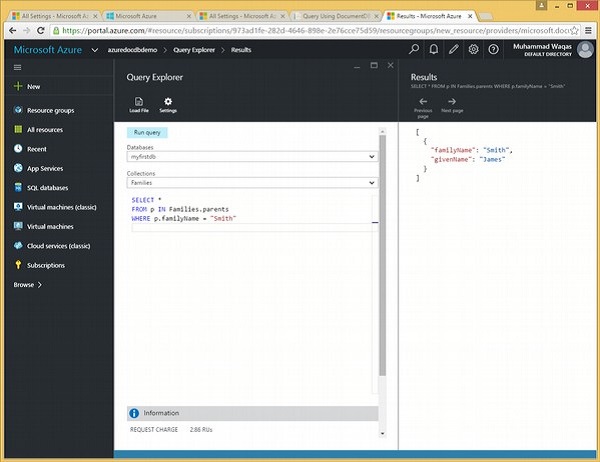
以下是将迭代所有父项然后返回familyName为 Smith的文档的查询。
SELECT * FROM p IN Families.parents WHERE p.familyName = "Smith"
执行上述查询时,会产生以下输出。
[
{
"familyName": "Smith",
"givenName": "James"
}
]
让我们考虑另一个嵌套查询的例子。
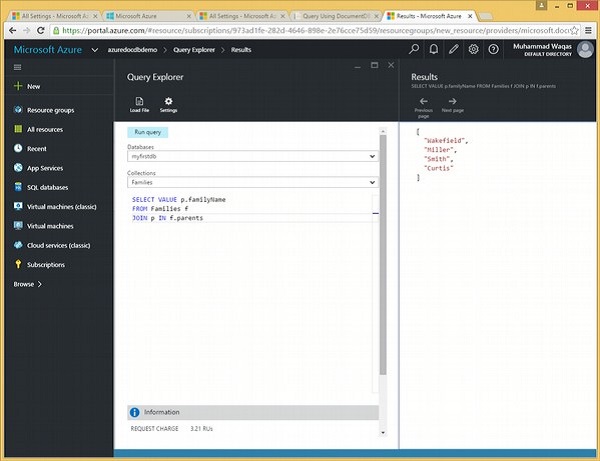
以下是将返回所有familyName的查询。
SELECT VALUE p.familyName FROM Families f JOIN p IN f.parents
执行上述查询时,会产生以下输出。
[ "Wakefield", "Miller", "Smith", "Curtis" ]
