HBase – 快速指南
HBase – 快速指南
HBase – 概述
自 1970 年以来,RDBMS 是数据存储和维护相关问题的解决方案。大数据出现后,公司意识到处理大数据的好处,并开始选择像 Hadoop 这样的解决方案。
Hadoop 使用分布式文件系统存储大数据,MapReduce 对其进行处理。Hadoop 擅长存储和处理各种格式的海量数据,例如任意的、半结构的,甚至非结构化的。
Hadoop 的局限性
Hadoop只能进行批处理,数据只能按顺序访问。这意味着即使是最简单的工作也必须搜索整个数据集。
一个庞大的数据集在处理时会产生另一个庞大的数据集,也应该按顺序处理。此时,需要一个新的解决方案来在单个时间单位内访问任何数据点(随机访问)。
Hadoop 随机访问数据库
HBase、Cassandra、couchDB、Dynamo 和 MongoDB 等应用程序是一些存储大量数据并以随机方式访问数据的数据库。
什么是 HBase?
HBase 是一个构建在 Hadoop 文件系统之上的分布式面向列的数据库。它是一个开源项目,可横向扩展。
HBase 是一种类似于谷歌大表的数据模型,旨在提供对海量结构化数据的快速随机访问。它利用了 Hadoop 文件系统 (HDFS) 提供的容错能力。
它是 Hadoop 生态系统的一部分,提供对 Hadoop 文件系统中数据的随机实时读/写访问。
可以直接或通过 HBase 将数据存储在 HDFS 中。数据消费者使用 HBase 随机读取/访问 HDFS 中的数据。HBase 位于 Hadoop 文件系统之上,提供读写访问。
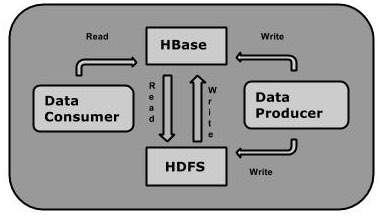
HBase 和 HDFS
| HDFS | HBase |
|---|---|
| HDFS is a distributed file system suitable for storing large files. | HBase 是一个建立在 HDFS 之上的数据库。 |
| HDFS does not support fast individual record lookups. | HBase 为较大的表提供快速查找。 |
| It provides high latency batch processing; no concept of batch processing. | 它提供对来自数十亿条记录的单行的低延迟访问(随机访问)。 |
| It provides only sequential access of data. | HBase 内部使用哈希表并提供随机访问,并将数据存储在索引的 HDFS 文件中以加快查找速度。 |
HBase 中的存储机制
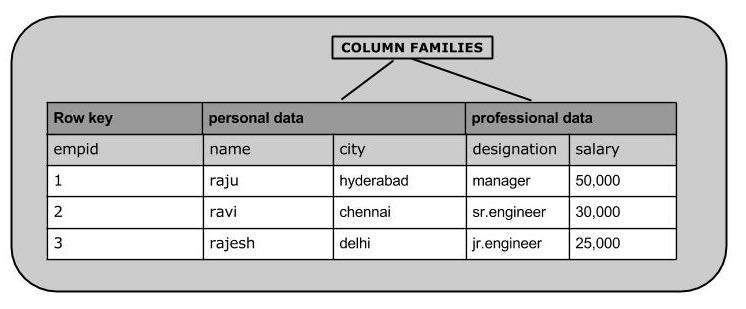
HBase 是一个面向列的数据库,其中的表是按行排序的。表模式只定义了列族,它们是键值对。一个表有多个列族,每个列族可以有任意数量的列。后续列值连续存储在磁盘上。表格的每个单元格值都有一个时间戳。简而言之,在 HBase 中:
- 表是行的集合。
- Row 是列族的集合。
- 列族是列的集合。
- 列是键值对的集合。
下面给出的是 HBase 中表的示例架构。
| Rowid | 列族 | 列族 | 列族 | 列族 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | 列2 | 第 3 列 | 第 1 列 | 列2 | 第 3 列 | 第 1 列 | 列2 | 第 3 列 | 第 1 列 | 列2 | 第 3 列 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
面向列和面向行
面向列的数据库是将数据表存储为数据列的部分而不是数据行的数据库。很快,他们将拥有列族。
| Row-Oriented Database | 面向列的数据库 |
|---|---|
| It is suitable for Online Transaction Process (OLTP). | 它适用于在线分析处理 (OLAP)。 |
| Such databases are designed for small number of rows and columns. | 面向列的数据库是为大表设计的。 |
下图显示了面向列的数据库中的列族:
HBase 和 RDBMS
| HBase | 关系型数据库管理系统 |
|---|---|
| HBase is schema-less, it doesn’t have the concept of fixed columns schema; defines only column families. | RDBMS 由其架构管理,架构描述了表的整个结构。 |
| It is built for wide tables. HBase is horizontally scalable. | 它很薄,适合小桌子。难以规模化。 |
| No transactions are there in HBase. | RDBMS 是事务性的。 |
| It has de-normalized data. | 它将具有标准化数据。 |
| It is good for semi-structured as well as structured data. | 它适用于结构化数据。 |
HBase 的特点
- HBase 是线性可扩展的。
- 它具有自动故障支持。
- 它提供一致的读取和写入。
- 它与 Hadoop 集成,作为源和目标。
- 它为客户端提供了简单的 Java API。
- 它提供跨集群的数据复制。
在哪里使用 HBase
-
Apache HBase 用于对大数据进行随机、实时的读/写访问。
-
它在商品硬件集群之上托管非常大的表。
-
Apache HBase 是仿照 Google Bigtable 建模的非关系型数据库。Bigtable 作用于 Google 文件系统,同样 Apache HBase 作用于 Hadoop 和 HDFS 之上。
HBase的应用
- 每当需要编写繁重的应用程序时都会使用它。
- 每当我们需要提供对可用数据的快速随机访问时,就会使用 HBase。
- Facebook、Twitter、Yahoo 和 Adobe 等公司在内部使用 HBase。
HBase 历史
| Year | 事件 |
|---|---|
| Nov 2006 | 谷歌发布了关于 BigTable 的论文。 |
| Feb 2007 | 最初的 HBase 原型是作为 Hadoop 的贡献而创建的。 |
| Oct 2007 | 第一个可用的 HBase 与 Hadoop 0.15.0 一起发布。 |
| Jan 2008 | HBase 成为 Hadoop 的子项目。 |
| Oct 2008 | HBase 0.18.1 发布。 |
| Jan 2009 | HBase 0.19.0 发布。 |
| Sept 2009 | HBase 0.20.0 发布。 |
| May 2010 | HBase 成为 Apache 顶级项目。 |
HBase – 架构
在 HBase 中,表被分成区域并由区域服务器提供服务。区域被列族垂直划分为“商店”。存储在 HDFS 中保存为文件。下图是HBase的架构。
注意:术语“存储”用于区域以解释存储结构。
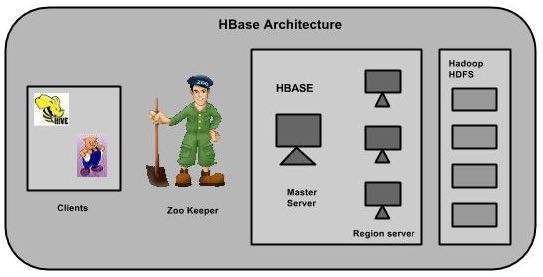
HBase 具有三个主要组件:客户端库、主服务器和区域服务器。可以根据需要添加或删除区域服务器。
主服务器
主服务器——
-
将区域分配给区域服务器,并在 Apache ZooKeeper 的帮助下完成此任务。
-
处理跨区域服务器的区域负载平衡。它卸载繁忙的服务器并将区域转移到占用较少的服务器。
-
通过协商负载平衡来维护集群的状态。
-
负责架构更改和其他元数据操作,例如创建表和列族。
地区
区域只不过是在区域服务器上拆分和分布的表。
区域服务器
区域服务器具有以下区域 –
- 与客户端通信,处理数据相关的操作。
- 处理其下所有区域的读写请求。
- 通过遵循区域大小阈值来决定区域的大小。
当我们深入研究区域服务器时,它包含区域和商店,如下所示:
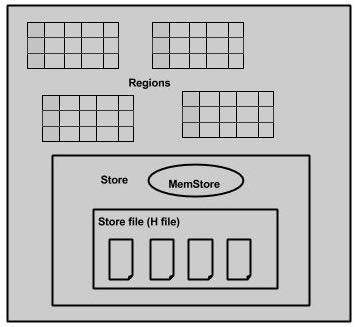
该存储包含内存存储和 HFile。Memstore 就像一个缓存。输入到 HBase 的任何内容最初都存储在这里。之后,数据作为块传输并保存在 Hfiles 中,并刷新 memstore。
动物园管理员
-
Zookeeper 是一个开源项目,提供维护配置信息、命名、提供分布式同步等服务。
-
Zookeeper 具有代表不同区域服务器的临时节点。主服务器使用这些节点来发现可用的服务器。
-
除了可用性之外,节点还用于跟踪服务器故障或网络分区。
-
客户端通过 zookeeper 与区域服务器通信。
-
在伪模式和独立模式下,HBase 本身会处理 zookeeper。
HBase – 安装
本章解释了 HBase 是如何安装和初始配置的。继续使用 HBase 需要 Java 和 Hadoop,因此您必须在系统中下载并安装 Java 和 Hadoop。
预安装设置
在将 Hadoop 安装到 Linux 环境之前,我们需要使用ssh(Secure Shell)设置 Linux 。按照下面给出的步骤设置 Linux 环境。
创建用户
首先,建议为Hadoop创建一个单独的用户,将Hadoop文件系统与Unix文件系统隔离开来。按照下面给出的步骤创建用户。
- 使用命令“su”打开根目录。
- 使用命令“useradd username”从 root 帐户创建一个用户。
- 现在您可以使用命令“su username”打开一个现有的用户帐户。
打开 Linux 终端并键入以下命令以创建用户。
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
SSH 设置和密钥生成
需要 SSH 设置才能在集群上执行不同的操作,例如启动、停止和分布式守护进程 shell 操作。为了对Hadoop的不同用户进行身份验证,需要为一个Hadoop用户提供公钥/私钥对,并与不同的用户共享。
以下命令用于使用 SSH 生成键值对。将id_rsa.pub中的公钥复制到authorized_keys中,分别为authorized_keys文件提供owner、读写权限。
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
验证 ssh
ssh localhost
安装 Java
Java 是 Hadoop 和 HBase 的主要先决条件。首先,您应该使用“java -version”验证系统中是否存在java。java version 命令的语法如下。
$ java -version
如果一切正常,它将为您提供以下输出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系统中未安装 java,请按照下面给出的步骤安装 java。
第1步
通过访问以下链接Oracle Java下载 java (JDK <最新版本> – X64.tar.gz) 。
然后jdk-7u71-linux-x64.tar.gz将被下载到您的系统中。
第2步
通常,您会在 Downloads 文件夹中找到下载的 java 文件。验证它并使用以下命令提取jdk-7u71-linux-x64.gz文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
第 3 步
要使所有用户都可以使用 java,您必须将其移动到“/usr/local/”位置。打开 root 并键入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
第四步
要设置PATH和JAVA_HOME变量,请将以下命令添加到~/.bashrc文件中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH= $PATH:$JAVA_HOME/bin
现在将所有更改应用到当前运行的系统中。
$ source ~/.bashrc
第 5 步
使用以下命令配置 java 替代方案:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
现在从终端验证java -version命令,如上所述。
下载 Hadoop
安装完java后,还得安装Hadoop。首先,使用“Hadoop version”命令验证Hadoop的存在,如下所示。
hadoop version
如果一切正常,它将为您提供以下输出。
Hadoop 2.6.0 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
如果您的系统无法定位 Hadoop,请在您的系统中下载 Hadoop。按照下面给出的命令执行此操作。
使用以下命令从 Apache Software Foundation下载并提取hadoop-2.6.0。
$ su password: # cd /usr/local # wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop- 2.6.0/hadoop-2.6.0-src.tar.gz # tar xzf hadoop-2.6.0-src.tar.gz # mv hadoop-2.6.0/* hadoop/ # exit
安装 Hadoop
以任何所需的模式安装 Hadoop。在这里,我们以伪分布式模式演示 HBase 功能,因此以伪分布式模式安装 Hadoop。
以下步骤用于安装Hadoop 2.4.1。
第 1 步 – 设置 Hadoop
您可以通过将以下命令附加到~/.bashrc文件来设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
现在将所有更改应用到当前运行的系统中。
$ source ~/.bashrc
第 2 步 – Hadoop 配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。您需要根据您的 Hadoop 基础架构对这些配置文件进行更改。
$ cd $HADOOP_HOME/etc/hadoop
为了用java开发Hadoop程序,您必须通过将JAVA_HOME值替换为您系统中java的位置来重置hadoop-env.sh文件中的java环境变量。
export JAVA_HOME=/usr/local/jdk1.7.0_71
您必须编辑以下文件才能配置 Hadoop。
核心站点.xml
该芯-的site.xml文件包含的信息,如用于Hadoop的实例的端口号,分配给文件系统,存储器限制用于存储数据的存储器,和读/写缓冲器的大小。
打开 core-site.xml 并在 <configuration> 和 </configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
在HDFS-的site.xml文件中包含的信息,如复制数据的价值,名称节点的路径,你的本地文件系统,要存储的Hadoop基础架构的数据节点的路径。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开此文件并在 <configuration>、</configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>dfs.replication</name >
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
注意:在上述文件中,所有属性值都是用户定义的,您可以根据您的 Hadoop 基础架构进行更改。
纱线站点.xml
该文件用于将 yarn 配置到 Hadoop 中。打开 yarn-site.xml 文件并在 <configuration$gt;、</configuration$gt; 之间添加以下属性。此文件中的标签。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
该文件用于指定我们使用的 MapReduce 框架。默认情况下,Hadoop 包含一个yarn-site.xml 模板。首先,需要使用以下命令将文件从mapred-site.xml.template复制到mapred-site.xml文件。
$ cp mapred-site.xml.template mapred-site.xml
打开mapred-site.xml文件并在 <configuration> 和 </configuration> 标记之间添加以下属性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
验证 Hadoop 安装
以下步骤用于验证 Hadoop 安装。
步骤 1 – 名称节点设置
使用命令“hdfs namenode -format”设置namenode,如下所示。
$ cd ~ $ hdfs namenode -format
预期结果如下。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
第 2 步 – 验证 Hadoop dfs
以下命令用于启动dfs。执行此命令将启动您的 Hadoop 文件系统。
$ start-dfs.sh
预期输出如下。
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
第 3 步 – 验证纱线脚本
以下命令用于启动纱线脚本。执行此命令将启动您的纱线守护进程。
$ start-yarn.sh
预期输出如下。
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
第 4 步 – 在浏览器上访问 Hadoop
访问 Hadoop 的默认端口号是 50070。使用以下 URL 在浏览器上获取 Hadoop 服务。
http://localhost:50070
第 5 步 – 验证集群的所有应用程序
访问集群所有应用的默认端口号是8088。使用下面的url访问这个服务。
http://localhost:8088/
安装 HBase
我们可以在三种模式中的任何一种安装HBase:Standalone模式、Pseudo Distributed模式和Fully Distributed模式。
以单机模式安装 HBase
使用“wget”命令从http://www.interior-dsgn.com/apache/hbase/stable/下载最新的HBase稳定版本,并使用tar“zxvf”命令解压。请参阅以下命令。
$cd usr/local/ $wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8- hadoop2-bin.tar.gz $tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gz
切换到超级用户模式并将 HBase 文件夹移动到 /usr/local ,如下所示。
$su $password: enter your password here mv hbase-0.99.1/* Hbase/
在独立模式下配置 HBase
在继续使用 HBase 之前,您必须编辑以下文件并配置 HBase。
hbase-env.sh
为 HBase 设置 java Home 并从 conf 文件夹中打开hbase-env.sh文件。编辑 JAVA_HOME 环境变量并将现有路径更改为当前 JAVA_HOME 变量,如下所示。
cd /usr/local/Hbase/conf gedit hbase-env.sh
这将打开 HBase 的 env.sh 文件。现在用您当前的值替换现有的JAVA_HOME值,如下所示。
export JAVA_HOME=/usr/lib/jvm/java-1.7.0
hbase-site.xml
这是HBase的主要配置文件。通过打开 /usr/local/HBase 中的 HBase 主文件夹,将数据目录设置到适当的位置。在conf文件夹里面,你会发现几个文件,打开hbase-site.xml文件如下图。
#cd /usr/local/HBase/ #cd conf # gedit hbase-site.xml
在hbase-site.xml文件中,您将找到 <configuration> 和 </configuration> 标记。在其中,将属性键下的 HBase 目录设置为“hbase.rootdir”,如下所示。
<configuration>
//Here you have to set the path where you want HBase to store its files.
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
//Here you have to set the path where you want HBase to store its built in zookeeper files.
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>
到此,HBase的安装和配置部分就顺利完成了。我们可以使用 HBase的 bin 文件夹中提供的start-hbase.sh脚本来启动HBase。为此,打开 HBase 主文件夹并运行 HBase 启动脚本,如下所示。
$cd /usr/local/HBase/bin $./start-hbase.sh
如果一切顺利,当您尝试运行 HBase 启动脚本时,它会提示您一条消息说 HBase 已启动。
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.out
伪分布式方式安装HBase
现在让我们检查一下 HBase 是如何以伪分布式模式安装的。
配置 HBase
在继续使用 HBase 之前,请在本地系统或远程系统上配置 Hadoop 和 HDFS,并确保它们正在运行。如果 HBase 正在运行,请停止它。
hbase-site.xml
编辑 hbase-site.xml 文件以添加以下属性。
<property> <name>hbase.cluster.distributed</name> <value>true</value> </property>
它将提到应该以哪种模式运行 HBase。在来自本地文件系统的同一个文件中,使用 hdfs://// URI 语法更改 hbase.rootdir,即您的 HDFS 实例地址。我们在本地主机的 8030 端口运行 HDFS。
<property> <name>hbase.rootdir</name> <value>hdfs://localhost:8030/hbase</value> </property>
启动 HBase
配置完成后,浏览到 HBase 主文件夹并使用以下命令启动 HBase。
$cd /usr/local/HBase $bin/start-hbase.sh
注意:在启动 HBase 之前,请确保 Hadoop 正在运行。
检查 HDFS 中的 HBase 目录
HBase 在 HDFS 中创建其目录。要查看创建的目录,请浏览到 Hadoop bin 并键入以下命令。
$ ./bin/hadoop fs -ls /hbase
如果一切顺利,它将为您提供以下输出。
Found 7 items drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data -rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id -rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALs
启动和停止 Master
使用“local-master-backup.sh”最多可以启动 10 个服务器。打开HBase的home文件夹,master执行如下命令启动。
$ ./bin/local-master-backup.sh 2 4
要杀死备份主服务器,您需要其进程 ID,该 ID 将存储在名为“/tmp/hbase-USER-X-master.pid”的文件中。您可以使用以下命令终止备份主服务器。
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9
启动和停止 RegionServers
您可以使用以下命令从单个系统运行多个区域服务器。
$ .bin/local-regionservers.sh start 2 3
要停止区域服务器,请使用以下命令。
$ .bin/local-regionservers.sh stop 3
启动 HBaseShell
成功安装HBase后,就可以启动HBase Shell了。下面给出了启动 HBase shell 所要遵循的步骤序列。打开终端,以超级用户身份登录。
启动 Hadoop 文件系统
浏览 Hadoop home sbin 文件夹并启动 Hadoop 文件系统,如下所示。
$cd $HADOOP_HOME/sbin $start-all.sh
启动 HBase
浏览 HBase 根目录 bin 文件夹并启动 HBase。
$cd /usr/local/HBase $./bin/start-hbase.sh
启动 HBase 主服务器
这将是相同的目录。如下图启动。
$./bin/local-master-backup.sh start 2 (number signifies specific server.)
起始区域
启动区域服务器,如下所示。
$./bin/./local-regionservers.sh start 3
启动 HBase Shell
您可以使用以下命令启动 HBase shell。
$cd bin $./hbase shell
这将为您提供 HBase Shell 提示,如下所示。
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14 18:26:29 PST 2014 hbase(main):001:0>
HBase 网页界面
要访问 HBase 的 Web 界面,请在浏览器中键入以下 URL。
http://localhost:60010
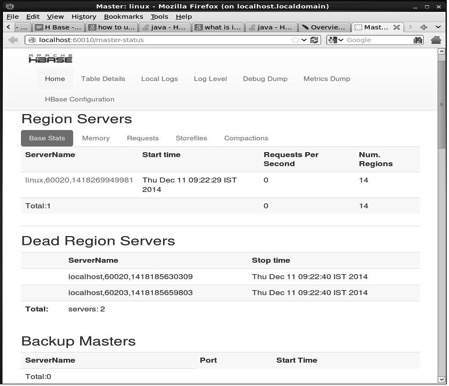
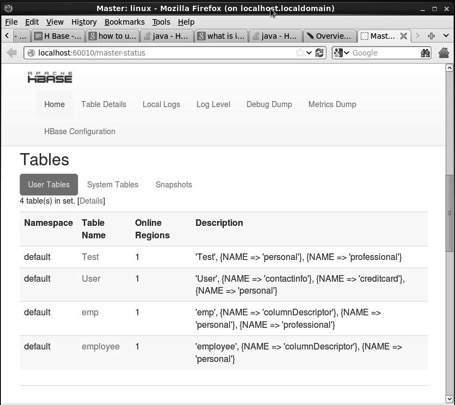
此界面列出了您当前运行的 Region 服务器、备份 master 和 HBase 表。
HBase 区域服务器和备份主服务器
HBase 表
设置 Java 环境
我们也可以使用 Java 库与 HBase 通信,但在使用 Java API 访问 HBase 之前,您需要为这些库设置类路径。
设置类路径
在继续编程之前,将类路径设置为.bashrc文件中的HBase 库。在任何编辑器中打开.bashrc,如下所示。
$ gedit ~/.bashrc
在其中设置 HBase 库(HBase 中的 lib 文件夹)的类路径,如下所示。
export CLASSPATH = $CLASSPATH://home/hadoop/hbase/lib/*
这是为了防止在使用 java API 访问 HBase 时出现“找不到类”异常。
HBase – 外壳
本章介绍如何启动 HBase 附带的 HBase 交互式 shell。
HBase 外壳
HBase 包含一个 shell,您可以使用它与 HBase 进行通信。HBase 使用 Hadoop 文件系统来存储其数据。它将有一个主服务器和区域服务器。数据存储将采用区域(表)的形式。这些区域将被拆分并存储在区域服务器中。
主服务器管理这些区域服务器,所有这些任务都在 HDFS 上进行。下面给出了 HBase Shell 支持的一些命令。
一般命令
-
status – 提供 HBase 的状态,例如,服务器数量。
-
version – 提供正在使用的 HBase 的版本。
-
table_help – 为表参考命令提供帮助。
-
whoami – 提供有关用户的信息。
数据定义语言
这些是对 HBase 中的表进行操作的命令。
-
create – 创建一个表。
-
list – 列出 HBase 中的所有表。
-
disable – 禁用表。
-
is_disabled – 验证表是否被禁用。
-
enable – 启用表。
-
is_enabled – 验证表是否已启用。
-
describe – 提供表的描述。
-
改变–改变一个表。
-
存在– 验证表是否存在。
-
drop – 从 HBase 中删除一个表。
-
drop_all – 删除与命令中给出的“regex”匹配的表。
-
Java Admin API – 在上述所有命令之前,Java 提供了一个 Admin API 以通过编程实现 DDL 功能。在org.apache.hadoop.hbase.client包下,HBaseAdmin 和 HTableDescriptor 是该包中提供 DDL 功能的两个重要类。
数据操作语言
-
put – 将单元格值放在特定表中指定行的指定列中。
-
get – 获取行或单元格的内容。
-
delete – 删除表格中的单元格值。
-
deleteall – 删除给定行中的所有单元格。
-
scan – 扫描并返回表数据。
-
count – 计算并返回表中的行数。
-
truncate – 禁用、删除和重新创建指定的表。
-
Java 客户端 API – 在上述所有命令之前,Java在 org.apache.hadoop.hbase.client 包下提供了一个客户端 API,以通过编程实现 DML 功能、CRUD(创建检索更新删除)操作等。HTable Put和Get是这个包中的重要类。
启动 HBase Shell
要访问 HBase shell,您必须导航到 HBase 主文件夹。
cd /usr/localhost/ cd Hbase
您可以使用“hbase shell”命令启动 HBase 交互式 shell ,如下所示。
./bin/hbase shell
如果您在系统中成功安装了 HBase,那么它会为您提供 HBase shell 提示,如下所示。
HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.94.23, rf42302b28aceaab773b15f234aa8718fff7eea3c, Wed Aug 27 00:54:09 UTC 2014 hbase(main):001:0>
要随时退出交互式 shell 命令,请键入 exit 或使用 <ctrl+c>。在继续之前检查外壳的功能。为此,请使用list命令。List是用来获取HBase中所有表的列表的命令。首先,使用此命令验证系统中 HBase 的安装和配置,如下所示。
hbase(main):001:0> list
当您键入此命令时,它会为您提供以下输出。
hbase(main):001:0> list TABLE
HBase – 一般命令
HBase 中的通用命令是 status、version、table_help 和 whoami。本章解释了这些命令。
地位
此命令返回系统状态,包括系统上运行的服务器的详细信息。其语法如下:
hbase(main):009:0> status
如果执行此命令,它将返回以下输出。
hbase(main):009:0> status 3 servers, 0 dead, 1.3333 average load
版本
此命令返回系统中使用的 HBase 版本。其语法如下:
hbase(main):010:0> version
如果执行此命令,它将返回以下输出。
hbase(main):009:0> version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14 18:26:29 PST 2014
表帮助
此命令将指导您使用什么以及如何使用表引用命令。下面给出了使用此命令的语法。
hbase(main):02:0> table_help
当您使用此命令时,它会显示与表相关的命令的帮助主题。下面给出的是这个命令的部分输出。
hbase(main):002:0> table_help Help for table-reference commands. You can either create a table via 'create' and then manipulate the table via commands like 'put', 'get', etc. See the standard help information for how to use each of these commands. However, as of 0.96, you can also get a reference to a table, on which you can invoke commands. For instance, you can get create a table and keep around a reference to it via: hbase> t = create 't', 'cf'…...
我是谁
此命令返回 HBase 的用户详细信息。如果执行此命令,则返回当前 HBase 用户,如下所示。
hbase(main):008:0> whoami hadoop (auth:SIMPLE) groups: hadoop
HBase – 管理 API
HBase 是用java 编写的,因此它提供了java API 来与HBase 进行通信。Java API 是与 HBase 通信的最快方式。下面给出了引用的 java Admin API,它涵盖了用于管理表的任务。
类 HBaseAdmin
HBaseAdmin是代表 Admin 的类。这个类属于org.apache.hadoop.hbase.client包。使用此类,您可以执行管理员的任务。您可以使用Connection.getAdmin()方法获取 Admin 的实例。
方法和说明
| S.No. | 方法和说明 |
|---|---|
| 1 |
void createTable(HTableDescriptor desc) 创建一个新表。 |
| 2 |
void createTable(HTableDescriptor desc, byte[][] splitKeys) 使用由指定拆分键定义的一组初始空区域创建一个新表。 |
| 3 |
void deleteColumn(byte[] tableName, String columnName) 从表中删除一列。 |
| 4 |
void deleteColumn(String tableName, String columnName) 从表中删除一列。 |
| 5 |
void deleteTable(String tableName) 删除一个表。 |
类描述符
此类包含有关 HBase 表的详细信息,例如:
- 所有列族的描述符,
- 如果表是目录表,
- 如果表是只读的,
- 内存存储的最大大小,
- 当区域分裂应该发生时,
- 与之相关的协处理器等。
构造函数
| S.No. | 构造函数和摘要 |
|---|---|
| 1 |
HTableDescriptor(TableName name)
|
方法和说明
| S.No. | 方法和说明 |
|---|---|
| 1 |
HTableDescriptor addFamily(HColumnDescriptor family) 将列族添加到给定的描述符 |
HBase – 创建表
使用 HBase Shell 创建表
您可以使用create命令创建表,这里您必须指定表名和列族名称。在 HBase shell 中创建表的语法如下所示。
create ‘<table name>’,’<column family>’
例子
下面给出了一个名为 emp 的表的示例模式。它有两个列族:“个人数据”和“专业数据”。
| Row key | 个人资料 | 专业资料 |
|---|---|---|
您可以在 HBase shell 中创建此表,如下所示。
hbase(main):002:0> create 'emp', 'personal data', 'professional data'
它将为您提供以下输出。
0 row(s) in 1.1300 seconds => Hbase::Table - emp
确认
您可以使用如下所示的list命令验证是否创建了表。在这里您可以观察创建的 emp 表。
hbase(main):002:0> list TABLE emp 2 row(s) in 0.0340 seconds
使用 java API 创建表
您可以使用HBaseAdmin类的createTable()方法在 HBase 中创建表。这个类属于org.apache.hadoop.hbase.client包。下面给出了使用 java API 在 HBase 中创建表的步骤。
Step1:实例化HBaseAdmin
该类需要 Configuration 对象作为参数,因此首先实例化 Configuration 类并将此实例传递给 HBaseAdmin。
Configuration conf = HBaseConfiguration.create(); HBaseAdmin admin = new HBaseAdmin(conf);
Step2:创建TableDescriptor
HTableDescriptor是一个属于org.apache.hadoop.hbase类的类。这个类就像一个表名和列族的容器。
//creating table descriptor
HTableDescriptor table = new HTableDescriptor(toBytes("Table name"));
//creating column family descriptor
HColumnDescriptor family = new HColumnDescriptor(toBytes("column family"));
//adding coloumn family to HTable
table.addFamily(family);
第 3 步:通过管理员执行
使用HBaseAdmin类的createTable()方法,可以在 Admin 模式下执行创建的表。
admin.createTable(table);
下面给出了通过管理员创建表的完整程序。
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.conf.Configuration;
public class CreateTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration con = HBaseConfiguration.create();
// Instantiating HbaseAdmin class
HBaseAdmin admin = new HBaseAdmin(con);
// Instantiating table descriptor class
HTableDescriptor tableDescriptor = new
HTableDescriptor(TableName.valueOf("emp"));
// Adding column families to table descriptor
tableDescriptor.addFamily(new HColumnDescriptor("personal"));
tableDescriptor.addFamily(new HColumnDescriptor("professional"));
// Execute the table through admin
admin.createTable(tableDescriptor);
System.out.println(" Table created ");
}
}
编译并执行上述程序,如下所示。
$javac CreateTable.java $java CreateTable
以下应该是输出:
Table created
HBase – 列表
使用 HBase Shell 列出表
list 是用于列出 HBase 中所有表的命令。下面给出了 list 命令的语法。
hbase(main):001:0 > list
当您键入此命令并在 HBase 提示符下执行时,它将显示 HBase 中所有表的列表,如下所示。
hbase(main):001:0> list TABLE emp
在这里您可以观察到一个名为 emp 的表。
使用 Java API 列出表
按照下面给出的步骤使用 java API 从 HBase 获取表列表。
第1步
你有一个方法叫listTables()在类HBaseAdmin让所有的HBase表的列表。此方法返回一个HTableDescriptor对象数组。
//creating a configuration object Configuration conf = HBaseConfiguration.create(); //Creating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf); //Getting all the list of tables using HBaseAdmin object HTableDescriptor[] tableDescriptor = admin.listTables();
第2步
您可以使用HTableDescriptor类的长度变量获取HTableDescriptor[]数组的长度。使用getNameAsString()方法从此对象获取表的名称。使用这些运行“for”循环并获取 HBase 中的表列表。
下面给出的是使用 Java API 列出 HBase 中所有表的程序。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ListTables {
public static void main(String args[])throws MasterNotRunningException, IOException{
// Instantiating a configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();
// printing all the table names.
for (int i=0; i<tableDescriptor.length;i++ ){
System.out.println(tableDescriptor[i].getNameAsString());
}
}
}
编译并执行上述程序,如下所示。
$javac ListTables.java $java ListTables
以下应该是输出:
User emp
HBase – 禁用表
使用 HBase Shell 禁用表
要删除表或更改其设置,您需要先使用 disable 命令禁用该表。您可以使用 enable 命令重新启用它。
下面给出了禁用表的语法:
disable ‘emp’
例子
下面给出的示例显示了如何禁用表。
hbase(main):025:0> disable 'emp' 0 row(s) in 1.2760 seconds
确认
禁用该表后,您仍然可以通过list和exists命令感知它的存在。你不能扫描它。它会给你以下错误。
hbase(main):028:0> scan 'emp' ROW COLUMN &plus CELL ERROR: emp is disabled.
被禁用
该命令用于查找表是否被禁用。其语法如下。
hbase> is_disabled 'table name'
以下示例验证名为 emp 的表是否已禁用。如果它被禁用,它会返回真,如果不是,它会返回假。
hbase(main):031:0> is_disabled 'emp' true 0 row(s) in 0.0440 seconds
禁用所有
此命令用于禁用与给定正则表达式匹配的所有表。disable_all命令的语法如下所示。
hbase> disable_all 'r.*'
假设HBase中有5张表,分别是raja、rajani、rajendra、rajesh和raju。以下代码将禁用所有以raj开头的表。
hbase(main):002:07> disable_all 'raj.*' raja rajani rajendra rajesh raju Disable the above 5 tables (y/n)? y 5 tables successfully disabled
使用 Java API 禁用表
要验证表是否已禁用,请使用isTableDisabled()方法,而要禁用表,请使用disableTable()方法。这些方法属于HBaseAdmin类。按照下面给出的步骤禁用表。
第1步
实例化HBaseAdmin类,如下所示。
// Creating configuration object Configuration conf = HBaseConfiguration.create(); // Creating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf);
第2步
使用isTableDisabled()方法验证表是否被禁用,如下所示。
Boolean b = admin.isTableDisabled("emp");
第 3 步
如果表未禁用,请禁用它,如下所示。
if(!b){
admin.disableTable("emp");
System.out.println("Table disabled");
}
下面给出了验证表是否被禁用的完整程序;如果没有,如何禁用它。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DisableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying weather the table is disabled
Boolean bool = admin.isTableDisabled("emp");
System.out.println(bool);
// Disabling the table using HBaseAdmin object
if(!bool){
admin.disableTable("emp");
System.out.println("Table disabled");
}
}
}
编译并执行上述程序,如下所示。
$javac DisableTable.java $java DsiableTable
以下应该是输出:
false Table disabled
HBase – 启用表
使用 HBase Shell 启用表
启用表的语法:
enable ‘emp’
例子
下面给出了一个启用表格的示例。
hbase(main):005:0> enable 'emp' 0 row(s) in 0.4580 seconds
确认
启用该表后,对其进行扫描。如果您可以看到架构,则您的表已成功启用。
hbase(main):006:0> scan 'emp' ROW COLUMN &plus CELL 1 column = personal data:city, timestamp = 1417516501, value = hyderabad 1 column = personal data:name, timestamp = 1417525058, value = ramu 1 column = professional data:designation, timestamp = 1417532601, value = manager 1 column = professional data:salary, timestamp = 1417524244109, value = 50000 2 column = personal data:city, timestamp = 1417524574905, value = chennai 2 column = personal data:name, timestamp = 1417524556125, value = ravi 2 column = professional data:designation, timestamp = 14175292204, value = sr:engg 2 column = professional data:salary, timestamp = 1417524604221, value = 30000 3 column = personal data:city, timestamp = 1417524681780, value = delhi 3 column = personal data:name, timestamp = 1417524672067, value = rajesh 3 column = professional data:designation, timestamp = 14175246987, value = jr:engg 3 column = professional data:salary, timestamp = 1417524702514, value = 25000 3 row(s) in 0.0400 seconds
is_enabled
此命令用于查找表是否已启用。其语法如下:
hbase> is_enabled 'table name'
以下代码验证名为emp的表是否已启用。如果启用,它将返回 true,否则,它将返回 false。
hbase(main):031:0> is_enabled 'emp' true 0 row(s) in 0.0440 seconds
使用 Java API 启用表
验证表是否启用,使用isTableEnabled()方法;并启用表,使用enableTable()方法。这些方法属于HBaseAdmin类。按照下面给出的步骤启用表。
第1步
实例化HBaseAdmin类,如下所示。
// Creating configuration object Configuration conf = HBaseConfiguration.create(); // Creating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf);
第2步
使用isTableEnabled()方法验证表是否已启用,如下所示。
Boolean bool = admin.isTableEnabled("emp");
第 3 步
如果表未禁用,请禁用它,如下所示。
if(!bool){
admin.enableTable("emp");
System.out.println("Table enabled");
}
下面给出了完整的程序,用于验证该表是否已启用,如果未启用,则如何启用它。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class EnableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying whether the table is disabled
Boolean bool = admin.isTableEnabled("emp");
System.out.println(bool);
// Enabling the table using HBaseAdmin object
if(!bool){
admin.enableTable("emp");
System.out.println("Table Enabled");
}
}
}
编译并执行上述程序,如下所示。
$javac EnableTable.java $java EnableTable
以下应该是输出:
false Table Enabled
HBase – 描述和更改
描述
此命令返回表的描述。其语法如下:
hbase> describe 'table name'
下面给出的是emp表上的 describe 命令的输出。
hbase(main):006:0> describe 'emp'
DESCRIPTION
ENABLED
'emp', {NAME ⇒ 'READONLY', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER
⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒ 'NONE', VERSIONS ⇒
'1', TTL true
⇒ 'FOREVER', MIN_VERSIONS ⇒ '0', KEEP_DELETED_CELLS ⇒ 'false',
BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME
⇒ 'personal
data', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW',
REPLICATION_SCOPE ⇒ '0', VERSIONS ⇒ '5', COMPRESSION ⇒ 'NONE',
MIN_VERSIONS ⇒ '0', TTL
⇒ 'FOREVER', KEEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536',
IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'professional
data', DATA_BLO
CK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0',
VERSIONS ⇒ '1', COMPRESSION ⇒ 'NONE', MIN_VERSIONS ⇒ '0', TTL ⇒
'FOREVER', K
EEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒
'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'table_att_unset',
DATA_BLOCK_ENCODING ⇒ 'NO
NE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒
'NONE', VERSIONS ⇒ '1', TTL ⇒ 'FOREVER', MIN_VERSIONS ⇒ '0',
KEEP_DELETED_CELLS
⇒ 'false', BLOCKSIZE ⇒ '6
改变
Alter 是用于更改现有表的命令。使用该命令,您可以更改列族的最大单元格数,设置和删除表范围运算符,以及从表中删除列族。
更改列族的最大单元格数
下面给出的是更改列族的最大单元格数的语法。
hbase> alter 't1', NAME ⇒ 'f1', VERSIONS ⇒ 5
在以下示例中,最大单元格数设置为 5。
hbase(main):003:0> alter 'emp', NAME ⇒ 'personal data', VERSIONS ⇒ 5 Updating all regions with the new schema... 0/1 regions updated. 1/1 regions updated. Done. 0 row(s) in 2.3050 seconds
表范围运算符
使用 alter,您可以设置和删除表范围运算符,例如 MAX_FILESIZE、READONLY、MEMSTORE_FLUSHSIZE、DEFERRED_LOG_FLUSH 等。
设置只读
下面给出的是使表只读的语法。
hbase>alter 't1', READONLY(option)
在以下示例中,我们将emp表设为只读。
hbase(main):006:0> alter 'emp', READONLY Updating all regions with the new schema... 0/1 regions updated. 1/1 regions updated. Done. 0 row(s) in 2.2140 seconds
删除表范围运算符
我们还可以删除表范围运算符。下面给出的是从 emp 表中删除 ‘MAX_FILESIZE’ 的语法。
hbase> alter 't1', METHOD ⇒ 'table_att_unset', NAME ⇒ 'MAX_FILESIZE'
删除列族
使用alter,您还可以删除列族。下面给出了使用alter 删除列族的语法。
hbase> alter ‘ table name ’, ‘delete’ ⇒ ‘ column family ’
下面给出了从“emp”表中删除列族的示例。
假设HBase 中有一个名为employee 的表。它包含以下数据:
hbase(main):006:0> scan 'employee' ROW COLUMN+CELL row1 column = personal:city, timestamp = 1418193767, value = hyderabad row1 column = personal:name, timestamp = 1418193806767, value = raju row1 column = professional:designation, timestamp = 1418193767, value = manager row1 column = professional:salary, timestamp = 1418193806767, value = 50000 1 row(s) in 0.0160 seconds
现在让我们使用alter 命令删除名为professional的列族。
hbase(main):007:0> alter 'employee','delete'⇒'professional' Updating all regions with the new schema... 0/1 regions updated. 1/1 regions updated. Done. 0 row(s) in 2.2380 seconds
现在验证更改后的表中的数据。观察列族 ‘professional’ 已不复存在,因为我们已将其删除。
hbase(main):003:0> scan 'employee' ROW COLUMN &plus CELL row1 column = personal:city, timestamp = 14181936767, value = hyderabad row1 column = personal:name, timestamp = 1418193806767, value = raju 1 row(s) in 0.0830 seconds
使用 Java API 添加列族
您可以使用该方法的列族添加到表addColumn()的HBAseAdmin类。按照下面给出的步骤将列族添加到表中。
第1步
实例化HBaseAdmin类。
// Instantiating configuration object Configuration conf = HBaseConfiguration.create(); // Instantiating HBaseAdmin class HBaseAdmin admin = new HBaseAdmin(conf);
第2步
所述addColumn()方法需要一个表名和的目的HColumnDescriptor类。因此实例化HColumnDescriptor类。HColumnDescriptor的构造函数反过来需要一个要添加的列族名称。在这里,我们将一个名为“contactDetails”的列族添加到现有的“employee”表中。
// Instantiating columnDescriptor object
HColumnDescriptor columnDescriptor = new
HColumnDescriptor("contactDetails");
第 3 步
使用addColumn方法添加列族。将表名和HColumnDescriptor类对象作为参数传递给此方法。
// Adding column family
admin.addColumn("employee", new HColumnDescriptor("columnDescriptor"));
下面给出了将列族添加到现有表的完整程序。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class AddColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Instantiating columnDescriptor class
HColumnDescriptor columnDescriptor = new HColumnDescriptor("contactDetails");
// Adding column family
admin.addColumn("employee", columnDescriptor);
System.out.println("coloumn added");
}
}
编译并执行上述程序,如下所示。
$javac AddColumn.java $java AddColumn
仅当您在“ .bashrc ”中设置了类路径时,上述编译才有效。如果还没有,请按照下面给出的过程编译您的 .java 文件。
//if "/home/home/hadoop/hbase " is your Hbase home folder then. $javac -cp /home/hadoop/hbase/lib/*: Demo.java
如果一切顺利,它将产生以下输出:
column added
使用 Java API 删除列族
您可以使用该方法从表中删除列族deleteColumn()的HBAseAdmin类。按照下面给出的步骤将列族添加到表中。
第1步
实例化HBaseAdmin类。
// Instantiating configuration object Configuration conf = HBaseConfiguration.create(); // Instantiating HBaseAdmin class HBaseAdmin admin = new HBaseAdmin(conf);
第2步
使用deleteColumn()方法添加列族。将表名和列族名作为参数传递给该方法。
// Deleting column family
admin.deleteColumn("employee", "contactDetails");
下面给出了从现有表中删除列族的完整程序。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Deleting a column family
admin.deleteColumn("employee","contactDetails");
System.out.println("coloumn deleted");
}
}
编译并执行上述程序,如下所示。
$javac DeleteColumn.java $java DeleteColumn
以下应该是输出:
column deleted
HBase – 存在
使用 HBase Shell 的表的存在
您可以使用exists命令验证表是否存在。以下示例显示了如何使用此命令。
hbase(main):024:0> exists 'emp' Table emp does exist 0 row(s) in 0.0750 seconds ================================================================== hbase(main):015:0> exists 'student' Table student does not exist 0 row(s) in 0.0480 seconds
使用 Java API 验证表的存在
您可以使用HBaseAdmin类的tableExists()方法验证 HBase 中表的存在。按照下面给出的步骤验证 HBase 中表的存在。
第1步
Instantiate the HBaseAdimn class // Instantiating configuration object Configuration conf = HBaseConfiguration.create(); // Instantiating HBaseAdmin class HBaseAdmin admin = new HBaseAdmin(conf);
第2步
使用tableExists( )方法验证表的存在。
下面给出的是使用 java API 测试 HBase 中表是否存在的 java 程序。
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class TableExists{
public static void main(String args[])throws IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying the existance of the table
boolean bool = admin.tableExists("emp");
System.out.println( bool);
}
}
编译并执行上述程序,如下所示。
$javac TableExists.java $java TableExists
以下应该是输出:
true
HBase – 删除表
使用 HBase Shell 删除表
使用drop命令,您可以删除表。在删除表之前,您必须禁用它。
hbase(main):018:0> disable 'emp' 0 row(s) in 1.4580 seconds hbase(main):019:0> drop 'emp' 0 row(s) in 0.3060 seconds
使用exists 命令验证表是否被删除。
hbase(main):020:07gt; exists 'emp' Table emp does not exist 0 row(s) in 0.0730 seconds
drop_all
此命令用于删除与命令中给出的“regex”匹配的表。其语法如下:
hbase> drop_all ‘t.*’
注意:在删除表之前,您必须禁用它。
例子
假设有名为 raja、rajani、rajendra、rajesh 和 raju 的表。
hbase(main):017:0> list TABLE raja rajani rajendra rajesh raju 9 row(s) in 0.0270 seconds
所有这些表都以字母raj开头。首先,让我们使用disable_all命令禁用所有这些表,如下所示。
hbase(main):002:0> disable_all 'raj.*' raja rajani rajendra rajesh raju Disable the above 5 tables (y/n)? y 5 tables successfully disabled
现在您可以使用如下所示的drop_all命令删除所有这些。
hbase(main):018:0> drop_all 'raj.*' raja rajani rajendra rajesh raju Drop the above 5 tables (y/n)? y 5 tables successfully dropped
使用 Java API 删除表
您可以使用HBaseAdmin类中的deleteTable()方法删除表。按照下面给出的步骤使用 java API 删除表。
第1步
实例化 HBaseAdmin 类。
// creating a configuration object Configuration conf = HBaseConfiguration.create(); // Creating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf);
第2步
使用HBaseAdmin类的disableTable()方法禁用表。
admin.disableTable("emp1");
第 3 步
现在使用HBaseAdmin类的deleteTable()方法删除表。
admin.deleteTable("emp12");
下面给出了在 HBase 中删除表的完整 java 程序。
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// disabling table named emp
admin.disableTable("emp12");
// Deleting emp
admin.deleteTable("emp12");
System.out.println("Table deleted");
}
}
编译并执行上述程序,如下所示。
$javac DeleteTable.java $java DeleteTable
以下应该是输出:
Table deleted
HBase – 关闭
出口
您可以通过键入exit命令退出 shell 。
hbase(main):021:0> exit
停止 HBase
要停止 HBase,请浏览到 HBase 主文件夹并键入以下命令。
./bin/stop-hbase.sh
使用 Java API 停止 HBase
您可以使用HBaseAdmin类的shutdown()方法关闭HBase 。请按照以下步骤关闭 HBase:
第1步
实例化 HbaseAdmin 类。
// Instantiating configuration object Configuration conf = HBaseConfiguration.create(); // Instantiating HBaseAdmin object HBaseAdmin admin = new HBaseAdmin(conf);
第2步
使用HBaseAdmin类的shutdown()方法关闭 HBase 。
admin.shutdown();
下面给出了停止 HBase 的程序。
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ShutDownHbase{
public static void main(String args[])throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Shutting down HBase
System.out.println("Shutting down hbase");
admin.shutdown();
}
}
编译并执行上述程序,如下所示。
$javac ShutDownHbase.java $java ShutDownHbase
以下应该是输出:
Shutting down hbase
HBase – 客户端 API
本章介绍 HBase 的 Java 客户端 API,用于对 HBase 表执行CRUD操作。HBase 是用 Java 编写的,并有一个 Java Native API。因此,它提供了对数据操作语言 (DML) 的编程访问。
类 HBase 配置
将 HBase 配置文件添加到配置中。这个类属于org.apache.hadoop.hbase包。
方法和说明
| S.No. | 方法和说明 |
|---|---|
| 1 |
static org.apache.hadoop.conf.Configuration create() 此方法使用 HBase 资源创建配置。 |
类 HTable
HTable 是一个 HBase 内部类,代表一个 HBase 表。它是 table 的一种实现,用于与单个 HBase 表进行通信。这个类属于org.apache.hadoop.hbase.client类。
构造函数
| S.No. | 构造函数和描述 |
|---|---|
| 1 |
HTable() |
| 2 |
HTable(TableName tableName, ClusterConnection connection, ExecutorService pool) 使用此构造函数,您可以创建一个对象来访问 HBase 表。 |
方法和说明
| S.No. | 方法和说明 |
|---|---|
| 1 |
void close() 释放HTable的所有资源。 |
| 2 |
void delete(Delete delete) 删除指定的单元格/行。 |
| 3 |
boolean exists(Get get) 使用此方法,您可以测试表中列是否存在,如 Get 指定的那样。 |
| 4 |
Result get(Get get) 从给定行中检索某些单元格。 |
| 5 |
org.apache.hadoop.conf.Configuration getConfiguration() 返回此实例使用的 Configuration 对象。 |
| 6 |
TableName getName() 返回此表的表名实例。 |
| 7 |
HTableDescriptor getTableDescriptor() 返回此表的表描述符。 |
| 8 |
byte[] getTableName() 返回此表的名称。 |
| 9 |
void put(Put put) 使用此方法,您可以向表中插入数据。 |
类放置
此类用于对单行执行 Put 操作。它属于org.apache.hadoop.hbase.client包。
构造函数
| S.No. | 构造函数和描述 |
|---|---|
| 1 |
Put(byte[] row) 使用此构造函数,您可以为指定行创建 Put 操作。 |
| 2 |
Put(byte[] rowArray, int rowOffset, int rowLength) 使用此构造函数,您可以复制传入的行键以保留本地。 |
| 3 |
Put(byte[] rowArray, int rowOffset, int rowLength, long ts) 使用此构造函数,您可以复制传入的行键以保留本地。 |
| 4 |
Put(byte[] row, long ts) 使用这个构造函数,我们可以使用给定的时间戳为指定的行创建一个 Put 操作。 |
方法
| S.No. | 方法和说明 |
|---|---|
| 1 |
Put add(byte[] family, byte[] qualifier, byte[] value) 将指定的列和值添加到此 Put 操作。 |
| 2 |
Put add(byte[] family, byte[] qualifier, long ts, byte[] value) 将指定的列和值(使用指定的时间戳作为其版本)添加到此 Put 操作。 |
| 3 |
Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) 将指定的列和值(使用指定的时间戳作为其版本)添加到此 Put 操作。 |
| 4 |
Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) 将指定的列和值(使用指定的时间戳作为其版本)添加到此 Put 操作。 |
获取类
此类用于对单行执行 Get 操作。这个类属于org.apache.hadoop.hbase.client包。
构造函数
| S.No. | 构造函数和描述 |
|---|---|
| 1 |
Get(byte[] row) 使用此构造函数,您可以为指定行创建 Get 操作。 |
| 2 | 得到(得到得到) |
方法
| S.No. | 方法和说明 |
|---|---|
| 1 |
Get addColumn(byte[] family, byte[] qualifier) 从具有指定限定符的特定系列中检索列。 |
| 2 |
Get addFamily(byte[] family) 从指定的系列中检索所有列。 |
班级删除
该类用于对单行执行删除操作。要删除整行,请使用要删除的行实例化一个 Delete 对象。这个类属于org.apache.hadoop.hbase.client包。
构造函数
| S.No. | 构造函数和描述 |
|---|---|
| 1 |
Delete(byte[] row) 为指定行创建删除操作。 |
| 2 |
Delete(byte[] rowArray, int rowOffset, int rowLength) 为指定的行和时间戳创建删除操作。 |
| 3 |
Delete(byte[] rowArray, int rowOffset, int rowLength, long ts) 为指定的行和时间戳创建删除操作。 |
| 4 |
Delete(byte[] row, long timestamp) 为指定的行和时间戳创建删除操作。 |
方法
| S.No. | 方法和说明 |
|---|---|
| 1 |
Delete addColumn(byte[] family, byte[] qualifier) 删除指定列的最新版本。 |
| 2 |
Delete addColumns(byte[] family, byte[] qualifier, long timestamp) 删除时间戳小于或等于指定时间戳的指定列的所有版本。 |
| 3 |
Delete addFamily(byte[] family) 删除指定系列的所有列的所有版本。 |
| 4 |
Delete addFamily(byte[] family, long timestamp) 删除指定族中时间戳小于或等于指定时间戳的所有列。 |
班级成绩
此类用于获取 Get 或 Scan 查询的单行结果。
构造函数
| S.No. | 构造函数 |
|---|---|
| 1 |
Result() 使用此构造函数,您可以创建一个没有 KeyValue 负载的空 Result;如果调用原始 Cells(),则返回 null。 |
方法
| S.No. | 方法和说明 |
|---|---|
| 1 |
byte[] getValue(byte[] family, byte[] qualifier) 该方法用于获取指定列的最新版本。 |
| 2 |
byte[] getRow() 此方法用于检索与创建此 Result 的行对应的行键。 |
HBase – 创建数据
使用 HBase Shell 插入数据
本章演示如何在 HBase 表中创建数据。要在 HBase 表中创建数据,使用以下命令和方法:
-
放置命令,
-
Put类的add()方法,以及
-
HTable类的put()方法。
例如,我们将在 HBase 中创建下表。
使用put命令,您可以向表中插入行。其语法如下:
put ’<table name>’,’row1’,’<colfamily:colname>’,’<value>’
插入第一行
让我们将第一行值插入到 emp 表中,如下所示。
hbase(main):005:0> put 'emp','1','personal data:name','raju' 0 row(s) in 0.6600 seconds hbase(main):006:0> put 'emp','1','personal data:city','hyderabad' 0 row(s) in 0.0410 seconds hbase(main):007:0> put 'emp','1','professional data:designation','manager' 0 row(s) in 0.0240 seconds hbase(main):007:0> put 'emp','1','professional data:salary','50000' 0 row(s) in 0.0240 seconds
以相同的方式使用 put 命令插入剩余的行。如果插入整个表,您将获得以下输出。
hbase(main):022:0> scan 'emp' ROW COLUMN+CELL 1 column=personal data:city, timestamp=1417524216501, value=hyderabad 1 column=personal data:name, timestamp=1417524185058, value=ramu 1 column=professional data:designation, timestamp=1417524232601, value=manager 1 column=professional data:salary, timestamp=1417524244109, value=50000 2 column=personal data:city, timestamp=1417524574905, value=chennai 2 column=personal data:name, timestamp=1417524556125, value=ravi 2 column=professional data:designation, timestamp=1417524592204, value=sr:engg 2 column=professional data:salary, timestamp=1417524604221, value=30000 3 column=personal data:city, timestamp=1417524681780, value=delhi 3 column=personal data:name, timestamp=1417524672067, value=rajesh 3 column=professional data:designation, timestamp=1417524693187, value=jr:engg 3 column=professional data:salary, timestamp=1417524702514, value=25000
使用 Java API 插入数据
您可以使用Put类的add()方法将数据插入到 Hbase 中。您可以使用HTable类的put()方法保存它。这些类属于org.apache.hadoop.hbase.client包。下面给出了在 HBase 表中创建数据的步骤。
第一步:实例化配置类
该配置类增加了HBase的配置文件,它的对象。您可以使用HbaseConfiguration类的create()方法创建配置对象,如下所示。
Configuration conf = HbaseConfiguration.create();
第二步:实例化HTable类
您有一个名为HTable的类,它是 HBase 中 Table 的实现。此类用于与单个 HBase 表进行通信。在实例化这个类时,它接受配置对象和表名作为参数。您可以实例化 HTable 类,如下所示。
HTable hTable = new HTable(conf, tableName);
第 3 步:实例化 PutClass
要将数据插入到 HBase 表中,需要使用add()方法及其变体。该方法属于Put,因此实例化 put 类。这个类需要你想要插入数据的行名,字符串格式。您可以实例化Put类,如下所示。
Put p = new Put(Bytes.toBytes("row1"));
第 4 步:插入数据
Put类的add()方法用于插入数据。它需要 3 个字节的数组,分别表示列族、列限定符(列名)和要插入的值。使用 add() 方法将数据插入到 HBase 表中,如下所示。
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));
步骤 5:将数据保存在表中
插入所需的行后,通过将 put 实例添加到HTable 类的put()方法来保存更改,如下所示。
hTable.put(p);
第六步:关闭HTable实例
在 HBase Table 中创建数据后,使用close()方法关闭HTable实例,如下所示。
hTable.close();
下面给出了在 HBase 表中创建数据的完整程序。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
// accepts a row name.
Put p = new Put(Bytes.toBytes("row1"));
// adding values using add() method
// accepts column family name, qualifier/row name ,value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("name"),Bytes.toBytes("raju"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("hyderabad"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("designation"),
Bytes.toBytes("manager"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("salary"),
Bytes.toBytes("50000"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data inserted");
// closing HTable
hTable.close();
}
}
编译并执行上述程序,如下所示。
$javac InsertData.java $java InsertData
以下应该是输出:
data inserted
HBase – 更新数据
使用 HBase Shell 更新数据
您可以使用put命令更新现有单元格值。为此,只需遵循相同的语法并提及您的新值,如下所示。
put ‘table name’,’row ’,'Column family:column name',’new value’
新给定的值替换现有值,更新行。
例子
假设 HBase 中有一个名为emp的表,其中包含以下数据。
hbase(main):003:0> scan 'emp' ROW COLUMN &plus CELL row1 column = personal:name, timestamp = 1418051555, value = raju row1 column = personal:city, timestamp = 1418275907, value = Hyderabad row1 column = professional:designation, timestamp = 14180555,value = manager row1 column = professional:salary, timestamp = 1418035791555,value = 50000 1 row(s) in 0.0100 seconds
以下命令会将名为“Raju”的员工的城市值更新为德里。
hbase(main):002:0> put 'emp','row1','personal:city','Delhi' 0 row(s) in 0.0400 seconds
更新后的表格如下所示,您可以在其中观察到 Raju 市已更改为“德里”。
hbase(main):003:0> scan 'emp' ROW COLUMN &plus CELL row1 column = personal:name, timestamp = 1418035791555, value = raju row1 column = personal:city, timestamp = 1418274645907, value = Delhi row1 column = professional:designation, timestamp = 141857555,value = manager row1 column = professional:salary, timestamp = 1418039555, value = 50000 1 row(s) in 0.0100 seconds
使用 Java API 更新数据
您可以使用put()方法更新特定单元格中的数据。按照下面给出的步骤更新表格的现有单元格值。
步骤 1:实例化配置类
配置类将 HBase 配置文件添加到其对象中。您可以使用HbaseConfiguration类的create()方法创建配置对象,如下所示。
Configuration conf = HbaseConfiguration.create();
第二步:实例化HTable类
您有一个名为HTable的类,它是 HBase 中 Table 的实现。此类用于与单个 HBase 表进行通信。在实例化这个类时,它接受配置对象和表名作为参数。您可以实例化 HTable 类,如下所示。
HTable hTable = new HTable(conf, tableName);
第 3 步:实例化 Put 类
要将数据插入 HBase 表,使用add()方法及其变体。该方法属于Put,因此实例化put类。这个类需要你想要插入数据的行名,字符串格式。您可以实例化Put类,如下所示。
Put p = new Put(Bytes.toBytes("row1"));
步骤 4:更新现有单元格
Put类的add()方法用于插入数据。它需要 3 个字节的数组,分别表示列族、列限定符(列名)和要插入的值。使用add()方法将数据插入到 HBase 表中,如下所示。
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));
步骤 5:将数据保存在表中
插入所需的行后,通过将 put 实例添加到HTable 类的put()方法来保存更改,如下所示。
hTable.put(p);
第六步:关闭HTable实例
在 HBase Table 中创建数据后,使用 close() 方法关闭HTable实例,如下所示。
hTable.close();
下面给出了更新特定表中数据的完整程序。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class UpdateData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
//accepts a row name
Put p = new Put(Bytes.toBytes("row1"));
// Updating a cell value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data Updated");
// closing HTable
hTable.close();
}
}
编译并执行上述程序,如下所示。
$javac UpdateData.java $java UpdateData
以下应该是输出:
data Updated
HBase – 读取数据
使用 HBase Shell 读取数据
HTable类的get命令和get()方法用于从 HBase 中的表中读取数据。使用get命令,您可以一次获取一行数据。其语法如下:
get ’<table name>’,’row1’
例子
以下示例显示了如何使用 get 命令。让我们扫描emp表的第一行。
hbase(main):012:0> get 'emp', '1' COLUMN CELL personal : city timestamp = 1417521848375, value = hyderabad personal : name timestamp = 1417521785385, value = ramu professional: designation timestamp = 1417521885277, value = manager professional: salary timestamp = 1417521903862, value = 50000 4 row(s) in 0.0270 seconds
读取特定列
下面给出了使用get方法读取特定列的语法。
hbase> get 'table name', ‘rowid’, {COLUMN ⇒ ‘column family:column name ’}
例子
下面给出的是读取 HBase 表中特定列的示例。
hbase(main):015:0> get 'emp', 'row1', {COLUMN ⇒ 'personal:name'}
COLUMN CELL
personal:name timestamp = 1418035791555, value = raju
1 row(s) in 0.0080 seconds
使用 Java API 读取数据
要从 HBase 表中读取数据,请使用HTable 类的get()方法。此方法需要Get类的实例。按照下面给出的步骤从 HBase 表中检索数据。
步骤 1:实例化配置类
配置类将 HBase 配置文件添加到其对象中。您可以使用HbaseConfiguration类的create()方法创建配置对象,如下所示。
Configuration conf = HbaseConfiguration.create();
第二步:实例化HTable类
您有一个名为HTable的类,它是 HBase 中 Table 的实现。此类用于与单个 HBase 表进行通信。在实例化这个类时,它接受配置对象和表名作为参数。您可以实例化 HTable 类,如下所示。
HTable hTable = new HTable(conf, tableName);
第 3 步:实例化 Get 类
您可以使用HTable类的get()方法从 HBase 表中检索数据。此方法从给定行中提取单元格。它需要一个Get类对象作为参数。如下图创建。
Get get = new Get(toBytes("row1"));
第 4 步:读取数据
在检索数据时,您可以通过 id 获取单行,或通过一组行 id 获取一组行,或者扫描整个表或行的子集。
您可以使用Get类中的 add 方法变体来检索 HBase 表数据。
要从特定列族中获取特定列,请使用以下方法。
get.addFamily(personal)
要从特定列族中获取所有列,请使用以下方法。
get.addColumn(personal, name)
第 5 步:获取结果
通过将您的Get类实例传递给HTable类的 get 方法来获取结果。此方法返回Result类对象,该对象保存请求的结果。下面给出了get()方法的用法。
Result result = table.get(g);
步骤 6:从结果实例中读取值
的结果类提供的getValue()方法来从它的实例中读取的值。如下所示使用它从Result实例中读取值。
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));
下面给出了从 HBase 表中读取值的完整程序。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
public class RetriveData{
public static void main(String[] args) throws IOException, Exception{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating Get class
Get g = new Get(Bytes.toBytes("row1"));
// Reading the data
Result result = table.get(g);
// Reading values from Result class object
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));
// Printing the values
String name = Bytes.toString(value);
String city = Bytes.toString(value1);
System.out.println("name: " + name + " city: " + city);
}
}
编译并执行上述程序,如下所示。
$javac RetriveData.java $java RetriveData
以下应该是输出:
name: Raju city: Delhi
HBase – 删除数据
删除表格中的特定单元格
使用删除命令,您可以删除表格中的特定单元格。删除命令的语法如下:
delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’
例子
这是删除特定单元格的示例。在这里,我们正在删除工资。
hbase(main):006:0> delete 'emp', '1', 'personal data:city', 1417521848375 0 row(s) in 0.0060 seconds
删除表格中的所有单元格
使用“deleteall”命令,您可以删除一行中的所有单元格。下面给出的是 deleteall 命令的语法。
deleteall ‘<table name>’, ‘<row>’,
例子
这是一个“deleteall”命令的例子,我们将删除emp表第1行的所有单元格。
hbase(main):007:0> deleteall 'emp','1' 0 row(s) in 0.0240 seconds
使用scan命令验证表。下面给出了删除表后的表快照。
hbase(main):022:0> scan 'emp' ROW COLUMN &plus CELL 2 column = personal data:city, timestamp = 1417524574905, value = chennai 2 column = personal data:name, timestamp = 1417524556125, value = ravi 2 column = professional data:designation, timestamp = 1417524204, value = sr:engg 2 column = professional data:salary, timestamp = 1417524604221, value = 30000 3 column = personal data:city, timestamp = 1417524681780, value = delhi 3 column = personal data:name, timestamp = 1417524672067, value = rajesh 3 column = professional data:designation, timestamp = 1417523187, value = jr:engg 3 column = professional data:salary, timestamp = 1417524702514, value = 25000
使用 Java API 删除数据
您可以使用HTable类的delete()方法从 HBase 表中删除数据。按照下面给出的步骤从表中删除数据。
步骤 1:实例化配置类
配置类将 HBase 配置文件添加到其对象中。您可以使用HbaseConfiguration类的create()方法创建配置对象,如下所示。
Configuration conf = HbaseConfiguration.create();
第二步:实例化HTable类
您有一个名为HTable的类,它是 HBase 中 Table 的实现。此类用于与单个 HBase 表进行通信。在实例化这个类时,它接受配置对象和表名作为参数。您可以实例化 HTable 类,如下所示。
HTable hTable = new HTable(conf, tableName);
第 3 步:实例化删除类
通过以字节数组格式传递要删除的行的 rowid 来实例化Delete类。您还可以将时间戳和 Rowlock 传递给此构造函数。
Delete delete = new Delete(toBytes("row1"));
第四步:选择要删除的数据
您可以使用Delete类的删除方法删除数据。这个类有各种删除方法。使用这些方法选择要删除的列或列族。查看以下示例,这些示例显示了 Delete 类方法的用法。
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));
步骤 5:删除数据
通过将删除实例传递给HTable类的delete()方法来删除选定的数据,如下所示。
table.delete(delete);
第六步:关闭HTableInstance
删除数据后,关闭HTable Instance。
table.close();
下面给出了从 HBase 表中删除数据的完整程序。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.util.Bytes;
public class DeleteData {
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(conf, "employee");
// Instantiating Delete class
Delete delete = new Delete(Bytes.toBytes("row1"));
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));
// deleting the data
table.delete(delete);
// closing the HTable object
table.close();
System.out.println("data deleted.....");
}
}
编译并执行上述程序,如下所示。
$javac Deletedata.java $java DeleteData
以下应该是输出:
data deleted
HBase – 扫描
使用 HBase Shell 进行扫描
的扫描命令用于在HTable查看数据。使用scan命令可以获取表数据。其语法如下:
scan ‘<table name>’
例子
以下示例显示如何使用 scan 命令从表中读取数据。在这里,我们正在读取emp表。
hbase(main):010:0> scan 'emp' ROW COLUMN &plus CELL 1 column = personal data:city, timestamp = 1417521848375, value = hyderabad 1 column = personal data:name, timestamp = 1417521785385, value = ramu 1 column = professional data:designation, timestamp = 1417585277,value = manager 1 column = professional data:salary, timestamp = 1417521903862, value = 50000 1 row(s) in 0.0370 seconds
使用 Java API 进行扫描
使用java API扫描整个表数据的完整程序如下。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating the Scan class
Scan scan = new Scan();
// Scanning the required columns
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("city"));
// Getting the scan result
ResultScanner scanner = table.getScanner(scan);
// Reading values from scan result
for (Result result = scanner.next(); result != null; result = Scanner.next())
System.out.println("Found row : " + result);
//closing the scanner
scanner.close();
}
}
编译并执行上述程序,如下所示。
$javac ScanTable.java $java ScanTable
以下应该是输出:
Found row :
keyvalues={row1/personal:city/1418275612888/Put/vlen=5/mvcc=0,
row1/personal:name/1418035791555/Put/vlen=4/mvcc=0}
HBase – 计数和截断
数数
您可以使用count命令计算表的行数。其语法如下:
count ‘<table name>’
删除第一行后,emp 表将有两行。如下图验证。
hbase(main):023:0> count 'emp' 2 row(s) in 0.090 seconds ⇒ 2
截短
此命令禁用删除并重新创建表。truncate的语法如下:
hbase> truncate 'table name'
例子
下面给出了 truncate 命令的示例。这里我们截断了emp表。
hbase(main):011:0> truncate 'emp' Truncating 'one' table (it may take a while): - Disabling table... - Truncating table... 0 row(s) in 1.5950 seconds
截断表后,使用scan命令进行验证。你会得到一个零行的表。
hbase(main):017:0> scan ‘emp’ ROW COLUMN &plus CELL 0 row(s) in 0.3110 seconds
HBase – 安全
我们可以在 HBase 中授予和撤销用户的权限。出于安全目的,共有三个命令:grant、revoke 和 user_permission。
授予
本批命令授予特定的权限,例如读取,写入,执行和管理上的表给某个用户。grant 命令的语法如下:
hbase> grant <user> <permissions> [<table> [<column family> [<column qualifier>]]
我们可以从 RWXCA 集合中授予一个用户零个或多个权限,其中
- R – 代表读取权限。
- W – 代表写权限。
- X – 代表执行权限。
- C – 代表创建权限。
- A – 代表管理员权限。
下面给出的示例将所有权限授予名为“Tutorialspoint”的用户。
hbase(main):018:0> grant 'Tutorialspoint', 'RWXCA'
撤销
该撤销命令用于撤销表的用户的访问权限。其语法如下:
hbase> revoke <user>
以下代码撤销名为“Tutorialspoint”的用户的所有权限。
hbase(main):006:0> revoke 'Tutorialspoint'
用户权限
此命令用于列出特定表的所有权限。user_permission的语法如下:
hbase>user_permission ‘tablename’
以下代码列出了 ’emp’ 表的所有用户权限。
hbase(main):013:0> user_permission 'emp'
