Mahout – 分类
Mahout – 分类
什么是分类?
分类是一种机器学习技术,它使用已知数据来确定应如何将新数据分类到一组现有类别中。例如,
-
iTunes 应用程序使用分类来准备播放列表。
-
邮件服务提供商,例如 Yahoo! Gmail 使用此技术来决定是否应将新邮件归类为垃圾邮件。分类算法通过分析用户将某些邮件标记为垃圾邮件的习惯来训练自己。基于此,分类器决定未来的邮件应该存放在您的收件箱中还是垃圾邮件文件夹中。
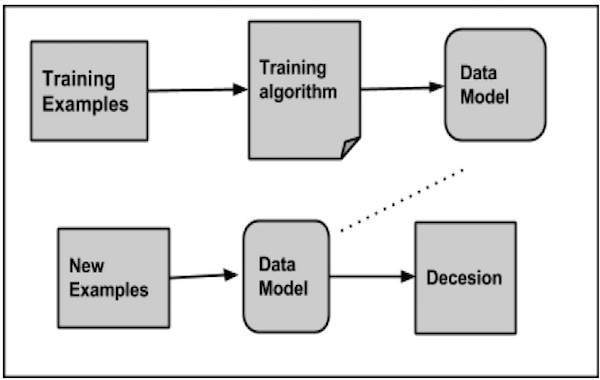
分类的工作原理
在对给定数据集进行分类时,分类器系统执行以下操作:
- 最初,使用任何学习算法准备一个新的数据模型。
- 然后对准备好的数据模型进行测试。
- 此后,该数据模型用于评估新数据并确定其类别。
分类的应用
-
信用卡欺诈检测– 分类机制用于预测信用卡欺诈。使用先前欺诈的历史信息,分类器可以预测哪些未来交易可能会变成欺诈。
-
垃圾邮件– 根据以前垃圾邮件的特征,分类器确定是否应将新遇到的电子邮件发送到垃圾邮件文件夹。
朴素贝叶斯分类器
Mahout 使用朴素贝叶斯分类器算法。它使用两种实现:
- 分布式朴素贝叶斯分类
- 互补朴素贝叶斯分类
朴素贝叶斯是一种构建分类器的简单技术。它不是用于训练此类分类器的单一算法,而是一系列算法。贝叶斯分类器构建模型来对问题实例进行分类。这些分类是使用可用数据进行的。
朴素贝叶斯的一个优点是它只需要少量的训练数据来估计分类所需的参数。
对于某些类型的概率模型,可以在监督学习设置中非常有效地训练朴素贝叶斯分类器。
尽管假设过于简单,朴素贝叶斯分类器在许多复杂的现实世界情况中都表现得很好。
分类程序
实施分类应遵循以下步骤:
- 生成示例数据
- 从数据创建序列文件
- 将序列文件转换为向量
- 训练向量
- 测试向量
步骤 1:生成示例数据
生成或下载要分类的数据。例如,您可以从以下链接获取
20 个新闻组示例数据:http :
//people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
创建用于存储输入数据的目录。下载示例,如下所示。
$ mkdir classification_example $ cd classification_example $tar xzvf 20news-bydate.tar.gz wget http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
步骤 2:创建序列文件
使用seqdirectory实用程序从示例创建序列文件。生成序列的语法如下:
mahout seqdirectory -i <input file path> -o <output directory>
步骤 3:将序列文件转换为向量
使用seq2parse实用程序从序列文件创建矢量文件。seq2parse实用程序的选项
如下:
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
第 4 步:训练向量
使用trainnb实用程序训练生成的向量。下面给出了使用trainnb实用程序的选项:
mahout trainnb
-i ${PATH_TO_TFIDF_VECTORS}
-el
-o ${PATH_TO_MODEL}/model
-li ${PATH_TO_MODEL}/labelindex
-ow
-c
第 5 步:测试向量
使用testnb实用程序测试向量。下面给出了使用testnb实用程序的选项:
mahout testnb
-i ${PATH_TO_TFIDF_TEST_VECTORS}
-m ${PATH_TO_MODEL}/model
-l ${PATH_TO_MODEL}/labelindex
-ow
-o ${PATH_TO_OUTPUT}
-c
-seq
