DynamoDB – 快速指南
DynamoDB – 快速指南
DynamoDB – 概述
DynamoDB 允许用户创建能够存储和检索任意数量数据并提供任意数量流量的数据库。它自动在服务器上分配数据和流量,以动态管理每个客户的请求,并保持快速的性能。
DynamoDB 与 RDBMS
DynamoDB 使用 NoSQL 模型,这意味着它使用非关系系统。下表突出显示了 DynamoDB 和 RDBMS 之间的差异 –
| Common Tasks | 关系型数据库管理系统 | 动态数据库 |
|---|---|---|
| Connect to the Source | 它使用持久连接和 SQL 命令。 | 它使用 HTTP 请求和 API 操作 |
| Create a Table | 它的基本结构是表格,必须定义。 | 它只使用主键,在创建时不使用模式。它使用各种数据源。 |
| Get Table Info | 所有表信息仍可访问 | 只显示主键。 |
| Load Table Data | 它使用由列组成的行。 | 在表格中,它使用由属性组成的项目 |
| Read Table Data | 它使用 SELECT 语句和过滤语句。 | 它使用 GetItem、Query 和 Scan。 |
| Manage Indexes | 它使用通过 SQL 语句创建的标准索引。对它的修改会在表更改时自动发生。 | 它使用二级索引来实现相同的功能。它需要规范(分区键和排序键)。 |
| Modify Table Data | 它使用 UPDATE 语句。 | 它使用 UpdateItem 操作。 |
| Delete Table Data | 它使用 DELETE 语句。 | 它使用 DeleteItem 操作。 |
| Delete a Table | 它使用 DROP TABLE 语句。 | 它使用 DeleteTable 操作。 |
好处
DynamoDB 的两个主要优势是可扩展性和灵活性。它不强制使用特定的数据源和结构,允许用户以统一的方式处理几乎任何事情。
其设计还支持从较轻的任务和操作到要求苛刻的企业功能的广泛使用。它还允许简单地使用多种语言:Ruby、Java、Python、C#、Erlang、PHP 和 Perl。
限制
DynamoDB 确实受到某些限制,但是,这些限制并不一定会造成巨大的问题或阻碍稳固的发展。
您可以从以下几点查看它们 –
-
容量单位大小– 读取容量单位是每秒对不大于 4KB 的项目进行的单一一致读取。写入容量单位是每秒一次写入不大于 1KB 的项目。
-
Provisioned Throughput Min/Max – 所有表和全局二级索引至少有一个读取和一个写入容量单位。最大值取决于地区。在美国,40K 读写仍然是每表的上限(每个账户 80K),其他地区的上限是每表 10K,账户上限为 20K。
-
预配置吞吐量增加和减少– 您可以根据需要经常增加它,但减少仍然限制在每张表每天不超过四次。
-
每个帐户的表大小和数量– 表大小没有限制,但除非您要求更高的上限,否则帐户有 256 个表限制。
-
每个表的二级索引– 允许五个本地和五个全局。
-
每个表的投影二级索引属性– DynamoDB 允许 20 个属性。
-
分区键长度和值– 它们的最小长度为 1 个字节,最大为 2048 个字节,但是,DynamoDB 对值没有限制。
-
排序键长度和值– 其最小长度为 1 个字节,最大为 1024 个字节,除非其表使用本地二级索引,否则对值没有限制。
-
表和二级索引名称– 名称的长度必须至少为 3 个字符,最多为 255 个。它们使用以下字符:AZ、az、0-9、“_”、“-”和“.” .
-
属性名称– 最少一个字符,最多 64KB,键和某些属性除外。
-
保留字– DynamoDB 不会阻止使用保留字作为名称。
-
表达式长度– 表达式字符串有 4KB 的限制。属性表达式有 255 字节的限制。表达式的替换变量有 2MB 的限制。
DynamoDB – 基本概念
在使用 DynamoDB 之前,您必须熟悉其基本组件和生态系统。在 DynamoDB 生态系统中,您可以使用表、属性和项目。一个表包含项目集,项目包含属性集。属性是不需要进一步分解的数据的基本元素,即字段。
首要的关键
主键作为唯一标识表项的手段,二级索引提供查询灵活性。DynamoDB 通过修改表数据流记录事件。
创建表不仅需要设置名称,还需要设置主键;它标识表项。没有两个项目共享一个密钥。DynamoDB 使用两种类型的主键 –
-
分区键– 这个简单的主键由一个称为“分区键”的属性组成。在内部,DynamoDB 使用键值作为哈希函数的输入来确定存储。
-
分区键和排序键– 此键称为“复合主键”,由两个属性组成。
-
分区键和
-
排序键。
DynamoDB 将第一个属性应用于哈希函数,并将具有相同分区键的项目存储在一起;它们的顺序由排序键决定。项目可以共享分区键,但不能共享排序键。
-
主键属性只允许标量(单个)值;和字符串、数字或二进制数据类型。非键属性没有这些约束。
二级索引
这些索引允许您使用备用键查询表数据。尽管 DynamoDB 不强制使用它们,但它们优化了查询。
DynamoDB 使用两种类型的二级索引 –
-
全局二级索引– 该索引拥有分区和排序键,可以与表键不同。
-
本地二级索引– 该索引拥有与表相同的分区键,但是,其排序键不同。
应用程序接口
DynamoDB 提供的API 操作包括控制平面、数据平面(例如,创建、读取、更新和删除)和流的操作。在控制平面操作中,您可以使用以下工具创建和管理表 –
- 创建表
- 描述表
- 列表
- 更新表
- 删除表
在数据平面中,您可以使用以下工具执行 CRUD 操作 –
| Create | 读 | 更新 | 删除 |
|---|---|---|---|
|
PutItem BatchWriteItem |
获取项目 批量获取项目 询问 扫描 |
更新项 |
删除项目 批量写入项目 |
流操作控制表流。您可以查看以下流工具 –
- 列表流
- 描述流
- 获取碎片迭代器
- 获取记录
预配置吞吐量
在表创建中,您指定预配置吞吐量,它为读取和写入保留资源。您可以使用容量单位来衡量和设置吞吐量。
当应用程序超过设置的吞吐量时,请求失败。DynamoDB GUI 控制台允许监控设置和使用的吞吐量,以实现更好的动态配置。
读取一致性
DynamoDB 使用最终一致性和强一致性读取来支持动态应用程序需求。最终一致性读取并不总是提供当前数据。
强一致性读取始终提供当前数据(设备故障或网络问题除外)。最终一致性读取作为默认设置,需要在ConsistentRead参数中设置 true才能更改它。
分区
DynamoDB 使用分区来存储数据。这些表的存储分配有 SSD 支持并自动跨区域复制。DynamoDB 管理所有分区任务,无需用户参与。
在创建表时,表进入 CREATING 状态,即分配分区。当它达到 ACTIVE 状态时,您可以执行操作。当系统容量达到最大值或当您更改吞吐量时,系统会更改分区。
DynamoDB – 环境
DynamoDB 环境仅包括使用您的 Amazon Web Services 帐户访问 DynamoDB GUI 控制台,但是,您也可以执行本地安装。
导航到以下网站 – https://aws.amazon.com/dynamodb/
单击“开始使用 Amazon DynamoDB”按钮,如果您没有 Amazon Web Services 帐户,请单击“创建 AWS 帐户”按钮。简单、有指导的流程将告知您所有相关费用和要求。
执行该过程的所有必要步骤后,您将获得访问权限。只需登录 AWS 控制台,然后导航到 DynamoDB 控制台。
请务必删除未使用或不必要的材料以避免相关费用。
本地安装
AWS (Amazon Web Service) 为本地安装提供了一个 DynamoDB 版本。它支持在没有 Web 服务或连接的情况下创建应用程序。它还通过允许使用本地数据库来降低预配置吞吐量、数据存储和传输费用。本指南假设本地安装。
准备好部署后,您可以对应用程序进行一些小的调整,以将其转换为 AWS 使用。
安装文件是一个.jar 可执行文件。它可以在 Linux、Unix、Windows 和任何其他支持 Java 的操作系统中运行。使用以下链接之一下载文件 –
-
Tarball – http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.tar.gz
-
Zip 存档– http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.zip
注意– 其他存储库提供该文件,但不一定是最新版本。使用上面的链接获取最新的安装文件。此外,请确保您拥有 Java 运行时引擎 (JRE) 版本 6.x 或更新版本。DynamoDB 无法与旧版本一起运行。
下载适当的存档后,解压缩其目录 (DynamoDBLocal.jar) 并将其放置在所需位置。
然后,您可以通过打开命令提示符、导航到包含 DynamoDBLocal.jar 的目录并输入以下命令来启动 DynamoDB –
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDb
您还可以通过关闭用于启动它的命令提示符来停止 DynamoDB。
工作环境
您可以使用 JavaScript shell、GUI 控制台和多种语言来使用 DynamoDB。可用的语言包括 Ruby、Java、Python、C#、Erlang、PHP 和 Perl。
在本教程中,我们使用 Java 和 GUI 控制台示例来明确概念和代码。安装 Java IDE、适用于 Java 的 AWS 开发工具包,并为 Java 开发工具包设置 AWS 安全凭证以使用 Java。
从本地到 Web 服务代码的转换
准备好部署时,您需要更改代码。调整取决于代码语言和其他因素。主要更改仅包括将端点从本地点更改为 AWS 区域。其他更改需要对您的应用程序进行更深入的分析。
本地安装在许多方面与 Web 服务不同,包括但不限于以下主要区别 –
-
本地安装会立即创建表,但服务需要更长的时间。
-
本地安装忽略吞吐量。
-
删除会在本地安装中立即发生。
-
由于没有网络开销,本地安装中的读/写速度很快。
DynamoDB – 操作工具
DynamoDB 提供了三个用于执行操作的选项:基于 Web 的 GUI 控制台、JavaScript shell 和您选择的编程语言。
在本教程中,我们将专注于使用 GUI 控制台和 Java 语言来清晰和概念理解。
图形用户界面控制台
可以在以下地址找到用于 Amazon DynamoDB 的 GUI 控制台或 AWS 管理控制台 – https://console.aws.amazon.com/dynamodb/home
它允许您执行以下任务 –
- CRUD
- 查看表格项目
- 执行表查询
- 为表容量监控设置警报
- 实时查看表指标
- 查看表警报

如果您的 DynamoDB 帐户没有表,在访问时,它会指导您创建表。它的主屏幕提供了三个用于执行常见操作的快捷方式 –
- 创建表
- 添加和查询表
- 监控和管理表
JavaScript 外壳
DynamoDB 包含一个交互式 JavaScript shell。shell 在 Web 浏览器中运行,推荐的浏览器包括 Firefox 和 Chrome。
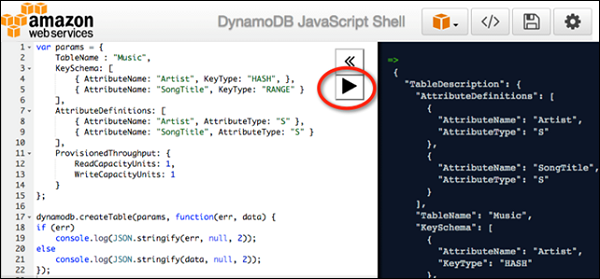
注意– 使用其他浏览器可能会导致错误。
通过打开 Web 浏览器并输入以下地址来访问 shell – http://localhost:8000/shell
通过在左窗格中输入 JavaScript 并单击运行代码的左窗格右上角的“播放”图标按钮来使用 shell。代码结果显示在右侧窗格中。
DynamoDB 和 Java
利用您的 Java 开发环境将 Java 与 DynamoDB 结合使用。操作确认为正常的 Java 语法和结构。
DynamoDB – 数据类型
DynamoDB 支持的数据类型包括特定于属性、操作和您选择的编码语言的数据类型。
属性数据类型
DynamoDB 支持大量的表属性数据类型。每种数据类型都属于以下三个类别之一 –
-
标量– 这些类型表示单个值,包括数字、字符串、二进制、布尔值和空值。
-
文档– 这些类型表示具有嵌套属性的复杂结构,包括列表和映射。
-
Set – 这些类型代表多个标量,包括字符串集、数字集和二进制集。
请记住,DynamoDB 是一个无模式的 NoSQL 数据库,在创建表时不需要属性或数据类型定义。与 RDBMS 相比,它只需要主键属性数据类型,后者在创建表时需要列数据类型。
标量
-
数字– 它们限制为 38 位,可以是正数、负数或零。
-
String – 它们是使用 UTF-8 的 Unicode,最小长度 >0,最大 400KB。
-
二进制– 它们存储任何二进制数据,例如加密数据、图像和压缩文本。DynamoDB 将其字节视为无符号。
-
Boolean – 他们存储真或假。
-
Null – 它们代表未知或未定义的状态。
文档
-
List – 它存储有序值集合,并使用方括号 ([…])。
-
Map – 它存储无序的名称-值对集合,并使用花括号 ({…})。
放
集合必须包含相同类型的元素,无论是数字、字符串还是二进制。对集合的唯一限制包括 400KB 项目大小限制,并且每个元素都是唯一的。
动作数据类型
DynamoDB API 保存操作使用的各种数据类型。您可以查看以下键类型的选择 –
-
AttributeDefinition – 它代表键表和索引模式。
-
容量– 它表示表或索引消耗的吞吐量数量。
-
CreateGlobalSecondaryIndexAction – 它表示添加到表中的新全局二级索引。
-
LocalSecondaryIndex – 它代表本地二级索引属性。
-
ProvisionedThroughput – 它表示索引或表的预配吞吐量。
-
PutRequest – 它代表 PutItem 请求。
-
TableDescription – 它代表表格属性。
支持的 Java 数据类型
DynamoDB 为 Java 提供对原始数据类型、集合和任意类型的支持。
DynamoDB – 创建表
创建表通常包括生成表、命名表、建立其主键属性和设置属性数据类型。
利用 GUI 控制台、Java 或其他选项来执行这些任务。
使用 GUI 控制台创建表
通过访问https://console.aws.amazon.com/dynamodb 上的控制台来创建表。然后选择“创建表”选项。
我们的示例生成一个填充有产品信息的表,其中产品的唯一属性由 ID 号(数字属性)标识。在创建表屏幕中,在表名字段中输入表名;在分区键字段中输入主键 (ID);并为数据类型输入“数字”。
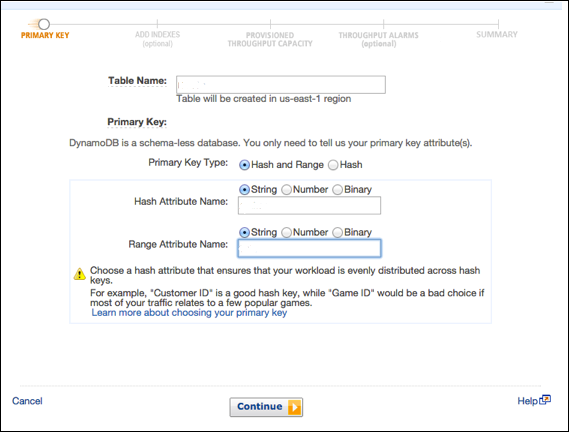
输入所有信息后,选择Create。
使用 Java 创建表
使用 Java 创建相同的表。它的主键由以下两个属性组成 –
-
ID – 使用分区键和 ScalarAttributeType N,意思是数字。
-
Nomenclature – 使用排序键和 ScalarAttributeType S,意思是字符串。
Java 使用createTable 方法生成表;在调用中,指定了表名、主键属性和属性数据类型。
您可以查看以下示例 –
import java.util.Arrays;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.ScalarAttributeType;
public class ProductsCreateTable {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
String tableName = "Products";
try {
System.out.println("Creating the table, wait...");
Table table = dynamoDB.createTable (tableName,
Arrays.asList (
new KeySchemaElement("ID", KeyType.HASH), // the partition key
// the sort key
new KeySchemaElement("Nomenclature", KeyType.RANGE)
),
Arrays.asList (
new AttributeDefinition("ID", ScalarAttributeType.N),
new AttributeDefinition("Nomenclature", ScalarAttributeType.S)
),
new ProvisionedThroughput(10L, 10L)
);
table.waitForActive();
System.out.println("Table created successfully. Status: " +
table.getDescription().getTableStatus());
} catch (Exception e) {
System.err.println("Cannot create the table: ");
System.err.println(e.getMessage());
}
}
}
在上面的示例中,请注意端点:.withEndpoint。
它表示使用本地主机进行本地安装。另外,请注意本地安装会忽略所需的ProvisionedThroughput 参数。
DynamoDB – 加载表
加载表通常包括创建源文件,确保源文件符合与 DynamoDB 兼容的语法,将源文件发送到目标,然后确认填充成功。
利用 GUI 控制台、Java 或其他选项来执行任务。
使用 GUI 控制台加载表
使用命令行和控制台的组合加载数据。您可以通过多种方式加载数据,其中一些如下 –
- 控制台
- 命令行
- 代码还有
- 数据管道(本教程稍后讨论的功能)
但是,为了速度,这个例子同时使用了 shell 和控制台。首先,使用以下语法将源数据加载到目标中 –
aws dynamodb batch-write-item -–request-items file://[filename]
例如 –
aws dynamodb batch-write-item -–request-items file://MyProductData.json
通过访问控制台验证操作是否成功 –
https://console.aws.amazon.com/dynamodb
从导航窗格中选择表,然后从表列表中选择目标表。
选择项目选项卡以检查用于填充表的数据。选择取消返回到表列表。
使用 Java 加载表
通过首先创建源文件来使用 Java。我们的源文件使用 JSON 格式。每个产品都有两个主键属性(ID 和 Nomenclature)和一个 JSON 映射(Stat) –
[
{
"ID" : ... ,
"Nomenclature" : ... ,
"Stat" : { ... }
},
{
"ID" : ... ,
"Nomenclature" : ... ,
"Stat" : { ... }
},
...
]
您可以查看以下示例 –
{
"ID" : 122,
"Nomenclature" : "Particle Blaster 5000",
"Stat" : {
"Manufacturer" : "XYZ Inc.",
"sales" : "1M+",
"quantity" : 500,
"img_src" : "http://www.xyz.com/manuals/particleblaster5000.jpg",
"description" : "A laser cutter used in plastic manufacturing."
}
}
下一步是将文件放在应用程序使用的目录中。
Java 主要使用putItem和path 方法来执行加载。
您可以查看以下代码示例来处理文件并加载它 –
import java.io.File;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.fasterxml.jackson.core.JsonFactory;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.databind.node.ObjectNode;
public class ProductsLoadData {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
JsonParser parser = new JsonFactory()
.createParser(new File("productinfo.json"));
JsonNode rootNode = new ObjectMapper().readTree(parser);
Iterator<JsonNode> iter = rootNode.iterator();
ObjectNode currentNode;
while (iter.hasNext()) {
currentNode = (ObjectNode) iter.next();
int ID = currentNode.path("ID").asInt();
String Nomenclature = currentNode.path("Nomenclature").asText();
try {
table.putItem(new Item()
.withPrimaryKey("ID", ID, "Nomenclature", Nomenclature)
.withJSON("Stat", currentNode.path("Stat").toString()));
System.out.println("Successful load: " + ID + " " + Nomenclature);
} catch (Exception e) {
System.err.println("Cannot add product: " + ID + " " + Nomenclature);
System.err.println(e.getMessage());
break;
}
}
parser.close();
}
}
DynamoDB – 查询表
查询一个表主要需要选择一个表,指定一个分区键,然后执行查询;具有使用二级索引和通过扫描操作执行更深层次过滤的选项。
利用 GUI 控制台、Java 或其他选项来执行任务。
使用 GUI 控制台查询表
使用之前创建的表执行一些简单的查询。首先,在https://console.aws.amazon.com/dynamodb打开控制台
从导航窗格中选择表,然后从表列表中选择回复。然后选择Items选项卡以查看加载的数据。
选择“创建项目”按钮下方的数据过滤链接(“扫描:[表格] 回复”)。
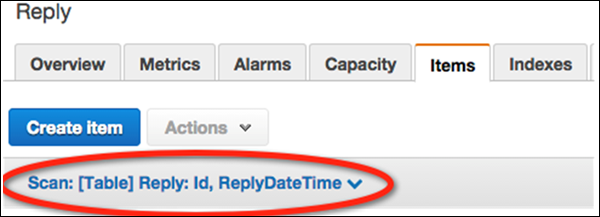
在过滤屏幕中,为操作选择查询。输入适当的分区键值,然后单击Start。
然后回复表返回匹配的项目。
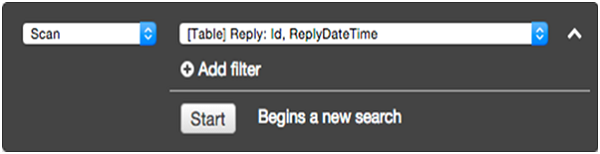
使用 Java 查询表
使用Java 中的查询方法进行数据检索操作。它需要指定分区键值,排序键是可选的。
通过首先创建一个描述参数的querySpec 对象来编码 Java 查询。然后将对象传递给查询方法。我们使用前面示例中的分区键。
您可以查看以下示例 –
import java.util.HashMap;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
public class ProductsQuery {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
HashMap<String, String> nameMap = new HashMap<String, String>();
nameMap.put("#ID", "ID");
HashMap<String, Object> valueMap = new HashMap<String, Object>();
valueMap.put(":xxx", 122);
QuerySpec querySpec = new QuerySpec()
.withKeyConditionExpression("#ID = :xxx")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(valueMap);
ItemCollection<QueryOutcome> items = null;
Iterator<Item> iterator = null;
Item item = null;
try {
System.out.println("Product with the ID 122");
items = table.query(querySpec);
iterator = items.iterator();
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.getNumber("ID") + ": "
+ item.getString("Nomenclature"));
}
} catch (Exception e) {
System.err.println("Cannot find products with the ID number 122");
System.err.println(e.getMessage());
}
}
}
请注意,查询使用分区键,但是,二级索引为查询提供了另一种选择。它们的灵活性允许查询非关键属性,本教程稍后将讨论该主题。
scan 方法还通过收集所有表数据来支持检索操作。所述可选.withFilterExpression的指定的标准以外防止项目出现在结果。
在本教程的后面,我们将详细讨论扫描。现在,看看下面的例子 –
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.ScanOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.ScanSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class ProductsScan {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
ScanSpec scanSpec = new ScanSpec()
.withProjectionExpression("#ID, Nomenclature , stat.sales")
.withFilterExpression("#ID between :start_id and :end_id")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(new ValueMap().withNumber(":start_id", 120)
.withNumber(":end_id", 129));
try {
ItemCollection<ScanOutcome> items = table.scan(scanSpec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
Item item = iter.next();
System.out.println(item.toString());
}
} catch (Exception e) {
System.err.println("Cannot perform a table scan:");
System.err.println(e.getMessage());
}
}
}
DynamoDB – 删除表
在本章中,我们将讨论如何删除表以及删除表的不同方法。
表删除是一个简单的操作,只需要表名。利用 GUI 控制台、Java 或任何其他选项来执行此任务。
使用 GUI 控制台删除表
通过首先访问控制台执行删除操作 –
https://console.aws.amazon.com/dynamodb。
从导航窗格中选择表,然后从表列表中选择需要删除的表,如下面的屏幕截图所示。
最后,选择删除表。选择删除表后,会出现确认信息。然后您的表被删除。
使用 Java 删除表
使用delete方法删除一个表。下面给出一个例子来更好地解释这个概念。
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Table;
public class ProductsDeleteTable {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
try {
System.out.println("Performing table delete, wait...");
table.delete();
table.waitForDelete();
System.out.print("Table successfully deleted.");
} catch (Exception e) {
System.err.println("Cannot perform table delete: ");
System.err.println(e.getMessage());
}
}
}
DynamoDB – API 接口
DynamoDB 为表操作、数据读取和数据修改提供了大量强大的 API 工具。
Amazon 建议使用AWS SDK(例如 Java SDK)而不是调用低级 API。这些库使得直接不需要与低级 API 交互。这些库简化了身份验证、序列化和连接等常见任务。
操作表格
DynamoDB 为表管理提供五个低级操作 –
-
CreateTable – 这会生成一个表并包括用户设置的吞吐量。它要求您设置主键,无论是复合键还是简单键。它还允许一个或多个二级索引。
-
ListTables – 这提供了当前 AWS 用户账户中所有表的列表,并与他们的端点相关联。
-
UpdateTable – 这会改变吞吐量和全局二级索引吞吐量。
-
DescribeTable – 提供表元数据;例如,状态、大小和索引。
-
DeleteTable – 这只是擦除表及其索引。
读取数据
DynamoDB 提供四个用于数据读取的低级操作 –
-
GetItem – 它接受一个主键并返回关联项目的属性。它允许更改其默认的最终一致读取设置。
-
BatchGetItem – 它通过主键对多个项目执行多个 GetItem 请求,可选择一个或多个表。它返回的项目不超过 100 个,并且必须保持在 16MB 以下。它允许最终一致和强一致的读取。
-
Scan – 它读取所有表项并产生最终一致的结果集。您可以通过条件过滤结果。它避免使用索引并扫描整个表,因此不要将它用于需要可预测性的查询。
-
查询– 它返回一个或多个表项或二级索引项。它使用指定的分区键值,并允许使用比较运算符来缩小范围。它支持两种类型的一致性,并且每个响应的大小限制为 1MB。
修改数据
DynamoDB 提供四个用于数据修改的低级操作 –
-
PutItem – 这会产生一个新项目或替换现有项目。在发现相同的主键时,默认情况下,它会替换该项目。条件运算符允许您绕过默认设置,并且仅在特定条件下替换项目。
-
BatchWriteItem – 这将执行多个 PutItem 和 DeleteItem 请求,并在多个表上执行。如果一个请求失败,它不会影响整个操作。它的上限为 25 个项目,大小为 16MB。
-
UpdateItem – 它更改现有项目属性,并允许使用条件运算符仅在特定条件下执行更新。
-
DeleteItem – 它使用主键擦除项目,还允许使用条件运算符来指定删除条件。
DynamoDB – 创建项目
在 DynamoDB 中创建项目主要包括项目和属性规范,以及指定条件的选项。每个项目都作为一组属性存在,每个属性都被命名并分配了一个特定类型的值。
值类型包括标量、文档或集合。项目的大小限制为 400KB,任何数量的属性都可能适合该限制。名称和值大小(二进制和 UTF-8 长度)决定项目大小。使用简短的属性名称有助于最小化项目大小。
注意– 您必须指定所有主键属性,主键只需要分区键;和需要分区和排序键的复合键。
另外,请记住表没有预定义的模式。您可以在一张表中存储截然不同的数据集。
使用 GUI 控制台、Java 或其他工具来执行此任务。
如何使用 GUI 控制台创建项目?
导航到控制台。在左侧的导航窗格中,选择Tables。选择用作目标的表名称,然后选择项目选项卡,如下面的屏幕截图所示。
选择创建项目。“创建项目”屏幕提供用于输入所需属性值的界面。还必须输入任何二级索引。
如果您需要更多属性,请选择Message左侧的操作菜单。然后选择Append和所需的数据类型。
输入所有基本信息后,选择保存以添加项目。
如何在项目创建中使用 Java?
在项目创建操作中使用 Java 包括创建 DynamoDB 类实例、Table 类实例、Item 类实例,以及指定您将创建的项目的主键和属性。然后使用 putItem 方法添加新项目。
例子
DynamoDB dynamoDB = new DynamoDB (new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
// Spawn a related items list
List<Number> RELItems = new ArrayList<Number>();
RELItems.add(123);
RELItems.add(456);
RELItems.add(789);
//Spawn a product picture map
Map<String, String> photos = new HashMap<String, String>();
photos.put("Anterior", "http://xyz.com/products/101_front.jpg");
photos.put("Posterior", "http://xyz.com/products/101_back.jpg");
photos.put("Lateral", "http://xyz.com/products/101_LFTside.jpg");
//Spawn a product review map
Map<String, List<String>> prodReviews = new HashMap<String, List<String>>();
List<String> fiveStarRVW = new ArrayList<String>();
fiveStarRVW.add("Shocking high performance.");
fiveStarRVW.add("Unparalleled in its market.");
prodReviews.put("5 Star", fiveStarRVW);
List<String> oneStarRVW = new ArrayList<String>();
oneStarRVW.add("The worst offering in its market.");
prodReviews.put("1 Star", oneStarRVW);
// Generate the item
Item item = new Item()
.withPrimaryKey("Id", 101)
.withString("Nomenclature", "PolyBlaster 101")
.withString("Description", "101 description")
.withString("Category", "Hybrid Power Polymer Cutter")
.withString("Make", "Brand – XYZ")
.withNumber("Price", 50000)
.withString("ProductCategory", "Laser Cutter")
.withBoolean("Availability", true)
.withNull("Qty")
.withList("ItemsRelated", RELItems)
.withMap("Images", photos)
.withMap("Reviews", prodReviews);
// Add item to the table
PutItemOutcome outcome = table.putItem(item);
您还可以查看以下更大的示例。
注意– 以下示例可能假设先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
以下示例还在 Eclipse AWS Java 项目中使用 Eclipse IDE、AWS 凭证文件和 AWS Toolkit。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class CreateItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
}
DynamoDB – 获取项目
在 DynamoDB 中检索项目需要使用 GetItem,并指定表名和项目主键。确保包含完整的主键而不是省略一部分。
例如,省略组合键的排序键。
GetItem 行为符合三个默认值 –
- 它作为最终一致性读取执行。
- 它提供了所有属性。
- 它没有详细说明其容量单位消耗。
这些参数允许您覆盖默认的 GetItem 行为。
检索项目
DynamoDB 通过跨多个服务器维护多个项目副本来确保可靠性。每次成功写入都会创建这些副本,但需要大量时间来执行;意思最终一致。这意味着您不能在写入项目后立即尝试读取。
您可以更改 GetItem 的默认最终一致性读取,但是,更多当前数据的成本仍然消耗更多容量单位;具体来说,是两倍。注意 DynamoDB 通常在一秒钟内实现每个副本的一致性。
您可以使用 GUI 控制台、Java 或其他工具来执行此任务。
使用 Java 检索项目
在项目检索操作中使用 Java 需要创建一个 DynamoDB 类实例、Table 类实例,并调用 Table 实例的 getItem 方法。然后指定项目的主键。
您可以查看以下示例 –
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
Item item = table.getItem("IDnum", 109);
在某些情况下,您需要为此操作指定参数。
以下示例使用.withProjectionExpression和GetItemSpec作为检索规范 –
GetItemSpec spec = new GetItemSpec()
.withPrimaryKey("IDnum", 122)
.withProjectionExpression("IDnum, EmployeeName, Department")
.withConsistentRead(true);
Item item = table.getItem(spec);
System.out.println(item.toJSONPretty());
您还可以查看以下更大的示例以更好地理解。
注意– 以下示例可能假设先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
此示例还使用 Eclipse IDE、AWS 凭证文件和 Eclipse AWS Java 项目中的 AWS 工具包。
package com.amazonaws.codesamples.document;
import java.io.IOException
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class GetItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void retrieveItem() {
Table table = dynamoDB.getTable(tableName);
try {
Item item = table.getItem("ID", 303, "ID, Nomenclature, Manufacturers", null);
System.out.println("Displaying retrieved items...");
System.out.println(item.toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot retrieve items.");
System.err.println(e.getMessage());
}
}
}
DynamoDB – 更新项目
更新 DynamoDB 中的项目主要包括为项目指定完整的主键和表名。您修改的每个属性都需要一个新值。该操作使用UpdateItem,它修改现有项目或在发现缺失项目时创建它们。
在更新中,您可能希望通过在操作前后显示原始值和新值来跟踪更改。UpdateItem 使用ReturnValues参数来实现此目的。
注意– 该操作不报告容量单位消耗,但您可以使用ReturnConsumedCapacity参数。
使用 GUI 控制台、Java 或任何其他工具来执行此任务。
如何使用 GUI 工具更新项目?
导航到控制台。在左侧的导航窗格中,选择Tables。选择所需的表,然后选择项目选项卡。
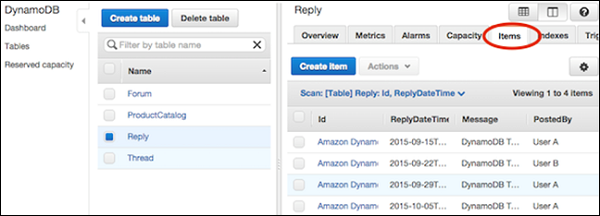
选择更新所需的项目,然后选择操作 | 编辑。
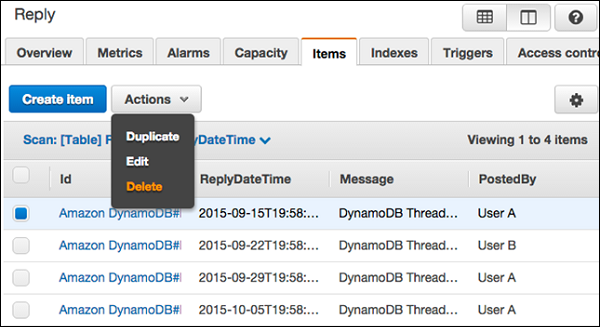
在编辑项目窗口中修改任何必要的属性或值。
使用 Java 更新项目
在项目更新操作中使用 Java 需要创建一个 Table 类实例,并调用其updateItem方法。然后指定项目的主键,并提供详细说明属性修改的UpdateExpression。
以下是相同的示例 –
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#M", "Make");
expressionAttributeNames.put("#P", "Price
expressionAttributeNames.put("#N", "ID");
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":val1",
new HashSet<String>(Arrays.asList("Make1","Make2")));
expressionAttributeValues.put(":val2", 1); //Price
UpdateItemOutcome outcome = table.updateItem(
"internalID", // key attribute name
111, // key attribute value
"add #M :val1 set #P = #P - :val2 remove #N", // UpdateExpression
expressionAttributeNames,
expressionAttributeValues);
所述的updateItem方法还允许指定的条件下,它可以在下面的例子中可以看出-
Table table = dynamoDB.getTable("ProductList");
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#P", "Price");
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":val1", 44); // change Price to 44
expressionAttributeValues.put(":val2", 15); // only if currently 15
UpdateItemOutcome outcome = table.updateItem (new PrimaryKey("internalID",111),
"set #P = :val1", // Update
"#P = :val2", // Condition
expressionAttributeNames,
expressionAttributeValues);
使用计数器更新项目
DynamoDB 允许原子计数器,这意味着使用 UpdateItem 增加/减少属性值而不影响其他请求;此外,计数器总是更新。
下面是一个示例,说明如何完成。
注意– 以下示例可能假设先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
此示例还使用 Eclipse IDE、AWS 凭证文件和 Eclipse AWS Java 项目中的 AWS 工具包。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class UpdateItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void updateAddNewAttribute() {
Table table = dynamoDB.getTable(tableName);
try {
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#na", "NewAttribute");
UpdateItemSpec updateItemSpec = new UpdateItemSpec()
.withPrimaryKey("ID", 303)
.withUpdateExpression("set #na = :val1")
.withNameMap(new NameMap()
.with("#na", "NewAttribute"))
.withValueMap(new ValueMap()
.withString(":val1", "A value"))
.withReturnValues(ReturnValue.ALL_NEW);
UpdateItemOutcome outcome = table.updateItem(updateItemSpec);
// Confirm
System.out.println("Displaying updated item...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot add an attribute in " + tableName);
System.err.println(e.getMessage());
}
}
}
DynamoDB – 删除项目
删除 DynamoDB 中的项目只需要提供表名和项目键。还强烈建议使用条件表达式,以避免删除错误的项目。
像往常一样,您可以使用 GUI 控制台、Java 或任何其他需要的工具来执行此任务。
使用 GUI 控制台删除项目
导航到控制台。在左侧的导航窗格中,选择Tables。然后选择表名和项目选项卡。
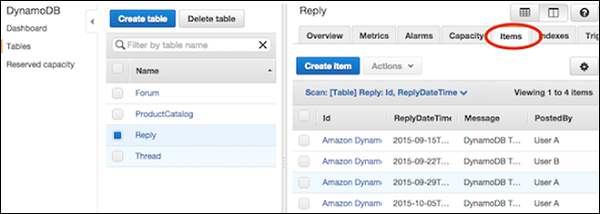
选择需要删除的项目,然后选择操作 | 删除。
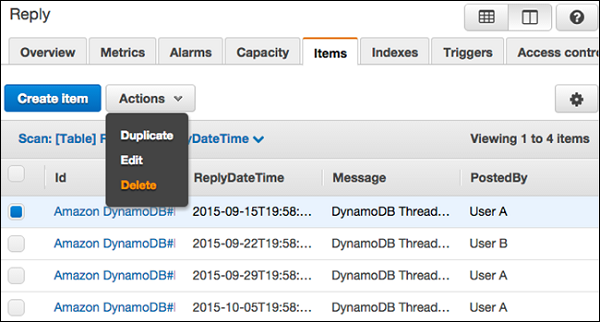
然后会出现一个删除项目对话框,如下面的截图所示。选择“删除”进行确认。
如何使用 Java 删除项目?
在项目删除操作中使用 Java 只需要创建一个 DynamoDB 客户端实例,并通过使用项目的键调用deleteItem方法。
您可以查看以下示例,其中已对其进行了详细说明。
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
DeleteItemOutcome outcome = table.deleteItem("IDnum", 151);
您还可以指定参数以防止错误删除。只需使用ConditionExpression。
例如 –
Map<String,Object> expressionAttributeValues = new HashMap<String,Object>();
expressionAttributeValues.put(":val", false);
DeleteItemOutcome outcome = table.deleteItem("IDnum",151,
"Ship = :val",
null, // doesn't use ExpressionAttributeNames
expressionAttributeValues);
下面是一个更大的例子,以便更好地理解。
注意– 以下示例可能假设先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
此示例还使用 Eclipse IDE、AWS 凭证文件和 Eclipse AWS Java 项目中的 AWS 工具包。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class DeleteItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void deleteItem() {
Table table = dynamoDB.getTable(tableName);
try {
DeleteItemSpec deleteItemSpec = new DeleteItemSpec()
.withPrimaryKey("ID", 303)
.withConditionExpression("#ip = :val")
.withNameMap(new NameMap()
.with("#ip", "InProduction"))
.withValueMap(new ValueMap()
.withBoolean(":val", false))
.withReturnValues(ReturnValue.ALL_OLD);
DeleteItemOutcome outcome = table.deleteItem(deleteItemSpec);
// Confirm
System.out.println("Displaying deleted item...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot delete item in " + tableName);
System.err.println(e.getMessage());
}
}
}
DynamoDB – 批量写入
批量写入通过创建或删除多个项目对多个项目进行操作。这些操作使用BatchWriteItem,它带有不超过 16MB 写入和 25 个请求的限制。每个项目都遵守 400KB 的大小限制。批量写入也无法执行项目更新。
什么是批量写入?
批量写入可以跨多个表操作项目。操作调用针对每个单独的请求进行,这意味着操作不会相互影响,并且允许异构混合;例如,批处理中的一个PutItem和三个DeleteItem请求,PutItem 请求失败不会影响其他请求。失败的请求导致操作返回与每个失败请求有关的信息(密钥和数据)。
注意– 如果 DynamoDB 返回任何项目而不处理它们,请重试;但是,使用回退方法来避免基于重载的另一个请求失败。
当以下一个或多个语句被证明是正确的时,DynamoDB 拒绝批量写入操作 –
-
请求超出了预配置的吞吐量。
-
该请求尝试使用BatchWriteItems来更新项目。
-
该请求对单个项目执行多个操作。
-
请求表不存在。
-
请求中的项目属性与目标不匹配。
-
请求超出大小限制。
批量写入需要某些RequestItem参数 –
-
删除操作需要DeleteRequest关键子元素,表示属性名称和值。
-
该PutRequest项目需要的项目子元素含义的属性和属性值映射。
响应– 成功的操作会产生 HTTP 200 响应,该响应指示消耗的容量单位、表处理指标和任何未处理的项目等特征。
使用 Java 批量写入
通过创建 DynamoDB 类实例、描述所有操作的TableWriteItems类实例并调用batchWriteItem方法以使用 TableWriteItems 对象来执行批量写入。
注意– 您必须在批量写入多个表时为每个表创建一个 TableWriteItems 实例。此外,请检查您的请求响应是否有任何未处理的请求。
您可以查看以下批量写入示例 –
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
TableWriteItems forumTableWriteItems = new TableWriteItems("Forum")
.withItemsToPut(
new Item()
.withPrimaryKey("Title", "XYZ CRM")
.withNumber("Threads", 0));
TableWriteItems threadTableWriteItems = new TableWriteItems(Thread)
.withItemsToPut(
new Item()
.withPrimaryKey("ForumTitle","XYZ CRM","Topic","Updates")
.withHashAndRangeKeysToDelete("ForumTitle","A partition key value",
"Product Line 1", "A sort key value"));
BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem (
forumTableWriteItems, threadTableWriteItems);
以下程序是另一个更大的示例,可以更好地理解批处理如何使用 Java 进行写入。
注意– 以下示例可能假设先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
此示例还使用 Eclipse IDE、AWS 凭证文件和 Eclipse AWS Java 项目中的 AWS 工具包。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.BatchWriteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.TableWriteItems;
import com.amazonaws.services.dynamodbv2.model.WriteRequest;
public class BatchWriteOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String forumTableName = "Forum";
static String threadTableName = "Thread";
public static void main(String[] args) throws IOException {
batchWriteMultiItems();
}
private static void batchWriteMultiItems() {
try {
// Place new item in Forum
TableWriteItems forumTableWriteItems = new TableWriteItems(forumTableName)
//Forum
.withItemsToPut(new Item()
.withPrimaryKey("Name", "Amazon RDS")
.withNumber("Threads", 0));
// Place one item, delete another in Thread
// Specify partition key and range key
TableWriteItems threadTableWriteItems = new TableWriteItems(threadTableName)
.withItemsToPut(new Item()
.withPrimaryKey("ForumName","Product
Support","Subject","Support Thread 1")
.withString("Message", "New OS Thread 1 message")
.withHashAndRangeKeysToDelete("ForumName","Subject", "Polymer Blaster",
"Support Thread 100"));
System.out.println("Processing request...");
BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem (
forumTableWriteItems, threadTableWriteItems);
do {
// Confirm no unprocessed items
Map<String, List<WriteRequest>> unprocessedItems
= outcome.getUnprocessedItems();
if (outcome.getUnprocessedItems().size() == 0) {
System.out.println("All items processed.");
} else {
System.out.println("Gathering unprocessed items...");
outcome = dynamoDB.batchWriteItemUnprocessed(unprocessedItems);
}
} while (outcome.getUnprocessedItems().size() > 0);
} catch (Exception e) {
System.err.println("Could not get items: ");
e.printStackTrace(System.err);
}
}
}
DynamoDB – 批量检索
批量检索操作返回单个或多个项目的属性。这些操作通常包括使用主键来识别所需的项目。该BatchGetItem运作受制于个人业务,以及自己独特的约束限制。
批量检索操作中的以下请求会导致拒绝 –
- 请求超过 100 个项目。
- 发出超过吞吐量的请求。
批量检索操作对可能超过限制的请求执行部分处理。
例如– 检索多个大小足以超过限制的项目的请求会导致请求处理的一部分,以及一条错误消息,指出未处理的部分。在返回未处理的项目时,创建一个回退算法解决方案来管理这个而不是限制表。
该BatchGet操作一致读取,需要为强烈一致的那些修改最终执行。它们还并行执行检索。
注意– 退回物品的顺序。DynamoDB 不会对项目进行排序。它也不表示没有请求的项目。此外,这些请求会消耗容量单位。
所有 BatchGet 操作都需要RequestItems参数,例如读取一致性、属性名称和主键。
响应– 成功的操作会产生 HTTP 200 响应,该响应指示消耗的容量单位、表处理指标和任何未处理的项目等特征。
使用 Java 进行批量检索
在BatchGet操作使用Java需要创建DynamoDB类的实例,TableKeysAndAttributes描述为项的主键值列表,并传递TableKeysAndAttributes类的实例对象的BatchGetItem方法。
以下是 BatchGet 操作的示例 –
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
TableKeysAndAttributes forumTableKeysAndAttributes = new TableKeysAndAttributes
(forumTableName);
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys (
"Title",
"Updates",
"Product Line 1"
);
TableKeysAndAttributes threadTableKeysAndAttributes = new TableKeysAndAttributes (
threadTableName);
threadTableKeysAndAttributes.addHashAndRangePrimaryKeys (
"ForumTitle",
"Topic",
"Product Line 1",
"P1 Thread 1",
"Product Line 1",
"P1 Thread 2",
"Product Line 2",
"P2 Thread 1"
);
BatchGetItemOutcome outcome = dynamoDB.batchGetItem (
forumTableKeysAndAttributes, threadTableKeysAndAttributes);
for (String tableName : outcome.getTableItems().keySet()) {
System.out.println("Table items " + tableName);
List<Item> items = outcome.getTableItems().get(tableName);
for (Item item : items) {
System.out.println(item);
}
}
您可以查看以下更大的示例。
注意– 以下程序可能假定先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
该程序还使用 Eclipse IDE、AWS 凭证文件和 Eclipse AWS Java 项目中的 AWS 工具包。
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.BatchGetItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.TableKeysAndAttributes;
import com.amazonaws.services.dynamodbv2.model.KeysAndAttributes;
public class BatchGetOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
static String forumTableName = "Forum";
static String threadTableName = "Thread";
public static void main(String[] args) throws IOException {
retrieveMultipleItemsBatchGet();
}
private static void retrieveMultipleItemsBatchGet() {
try {
TableKeysAndAttributes forumTableKeysAndAttributes =
new TableKeysAndAttributes(forumTableName);
//Create partition key
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys (
"Name",
"XYZ Melt-O-tron",
"High-Performance Processing"
);
TableKeysAndAttributes threadTableKeysAndAttributes =
new TableKeysAndAttributes(threadTableName);
//Create partition key and sort key
threadTableKeysAndAttributes.addHashAndRangePrimaryKeys (
"ForumName",
"Subject",
"High-Performance Processing",
"HP Processing Thread One",
"High-Performance Processing",
"HP Processing Thread Two",
"Melt-O-Tron",
"MeltO Thread One"
);
System.out.println("Processing...");
BatchGetItemOutcome outcome = dynamoDB.batchGetItem(forumTableKeysAndAttributes,
threadTableKeysAndAttributes);
Map<String, KeysAndAttributes> unprocessed = null;
do {
for (String tableName : outcome.getTableItems().keySet()) {
System.out.println("Table items for " + tableName);
List<Item> items = outcome.getTableItems().get(tableName);
for (Item item : items) {
System.out.println(item.toJSONPretty());
}
}
// Confirm no unprocessed items
unprocessed = outcome.getUnprocessedKeys();
if (unprocessed.isEmpty()) {
System.out.println("All items processed.");
} else {
System.out.println("Gathering unprocessed items...");
outcome = dynamoDB.batchGetItemUnprocessed(unprocessed);
}
} while (!unprocessed.isEmpty());
} catch (Exception e) {
System.err.println("Could not get items.");
System.err.println(e.getMessage());
}
}
}
DynamoDB – 查询
查询通过主键定位项目或二级索引。执行查询需要分区键和特定值,或排序键和值;可以选择通过比较进行过滤。查询的默认行为包括返回与提供的主键关联的项目的每个属性。但是,您可以使用ProjectionExpression参数指定所需的属性。
查询使用KeyConditionExpression参数来选择项目,这需要以相等条件的形式提供分区键名称和值。您还可以选择为存在的任何排序键提供附加条件。
排序键条件的一些示例是 –
| Sr.No | 条件和描述 |
|---|---|
| 1 |
x = y 如果属性 x 等于 y,则计算结果为真。 |
| 2 |
x < y 如果 x 小于 y,则计算结果为真。 |
| 3 |
x <= y 如果 x 小于或等于 y,则计算结果为真。 |
| 4 |
x > y 如果 x 大于 y,则计算结果为真。 |
| 5 |
x >= y 如果 x 大于或等于 y,则计算结果为真。 |
| 6 |
x BETWEEN y AND z 如果 x 既 >= y,又 <= z,则计算结果为真。 |
DynamoDB 还支持以下函数:begins_with (x, substr)
如果属性 x 以指定的字符串开头,则计算结果为真。
以下条件必须符合某些要求 –
-
属性名称必须以 az 或 AZ 集中的字符开头。
-
属性名称的第二个字符必须属于 az、AZ 或 0-9 集合。
-
属性名称不能使用保留字。
不符合上述约束的属性名称可以定义占位符。
查询通过按排序键顺序执行检索并使用任何存在的条件和过滤器表达式来处理。查询总是返回一个结果集,在没有匹配的情况下,它返回一个空的。
结果总是按排序键顺序和基于数据类型的顺序返回,可修改的默认值是升序。
使用 Java 查询
Java 中的查询允许您查询表和二级索引。它们需要指定分区键和相等条件,以及指定排序键和条件的选项。
Java中查询一般需要的步骤包括为目标表创建一个DynamoDB类实例、Table类实例,以及调用Table实例的查询方法接收查询对象。
对查询的响应包含一个ItemCollection对象,提供所有返回的项目。
以下示例演示了详细的查询 –
DynamoDB dynamoDB = new DynamoDB (
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("Response");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("ID = :nn")
.withValueMap(new ValueMap()
.withString(":nn", "Product Line 1#P1 Thread 1"));
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
Item item = null;
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.toJSONPretty());
}
查询方法支持多种可选参数。以下示例演示如何使用这些参数 –
Table table = dynamoDB.getTable("Response");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("ID = :nn and ResponseTM > :nn_responseTM")
.withFilterExpression("Author = :nn_author")
.withValueMap(new ValueMap()
.withString(":nn", "Product Line 1#P1 Thread 1")
.withString(":nn_responseTM", twoWeeksAgoStr)
.withString(":nn_author", "Member 123"))
.withConsistentRead(true);
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
您还可以查看以下更大的示例。
注意– 以下程序可能假定先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
此示例还使用 Eclipse IDE、AWS 凭证文件和 Eclipse AWS Java 项目中的 AWS 工具包。
package com.amazonaws.codesamples.document;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.Page;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class QueryOpSample {
static DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
static String tableName = "Reply";
public static void main(String[] args) throws Exception {
String forumName = "PolyBlaster";
String threadSubject = "PolyBlaster Thread 1";
getThreadReplies(forumName, threadSubject);
}
private static void getThreadReplies(String forumName, String threadSubject) {
Table table = dynamoDB.getTable(tableName);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Id = :v_id")
.withValueMap(new ValueMap()
.withString(":v_id", replyId));
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\ngetThreadReplies results:");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
DynamoDB – 扫描
扫描操作读取所有表项或二级索引。它的默认函数导致返回索引或表中所有项目的所有数据属性。在过滤属性中使用ProjectionExpression参数。
每次扫描都会返回一个结果集,即使没有找到匹配项,也会导致一个空集。扫描检索不超过 1MB,可选择过滤数据。
注意– 扫描的参数和过滤也适用于查询。
扫描操作的类型
过滤– 扫描操作通过过滤器表达式提供精细过滤,在扫描或查询后修改数据;在返回结果之前。表达式使用比较运算符。它们的语法类似于条件表达式,但关键属性除外,过滤表达式不允许。您不能在过滤器表达式中使用分区或排序键。
注意– 1MB 限制适用于任何过滤应用程序。
吞吐量规范– 扫描消耗吞吐量,但是,消耗侧重于项目大小而不是返回的数据。无论您请求每个属性还是仅请求几个属性,消耗量都保持不变,使用或不使用过滤器表达式也不会影响消耗量。
分页– DynamoDB 对结果进行分页,导致将结果划分为特定页面。1MB 限制适用于返回的结果,当您超过该限制时,需要再次扫描以收集其余数据。该LastEvaluatedKey值可以执行此后续扫描。只需将该值应用于ExclusiveStartkey。当LastEvaluatedKey值变为 null 时,操作已完成所有数据页。但是,非空值并不自动意味着还有更多数据。只有空值表示状态。
限制参数– 限制参数管理结果大小。DynamoDB 使用它来确定返回数据之前要处理的项目数,并且不在范围之外工作。如果您将值设置为 x,DynamoDB 将返回前 x 个匹配项。
LastEvaluatedKey 值也适用于产生部分结果的限制参数的情况。用它来完成扫描。
结果计数– 对查询和扫描的响应还包括与ScannedCount和 Count相关的信息,这些信息量化扫描/查询的项目并量化返回的项目。如果不过滤,它们的值是相同的。当您超过 1MB 时,计数仅代表已处理的部分。
Consistency – 查询结果和扫描结果是最终一致性读取,但是,您也可以设置强一致性读取。使用ConsistentRead参数更改此设置。
注意– 一致读取设置在设置为强一致时通过使用双倍容量单位来影响消耗。
性能– 由于扫描爬行全表或二级索引,查询提供比扫描更好的性能,导致响应缓慢和吞吐量消耗大。扫描最适合使用较少过滤器的小表和搜索,但是,您可以通过遵循一些最佳实践来设计精益扫描,例如避免突然、加速的读取活动和利用并行扫描。
查询找到满足给定条件的特定范围的键,其性能取决于它检索的数据量而不是键的数量。操作的参数和匹配的数量会特别影响性能。
并行扫描
扫描操作默认按顺序进行处理。然后它们以 1MB 的部分返回数据,这会提示应用程序获取下一部分。这会导致对大型表和索引的长时间扫描。
这一特性也意味着扫描可能并不总是充分利用可用的吞吐量。DynamoDB 跨多个分区分布表数据;由于其单分区操作,扫描吞吐量仍然仅限于单个分区。
此问题的解决方案来自将表或索引逻辑地划分为段。然后“工人”并行(同时)扫描段。它使用 Segment 和TotalSegments的参数来指定某些 worker 扫描的段并指定处理的段总数。
工人编号
您必须对工作器值(段参数)进行试验以实现最佳应用程序性能。
注意– 大量工作人员的并行扫描可能会消耗所有吞吐量,从而影响吞吐量。使用限制参数管理此问题,您可以使用该参数阻止单个工作人员消耗所有吞吐量。
以下是深度扫描示例。
注意– 以下程序可能假定先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
此示例还使用 Eclipse IDE、AWS 凭证文件和 Eclipse AWS Java 项目中的 AWS 工具包。
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.ScanOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
public class ScanOpSample {
static DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
static String tableName = "ProductList";
public static void main(String[] args) throws Exception {
findProductsUnderOneHun(); //finds products under 100 dollars
}
private static void findProductsUnderOneHun() {
Table table = dynamoDB.getTable(tableName);
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":pr", 100);
ItemCollection<ScanOutcome> items = table.scan (
"Price < :pr", //FilterExpression
"ID, Nomenclature, ProductCategory, Price", //ProjectionExpression
null, //No ExpressionAttributeNames
expressionAttributeValues);
System.out.println("Scanned " + tableName + " to find items under $100.");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
DynamoDB – 索引
DynamoDB 使用主键属性的索引来改进访问。它们加速应用程序访问和数据检索,并通过减少应用程序延迟来支持更好的性能。
二级索引
二级索引包含一个属性子集和一个备用键。您可以通过以索引为目标的查询或扫描操作来使用它。
其内容包括您投影或复制的属性。在创建时,您可以为索引定义一个备用键,以及您希望在索引中投影的任何属性。然后,DynamoDB 将属性复制到索引中,包括源自表的主键属性。执行完这些任务后,您只需像在表上执行一样使用查询/扫描。
DynamoDB 会自动维护所有二级索引。在项目操作上,例如添加或删除,它更新目标表上的任何索引。
DynamoDB 提供两种类型的二级索引 –
-
全局二级索引– 此索引包括分区键和排序键,可能与源表不同。由于对索引的查询/扫描能够跨越所有表数据和所有分区,它使用标签“全局”。
-
本地二级索引– 该索引与表共享一个分区键,但使用不同的排序键。它的“本地”性质源于它的所有分区范围限定为具有相同分区键值的表分区。
要使用的最佳索引类型取决于应用程序需求。考虑下表中显示的两者之间的差异 –
| Quality | 全球二级索引 | 本地二级索引 |
|---|---|---|
| Key Schema | 它使用简单或复合主键。 | 它始终使用复合主键。 |
| Key Attributes | 索引分区键和排序键可以由字符串、数字或二进制表属性组成。 | 索引的分区键是与表分区键共享的属性。排序键可以是字符串、数字或二进制表属性。 |
| Size Limits Per Partition Key Value | 它们没有尺寸限制。 | 它对与分区键值关联的索引项的总大小施加了 10GB 的最大限制。 |
| Online Index Operations | 您可以在创建表时生成它们、将它们添加到现有表或删除现有表。 | 您必须在创建表时创建它们,但不能删除它们或将它们添加到现有表中。 |
| Queries | 它允许查询覆盖整个表和每个分区。 | 它们通过查询中提供的分区键值来寻址单个分区。 |
| Consistency | 这些索引的查询仅提供最终一致的选项。 | 这些查询提供了最终一致或强一致的选项。 |
| Throughput Cost | 它包括读取和写入的吞吐量设置。查询/扫描消耗索引的容量,而不是表的容量,这也适用于表写入更新。 | 查询/扫描消耗表读取容量。表写入更新本地索引,并消耗表容量单位。 |
| Projection | 查询/扫描只能请求投影到索引中的属性,而不能检索表属性。 | 查询/扫描可以请求那些未投影的属性;此外,还会自动获取它们。 |
创建多个带有二级索引的表时,按顺序进行;意思是创建一个表并等待它达到 ACTIVE 状态,然后再创建另一个并再次等待。DynamoDB 不允许并发创建。
每个二级索引都需要特定的规格 –
-
类型– 指定本地或全局。
-
Name – 它使用与表相同的命名规则。
-
Key Schema – 仅允许顶级字符串、数字或二进制类型,索引类型决定其他要求。
-
投影属性– DynamoDB 自动投影它们,并允许任何数据类型。
-
吞吐量– 指定全局二级索引的读/写容量。
每个表的索引限制仍然是 5 个全局索引和 5 个本地索引。
您可以使用DescribeTable访问有关索引的详细信息。它返回名称、大小和项目计数。
注意– 这些值每 6 小时更新一次。
在用于访问索引数据的查询或扫描中,提供表和索引名称、结果所需的属性以及任何条件语句。DynamoDB 提供了按升序或降序返回结果的选项。
注意– 删除表也会删除所有索引。
DynamoDB – 全局二级索引
需要具有不同属性的各种查询类型的应用程序可以使用单个或多个全局二级索引来执行这些详细查询。
例如– 一个系统跟踪用户、他们的登录状态和他们的登录时间。上一个示例的增长减慢了对其数据的查询。
全局二级索引通过组织从表中选择的属性来加速查询。它们在对数据进行排序时使用主键,并且不需要与表相同的键表属性或键模式。
所有全局二级索引都必须包含一个分区键,并且可以选择排序键。索引键模式可以与表不同,索引键属性可以使用任何顶级字符串、数字或二进制表属性。
在投影中,您可以使用其他表属性,但是,查询不会从父表中检索。
属性投影
投影由从表复制到二级索引的属性集组成。投影总是与表分区键和排序键一起发生。在查询中,投影允许 DynamoDB 访问投影的任何属性;它们本质上是作为自己的表存在的。
在二级索引创建中,您必须为投影指定属性。DynamoDB 提供了三种执行此任务的方法 –
-
KEYS_ONLY – 所有索引项都由表分区和排序键值以及索引键值组成。这将创建最小的索引。
-
INCLUDE – 它包括 KEYS_ONLY 属性和指定的非关键属性。
-
ALL – 它包括所有源表属性,创建最大可能的索引。
请注意将属性投影到全局二级索引中的权衡,这与吞吐量和存储成本有关。
考虑以下几点 –
-
如果您只需要访问少数属性,并且延迟很低,则只投影您需要的那些。这降低了存储和写入成本。
-
如果应用程序频繁访问某些非关键属性,请对其进行投影,因为与扫描消耗相比,存储成本相形见绌。
-
您可以投影经常访问的大量属性,但是,这会带来很高的存储成本。
-
将 KEYS_ONLY 用于不频繁的表查询和频繁的写入/更新。这控制了大小,但仍然提供了良好的查询性能。
全局二级索引查询和扫描
您可以使用查询来访问索引中的单个或多个项目。您必须指定索引和表名、所需的属性和条件;可以选择按升序或降序返回结果。
您还可以利用扫描来获取所有索引数据。它需要表和索引名称。您可以使用过滤器表达式来检索特定数据。
表和索引数据同步
DynamoDB 自动对索引与其父表执行同步。对项目的每次修改操作都会导致异步更新,但是,应用程序不会直接写入索引。
您需要了解 DynamoDB 维护对索引的影响。在创建索引时,您指定键属性和数据类型,这意味着在写入时,这些数据类型必须匹配键模式数据类型。
在项目创建或删除时,索引以最终一致的方式更新,但是,数据更新会在几分之一秒内传播(除非发生某种类型的系统故障)。您必须考虑申请中的这种延迟。
全局二级索引中的吞吐量注意事项– 多个全局二级索引影响吞吐量。索引创建需要容量单位规范,该规范与表分开存在,导致操作消耗索引容量单位而不是表单位。
如果查询或写入超过预配置的吞吐量,这可能会导致限制。使用DescribeTable查看吞吐量设置。
读取容量– 全局二级索引提供最终的一致性。在查询中,DynamoDB 执行的供应计算与用于表的计算相同,唯一的区别是使用索引条目大小而不是项目大小。查询返回的限制仍然是 1MB,其中包括每个返回项目的属性名称大小和值。
写入容量
当写操作发生时,受影响的索引消耗写单元。写入吞吐量成本是表写入消耗的写入容量单位和索引更新消耗的单位的总和。成功的写入操作需要足够的容量,否则会导致限制。
写入成本还取决于某些因素,其中一些如下 –
-
定义索引属性的新项目或定义未定义索引属性的项目更新使用单个写入操作将项目添加到索引。
-
更新更改索引键属性值使用两次写入来删除一个项目并写入一个新项目。
-
表写入触发删除索引属性使用单个写入来擦除索引中的旧项目投影。
-
更新操作前后索引中不存在的项目不使用写入。
-
更新仅更改索引键架构中的投影属性值,而不更改索引键属性值,使用一次写入将投影属性的值更新到索引中。
所有这些因素都假定项目大小小于或等于 1KB。
全局二级索引存储
在项目写入时,DynamoDB 会自动将正确的属性集复制到属性必须存在的任何索引。这会通过向您的帐户收取表格项目存储和属性存储费用来影响您的帐户。使用的空间来自这些数量的总和 –
- 表主键的字节大小
- 索引键属性的字节大小
- 投影属性的字节大小
- 每个索引项 100 字节的开销
您可以通过估计平均项目大小并乘以具有全局二级索引键属性的表项目的数量来估计存储需求。
DynamoDB 不会为具有定义为索引分区或排序键的未定义属性的表项目写入项目数据。
全球二级指数原油
使用与GlobalSecondaryIndexes参数配对的CreateTable操作创建具有全局二级索引的表。您必须指定一个属性作为索引分区键,或者使用另一个属性作为索引排序键。所有索引键属性必须是字符串、数字或二进制标量。您还必须提供吞吐量设置,包括ReadCapacityUnits和WriteCapacityUnits。
使用UpdateTable再次使用 GlobalSecondaryIndexes 参数将全局二级索引添加到现有表。
在此操作中,您必须提供以下输入 –
- 索引名称
- 键模式
- 投影属性
- 吞吐量设置
通过添加全局二级索引,由于项目量、预计属性量、写入容量和写入活动,大型表可能需要大量时间。使用CloudWatch指标来监控流程。
使用DescribeTable获取全局二级索引的状态信息。它返回GlobalSecondaryIndexes的四个IndexStatus之一 –
-
CREATING – 它表示索引的构建阶段及其不可用。
-
ACTIVE – 它表示索引已准备好使用。
-
UPDATING – 表示吞吐量设置的更新状态。
-
DELETING – 它指示索引的删除状态,及其永久不可用。
在加载/回填阶段更新全局二级索引预置吞吐量设置(DynamoDB 将属性写入索引并跟踪添加/删除/更新的项目)。使用UpdateTable执行此操作。
您应该记住,在回填阶段您不能添加/删除其他索引。
使用 UpdateTable 删除全局二级索引。它允许每个操作只删除一个索引,但是,您可以同时运行多个操作,最多五个。删除过程不会影响父表的读/写活动,但在操作完成之前您不能添加/删除其他索引。
使用 Java 处理全局二级索引
通过 CreateTable 创建带有索引的表。只需创建一个 DynamoDB 类实例,一个用于请求信息的CreateTableRequest类实例,并将请求对象传递给 CreateTable 方法。
以下程序是一个简短的示例 –
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
// Attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("City")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Date")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Wind")
.withAttributeType("N"));
// Key schema of the table
ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("City")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Date")
.withKeyType(KeyType.RANGE)); //Sort key
// Wind index
GlobalSecondaryIndex windIndex = new GlobalSecondaryIndex()
.withIndexName("WindIndex")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 10)
.withWriteCapacityUnits((long) 1))
.withProjection(new Projection().withProjectionType(ProjectionType.ALL));
ArrayList<KeySchemaElement> indexKeySchema = new ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Date")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Wind")
.withKeyType(KeyType.RANGE)); //Sort key
windIndex.setKeySchema(indexKeySchema);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName("ClimateInfo")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 5)
.withWriteCapacityUnits((long) 1))
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(tableKeySchema)
.withGlobalSecondaryIndexes(windIndex);
Table table = dynamoDB.createTable(createTableRequest);
System.out.println(table.getDescription());
使用DescribeTable检索索引信息。首先,创建一个 DynamoDB 类实例。然后创建一个 Table 类实例来定位一个索引。最后,将表传递给 describe 方法。
这是一个简短的例子 –
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ClimateInfo");
TableDescription tableDesc = table.describe();
Iterator<GlobalSecondaryIndexDescription> gsiIter =
tableDesc.getGlobalSecondaryIndexes().iterator();
while (gsiIter.hasNext()) {
GlobalSecondaryIndexDescription gsiDesc = gsiIter.next();
System.out.println("Index data " + gsiDesc.getIndexName() + ":");
Iterator<KeySchemaElement> kse7Iter = gsiDesc.getKeySchema().iterator();
while (kseIter.hasNext()) {
KeySchemaElement kse = kseIter.next();
System.out.printf("\t%s: %s\n", kse.getAttributeName(), kse.getKeyType());
}
Projection projection = gsiDesc.getProjection();
System.out.println("\tProjection type: " + projection.getProjectionType());
if (projection.getProjectionType().toString().equals("INCLUDE")) {
System.out.println("\t\tNon-key projected attributes: "
+ projection.getNonKeyAttributes());
}
}
使用 Query 可以像执行表查询一样执行索引查询。只需创建一个 DynamoDB 类实例,为目标索引创建一个 Table 类实例,为特定索引创建一个 Index 类实例,并将索引和查询对象传递给查询方法。
查看以下代码以更好地理解 –
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ClimateInfo");
Index index = table.getIndex("WindIndex");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("#d = :v_date and Wind = :v_wind")
.withNameMap(new NameMap()
.with("#d", "Date"))
.withValueMap(new ValueMap()
.withString(":v_date","2016-05-15")
.withNumber(":v_wind",0));
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
System.out.println(iter.next().toJSONPretty());
}
以下程序是一个更大的例子,可以更好地理解 –
注意– 以下程序可能假定先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
此示例还使用 Eclipse IDE、AWS 凭证文件和 Eclipse AWS Java 项目中的 AWS 工具包。
import java.util.ArrayList;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Index;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.GlobalSecondaryIndex;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.Projection;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
public class GlobalSecondaryIndexSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
public static String tableName = "Bugs";
public static void main(String[] args) throws Exception {
createTable();
queryIndex("CreationDateIndex");
queryIndex("NameIndex");
queryIndex("DueDateIndex");
}
public static void createTable() {
// Attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("BugID")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Name")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("CreationDate")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("DueDate")
.withAttributeType("S"));
// Table Key schema
ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>();
tableKeySchema.add (new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add (new KeySchemaElement()
.withAttributeName("Name")
.withKeyType(KeyType.RANGE)); //Sort key
// Indexes' initial provisioned throughput
ProvisionedThroughput ptIndex = new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L);
// CreationDateIndex
GlobalSecondaryIndex creationDateIndex = new GlobalSecondaryIndex()
.withIndexName("CreationDateIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("CreationDate")
.withKeyType(KeyType.HASH), //Partition key
new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.RANGE)) //Sort key
.withProjection(new Projection()
.withProjectionType("INCLUDE")
.withNonKeyAttributes("Description", "Status"));
// NameIndex
GlobalSecondaryIndex nameIndex = new GlobalSecondaryIndex()
.withIndexName("NameIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("Name")
.withKeyType(KeyType.HASH), //Partition key
new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.RANGE)) //Sort key
.withProjection(new Projection()
.withProjectionType("KEYS_ONLY"));
// DueDateIndex
GlobalSecondaryIndex dueDateIndex = new GlobalSecondaryIndex()
.withIndexName("DueDateIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("DueDate")
.withKeyType(KeyType.HASH)) //Partition key
.withProjection(new Projection()
.withProjectionType("ALL"));
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withProvisionedThroughput( new ProvisionedThroughput()
.withReadCapacityUnits( (long) 1)
.withWriteCapacityUnits( (long) 1))
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(tableKeySchema)
.withGlobalSecondaryIndexes(creationDateIndex, nameIndex, dueDateIndex);
System.out.println("Creating " + tableName + "...");
dynamoDB.createTable(createTableRequest);
// Pause for active table state
System.out.println("Waiting for ACTIVE state of " + tableName);
try {
Table table = dynamoDB.getTable(tableName);
table.waitForActive();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void queryIndex(String indexName) {
Table table = dynamoDB.getTable(tableName);
System.out.println
("\n*****************************************************\n");
System.out.print("Querying index " + indexName + "...");
Index index = table.getIndex(indexName);
ItemCollection<QueryOutcome> items = null;
QuerySpec querySpec = new QuerySpec();
if (indexName == "CreationDateIndex") {
System.out.println("Issues filed on 2016-05-22");
querySpec.withKeyConditionExpression("CreationDate = :v_date and begins_with
(BugID, :v_bug)")
.withValueMap(new ValueMap()
.withString(":v_date","2016-05-22")
.withString(":v_bug","A-"));
items = index.query(querySpec);
} else if (indexName == "NameIndex") {
System.out.println("Compile error");
querySpec.withKeyConditionExpression("Name = :v_name and begins_with
(BugID, :v_bug)")
.withValueMap(new ValueMap()
.withString(":v_name","Compile error")
.withString(":v_bug","A-"));
items = index.query(querySpec);
} else if (indexName == "DueDateIndex") {
System.out.println("Items due on 2016-10-15");
querySpec.withKeyConditionExpression("DueDate = :v_date")
.withValueMap(new ValueMap()
.withString(":v_date","2016-10-15"));
items = index.query(querySpec);
} else {
System.out.println("\nInvalid index name");
return;
}
Iterator<Item> iterator = items.iterator();
System.out.println("Query: getting result...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
DynamoDB – 本地二级索引
某些应用程序仅使用主键执行查询,但某些情况下会受益于备用排序键。通过创建单个或多个本地二级索引,允许您的应用程序进行选择。
复杂的数据访问要求,例如组合数百万个项目,需要执行更高效的查询/扫描。本地二级索引为分区键值提供备用排序键。它们还保存所有或某些表属性的副本。它们按表分区键组织数据,但使用不同的排序键。
使用本地二级索引消除了对整个表扫描的需要,并允许使用排序键进行简单快速的查询。
所有本地二级索引必须满足某些条件 –
- 相同的分区键和源表分区键。
- 只有一个标量属性的排序键。
- 源表排序键作为非键属性的投影。
所有本地二级索引都会自动保存父表中的分区和排序键。在查询中,这意味着有效收集投影属性,以及检索未投影的属性。
本地二级索引的存储限制仍然是每个分区键值 10GB,其中包括所有表项和共享分区键值的索引项。
投影属性
由于复杂性,某些操作需要额外的读取/获取。这些操作会消耗大量吞吐量。投影允许您通过隔离这些属性来避免昂贵的获取和执行丰富的查询。请记住,投影由复制到二级索引中的属性组成。
在制作二级索引时,您指定投影的属性。回想一下 DynamoDB 提供的三个选项:KEYS_ONLY、INCLUDE 和 ALL。
在投影中选择某些属性时,请考虑相关的成本权衡 –
-
如果您只投影一小组必要的属性,则可以显着降低存储成本。
-
如果您投影经常访问的非关键属性,则可以用存储成本抵消扫描成本。
-
如果您投影大部分或所有非关键属性,这将最大限度地提高灵活性并降低吞吐量(无检索);然而,存储成本上升。
-
如果您将 KEYS_ONLY 用于频繁的写入/更新和不频繁的查询,它会最小化大小,但会保持查询准备。
本地二级索引创建
使用CreateTable的LocalSecondaryIndex参数创建单个或多个本地二级索引。您必须为排序键指定一个非键属性。在创建表时,您创建本地二级索引。删除时,您将删除这些索引。
具有本地二级索引的表必须遵守每个分区键值 10GB 的大小限制,但可以存储任意数量的项目。
本地二级索引查询和扫描
当索引中的多个项目共享排序键值时,对本地二级索引的查询操作将返回具有匹配分区键值的所有项目。匹配项不会按特定顺序返回。对本地二级索引的查询使用最终一致性或强一致性,强一致性读取提供最新值。
扫描操作返回所有本地二级索引数据。扫描要求您提供表和索引名称,并允许使用过滤器表达式来丢弃数据。
项目写作
创建本地二级索引时,指定排序键属性及其数据类型。编写项目时,如果项目定义了索引键的属性,则其类型必须与键模式的数据类型相匹配。
DynamoDB 对表项和本地二级索引项没有一对一的关系要求。具有多个本地二级索引的表比那些较少的表具有更高的写入成本。
本地二级索引中的吞吐量注意事项
查询的读取容量消耗取决于数据访问的性质。查询使用最终一致性或强一致性,强一致性读取使用一个单元,而最终一致性读取使用半个单元。
结果限制包括最大 1MB 大小。结果大小来自四舍五入到最接近的 4KB 的匹配索引项大小的总和,并且匹配表项大小也四舍五入到最接近的 4KB。
写入容量消耗保持在预配单位内。通过查找表写入中消耗的单位和更新索引中消耗的单位的总和来计算总配置成本。
您还可以考虑影响成本的关键因素,其中一些可以是 –
-
当您编写定义索引属性的项目或更新项目以定义未定义的索引属性时,会发生单个写入操作。
-
当表更新更改索引键属性值时,会发生两次写入以删除然后添加一个项目。
-
当写入导致删除索引属性时,会发生一次写入以删除旧项目投影。
-
如果在更新之前或之后索引中不存在某个项目,则不会发生写入。
本地二级索引存储
在表项写入时,DynamoDB 会自动将正确的属性集复制到所需的本地二级索引。这会向您的帐户收费。使用的空间由表主键字节大小、索引键属性字节大小、任何当前预计的属性字节大小以及每个索引项的 100 字节开销的总和得出。
估计存储量是通过估计平均索引项大小并乘以表项数量得到的。
使用 Java 处理本地二级索引
通过首先创建 DynamoDB 类实例来创建本地二级索引。然后,使用必要的请求信息创建一个 CreateTableRequest 类实例。最后,使用 createTable 方法。
例子
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
CreateTableRequest createTableRequest = new
CreateTableRequest().withTableName(tableName);
//Provisioned Throughput
createTableRequest.setProvisionedThroughput (
new ProvisionedThroughput()
.withReadCapacityUnits((long)5)
.withWriteCapacityUnits(( long)5));
//Attributes
ArrayList<AttributeDefinition> attributeDefinitions =
new ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Make")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Model")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Line")
.withAttributeType("S"));
createTableRequest.setAttributeDefinitions(attributeDefinitions);
//Key Schema
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Make")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Model")
.withKeyType(KeyType.RANGE)); //Sort key
createTableRequest.setKeySchema(tableKeySchema);
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Make")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Line")
.withKeyType(KeyType.RANGE)); //Sort key
Projection projection = new Projection()
.withProjectionType(ProjectionType.INCLUDE);
ArrayList<String> nonKeyAttributes = new ArrayList<String>();
nonKeyAttributes.add("Type");
nonKeyAttributes.add("Year");
projection.setNonKeyAttributes(nonKeyAttributes);
LocalSecondaryIndex localSecondaryIndex = new LocalSecondaryIndex()
.withIndexName("ModelIndex")
.withKeySchema(indexKeySchema)
.withProjection(p rojection);
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
localSecondaryIndexes.add(localSecondaryIndex);
createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes);
Table table = dynamoDB.createTable(createTableRequest);
System.out.println(table.getDescription());
使用 describe 方法检索有关本地二级索引的信息。只需创建一个 DynamoDB 类实例,创建一个 Table 类实例,然后将表传递给 describe 方法。
例子
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
Table table = dynamoDB.getTable(tableName);
TableDescription tableDescription = table.describe();
List<LocalSecondaryIndexDescription> localSecondaryIndexes =
tableDescription.getLocalSecondaryIndexes();
Iterator<LocalSecondaryIndexDescription> lsiIter =
localSecondaryIndexes.iterator();
while (lsiIter.hasNext()) {
LocalSecondaryIndexDescription lsiDescription = lsiIter.next();
System.out.println("Index info " + lsiDescription.getIndexName() + ":");
Iterator<KeySchemaElement> kseIter = lsiDescription.getKeySchema().iterator();
while (kseIter.hasNext()) {
KeySchemaElement kse = kseIter.next();
System.out.printf("\t%s: %s\n", kse.getAttributeName(), kse.getKeyType());
}
Projection projection = lsiDescription.getProjection();
System.out.println("\tProjection type: " + projection.getProjectionType());
if (projection.getProjectionType().toString().equals("INCLUDE")) {
System.out.println("\t\tNon-key projected attributes: " +
projection.getNonKeyAttributes());
}
}
使用与表查询相同的步骤执行查询。只需创建一个 DynamoDB 类实例、一个 Table 类实例、一个 Index 类实例、一个查询对象,并使用查询方法。
例子
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
Table table = dynamoDB.getTable(tableName);
Index index = table.getIndex("LineIndex");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Make = :v_make and Line = :v_line")
.withValueMap(new ValueMap()
.withString(":v_make", "Depault")
.withString(":v_line", "SuperSawz"));
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> itemsIter = items.iterator();
while (itemsIter.hasNext()) {
Item item = itemsIter.next();
System.out.println(item.toJSONPretty());
}
您还可以查看以下示例。
注意– 以下示例可能假设先前创建的数据源。在尝试执行之前,获取支持库并创建必要的数据源(具有所需特征的表或其他参考源)。
以下示例还在 Eclipse AWS Java 项目中使用 Eclipse IDE、AWS 凭证文件和 AWS Toolkit。
例子
import java.util.ArrayList;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Index;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.PutItemOutcome;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.LocalSecondaryIndex;
import com.amazonaws.services.dynamodbv2.model.Projection;
import com.amazonaws.services.dynamodbv2.model.ProjectionType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.ReturnConsumedCapacity;
import com.amazonaws.services.dynamodbv2.model.Select;
public class LocalSecondaryIndexSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
public static String tableName = "ProductOrders";
public static void main(String[] args) throws Exception {
createTable();
query(null);
query("IsOpenIndex");
query("OrderCreationDateIndex");
}
public static void createTable() {
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 1)
.withWriteCapacityUnits((long) 1));
// Table partition and sort keys attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("CustomerID")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OrderID")
.withAttributeType("N"));
// Index primary key attributes
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OrderDate")
.withAttributeType("N"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OpenStatus")
.withAttributeType("N"));
createTableRequest.setAttributeDefinitions(attributeDefinitions);
// Table key schema
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("OrderID")
.withKeyType(KeyType.RANGE)); //Sort key
createTableRequest.setKeySchema(tableKeySchema);
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
// OrderDateIndex
LocalSecondaryIndex orderDateIndex = new LocalSecondaryIndex()
.withIndexName("OrderDateIndex");
// OrderDateIndex key schema
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("OrderDate")
.withKeyType(KeyType.RANGE)); //Sort key
orderDateIndex.setKeySchema(indexKeySchema);
// OrderCreationDateIndex projection w/attributes list
Projection projection = new Projection()
.withProjectionType(ProjectionType.INCLUDE);
ArrayList<String> nonKeyAttributes = new ArrayList<String>();
nonKeyAttributes.add("ProdCat");
nonKeyAttributes.add("ProdNomenclature");
projection.setNonKeyAttributes(nonKeyAttributes);
orderCreationDateIndex.setProjection(projection);
localSecondaryIndexes.add(orderDateIndex);
// IsOpenIndex
LocalSecondaryIndex isOpenIndex = new LocalSecondaryIndex()
.withIndexName("IsOpenIndex");
// OpenStatusIndex key schema
indexKeySchema = new ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("OpenStatus")
.withKeyType(KeyType.RANGE)); //Sort key
// OpenStatusIndex projection
projection = new Projection() .withProjectionType(ProjectionType.ALL);
OpenStatusIndex.setKeySchema(indexKeySchema);
OpenStatusIndex.setProjection(projection);
localSecondaryIndexes.add(OpenStatusIndex);
// Put definitions in CreateTable request
createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes);
System.out.println("Spawning table " + tableName + "...");
System.out.println(dynamoDB.createTable(createTableRequest));
// Pause for ACTIVE status
System.out.println("Waiting for ACTIVE table:" + tableName);
try {
Table table = dynamoDB.getTable(tableName);
table.waitForActive();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void query(String indexName) {
Table table = dynamoDB.getTable(tableName);
System.out.println("\n*************************************************\n");
System.out.println("Executing query on" + tableName);
QuerySpec querySpec = new QuerySpec()
.withConsistentRead(true)
.withScanIndexForward(true)
.withReturnConsumedCapacity(ReturnConsumedCapacity.TOTAL);
if (indexName == "OpenStatusIndex") {
System.out.println("\nEmploying index: '" + indexName
+ "' open orders for this customer.");
System.out.println(
"Returns only user-specified attribute list\n");
Index index = table.getIndex(indexName);
querySpec.withKeyConditionExpression("CustomerID = :v_custmid and
OpenStatus = :v_openstat")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]")
.withNumber(":v_openstat", 1));
querySpec.withProjectionExpression(
"OrderDate, ProdCat, ProdNomenclature, OrderStatus");
ItemCollection<QueryOutcome> items = index.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
} else if (indexName == "OrderDateIndex") {
System.out.println("\nUsing index: '" + indexName
+ "': this customer's orders placed after 05/22/2016.");
System.out.println("Projected attributes are returned\n");
Index index = table.getIndex(indexName);
querySpec.withKeyConditionExpression("CustomerID = :v_custmid and OrderDate
>= :v_ordrdate")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]")
.withNumber(":v_ordrdate", 20160522));
querySpec.withSelect(Select.ALL_PROJECTED_ATTRIBUTES);
ItemCollection<QueryOutcome> items = index.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
} else {
System.out.println("\nNo index: All Jane's orders by OrderID:\n");
querySpec.withKeyConditionExpression("CustomerID = :v_custmid")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]"));
ItemCollection<QueryOutcome> items = table.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
}
DynamoDB – 聚合
DynamoDB 不提供聚合功能。您必须创造性地使用查询、扫描、索引和各种工具来执行这些任务。在所有这些中,这些操作中查询/扫描的吞吐量开销可能很大。
您还可以选择将库和其他工具用于您首选的 DynamoDB 编码语言。在使用 DynamoDB 之前确保它们与 DynamoDB 兼容。
计算最大值或最小值
利用结果的升序/降序存储顺序、限制参数和任何设置顺序的参数来查找最高值和最低值。
例如 –
Map<String, AttributeValue> eaval = new HashMap<>();
eaval.put(":v1", new AttributeValue().withS("hashval"));
queryExpression = new DynamoDBQueryExpression<Table>()
.withIndexName("yourindexname")
.withKeyConditionExpression("HK = :v1")
.withExpressionAttributeValues(values)
.withScanIndexForward(false); //descending order
queryExpression.setLimit(1);
QueryResultPage<Lookup> res =
dynamoDBMapper.queryPage(Table.class, queryExpression);
计算计数
使用DescribeTable获取表项的计数,但请注意,它提供的是陈旧数据。此外,利用 Java getScannedCount 方法。
利用LastEvaluatedKey确保它提供所有结果。
例如 –
ScanRequest scanRequest = new ScanRequest().withTableName(yourtblName);
ScanResult yourresult = client.scan(scanRequest);
System.out.println("#items:" + yourresult.getScannedCount());
计算平均值和总和
在处理之前利用索引和查询/扫描来检索和过滤值。然后只需通过对象对这些值进行操作。
DynamoDB – 访问控制
DynamoDB 使用您提供的凭据对请求进行身份验证。这些凭证是必需的,并且必须包括 AWS 资源访问权限。这些权限几乎涵盖 DynamoDB 的各个方面,直至操作或功能的次要特性。
权限类型
在本节中,我们将讨论 DynamoDB 中的各种权限和资源访问。
验证用户
在注册时,您提供了一个密码和电子邮件,作为 root 凭据。DynamoDB 将此数据与您的 AWS 账户相关联,并使用它来提供对所有资源的完全访问权限。
AWS 建议您仅将根凭证用于创建管理账户。这允许您创建具有较少权限的 IAM 账户/用户。IAM 用户是使用 IAM 服务生成的其他账户。他们的访问权限/特权包括访问安全页面和某些自定义权限,如表格修改。
访问密钥为其他帐户和访问提供了另一种选择。使用它们来授予访问权限,并避免在某些情况下手动授予访问权限。通过允许通过身份提供者进行访问,联合用户提供了另一种选择。
行政
AWS 资源仍归账户所有。权限策略管理授予生成或访问资源的权限。管理员将权限策略与 IAM 身份相关联,即角色、组、用户和服务。他们还将权限附加到资源。
权限指定用户、资源和操作。注意管理员只是具有管理员权限的帐户。
运营与资源
表仍然是 DynamoDB 中的主要资源。子资源用作附加资源,例如流和索引。这些资源使用唯一名称,下表中提到了其中一些 –
| Type | ARN(亚马逊资源名称) |
|---|---|
| Stream | arn:aws:dynamodb:region:account-id:table/table-name/stream/stream-label |
| Index | arn:aws:dynamodb:region:account-id:table/table-name/index/index-name |
| Table | arn:aws:dynamodb:region:account-id:table/table-name |
所有权
资源所有者被定义为产生资源的 AWS 账户,或负责资源创建中请求身份验证的委托人实体账户。考虑它在 DynamoDB 环境中的功能 –
-
在使用 root 凭据创建表时,您的帐户仍然是资源所有者。
-
在创建 IAM 用户并授予用户创建表的权限时,您的账户仍然是资源所有者。
-
在创建 IAM 用户并授予该用户以及任何能够担任该角色的人创建表的权限时,您的账户仍然是资源所有者。
管理资源访问
访问管理主要需要关注描述用户和资源访问的权限策略。您将策略与 IAM 身份或资源相关联。但是,DynamoDB 仅支持 IAM/身份策略。
基于身份 (IAM) 的策略允许您通过以下方式授予权限 –
- 为用户或组附加权限。
- 将权限附加到角色以获得跨账户权限。
其他 AWS 允许基于资源的策略。这些策略允许访问诸如 S3 存储桶之类的内容。
政策要素
政策定义了行动、效果、资源和委托人;并授予执行这些操作的权限。
注意– API 操作可能需要多个操作的权限。
仔细看看以下政策要素 –
-
Resource – ARN 标识了这一点。
-
Action – 关键字标识这些资源操作,以及是允许还是拒绝。
-
Effect – 它指定用户请求操作的效果,这意味着允许或拒绝,默认为拒绝。
-
Principal – 这标识了附加到策略的用户。
使适应
在授予权限时,您可以指定策略何时处于活动状态(例如在特定日期)的条件。使用条件键表达条件,包括 AWS 系统范围内的键和 DynamoDB 键。本教程稍后将详细讨论这些键。
控制台权限
用户需要某些基本权限才能使用控制台。他们还需要其他标准服务中的控制台权限 –
- 云观察
- 数据管道
- 身份和访问管理
- 通知服务
- 拉姆达
如果 IAM 策略被证明过于有限,用户将无法有效地使用控制台。此外,您无需担心仅调用 CLI 或 API 的用户的权限。
常用 Iam 策略
AWS 使用独立的 IAM 托管策略涵盖权限方面的常见操作。它们提供关键权限,使您可以避免对必须授予的内容进行深入调查。
其中一些如下 –
-
AmazonDynamoDBReadOnlyAccess – 它通过控制台提供只读访问。
-
AmazonDynamoDBFullAccess – 它通过控制台提供完全访问权限。
-
AmazonDynamoDBFullAccesswithDataPipeline – 它通过控制台提供完全访问权限,并允许使用数据管道导出/导入。
您当然也可以制定自定义策略。
授予权限:使用 Shell
您可以使用 Javascript shell 授予权限。以下程序显示了典型的权限策略 –
{
"Version": "2016-05-22",
"Statement": [
{
"Sid": "DescribeQueryScanToolsTable",
"Effect": "Deny",
"Action": [
"dynamodb:DescribeTable",
"dynamodb:Query",
"dynamodb:Scan"
],
"Resource": "arn:aws:dynamodb:us-west-2:account-id:table/Tools"
}
]
}
您可以查看以下三个示例 –
阻止用户执行任何表操作。
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "AllAPIActionsOnTools",
"Effect": "Deny",
"Action": "dynamodb:*",
"Resource": "arn:aws:dynamodb:us-west-2:155556789012:table/Tools"
}
]
}
阻止对表及其索引的访问。
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "AccessAllIndexesOnTools",
"Effect": "Deny",
"Action": [
"dynamodb:*"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:155556789012:table/Tools",
"arn:aws:dynamodb:us-west-2:155556789012:table/Tools/index/*"
]
}
]
}
阻止用户进行预留容量产品购买。
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "BlockReservedCapacityPurchases",
"Effect": "Deny",
"Action": "dynamodb:PurchaseReservedCapacityOfferings",
"Resource": "arn:aws:dynamodb:us-west-2:155556789012:*"
}
]
}
授予权限:使用 GUI 控制台
您还可以使用 GUI 控制台创建 IAM 策略。首先,从导航窗格中选择表。在表列表中,选择目标表并按照以下步骤操作。
步骤 1 – 选择访问控制选项卡。
步骤 2 – 选择身份提供者、操作和策略属性。输入所有设置后选择创建策略。
Step 3 – 选择Attach policy instructions,并完成每个必需的步骤以将策略与适当的 IAM 角色相关联。
DynamoDB – 权限 API
DynamoDB API 提供了大量需要权限的操作。在设置权限时,您必须建立允许的操作、允许的资源以及每个操作的条件。
您可以在策略的 Action 字段中指定操作。在策略的 Resource 字段中指定资源值。但请确保您使用包含 API 操作的 Dynamodb: 前缀的正确语法。
例如 – dynamodb:CreateTable
您还可以使用条件键来过滤权限。
权限和 API 操作
仔细查看下表中给出的 API 操作和相关权限 –
| API Operation | 必要的许可 |
|---|---|
| BatchGetItem | dynamodb:BatchGetItem |
| BatchWriteItem | dynamodb:BatchWriteItem |
| CreateTable | 动态数据库:创建表 |
| DeleteItem | 动态数据库:删除项目 |
| DeleteTable | 动态数据库:删除表 |
| DescribeLimits | dynamodb:DescribeLimits |
| DescribeReservedCapacity | dynamodb:DescribeReservedCapacity |
| DescribeReservedCapacityOfferings | dynamodb:DescribeReservedCapacityOfferings |
| DescribeStream | dynamodb:DescribeStream |
| DescribeTable | 动态数据库:描述表 |
| GetItem | 动态数据库:获取项目 |
| GetRecords | 动态数据库:获取记录 |
| GetShardIterator | dynamodb:GetShardIterator |
| ListStreams | dynamodb:ListStreams |
| ListTables | dynamodb:ListTables |
| PurchaseReservedCapacityOfferings | dynamodb:PurchaseReservedCapacityOfferings |
| PutItem | dynamodb:PutItem |
| Query | 动态数据库:查询 |
| Scan | 动态数据库:扫描 |
| UpdateItem | 动态数据库:更新项 |
| UpdateTable | 动态数据库:更新表 |
资源
在下表中,您可以查看与每个允许的 API 操作相关的资源 –
| API Operation | 资源 |
|---|---|
| BatchGetItem | arn:aws:dynamodb:region:account-id:table/table-name |
| BatchWriteItem | arn:aws:dynamodb:region:account-id:table/table-name |
| CreateTable | arn:aws:dynamodb:region:account-id:table/table-name |
| DeleteItem | arn:aws:dynamodb:region:account-id:table/table-name |
| DeleteTable | arn:aws:dynamodb:region:account-id:table/table-name |
| DescribeLimits | arn:aws:dynamodb:region:account-id:* |
| DescribeReservedCapacity | arn:aws:dynamodb:region:account-id:* |
| DescribeReservedCapacityOfferings | arn:aws:dynamodb:region:account-id:* |
| DescribeStream | arn:aws:dynamodb:region:account-id:table/table-name/stream/stream-label |
| DescribeTable | arn:aws:dynamodb:region:account-id:table/table-name |
| GetItem | arn:aws:dynamodb:region:account-id:table/table-name |
| GetRecords | arn:aws:dynamodb:region:account-id:table/table-name/stream/stream-label |
| GetShardIterator | arn:aws:dynamodb:region:account-id:table/table-name/stream/stream-label |
| ListStreams | arn:aws:dynamodb:region:account-id:table/table-name/stream/* |
| ListTables | * |
| PurchaseReservedCapacityOfferings | arn:aws:dynamodb:region:account-id:* |
| PutItem | arn:aws:dynamodb:region:account-id:table/table-name |
| Query |
arn:aws:dynamodb:region:account-id:table/table-name 或者 arn:aws:dynamodb:region:account-id:table/table-name/index/index-name |
| Scan |
arn:aws:dynamodb:region:account-id:table/table-name 或者 arn:aws:dynamodb:region:account-id:table/table-name/index/index-name |
| UpdateItem | arn:aws:dynamodb:region:account-id:table/table-name |
| UpdateTable | arn:aws:dynamodb:region:account-id:table/table-name |
DynamoDB – 条件
在授予权限时,DynamoDB 允许通过带有条件键的详细 IAM 策略为它们指定条件。这支持诸如访问特定项目和属性之类的设置。
注意– DynamoDB 不支持任何标签。
精细化管控
有几个条件允许特定于项目和属性,例如根据用户帐户授予对特定项目的只读访问权限。使用管理安全凭证的有条件的 IAM 策略实施此级别的控制。然后简单地将策略应用到所需的用户、组和角色。Web Identity Federation(稍后讨论的主题)还提供了一种通过 Amazon、Facebook 和 Google 登录来控制用户访问的方法。
IAM 策略的条件元素实现访问控制。您只需将其添加到策略中即可。其使用示例包括拒绝或允许访问表项和属性。条件元素还可以使用条件键来限制权限。
您可以查看以下两个条件键示例 –
-
dynamodb:LeadingKeys – 它可以防止没有与分区键值匹配的 ID 的用户访问项目。
-
dynamodb:Attributes – 它阻止用户访问或操作列出的属性之外的属性。
在评估时,IAM 策略会产生 true 或 false 值。如果任何部分评估为 false,则整个策略评估为 false,从而导致拒绝访问。请务必在条件键中指定所有必需的信息,以确保用户具有适当的访问权限。
预定义条件键
AWS 提供了一组适用于所有服务的预定义条件键。它们在检查用户和访问时支持广泛的用途和精细的细节。
注意– 条件键区分大小写。
您可以查看以下服务特定键的选择 –
-
dynamodb:LeadingKey – 它代表表的第一个键属性;分区键。在条件中使用 ForAllValues 修饰符。
-
dynamodb:Select – 它代表查询/扫描请求选择参数。它的值必须是 ALL_ATTRIBUTES、ALL_PROJECTED_ATTRIBUTES、SPECIFIC_ATTRIBUTES 或 COUNT。
-
dynamodb:Attributes – 它表示请求中的属性名称列表,或从请求返回的属性。它的值及其功能类似于 API 操作参数,例如,BatchGetItem 使用 AttributesToGet。
-
dynamodb:ReturnValues – 它代表请求的 ReturnValues 参数,可以使用这些值:ALL_OLD、UPDATED_OLD、ALL_NEW、UPDATED_NEW 和 NONE。
-
dynamodb:ReturnConsumedCapacity – 它代表请求的 ReturnConsumedCapacity 参数,可以使用这些值:TOTAL 和 NONE。
DynamoDB – Web 身份联合
Web Identity Federation 允许您简化大型用户组的身份验证和授权。您可以跳过个人帐户的创建,并要求用户登录到身份提供商以获取临时凭证或令牌。它使用 AWS Security Token Service (STS) 来管理凭证。应用程序使用这些令牌与服务交互。
Web Identity Federation 还支持其他身份提供商,例如 – Amazon、Google 和 Facebook。
功能– 在使用中,Web 身份联合首先调用身份提供者进行用户和应用程序身份验证,提供者返回一个令牌。这会导致应用程序调用 AWS STS 并传递令牌以进行输入。STS 授权应用程序并授予它临时访问凭证,这允许应用程序使用 IAM 角色并基于策略访问资源。
实施 Web 身份联合
您必须在使用前执行以下三个步骤 –
-
使用受支持的第三方身份提供商注册为开发人员。
-
向提供商注册您的应用程序以获取应用程序 ID。
-
创建一个或多个 IAM 角色,包括策略附件。您必须为每个应用程序的每个提供商使用一个角色。
承担您的一个 IAM 角色以使用 Web Identity Federation。然后您的应用程序必须执行一个三步过程 –
- 验证
- 凭证获取
- 资源访问
第一步,您的应用程序使用自己的接口调用提供程序,然后管理令牌流程。
然后第二步管理令牌并要求您的应用程序向 AWS STS发送AssumeRoleWithWebIdentity请求。该请求包含第一个令牌、提供者应用程序 ID 和 IAM 角色的 ARN。STS 提供的凭据设置为在一段时间后过期。
在最后一步中,您的应用程序会收到来自 STS 的响应,其中包含 DynamoDB 资源的访问信息。它由访问凭证、到期时间、角色和角色 ID 组成。
DynamoDB – 数据管道
Data Pipeline 允许向/从表、文件或 S3 存储桶导出和导入数据。这当然在备份、测试以及类似的需求或场景中证明是有用的。
在导出中,您使用 Data Pipeline 控制台创建新管道并启动 Amazon EMR (Elastic MapReduce) 集群来执行导出。EMR 从 DynamoDB 读取数据并写入目标。我们将在本教程后面详细讨论 EMR。
在导入操作中,您使用数据管道控制台,它创建管道并启动 EMR 来执行导入。它从源读取数据并写入目标。
注– 导出/导入操作会根据所使用的服务产生成本,特别是 EMR 和 S3。
使用数据管道
使用 Data Pipeline 时,您必须指定操作和资源权限。您可以利用 IAM 角色或策略来定义它们。执行导入/导出的用户应注意他们需要活动的访问密钥 ID 和秘密密钥。
数据管道的 IAM 角色
您需要两个 IAM 角色才能使用 Data Pipeline –
-
DataPipelineDefaultRole – 这包含您允许管道为您执行的所有操作。
-
DataPipelineDefaultResourceRole – 这包含您允许管道为您提供的资源。
如果您不熟悉 Data Pipeline,则必须生成每个角色。由于现有角色,所有以前的用户都拥有这些角色。
使用 IAM 控制台为 Data Pipeline 创建 IAM 角色,并执行以下四个步骤 –
步骤 1 – 登录位于https://console.aws.amazon.com/iam/的 IAM 控制台
步骤 2 –从仪表板中选择角色。
步骤 3 – 选择创建新角色。然后在Role Name字段中输入 DataPipelineDefaultRole ,并选择Next Step。在Role Type面板的AWS Service Roles列表中,导航到Data Pipeline,然后选择Select。在“审阅”面板中选择“创建角色”。
步骤 4 – 选择创建新角色。
DynamoDB – 数据备份
利用 Data Pipeline 的导入/导出功能来执行备份。执行备份的方式取决于您是使用 GUI 控制台还是直接使用数据管道 (API)。使用控制台时为每个表创建单独的管道,或者如果使用直接选项在单个管道中导入/导出多个表。
导出和导入数据
您必须在执行导出之前创建 Amazon S3 存储桶。您可以从一张或多张表中导出。
执行以下四步过程以执行导出 –
步骤 1 – 登录 AWS 管理控制台并打开位于https://console.aws.amazon.com/datapipeline/的 Data Pipeline 控制台
第 2 步– 如果您在使用的 AWS 区域中没有管道,请选择立即开始。如果您有一个或多个,请选择Create new pipeline。
步骤 3 – 在创建页面上,输入管道的名称。为 Source 参数选择使用模板构建。从列表中选择将 DynamoDB 表导出到 S3。在源 DynamoDB 表名称字段中输入源表。
使用以下格式在输出 S3 文件夹文本框中输入目标 S3 存储桶:s3://nameOfBucket/region/nameOfFolder。在S3 location for logs文本框中输入日志文件的 S3 目标。
步骤 4 –输入所有设置后选择激活。
管道可能需要几分钟才能完成其创建过程。使用控制台监控其状态。通过查看导出的文件,确认使用 S3 控制台成功处理。
导入数据
只有满足以下条件才能成功导入:您创建了目标表,目标和源使用相同的名称,并且目标和源使用相同的键模式。
您可以使用填充的目标表,但是,导入替换与源项目共享键的数据项目,并将多余的项目添加到表中。目的地也可以使用不同的区域。
虽然您可以导出多个源,但每次操作只能导入一个。您可以通过遵循以下步骤来执行导入 –
步骤 1 – 登录 AWS 管理控制台,然后打开数据管道控制台。
步骤 2 – 如果您打算执行跨区域导入,则应选择目标区域。
步骤 3 – 选择创建新管道。
步骤 4 – 在名称字段中输入管道名称。为 Source 参数选择Build using a template,然后在模板列表中,选择Import DynamoDB backup data from S3。
在Input S3 Folder文本框中输入源文件的位置。在目标 DynamoDB 表名称字段中输入目标表名称。然后在日志的S3 位置文本框中输入日志文件的位置。
步骤 5 –输入所有设置后选择激活。
导入在管道创建后立即开始。管道可能需要几分钟才能完成创建过程。
错误
发生错误时,Data Pipeline 控制台将 ERROR 作为管道状态显示。单击出现错误的管道会将您带到其详细信息页面,该页面会显示流程的每个步骤以及发生故障的点。其中的日志文件也提供了一些见解。
您可以查看错误的常见原因如下 –
-
导入的目标表不存在,或者不使用与源相同的键模式。
-
S3 存储桶不存在,或者您没有读取/写入权限。
-
管道超时。
-
您没有必要的导出/导入权限。
-
您的 AWS 账户已达到其资源限制。
DynamoDB – 监控
Amazon 提供 CloudWatch,用于通过 CloudWatch 控制台、命令行或 CloudWatch API 聚合和分析性能。您还可以使用它来设置警报和执行任务。它对某些事件执行指定的操作。
Cloudwatch 控制台
通过访问管理控制台来使用 CloudWatch,然后通过https://console.aws.amazon.com/cloudwatch/打开 CloudWatch 控制台。
然后您可以执行以下步骤 –
-
从导航窗格中选择指标。
-
在 CloudWatch Metrics by Category窗格中的DynamoDB 指标下,选择Table Metrics。
-
使用上部窗格向下滚动并检查表指标的整个列表。在查看列表提供的指标选项。
在结果界面中,您可以通过选中资源名称和指标旁边的复选框来选择/取消选择每个指标。然后您将能够查看每个项目的图表。
API集成
您可以通过查询访问 CloudWatch。使用指标值执行 CloudWatch 操作。注意 DynamoDB 不会发送值为零的指标。它只是跳过那些指标保持该值的时间段的指标。
以下是一些最常用的指标 –
-
ConditionalCheckFailedRequests – 它跟踪条件写入(例如条件 PutItem 写入)的失败尝试次数。失败的写入在评估为 false 时将此指标增加 1。它还会引发 HTTP 400 错误。
-
ConsumedReadCapacityUnits – 它量化了特定时间段内使用的容量单位。您可以使用它来检查单个表和索引的使用情况。
-
ConsumedWriteCapacityUnits – 它量化了特定时间段内使用的容量单位。您可以使用它来检查单个表和索引的使用情况。
-
ReadThrottleEvents – 它在表/索引读取中量化超过预配置容量单位的请求。它在每个节流阀上递增,包括具有多个节流阀的批处理操作。
-
ReturnedBytes – 它量化了特定时间段内检索操作中返回的字节。
-
ReturnedItemCount – 它量化了特定时间段内查询和扫描操作中返回的项目。它只处理返回的项目,而不是那些被评估的项目,这些项目通常是完全不同的数字。
注意– 存在更多指标,其中大多数允许您计算平均值、总和、最大值、最小值和计数。
DynamoDB – CloudTrail
DynamoDB 包括 CloudTrail 集成。它从账户中的 DynamoDB 或为 DynamoDB 捕获低级 API 请求,并将日志文件发送到指定的 S3 存储桶。它针对来自控制台或 API 的调用。您可以使用此数据来确定发出的请求及其来源、用户、时间戳等。
启用后,它会跟踪日志文件中的操作,其中包括其他服务记录。它支持八个动作和两个流 –
八个动作如下 –
- 创建表
- 删除表
- 描述表
- 列表
- 更新表
- 描述预留容量
- 描述预留容量产品
- 购买预留容量产品
虽然,这两个流是 –
- 描述流
- 列表流
所有日志都包含有关发出请求的帐户的信息。您可以确定详细信息,例如是 root 用户还是 IAM 用户发出请求,或者是使用临时凭证还是联合身份。
无论您指定多长时间,日志文件都会保留在存储中,并带有存档和删除设置。默认创建加密日志。您可以为新日志设置警报。您还可以将跨区域和账户的多个日志组织到一个存储桶中。
解释日志文件
每个文件包含一个或多个条目。每个条目由多个 JSON 格式的事件组成。一个条目代表一个请求,并包含相关信息;不保证订单。
您可以查看以下示例日志文件 –
{"Records": [
{
"eventVersion": "5.05",
"userIdentity": {
"type": "AssumedRole",
"principalId": "AKTTIOSZODNN8SAMPLE:jane",
"arn": "arn:aws:sts::155522255533:assumed-role/users/jane",
"accountId": "155522255533",
"accessKeyId": "AKTTIOSZODNN8SAMPLE",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2016-05-11T19:01:01Z"
},
"sessionIssuer": {
"type": "Role",
"principalId": "AKTTI44ZZ6DHBSAMPLE",
"arn": "arn:aws:iam::499955777666:role/admin-role",
"accountId": "499955777666",
"userName": "jill"
}
}
},
"eventTime": "2016-05-11T14:33:20Z",
"eventSource": "dynamodb.amazonaws.com",
"eventName": "DeleteTable",
"awsRegion": "us-west-2",
"sourceIPAddress": "192.0.2.0",
"userAgent": "console.aws.amazon.com",
"requestParameters": {"tableName": "Tools"},
"responseElements": {"tableDescription": {
"tableName": "Tools",
"itemCount": 0,
"provisionedThroughput": {
"writeCapacityUnits": 25,
"numberOfDecreasesToday": 0,
"readCapacityUnits": 25
},
"tableStatus": "DELETING",
"tableSizeBytes": 0
}},
"requestID": "4D89G7D98GF7G8A7DF78FG89AS7GFSO5AEMVJF66Q9ASUAAJG",
"eventID": "a954451c-c2fc-4561-8aea-7a30ba1fdf52",
"eventType": "AwsApiCall",
"apiVersion": "2013-04-22",
"recipientAccountId": "155522255533"
}
]}
DynamoDB – MapReduce
Amazon 的 Elastic MapReduce (EMR) 可让您快速高效地处理大数据。EMR 在 EC2 实例上运行 Apache Hadoop,但简化了流程。您可以使用 Apache Hive通过HiveQL(一种类似于 SQL 的查询语言)查询映射减少作业流。Apache Hive 可作为优化查询和应用程序的一种方式。
您可以使用管理控制台的 EMR 选项卡、EMR CLI、API 或 SDK 来启动作业流。您还可以选择以交互方式运行 Hive 或使用脚本。
EMR 读/写操作会影响吞吐量消耗,但是,在大型请求中,它会在退避算法的保护下执行重试。此外,与其他操作和任务同时运行 EMR 可能会导致限制。
DynamoDB/EMR 集成不支持二进制和二进制集属性。
DynamoDB/EMR 集成先决条件
在使用 EMR 之前查看此必要项目清单 –
- 一个 AWS 账户
- 在 EMR 操作中使用的同一帐户下的填充表
- 具有 DynamoDB 连接的自定义 Hive 版本
- DynamoDB 连接支持
- S3 存储桶(可选)
- SSH 客户端(可选)
- EC2 密钥对(可选)
蜂巢设置
在使用 EMR 之前,创建一个密钥对以交互模式运行 Hive。密钥对允许连接到 EC2 实例和作业流的主节点。
您可以按照以下步骤执行此操作 –
-
登录管理控制台,然后打开位于https://console.aws.amazon.com/ec2/的 EC2 控制台
-
在控制台的右上角选择一个区域。确保该区域与 DynamoDB 区域匹配。
-
在导航窗格中,选择密钥对。
-
选择创建密钥对。
-
在Key Pair Name字段中,输入名称并选择Create。
-
下载使用以下格式生成的私钥文件:filename.pem。
注意– 如果没有密钥对,您将无法连接到 EC2 实例。
蜂巢集群
创建启用 Hive 的集群来运行 Hive。它为 Hive 到 DynamoDB 连接构建所需的应用程序和基础设施环境。
您可以使用以下步骤执行此任务 –
-
访问 EMR 控制台。
-
选择创建集群。
-
在创建屏幕中,使用集群的描述性名称设置集群配置,选择Yes进行终止保护并选中Enabled for logging、S3 destination for log folder S3 location和Enabled for debugging。
-
在“软件配置”屏幕中,确保字段包含用于 Hadoop 分发的Amazon、用于 AMI 版本的最新版本、用于要安装的应用程序的默认 Hive 版本-Hive 以及用于要安装的应用程序的默认 Pig 版本-Pig。
-
在硬件配置屏幕中,确保字段包含Launch into EC2-Classic for Network、No Preference for EC2 Availability Zone、Master-Amazon EC2 Instance Type 的默认值、不检查 Request Spot Instances、Core-Amazon EC2 Instance 的默认值类型,计数为2,不检查请求 Spot 实例,任务-Amazon EC2 实例类型的默认值,计数为0,不检查请求 Spot 实例。
请务必设置提供足够容量的限制以防止集群故障。
-
在 Security and Access 屏幕中,确保字段包含 EC2 密钥对中的密钥对、IAM 用户访问中没有其他 IAM 用户和 IAM角色中没有角色继续。
-
查看 Bootstrap Actions 屏幕,但不要修改它。
-
查看设置,完成后选择创建集群。
一个总结窗格出现在集群的开始。
激活 SSH 会话
您需要一个活动的 SSH 会话来连接到主节点并执行 CLI 操作。通过在 EMR 控制台中选择集群来定位主节点。它将主节点列为Master Public DNS Name。
如果您没有 PuTTY,请安装它。然后启动 PuTTYgen 并选择Load。选择您的 PEM 文件,然后打开它。PuTTYgen 会通知您成功导入。选择Save private key以 PuTTY 私钥格式 (PPK)保存,并选择Yes进行保存,无需密码。然后输入 PuTTY 键的名称,点击Save并关闭 PuTTYgen。
首先启动 PuTTY,使用 PuTTY 与主节点建立连接。从类别列表中选择会话。在主机名字段中输入 hadoop@DNS。在 Category 列表中展开Connection > SSH,然后选择Auth。在控制选项屏幕中,选择浏览用于身份验证的私钥文件。然后选择您的私钥文件并打开它。为安全警报弹出窗口选择是。
连接到主节点后,会出现 Hadoop 命令提示符,这意味着您可以开始交互式 Hive 会话。
蜂巢表
Hive 用作数据仓库工具,允许使用HiveQL对 EMR 集群进行查询。先前的设置为您提供了一个工作提示。只需输入“hive”,然后输入您想要的任何命令,即可交互地运行 Hive 命令。请参阅我们的蜂巢教程的详细信息蜂巢。
DynamoDB – 表活动
DynamoDB 流使您能够跟踪和响应表项更改。使用此功能创建一个应用程序,该应用程序通过更新跨源的信息来响应更改。为大型多用户系统的数千个用户同步数据。使用它向用户发送更新通知。它的应用被证明是多样的和实质性的。DynamoDB 流是用于实现此功能的主要工具。
流捕获按时间排序的序列,其中包含表中的项目修改。他们最多保留这些数据 24 小时。应用程序使用它们几乎实时地查看原始项目和修改项目。
表上启用的流捕获所有修改。在任何 CRUD 操作中,DynamoDB 都会使用已修改项的主键属性创建一个流记录。您可以为附加信息配置流,例如图像前后。
Streams 有两个保证 –
-
每条记录在流中出现一次,并且
-
每一项修改都会产生与修改顺序相同的流记录。
所有流都实时处理,以允许您将它们用于应用程序中的相关功能。
管理流
在创建表时,您可以启用流。现有表允许禁用流或更改设置。Streams 提供了异步操作的特性,这意味着对表性能没有影响。
利用 AWS 管理控制台进行简单的流管理。首先,导航到控制台,然后选择Tables。在概览选项卡中,选择管理流。在窗口内,选择添加到表数据修改流中的信息。输入所有设置后,选择启用。
如果要禁用任何现有流,请选择Manage Stream,然后选择Disable。
您还可以利用 API CreateTable 和 UpdateTable 来启用或更改流。使用参数 StreamSpecification 来配置流。StreamEnabled 指定状态,表示启用为真,禁用为假。
StreamViewType 指定添加到流的信息:KEYS_ONLY、NEW_IMAGE、OLD_IMAGE 和 NEW_AND_OLD_IMAGES。
流阅读
通过连接到端点并发出 API 请求来读取和处理流。每个流都由流记录组成,并且每个记录都作为拥有该流的单个修改而存在。流记录包括显示发布顺序的序列号。记录属于也称为分片的组。分片充当多个记录的容器,还保存访问和遍历记录所需的信息。24 小时后,记录自动删除。
这些 Shard 会根据需要生成和删除,并且不会持续很长时间。它们还会自动划分为多个新分片,通常是为了响应写入活动高峰。在流禁用时,打开的分片关闭。分片之间的层次关系意味着应用程序必须优先考虑父分片以获得正确的处理顺序。您可以使用 Kinesis Adapter 自动执行此操作。
注意– 导致没有更改的操作不写入流记录。
访问和处理记录需要执行以下任务 –
- 确定目标流的 ARN。
- 确定保存目标记录的流的分片。
- 访问分片以检索所需的记录。
注意– 一次最多应该有 2 个进程读取一个分片。如果超过 2 个进程,则它可以限制源。
可用的流 API 操作包括
- 列表流
- 描述流
- 获取碎片迭代器
- 获取记录
您可以查看以下流阅读示例 –
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreamsClient;
import com.amazonaws.services.dynamodbv2.model.AttributeAction;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.AttributeValue;
import com.amazonaws.services.dynamodbv2.model.AttributeValueUpdate;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.DescribeStreamRequest;
import com.amazonaws.services.dynamodbv2.model.DescribeStreamResult;
import com.amazonaws.services.dynamodbv2.model.DescribeTableResult;
import com.amazonaws.services.dynamodbv2.model.GetRecordsRequest;
import com.amazonaws.services.dynamodbv2.model.GetRecordsResult;
import com.amazonaws.services.dynamodbv2.model.GetShardIteratorRequest;
import com.amazonaws.services.dynamodbv2.model.GetShardIteratorResult;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.Record;
import com.amazonaws.services.dynamodbv2.model.Shard;
import com.amazonaws.services.dynamodbv2.model.ShardIteratorType;
import com.amazonaws.services.dynamodbv2.model.StreamSpecification;
import com.amazonaws.services.dynamodbv2.model.StreamViewType;
import com.amazonaws.services.dynamodbv2.util.Tables;
public class StreamsExample {
private static AmazonDynamoDBClient dynamoDBClient =
new AmazonDynamoDBClient(new ProfileCredentialsProvider());
private static AmazonDynamoDBStreamsClient streamsClient =
new AmazonDynamoDBStreamsClient(new ProfileCredentialsProvider());
public static void main(String args[]) {
dynamoDBClient.setEndpoint("InsertDbEndpointHere");
streamsClient.setEndpoint("InsertStreamEndpointHere");
// table creation
String tableName = "MyTestingTable";
ArrayList<AttributeDefinition> attributeDefinitions =
new ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("ID")
.withAttributeType("N"));
ArrayList<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new KeySchemaElement()
.withAttributeName("ID")
.withKeyType(KeyType.HASH)); //Partition key
StreamSpecification streamSpecification = new StreamSpecification();
streamSpecification.setStreamEnabled(true);
streamSpecification.setStreamViewType(StreamViewType.NEW_AND_OLD_IMAGES);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withKeySchema(keySchema)
.withAttributeDefinitions(attributeDefinitions)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L))
.withStreamSpecification(streamSpecification);
System.out.println("Executing CreateTable for " + tableName);
dynamoDBClient.createTable(createTableRequest);
System.out.println("Creating " + tableName);
try {
Tables.awaitTableToBecomeActive(dynamoDBClient, tableName);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Get the table's stream settings
DescribeTableResult describeTableResult =
dynamoDBClient.describeTable(tableName);
String myStreamArn = describeTableResult.getTable().getLatestStreamArn();
StreamSpecification myStreamSpec =
describeTableResult.getTable().getStreamSpecification();
System.out.println("Current stream ARN for " + tableName + ": "+ myStreamArn);
System.out.println("Stream enabled: "+ myStreamSpec.getStreamEnabled());
System.out.println("Update view type: "+ myStreamSpec.getStreamViewType());
// Add an item
int numChanges = 0;
System.out.println("Making some changes to table data");
Map<String, AttributeValue> item = new HashMap<String, AttributeValue>();
item.put("ID", new AttributeValue().withN("222"));
item.put("Alert", new AttributeValue().withS("item!"));
dynamoDBClient.putItem(tableName, item);
numChanges++;
// Update the item
Map<String, AttributeValue> key = new HashMap<String, AttributeValue>();
key.put("ID", new AttributeValue().withN("222"));
Map<String, AttributeValueUpdate> attributeUpdates =
new HashMap<String, AttributeValueUpdate>();
attributeUpdates.put("Alert", new AttributeValueUpdate()
.withAction(AttributeAction.PUT)
.withValue(new AttributeValue().withS("modified item")));
dynamoDBClient.updateItem(tableName, key, attributeUpdates);
numChanges++;
// Delete the item
dynamoDBClient.deleteItem(tableName, key);
numChanges++;
// Get stream shards
DescribeStreamResult describeStreamResult =
streamsClient.describeStream(new DescribeStreamRequest()
.withStreamArn(myStreamArn));
String streamArn =
describeStreamResult.getStreamDescription().getStreamArn();
List<Shard> shards =
describeStreamResult.getStreamDescription().getShards();
// Process shards
for (Shard shard : shards) {
String shardId = shard.getShardId();
System.out.println("Processing " + shardId + " in "+ streamArn);
// Get shard iterator
GetShardIteratorRequest getShardIteratorRequest = new
GetShardIteratorRequest()
.withStreamArn(myStreamArn)
.withShardId(shardId)
.withShardIteratorType(ShardIteratorType.TRIM_HORIZON);
GetShardIteratorResult getShardIteratorResult =
streamsClient.getShardIterator(getShardIteratorRequest);
String nextItr = getShardIteratorResult.getShardIterator();
while (nextItr != null && numChanges > 0) {
// Read data records with iterator
GetRecordsResult getRecordsResult =
streamsClient.getRecords(new GetRecordsRequest().
withShardIterator(nextItr));
List<Record> records = getRecordsResult.getRecords();
System.out.println("Pulling records...");
for (Record record : records) {
System.out.println(record);
numChanges--;
}
nextItr = getRecordsResult.getNextShardIterator();
}
}
}
}
DynamoDB – 错误处理
如果请求处理失败,DynamoDB 会引发错误。每个错误由以下部分组成:HTTP 状态代码、异常名称和消息。错误管理依赖于传播错误的 SDK 或您自己的代码。
代码和消息
异常属于不同的 HTTP 标头状态代码。4xx 和 5xx 包含与请求问题和 AWS 相关的错误。
HTTP 4xx 类别中的一些例外情况如下 –
-
AccessDeniedException – 客户端未能正确签署请求。
-
ConditionalCheckFailedException – 评估为假的条件。
-
IncompleteSignatureException – 请求包含不完整的签名。
HTTP 5xx 类别中的例外情况如下 –
- 内部服务器错误
- 暂停服务
重试和退避算法
错误来自各种来源,例如服务器、交换机、负载平衡器以及其他结构和系统。常见的解决方案包括简单的重试,这支持可靠性。所有 SDK 都自动包含此逻辑,您可以设置重试参数以满足您的应用程序需求。
例如– Java 提供了一个 maxErrorRetry 值来停止重试。
除了重试之外,亚马逊还建议使用退避解决方案来控制流量。这包括逐渐增加重试之间的等待时间,并在相当短的时间后最终停止。注意 SDK 执行自动重试,但不执行指数退避。
以下程序是重试退避的示例 –
public enum Results {
SUCCESS,
NOT_READY,
THROTTLED,
SERVER_ERROR
}
public static void DoAndWaitExample() {
try {
// asynchronous operation.
long token = asyncOperation();
int retries = 0;
boolean retry = false;
do {
long waitTime = Math.min(getWaitTime(retries), MAX_WAIT_INTERVAL);
System.out.print(waitTime + "\n");
// Pause for result
Thread.sleep(waitTime);
// Get result
Results result = getAsyncOperationResult(token);
if (Results.SUCCESS == result) {
retry = false;
} else if (Results.NOT_READY == result) {
retry = true;
} else if (Results.THROTTLED == result) {
retry = true;
} else if (Results.SERVER_ERROR == result) {
retry = true;
} else {
// stop on other error
retry = false;
}
} while (retry && (retries++ < MAX_RETRIES));
}
catch (Exception ex) {
}
}
public static long getWaitTime(int retryCount) {
long waitTime = ((long) Math.pow(3, retryCount) * 100L);
return waitTime;
}
DynamoDB – 最佳实践
某些做法在使用各种源和元素时优化代码、防止错误并最小化吞吐量成本。
以下是 DynamoDB 中一些最重要和最常用的最佳实践。
表
表的分布意味着最好的方法在所有表项中均匀分布读/写活动。
旨在对表项进行统一的数据访问。最佳吞吐量使用取决于主键选择和项目工作负载模式。在分区键值之间均匀分布工作负载。避免诸如少量频繁使用的分区键值之类的事情。选择更好的选择,例如大量不同的分区键值。
了解分区行为。估计 DynamoDB 自动分配的分区。
DynamoDB 提供突发吞吐量使用,为“突发”功率保留未使用的吞吐量。避免大量使用此选项,因为突发会快速消耗大量吞吐量;此外,它并不能证明是一种可靠的资源。
在上传时,分发数据以实现更好的性能。通过同时上传到所有分配的服务器来实现这一点。
缓存经常使用的项目以将读取活动卸载到缓存而不是数据库。
项目
限制、性能、大小和访问成本仍然是项目最大的问题。选择一对多表。删除属性并划分表以匹配访问模式。您可以通过这种简单的方法显着提高效率。
在存储它们之前压缩大值。使用标准压缩工具。对大型属性值(如 S3)使用备用存储。您可以将对象存储在 S3 中,并将标识符存储在项目中。
通过虚拟物品碎片在多个物品之间分配大属性。这为项目大小的限制提供了一种解决方法。
查询和扫描
查询和扫描主要受到吞吐量消耗挑战的影响。避免突发,这通常是由于切换到强一致性读取等原因造成的。以低资源方式使用并行扫描(即没有限制的后台功能)。此外,仅将它们用于大型表,并且在没有充分利用吞吐量或扫描操作的情况下性能较差。
本地二级指数
索引在吞吐量和存储成本以及查询效率方面存在问题。除非经常查询属性,否则应避免索引。在预测中,明智地选择,因为它们会使索引膨胀。只选择那些经常使用的。
使用稀疏索引,即排序键不会出现在所有表项中的索引。它们有益于对大多数表项中不存在的属性进行查询。
注意项目集合(所有表格项目及其索引)的扩展。添加/更新操作会导致表和索引同时增长,10GB 仍然是集合的限制。
全球二级指数
索引在吞吐量和存储成本以及查询效率方面存在问题。选择关键属性传播,如表中的读/写传播提供工作负载一致性。选择均匀分布数据的属性。此外,利用稀疏索引。
利用全局二级索引在请求适度数据的查询中进行快速搜索。
