DynamoDB – 查询表
DynamoDB – 查询表
查询一个表主要需要选择一个表,指定一个分区键,然后执行查询;具有使用二级索引和通过扫描操作执行更深层次过滤的选项。
利用 GUI 控制台、Java 或其他选项来执行任务。
使用 GUI 控制台查询表
使用之前创建的表执行一些简单的查询。首先,在https://console.aws.amazon.com/dynamodb打开控制台
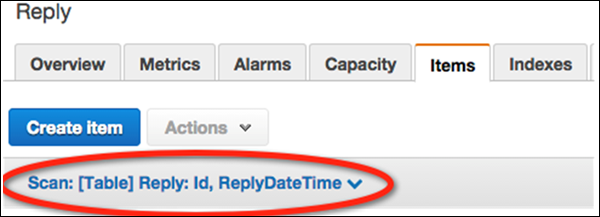
从导航窗格中选择表,然后从表列表中选择回复。然后选择Items选项卡以查看加载的数据。
选择“创建项目”按钮下方的数据过滤链接(“扫描:[表格] 回复”)。
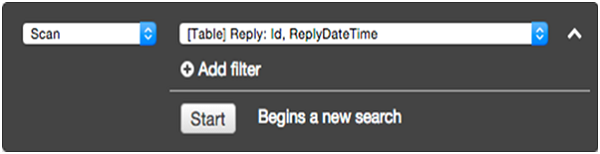
在过滤屏幕中,为操作选择查询。输入适当的分区键值,然后单击Start。
然后回复表返回匹配的项目。
使用 Java 查询表
使用Java 中的查询方法进行数据检索操作。它需要指定分区键值,排序键是可选的。
通过首先创建一个描述参数的querySpec 对象来编码 Java 查询。然后将对象传递给查询方法。我们使用前面示例中的分区键。
您可以查看以下示例 –
import java.util.HashMap;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
public class ProductsQuery {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
HashMap<String, String> nameMap = new HashMap<String, String>();
nameMap.put("#ID", "ID");
HashMap<String, Object> valueMap = new HashMap<String, Object>();
valueMap.put(":xxx", 122);
QuerySpec querySpec = new QuerySpec()
.withKeyConditionExpression("#ID = :xxx")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(valueMap);
ItemCollection<QueryOutcome> items = null;
Iterator<Item> iterator = null;
Item item = null;
try {
System.out.println("Product with the ID 122");
items = table.query(querySpec);
iterator = items.iterator();
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.getNumber("ID") + ": "
+ item.getString("Nomenclature"));
}
} catch (Exception e) {
System.err.println("Cannot find products with the ID number 122");
System.err.println(e.getMessage());
}
}
}
请注意,查询使用分区键,但是,二级索引为查询提供了另一种选择。它们的灵活性允许查询非关键属性,本教程稍后将讨论该主题。
scan 方法还通过收集所有表数据来支持检索操作。所述可选.withFilterExpression的指定的标准以外防止项目出现在结果。
在本教程的后面,我们将详细讨论扫描。现在,看看下面的例子 –
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.ScanOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.ScanSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class ProductsScan {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
ScanSpec scanSpec = new ScanSpec()
.withProjectionExpression("#ID, Nomenclature , stat.sales")
.withFilterExpression("#ID between :start_id and :end_id")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(new ValueMap().withNumber(":start_id", 120)
.withNumber(":end_id", 129));
try {
ItemCollection<ScanOutcome> items = table.scan(scanSpec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
Item item = iter.next();
System.out.println(item.toString());
}
} catch (Exception e) {
System.err.println("Cannot perform a table scan:");
System.err.println(e.getMessage());
}
}
}
