大数据分析 – 快速指南
大数据分析 – 快速指南
大数据分析 – 概述
在过去十年中,人们必须处理的数据量激增至难以想象的水平,与此同时,数据存储的价格也系统性地降低了。私营公司和研究机构从移动电话和汽车等设备中捕获有关其用户交互、业务、社交媒体以及传感器的 TB 级数据。这个时代的挑战是理解这片数据的海洋。这就是大数据分析的用武之地。
大数据分析主要涉及从不同来源收集数据,以一种可供分析师使用的方式对其进行处理,并最终提供对组织业务有用的数据产品。

将从不同来源检索的大量非结构化原始数据转换为对组织有用的数据产品的过程构成了大数据分析的核心。
大数据分析 – 数据生命周期
传统数据挖掘生命周期
为了提供一个框架来组织组织所需的工作并从大数据中提供清晰的见解,将其视为具有不同阶段的循环很有用。它绝不是线性的,这意味着所有阶段都相互关联。这个循环与CRISP 方法中描述的更传统的数据挖掘循环有表面上的相似之处。
CRISP-DM 方法论
在CRISP-DM方法是代表了数据挖掘跨行业标准流程,是数据挖掘专家使用它们来处理传统的BI数据挖掘的问题,介绍了常用的手法周期。它仍在传统的 BI 数据挖掘团队中使用。
请看下图。它显示了 CRISP-DM 方法所描述的周期的主要阶段以及它们是如何相互关联的。
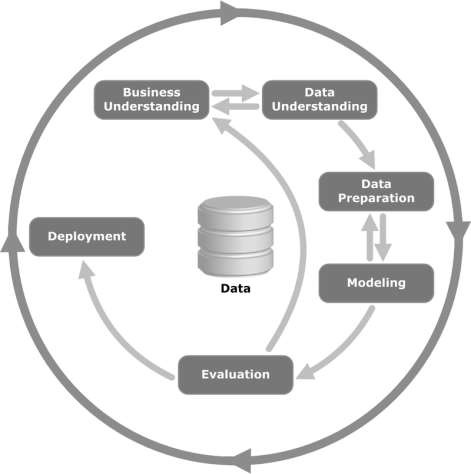
CRISP-DM 于 1996 年构想,次年作为 ESPRIT 资助计划下的欧盟项目开始实施。该项目由五家公司牵头:SPSS、Teradata、戴姆勒股份公司、NCR Corporation 和 OHRA(一家保险公司)。该项目最终被并入SPSS。该方法论针对如何指定数据挖掘项目非常详细。
现在让我们更多地了解 CRISP-DM 生命周期中涉及的每个阶段 –
-
业务理解– 此初始阶段侧重于从业务角度理解项目目标和要求,然后将这些知识转换为数据挖掘问题定义。初步计划旨在实现目标。可以使用决策模型,尤其是使用决策模型和符号标准构建的模型。
-
数据理解– 数据理解阶段从初始数据收集开始,然后进行活动以熟悉数据,识别数据质量问题,发现对数据的初步见解,或检测有趣的子集以形成隐藏的假设信息。
-
数据准备– 数据准备阶段涵盖从初始原始数据构建最终数据集(将被馈送到建模工具的数据)的所有活动。数据准备任务可能会执行多次,并且没有任何规定的顺序。任务包括表、记录和属性选择以及建模工具的数据转换和清理。
-
建模– 在此阶段,选择并应用各种建模技术,并将其参数校准为最佳值。通常,对于相同的数据挖掘问题类型有多种技术。一些技术对数据的形式有特定的要求。因此,往往需要退回到数据准备阶段。
-
评估– 在项目的这个阶段,从数据分析的角度来看,您已经构建了一个看起来高质量的模型(或多个模型)。在进行模型的最终部署之前,重要的是彻底评估模型并审查构建模型所执行的步骤,以确保其正确实现业务目标。
一个关键目标是确定是否存在一些尚未充分考虑的重要业务问题。在此阶段结束时,应就数据挖掘结果的使用做出决定。
-
部署– 模型的创建通常不是项目的结束。即使模型的目的是增加对数据的了解,所获得的知识也需要以对客户有用的方式进行组织和呈现。
根据要求,部署阶段可以像生成报告一样简单,也可以像实施可重复的数据评分(例如段分配)或数据挖掘过程一样复杂。
在许多情况下,执行部署步骤的是客户,而不是数据分析师。即使分析师部署了模型,客户也必须预先了解需要执行的操作,以便实际使用创建的模型。
SEMMA方法论
SEMMA 是 SAS 开发的另一种数据挖掘建模方法。它代表着小号充足,ē Xplore数据库,中号odify,中号奥德尔,和一个小规模企业。以下是其阶段的简要说明 –
-
Sample – 该过程从数据采样开始,例如,选择用于建模的数据集。数据集应该足够大以包含足够的信息来检索,但又要足够小以有效使用。此阶段还处理数据分区。
-
探索– 此阶段通过在数据可视化的帮助下发现变量之间的预期和意外关系以及异常来涵盖对数据的理解。
-
修改– 修改阶段包含选择、创建和转换变量以准备数据建模的方法。
-
模型– 在模型阶段,重点是对准备好的变量应用各种建模(数据挖掘)技术,以创建可能提供所需结果的模型。
-
评估– 建模结果的评估显示了所创建模型的可靠性和实用性。
CRISM-DM 和 SEMMA 之间的主要区别在于 SEMMA 侧重于建模方面,而 CRISP-DM 更重视建模之前的周期阶段,例如理解要解决的业务问题、理解和预处理要解决的数据。用作输入,例如机器学习算法。
大数据生命周期
在当今的大数据环境中,以前的方法要么不完整,要么不理想。例如,SEMMA 方法完全忽略了不同数据源的数据收集和预处理。这些阶段通常构成成功的大数据项目的大部分工作。
大数据分析周期可以通过以下阶段来描述 –
- 业务问题定义
- 研究
- 人力资源评估
- 数据采集
- 数据处理
- 数据存储
- 探索性数据分析
- 建模和评估的数据准备
- 造型
- 执行
在本节中,我们将介绍大数据生命周期的每个阶段。
业务问题定义
这是传统 BI 和大数据分析生命周期中的常见问题。通常,定义问题并正确评估它可能为组织带来多少潜在收益是大数据项目的一个重要阶段。提到这一点似乎很明显,但必须评估项目的预期收益和成本。
研究
分析其他公司在相同情况下的做法。这涉及寻找对贵公司合理的解决方案,即使它涉及调整其他解决方案以适应贵公司拥有的资源和要求。在这个阶段,应该定义未来阶段的方法论。
人力资源评估
一旦定义了问题,就可以继续分析当前员工是否能够成功完成项目。传统的 BI 团队可能无法提供所有阶段的最佳解决方案,因此如果需要将项目的一部分外包或雇用更多人员,则应在开始项目之前考虑。
数据采集
这部分是大数据生命周期的关键;它定义了交付结果数据产品所需的配置文件类型。数据收集是该过程的重要步骤;它通常涉及从不同来源收集非结构化数据。举个例子,它可能涉及编写一个爬虫来从网站检索评论。这涉及处理文本,可能是不同语言的文本,通常需要大量时间才能完成。
数据处理
一旦数据被检索到,例如,从网络,它需要以易于使用的格式存储。为了继续评论示例,让我们假设数据是从不同站点检索的,每个站点都有不同的数据显示。
假设一个数据源根据星级评分给出评论,因此可以将其理解为响应变量y ∈ {1, 2, 3, 4, 5}的映射。另一个数据源使用两个箭头系统给出评论,一个用于向上投票,另一个用于向下投票。这意味着形式为y ∈ {positive, negative}的响应变量。
为了组合这两个数据源,必须做出决定以使这两个响应表示等效。这可能涉及将第一个数据源响应表示转换为第二个形式,将一颗星视为负数,将五颗星视为正数。这个过程通常需要大量的时间分配才能高质量地交付。
数据存储
处理完数据后,有时需要将其存储在数据库中。关于这一点,大数据技术提供了大量替代方案。最常见的替代方法是使用 Hadoop 文件系统进行存储,它为用户提供有限版本的 SQL,称为 HIVE 查询语言。从用户的角度来看,这允许大多数分析任务以与在传统 BI 数据仓库中完成的方式类似的方式完成。其他需要考虑的存储选项是 MongoDB、Redis 和 SPARK。
周期的这个阶段与人力资源知识在实施不同架构的能力方面有关。传统数据仓库的修改版本仍在大规模应用中使用。例如,teradata 和 IBM 提供可以处理 TB 级数据的 SQL 数据库;开源解决方案如 postgreSQL 和 MySQL 仍在用于大规模应用程序。
尽管不同存储在后台的工作方式存在差异,但从客户端来看,大多数解决方案都提供 SQL API。因此,对 SQL 有一个很好的理解仍然是大数据分析的关键技能。
这个先验阶段似乎是最重要的话题,实际上,事实并非如此。它甚至不是一个必不可少的阶段。可以实现一个处理实时数据的大数据解决方案,所以在这种情况下,我们只需要收集数据来开发模型,然后实时实现它。因此根本不需要正式存储数据。
探索性数据分析
一旦数据以一种可以从中检索洞察力的方式被清理和存储,数据探索阶段是强制性的。这个阶段的目标是理解数据,这通常是通过统计技术和绘制数据来完成的。这是评估问题定义是否有意义或可行的好阶段。
建模和评估的数据准备
此阶段涉及对先前检索到的清理数据进行整形,并使用统计预处理进行缺失值插补、异常值检测、归一化、特征提取和特征选择。
造型
前一阶段应该已经生成了几个用于训练和测试的数据集,例如一个预测模型。这个阶段涉及尝试不同的模型并期待解决手头的业务问题。在实践中,通常希望模型能够提供对业务的一些洞察。最后,选择最佳模型或模型组合来评估其在遗漏数据集上的性能。
执行
在这个阶段,开发的数据产品在公司的数据管道中实施。这涉及在数据产品工作时设置验证方案,以跟踪其性能。例如,在实施预测模型的情况下,此阶段将涉及将模型应用于新数据,一旦响应可用,则评估模型。
大数据分析 – 方法论
在方法论方面,大数据分析与实验设计的传统统计方法有很大不同。分析从数据开始。通常,我们以一种解释响应的方式对数据建模。这种方法的目标是预测响应行为或了解输入变量与响应的关系。通常在统计实验设计中,开发实验并检索数据作为结果。这允许以统计模型可以使用的方式生成数据,其中某些假设成立,例如独立性、正态性和随机性。
在大数据分析中,我们会看到数据。我们无法设计一个满足我们最喜欢的统计模型的实验。在大规模的分析应用中,仅仅为了清理数据就需要大量的工作(通常是 80% 的工作量),因此它可以被机器学习模型使用。
在真正的大规模应用程序中,我们没有可遵循的独特方法。通常,一旦定义了业务问题,就需要一个研究阶段来设计要使用的方法论。然而,一般准则是相关的,并且适用于几乎所有问题。
大数据分析中最重要的任务之一是统计建模,这意味着有监督和无监督的分类或回归问题。一旦数据经过清理和预处理,可用于建模,就应谨慎评估具有合理损失指标的不同模型,然后一旦实施模型,应报告进一步的评估和结果。预测建模中的一个常见陷阱是只实施模型而从不测量其性能。
大数据分析 – 核心可交付成果
正如大数据生命周期中提到的,开发大数据产品所产生的数据产品在大多数情况下是以下一些 –
-
机器学习实现– 这可以是分类算法、回归模型或分割模型。
-
推荐系统– 目标是开发一个基于用户行为推荐选择的系统。Netflix是这个数据产品的典型例子,根据用户的评分推荐其他电影。
-
仪表板– 业务通常需要工具来可视化聚合数据。仪表板是一种图形机制,使这些数据可访问。
-
Ad-Hoc analysis – 通常业务领域有问题、假设或神话,可以通过数据进行临时分析来回答。
大数据分析 – 主要利益相关者
在大型组织中,为了成功开发一个大数据项目,需要有管理层支持该项目。这通常涉及找到一种方法来展示项目的业务优势。对于为项目寻找赞助商的问题,我们没有独特的解决方案,但下面给出了一些指导方针 –
-
检查与您感兴趣的项目类似的其他项目的赞助商是谁和在哪里。
-
在关键管理职位上拥有个人联系人会有所帮助,因此如果项目有希望,任何联系人都可以触发。
-
谁会从你的项目中受益?一旦项目走上正轨,谁会是你的客户?
-
制定一个简单、清晰和现有的提案,并与您组织中的主要参与者分享。
为项目寻找赞助商的最佳方法是了解问题以及实施后会产生什么数据产品。这种理解将有助于说服管理层相信大数据项目的重要性。
大数据分析 – 数据分析师
数据分析师具有面向报告的配置文件,具有使用 SQL 从传统数据仓库中提取和分析数据的经验。他们的任务通常是在数据存储方面或报告一般业务结果。数据仓库绝不是简单的,它只是与数据科学家所做的不同。
许多组织很难在市场上找到称职的数据科学家。然而,选择潜在的数据分析师并教他们成为数据科学家的相关技能是一个好主意。这绝不是一项微不足道的任务,通常涉及在定量领域攻读硕士学位的人,但这绝对是一个可行的选择。下面列出了称职的数据分析师必须具备的基本技能 –
- 业务理解
- SQL编程
- 报表设计与实现
- 仪表盘开发
大数据分析 – 数据科学家
数据科学家的角色通常与预测建模、开发分割算法、推荐系统、A/B 测试框架以及经常处理原始非结构化数据等任务相关。
他们的工作性质要求对数学、应用统计学和编程有深刻的理解。数据分析师和数据科学家之间有一些共同的技能,例如查询数据库的能力。两者都分析数据,但数据科学家的决策可以对组织产生更大的影响。
这是数据科学家通常需要具备的一组技能 –
- 在统计包中编程,例如:R、Python、SAS、SPSS 或 Julia
- 能够清理、提取和探索来自不同来源的数据
- 统计模型的研究、设计和实施
- 深厚的统计、数学和计算机科学知识
在大数据分析中,人们通常会将数据科学家的角色与数据架构师的角色混淆。实际上,区别很简单。数据架构师定义了存储数据的工具和架构,而数据科学家使用这种架构。当然,如果临时项目需要,数据科学家应该能够设置新工具,但基础设施定义和设计不应该是他的任务的一部分。
大数据分析 – 问题定义
通过本教程,我们将开发一个项目。本教程的每个后续章节都在小项目部分中处理较大项目的一部分。这被认为是一个应用教程部分,将提供对现实世界问题的了解。在这种情况下,我们将从项目的问题定义开始。
项目介绍
该项目的目标是开发一种机器学习模型,以使用简历 (CV) 文本作为输入来预测人们的时薪。
使用上面定义的框架,定义问题很简单。我们可以定义X = {x1, X2, …, Xn}作为用户的简历,其中每个功能都可以以最简单的方式表示该词出现的次数。然后响应是真实值,我们试图以美元为单位预测个人的小时工资。
这两个考虑足以得出结论,所提出的问题可以用监督回归算法解决。
问题定义
问题定义可能是大数据分析管道中最复杂和最容易被忽视的阶段之一。为了定义数据产品将解决的问题,经验是必不可少的。大多数有抱负的数据科学家在这个阶段几乎没有经验。
大多数大数据问题可以按以下方式分类 –
- 监督分类
- 监督回归
- 无监督学习
- 学习排名
现在让我们更多地了解这四个概念。
监督分类
给定一个特征矩阵X = {x1, X2, …, Xn}我们开发了一个模型M预测定义为不同的类Y = {C1, C2, …, Cn} . 例如:给定保险公司客户的交易数据,可以开发一个模型来预测客户是否会流失。后者是一个二元分类问题,其中有两个类或目标变量:churn 和 not churn。
其他问题涉及预测多个类别,我们可能会对数字识别感兴趣,因此响应向量将定义为:y = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9},最先进的模型将是卷积神经网络,特征矩阵将被定义为图像的像素。
监督回归
在这种情况下,问题定义与前面的示例非常相似;差异取决于响应。在回归问题中,响应 y ∈ ℜ,这意味着响应是实值的。例如,我们可以开发一个模型,根据个人简历的语料库预测个人的时薪。
无监督学习
管理层通常渴望获得新的见解。细分模型可以提供这种洞察力,以便营销部门为不同的细分市场开发产品。开发分割模型的一个好方法是选择与所需分割相关的特征,而不是考虑算法。
例如,在一家电信公司,根据手机使用情况对客户进行细分很有趣。这将涉及忽略与分割目标无关的特征,而只包括那些有关系的特征。在这种情况下,这将选择功能,如一个月使用的 SMS 数量、入站和出站分钟数等。
学习排名
这个问题可以被认为是一个回归问题,但它有特殊的特点,值得单独处理。问题涉及给定一组文档,我们试图找到给定查询最相关的排序。为了开发监督学习算法,需要在给定查询的情况下标记排序的相关性。
需要注意的是,为了开发监督学习算法,需要对训练数据进行标记。这意味着为了训练一个模型,例如识别图像中的数字,我们需要手动标记大量示例。有一些 Web 服务可以加快此过程,并且通常用于此任务,例如 amazon Mechanical turk。事实证明,当提供更多数据时,学习算法会提高其性能,因此在监督学习中标记相当数量的示例实际上是强制性的。
大数据分析 – 数据收集
数据收集在大数据周期中扮演着最重要的角色。互联网为各种主题提供了几乎无限的数据源。该领域的重要性取决于业务类型,但传统行业可以获取多种外部数据来源,并将其与其交易数据相结合。
例如,假设我们想构建一个推荐餐厅的系统。第一步是收集数据,在这种情况下,是来自不同网站的餐厅评论,并将它们存储在数据库中。由于我们对原始文本感兴趣,并将其用于分析,因此用于开发模型的数据的存储位置并不重要。这听起来可能与大数据的主要技术矛盾,但是为了实现一个大数据应用,我们只需要让它实时工作。
推特迷你项目
一旦定义了问题,接下来的阶段就是收集数据。以下小项目的想法是致力于从网络收集数据并将其结构化以用于机器学习模型。我们将使用 R 编程语言从 twitter rest API 收集一些推文。
首先创建一个twitter账号,然后按照twitteR包vignette中的说明创建一个twitter开发者账号。这是这些说明的摘要 –
-
填写基本信息后,进入“设置”选项卡,选择“读取、写入和访问直接消息”。
-
确保在执行此操作后单击保存按钮
-
在“详细信息”选项卡中,记下您的消费者密钥和消费者秘密
-
在您的 R 会话中,您将使用 API 密钥和 API 秘密值
-
最后运行以下脚本。这将从其在 github 上的存储库安装twitteR包。
install.packages(c("devtools", "rjson", "bit64", "httr"))
# Make sure to restart your R session at this point
library(devtools)
install_github("geoffjentry/twitteR")
我们有兴趣获取包含字符串“big mac”的数据,并找出与此相关的突出主题。为此,第一步是从 Twitter 收集数据。下面是我们从 Twitter 收集所需数据的 R 脚本。此代码也可在 bda/part1/collect_data/collect_data_twitter.R 文件中找到。
rm(list = ls(all = TRUE)); gc() # Clears the global environment
library(twitteR)
Sys.setlocale(category = "LC_ALL", locale = "C")
### Replace the xxx’s with the values you got from the previous instructions
# consumer_key = "xxxxxxxxxxxxxxxxxxxx"
# consumer_secret = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# access_token = "xxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# access_token_secret= "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Connect to twitter rest API
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_token_secret)
# Get tweets related to big mac
tweets <- searchTwitter(’big mac’, n = 200, lang = ’en’)
df <- twListToDF(tweets)
# Take a look at the data
head(df)
# Check which device is most used
sources <- sapply(tweets, function(x) x$getStatusSource())
sources <- gsub("</a>", "", sources)
sources <- strsplit(sources, ">")
sources <- sapply(sources, function(x) ifelse(length(x) > 1, x[2], x[1]))
source_table = table(sources)
source_table = source_table[source_table > 1]
freq = source_table[order(source_table, decreasing = T)]
as.data.frame(freq)
# Frequency
# Twitter for iPhone 71
# Twitter for Android 29
# Twitter Web Client 25
# recognia 20
大数据分析 – 清理数据
一旦收集到数据,我们通常会拥有具有不同特征的不同数据源。最直接的步骤是使这些数据源同质化并继续开发我们的数据产品。但是,这取决于数据类型。我们应该问问自己,将数据同质化是否可行。
可能数据来源完全不同,如果来源同质化,信息损失会很大。在这种情况下,我们可以考虑替代方案。一个数据源可以帮助我构建回归模型,而另一个数据源可以帮助我构建分类模型吗?是否有可能利用我们的优势来处理异质性,而不仅仅是丢失信息?做出这些决定使分析变得有趣和具有挑战性。
在评论的情况下,可以为每个数据源使用一种语言。同样,我们有两个选择 –
-
同质化– 它涉及将不同的语言翻译成我们拥有更多数据的语言。翻译服务的质量是可以接受的,但如果我们想用 API 翻译大量数据,成本会很高。有可用于此任务的软件工具,但这也会很昂贵。
-
异质化– 是否可以为每种语言开发解决方案?由于检测语料库的语言很简单,我们可以为每种语言开发一个推荐器。这将涉及根据可用语言数量调整每个推荐器的更多工作,但如果我们有几种语言可用,这绝对是一个可行的选择。
推特迷你项目
在目前的情况下,我们需要首先清理非结构化数据,然后将其转换为数据矩阵,以便对其应用主题建模。一般来说,从 Twitter 获取数据时,有几个字符我们不感兴趣使用,至少在数据清理过程的第一阶段是这样。
例如,在收到推文后,我们会得到这些奇怪的字符:“<ed><U+00A0><U+00BD><ed><U+00B8><U+008B>”。这些可能是表情符号,因此为了清理数据,我们将使用以下脚本删除它们。此代码也可在 bda/part1/collect_data/cleaning_data.R 文件中找到。
rm(list = ls(all = TRUE)); gc() # Clears the global environment
source('collect_data_twitter.R')
# Some tweets
head(df$text)
[1] "I’m not a big fan of turkey but baked Mac &
cheese <ed><U+00A0><U+00BD><ed><U+00B8><U+008B>"
[2] "@Jayoh30 Like no special sauce on a big mac. HOW"
### We are interested in the text - Let’s clean it!
# We first convert the encoding of the text from latin1 to ASCII
df$text <- sapply(df$text,function(row) iconv(row, "latin1", "ASCII", sub = ""))
# Create a function to clean tweets
clean.text <- function(tx) {
tx <- gsub("htt.{1,20}", " ", tx, ignore.case = TRUE)
tx = gsub("[^#[:^punct:]]|@|RT", " ", tx, perl = TRUE, ignore.case = TRUE)
tx = gsub("[[:digit:]]", " ", tx, ignore.case = TRUE)
tx = gsub(" {1,}", " ", tx, ignore.case = TRUE)
tx = gsub("^\\s+|\\s+$", " ", tx, ignore.case = TRUE)
return(tx)
}
clean_tweets <- lapply(df$text, clean.text)
# Cleaned tweets
head(clean_tweets)
[1] " WeNeedFeminlsm MAC s new make up line features men woc and big girls "
[1] " TravelsPhoto What Happens To Your Body One Hour After A Big Mac "
数据清理迷你项目的最后一步是清理文本,我们可以将其转换为矩阵并对其应用算法。从存储在clean_tweets向量中的文本,我们可以轻松地将其转换为词袋矩阵并应用无监督学习算法。
大数据分析 – 总结数据
报告在大数据分析中非常重要。每个组织都必须定期提供信息以支持其决策过程。此任务通常由具有 SQL 和 ETL(提取、传输和加载)经验的数据分析师处理。
负责此任务的团队负责将大数据分析部门产生的信息传播到组织的不同领域。
以下示例演示了数据汇总的含义。导航到文件夹bda/part1/summarize_data并在该文件夹中双击打开summarise_data.Rproj文件。然后,打开summary_data.R脚本并查看代码,并按照提供的说明进行操作。
# Install the following packages by running the following code in R.
pkgs = c('data.table', 'ggplot2', 'nycflights13', 'reshape2')
install.packages(pkgs)
该GGPLOT2包是伟大的数据可视化。该data.table包是一个很好的选择,以做快速和高效存储技术综述[R 。最近的基准测试表明它甚至比用于类似任务的 python 库pandas还要快。
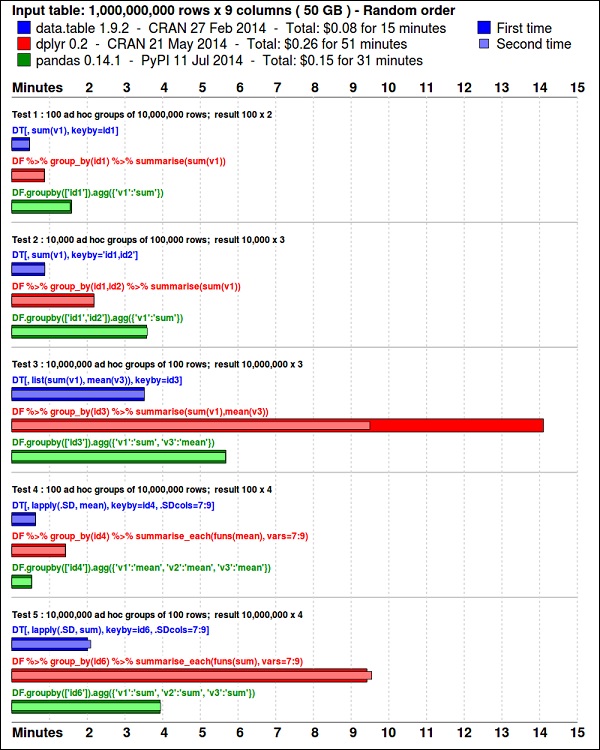
使用以下代码查看数据。此代码也可在bda/part1/summarize_data/summarize_data.Rproj文件中找到。
library(nycflights13) library(ggplot2) library(data.table) library(reshape2) # Convert the flights data.frame to a data.table object and call it DT DT <- as.data.table(flights) # The data has 336776 rows and 16 columns dim(DT) # Take a look at the first rows head(DT) # year month day dep_time dep_delay arr_time arr_delay carrier # 1: 2013 1 1 517 2 830 11 UA # 2: 2013 1 1 533 4 850 20 UA # 3: 2013 1 1 542 2 923 33 AA # 4: 2013 1 1 544 -1 1004 -18 B6 # 5: 2013 1 1 554 -6 812 -25 DL # 6: 2013 1 1 554 -4 740 12 UA # tailnum flight origin dest air_time distance hour minute # 1: N14228 1545 EWR IAH 227 1400 5 17 # 2: N24211 1714 LGA IAH 227 1416 5 33 # 3: N619AA 1141 JFK MIA 160 1089 5 42 # 4: N804JB 725 JFK BQN 183 1576 5 44 # 5: N668DN 461 LGA ATL 116 762 5 54 # 6: N39463 1696 EWR ORD 150 719 5 54
下面的代码有一个数据汇总的例子。
### Data Summarization # Compute the mean arrival delay DT[, list(mean_arrival_delay = mean(arr_delay, na.rm = TRUE))] # mean_arrival_delay # 1: 6.895377 # Now, we compute the same value but for each carrier mean1 = DT[, list(mean_arrival_delay = mean(arr_delay, na.rm = TRUE)), by = carrier] print(mean1) # carrier mean_arrival_delay # 1: UA 3.5580111 # 2: AA 0.3642909 # 3: B6 9.4579733 # 4: DL 1.6443409 # 5: EV 15.7964311 # 6: MQ 10.7747334 # 7: US 2.1295951 # 8: WN 9.6491199 # 9: VX 1.7644644 # 10: FL 20.1159055 # 11: AS -9.9308886 # 12: 9E 7.3796692 # 13: F9 21.9207048 # 14: HA -6.9152047 # 15: YV 15.5569853 # 16: OO 11.9310345 # Now let’s compute to means in the same line of code mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE), mean_arrival_delay = mean(arr_delay, na.rm = TRUE)), by = carrier] print(mean2) # carrier mean_departure_delay mean_arrival_delay # 1: UA 12.106073 3.5580111 # 2: AA 8.586016 0.3642909 # 3: B6 13.022522 9.4579733 # 4: DL 9.264505 1.6443409 # 5: EV 19.955390 15.7964311 # 6: MQ 10.552041 10.7747334 # 7: US 3.782418 2.1295951 # 8: WN 17.711744 9.6491199 # 9: VX 12.869421 1.7644644 # 10: FL 18.726075 20.1159055 # 11: AS 5.804775 -9.9308886 # 12: 9E 16.725769 7.3796692 # 13: F9 20.215543 21.9207048 # 14: HA 4.900585 -6.9152047 # 15: YV 18.996330 15.5569853 # 16: OO 12.586207 11.9310345 ### Create a new variable called gain # this is the difference between arrival delay and departure delay DT[, gain:= arr_delay - dep_delay] # Compute the median gain per carrier median_gain = DT[, median(gain, na.rm = TRUE), by = carrier] print(median_gain)
大数据分析 – 数据探索
探索性数据分析是由 John Tuckey (1977) 提出的一个概念,它包含一个新的统计视角。Tuckey 的想法是,在传统统计中,数据不是以图形方式探索的,只是用于检验假设。开发工具的第一次尝试是在斯坦福完成的,该项目被称为prim9。该工具能够在九个维度上可视化数据,因此它能够提供数据的多元视角。
最近几天,探索性数据分析是必须的,并已被纳入大数据分析生命周期。强大的 EDA 功能推动了发现洞察力并能够在组织中有效地传达洞察力的能力。
基于 Tuckey 的想法,贝尔实验室开发了S 编程语言,以便为进行统计提供交互界面。S 的想法是通过易于使用的语言提供广泛的图形功能。在当今世界,在大数据的背景下,基于S编程语言的R是最流行的分析软件。
以下程序演示了探索性数据分析的使用。
以下是探索性数据分析的示例。此代码也可在part1/eda/exploratory_data_analysis.R文件中找到。
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# Using the code from the previous section
# This computes the mean arrival and departure delays by carrier.
DT <- as.data.table(flights)
mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE),
mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
# In order to plot data in R usign ggplot, it is normally needed to reshape the data
# We want to have the data in long format for plotting with ggplot
dt = melt(mean2, id.vars = ’carrier’)
# Take a look at the first rows
print(head(dt))
# Take a look at the help for ?geom_point and geom_line to find similar examples
# Here we take the carrier code as the x axis
# the value from the dt data.table goes in the y axis
# The variable column represents the color
p = ggplot(dt, aes(x = carrier, y = value, color = variable, group = variable)) +
geom_point() + # Plots points
geom_line() + # Plots lines
theme_bw() + # Uses a white background
labs(list(title = 'Mean arrival and departure delay by carrier',
x = 'Carrier', y = 'Mean delay'))
print(p)
# Save the plot to disk
ggsave('mean_delay_by_carrier.png', p,
width = 10.4, height = 5.07)
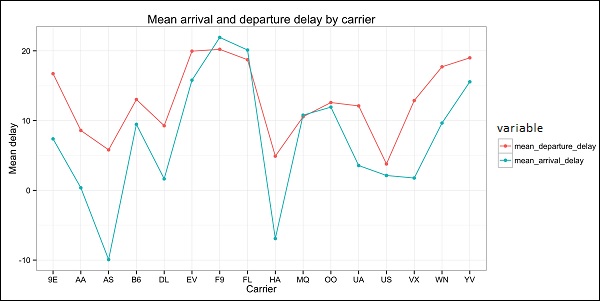
代码应生成如下图像 –
大数据分析 – 数据可视化
为了理解数据,将数据可视化通常很有用。通常在大数据应用程序中,兴趣依赖于发现洞察力,而不仅仅是制作漂亮的图表。以下是使用绘图理解数据的不同方法的示例。
要开始分析航班数据,我们可以先检查数值变量之间是否存在相关性。此代码也可在bda/part1/data_visualization/data_visualization.R文件中找到。
# Install the package corrplot by running
install.packages('corrplot')
# then load the library
library(corrplot)
# Load the following libraries
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# We will continue working with the flights data
DT <- as.data.table(flights)
head(DT) # take a look
# We select the numeric variables after inspecting the first rows.
numeric_variables = c('dep_time', 'dep_delay',
'arr_time', 'arr_delay', 'air_time', 'distance')
# Select numeric variables from the DT data.table
dt_num = DT[, numeric_variables, with = FALSE]
# Compute the correlation matrix of dt_num
cor_mat = cor(dt_num, use = "complete.obs")
print(cor_mat)
### Here is the correlation matrix
# dep_time dep_delay arr_time arr_delay air_time distance
# dep_time 1.00000000 0.25961272 0.66250900 0.23230573 -0.01461948 -0.01413373
# dep_delay 0.25961272 1.00000000 0.02942101 0.91480276 -0.02240508 -0.02168090
# arr_time 0.66250900 0.02942101 1.00000000 0.02448214 0.05429603 0.04718917
# arr_delay 0.23230573 0.91480276 0.02448214 1.00000000 -0.03529709 -0.06186776
# air_time -0.01461948 -0.02240508 0.05429603 -0.03529709 1.00000000 0.99064965
# distance -0.01413373 -0.02168090 0.04718917 -0.06186776 0.99064965 1.00000000
# We can display it visually to get a better understanding of the data
corrplot.mixed(cor_mat, lower = "circle", upper = "ellipse")
# save it to disk
png('corrplot.png')
print(corrplot.mixed(cor_mat, lower = "circle", upper = "ellipse"))
dev.off()
此代码生成以下相关矩阵可视化 –
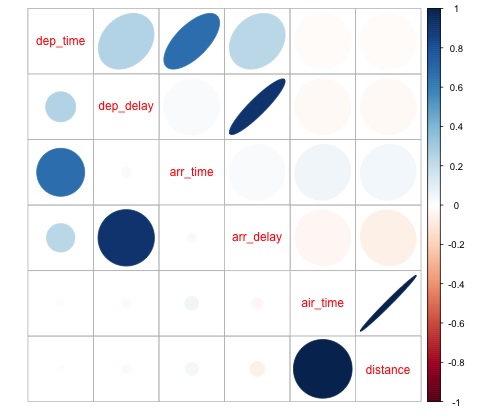
我们可以在图中看到数据集中的一些变量之间存在很强的相关性。例如,到达延误和出发延误似乎高度相关。我们可以看到这一点,因为椭圆显示两个变量之间几乎呈线性关系,但是,从这个结果中找出因果关系并不简单。
我们不能说由于两个变量是相关的,所以一个对另一个有影响。我们还在图中发现飞行时间和距离之间存在很强的相关性,这是相当合理的,因为距离越远,飞行时间就会增加。
我们还可以对数据进行单变量分析。一种简单而有效的可视化分布的方法是箱线图。以下代码演示了如何使用 ggplot2 库生成箱线图和格状图。此代码也可在bda/part1/data_visualization/boxplots.R文件中找到。
source('data_visualization.R')
### Analyzing Distributions using box-plots
# The following shows the distance as a function of the carrier
p = ggplot(DT, aes(x = carrier, y = distance, fill = carrier)) + # Define the carrier
in the x axis and distance in the y axis
geom_box-plot() + # Use the box-plot geom
theme_bw() + # Leave a white background - More in line with tufte's
principles than the default
guides(fill = FALSE) + # Remove legend
labs(list(title = 'Distance as a function of carrier', # Add labels
x = 'Carrier', y = 'Distance'))
p
# Save to disk
png(‘boxplot_carrier.png’)
print(p)
dev.off()
# Let's add now another variable, the month of each flight
# We will be using facet_wrap for this
p = ggplot(DT, aes(carrier, distance, fill = carrier)) +
geom_box-plot() +
theme_bw() +
guides(fill = FALSE) +
facet_wrap(~month) + # This creates the trellis plot with the by month variable
labs(list(title = 'Distance as a function of carrier by month',
x = 'Carrier', y = 'Distance'))
p
# The plot shows there aren't clear differences between distance in different months
# Save to disk
png('boxplot_carrier_by_month.png')
print(p)
dev.off()
大数据分析 – R 简介
本节专门向用户介绍 R 编程语言。R 可以从cran 网站下载。对于 Windows 用户,安装 rtools和rstudio IDE很有用。
R背后的一般概念是作为其他以 C、C++ 和 Fortran 等编译语言开发的软件的接口,并为用户提供一个交互式工具来分析数据。
导航到书籍 zip 文件bda/part2/R_introduction的文件夹并打开R_introduction.Rproj文件。这将打开一个 RStudio 会话。然后打开 01_vectors.R 文件。逐行运行脚本并按照代码中的注释进行操作。为了学习,另一个有用的选择是键入代码,这将帮助您习惯 R 语法。在 R 中,注释是用 # 符号写的。
书中为了展示运行R代码的结果,在代码求值后,对R返回的结果进行注释。这样,您可以复制粘贴书中的代码,然后直接在 R 中尝试其中的部分。
# Create a vector of numbers
numbers = c(1, 2, 3, 4, 5)
print(numbers)
# [1] 1 2 3 4 5
# Create a vector of letters
ltrs = c('a', 'b', 'c', 'd', 'e')
# [1] "a" "b" "c" "d" "e"
# Concatenate both
mixed_vec = c(numbers, ltrs)
print(mixed_vec)
# [1] "1" "2" "3" "4" "5" "a" "b" "c" "d" "e"
让我们分析一下前面代码中发生了什么。我们可以看到可以用数字和字母创建向量。我们不需要事先告诉 R 我们想要什么类型的数据类型。最后,我们能够创建一个包含数字和字母的向量。向量 mix_vec 将数字强制转换为字符,我们可以通过可视化值如何打印在引号内来看到这一点。
以下代码显示了函数类返回的不同向量的数据类型。通常使用类函数来“询问”一个对象,询问他的类是什么。
### Evaluate the data types using class ### One dimensional objects # Integer vector num = 1:10 class(num) # [1] "integer" # Numeric vector, it has a float, 10.5 num = c(1:10, 10.5) class(num) # [1] "numeric" # Character vector ltrs = letters[1:10] class(ltrs) # [1] "character" # Factor vector fac = as.factor(ltrs) class(fac) # [1] "factor"
R 也支持二维对象。在下面的代码中,有 R 中使用的两种最流行的数据结构的示例:矩阵和 data.frame。
# Matrix M = matrix(1:12, ncol = 4) # [,1] [,2] [,3] [,4] # [1,] 1 4 7 10 # [2,] 2 5 8 11 # [3,] 3 6 9 12 lM = matrix(letters[1:12], ncol = 4) # [,1] [,2] [,3] [,4] # [1,] "a" "d" "g" "j" # [2,] "b" "e" "h" "k" # [3,] "c" "f" "i" "l" # Coerces the numbers to character # cbind concatenates two matrices (or vectors) in one matrix cbind(M, lM) # [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] # [1,] "1" "4" "7" "10" "a" "d" "g" "j" # [2,] "2" "5" "8" "11" "b" "e" "h" "k" # [3,] "3" "6" "9" "12" "c" "f" "i" "l" class(M) # [1] "matrix" class(lM) # [1] "matrix" # data.frame # One of the main objects of R, handles different data types in the same object. # It is possible to have numeric, character and factor vectors in the same data.frame df = data.frame(n = 1:5, l = letters[1:5]) df # n l # 1 1 a # 2 2 b # 3 3 c # 4 4 d # 5 5 e
如前面的示例所示,可以在同一对象中使用不同的数据类型。一般来说,这就是数据在数据库中的呈现方式,API 部分数据是文本或字符向量和其他数字。分析师的工作是确定要分配的统计数据类型,然后为其使用正确的 R 数据类型。在统计学中,我们通常认为变量具有以下类型 –
- 数字
- 名义或分类
- 序数
在 R 中,向量可以是以下类别 –
- 数字 – 整数
- 因素
- 有序因子
R 为每种统计类型的变量提供了一种数据类型。然而,有序因子很少使用,但可以由函数因子创建,或有序。
以下部分讨论索引的概念。这是一个很常见的操作,处理选择对象的部分并对它们进行转换的问题。
# Let's create a data.frame
df = data.frame(numbers = 1:26, letters)
head(df)
# numbers letters
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 e
# 6 6 f
# str gives the structure of a data.frame, it’s a good summary to inspect an object
str(df)
# 'data.frame': 26 obs. of 2 variables:
# $ numbers: int 1 2 3 4 5 6 7 8 9 10 ...
# $ letters: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ...
# The latter shows the letters character vector was coerced as a factor.
# This can be explained by the stringsAsFactors = TRUE argumnet in data.frame
# read ?data.frame for more information
class(df)
# [1] "data.frame"
### Indexing
# Get the first row
df[1, ]
# numbers letters
# 1 1 a
# Used for programming normally - returns the output as a list
df[1, , drop = TRUE]
# $numbers
# [1] 1
#
# $letters
# [1] a
# Levels: a b c d e f g h i j k l m n o p q r s t u v w x y z
# Get several rows of the data.frame
df[5:7, ]
# numbers letters
# 5 5 e
# 6 6 f
# 7 7 g
### Add one column that mixes the numeric column with the factor column
df$mixed = paste(df$numbers, df$letters, sep = ’’)
str(df)
# 'data.frame': 26 obs. of 3 variables:
# $ numbers: int 1 2 3 4 5 6 7 8 9 10 ...
# $ letters: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ...
# $ mixed : chr "1a" "2b" "3c" "4d" ...
### Get columns
# Get the first column
df[, 1]
# It returns a one dimensional vector with that column
# Get two columns
df2 = df[, 1:2]
head(df2)
# numbers letters
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 e
# 6 6 f
# Get the first and third columns
df3 = df[, c(1, 3)]
df3[1:3, ]
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
### Index columns from their names
names(df)
# [1] "numbers" "letters" "mixed"
# This is the best practice in programming, as many times indeces change, but
variable names don’t
# We create a variable with the names we want to subset
keep_vars = c("numbers", "mixed")
df4 = df[, keep_vars]
head(df4)
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# 6 6 6f
### subset rows and columns
# Keep the first five rows
df5 = df[1:5, keep_vars]
df5
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# subset rows using a logical condition
df6 = df[df$numbers < 10, keep_vars]
df6
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# 6 6 6f
# 7 7 7g
# 8 8 8h
# 9 9 9i
大数据分析 – SQL 简介
SQL 代表结构化查询语言。它是传统数据仓库和大数据技术中用于从数据库中提取数据的最广泛使用的语言之一。为了演示 SQL 的基础知识,我们将使用示例。为了专注于语言本身,我们将在 R 中使用 SQL。就编写 SQL 代码而言,这与在数据库中所做的完全一样。
SQL 的核心是三个语句:SELECT、FROM 和 WHERE。以下示例使用了最常见的 SQL 用例。导航到文件夹bda/part2/SQL_introduction并打开SQL_introduction.Rproj文件。然后打开 01_select.R 脚本。为了在 R 中编写 SQL 代码,我们需要安装sqldf包,如下面的代码所示。
# Install the sqldf package
install.packages('sqldf')
# load the library
library('sqldf')
library(nycflights13)
# We will be working with the fligths dataset in order to introduce SQL
# Let’s take a look at the table
str(flights)
# Classes 'tbl_d', 'tbl' and 'data.frame': 336776 obs. of 16 variables:
# $ year : int 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 ...
# $ month : int 1 1 1 1 1 1 1 1 1 1 ...
# $ day : int 1 1 1 1 1 1 1 1 1 1 ...
# $ dep_time : int 517 533 542 544 554 554 555 557 557 558 ...
# $ dep_delay: num 2 4 2 -1 -6 -4 -5 -3 -3 -2 ...
# $ arr_time : int 830 850 923 1004 812 740 913 709 838 753 ...
# $ arr_delay: num 11 20 33 -18 -25 12 19 -14 -8 8 ...
# $ carrier : chr "UA" "UA" "AA" "B6" ...
# $ tailnum : chr "N14228" "N24211" "N619AA" "N804JB" ...
# $ flight : int 1545 1714 1141 725 461 1696 507 5708 79 301 ...
# $ origin : chr "EWR" "LGA" "JFK" "JFK" ...
# $ dest : chr "IAH" "IAH" "MIA" "BQN" ...
# $ air_time : num 227 227 160 183 116 150 158 53 140 138 ...
# $ distance : num 1400 1416 1089 1576 762 ...
# $ hour : num 5 5 5 5 5 5 5 5 5 5 ...
# $ minute : num 17 33 42 44 54 54 55 57 57 58 ...
select 语句用于从表中检索列并对其进行计算。ej1 中演示了最简单的 SELECT 语句。我们还可以创建新变量,如ej2所示。
### SELECT statement
ej1 = sqldf("
SELECT
dep_time
,dep_delay
,arr_time
,carrier
,tailnum
FROM
flights
")
head(ej1)
# dep_time dep_delay arr_time carrier tailnum
# 1 517 2 830 UA N14228
# 2 533 4 850 UA N24211
# 3 542 2 923 AA N619AA
# 4 544 -1 1004 B6 N804JB
# 5 554 -6 812 DL N668DN
# 6 554 -4 740 UA N39463
# In R we can use SQL with the sqldf function. It works exactly the same as in
a database
# The data.frame (in this case flights) represents the table we are querying
and goes in the FROM statement
# We can also compute new variables in the select statement using the syntax:
# old_variables as new_variable
ej2 = sqldf("
SELECT
arr_delay - dep_delay as gain,
carrier
FROM
flights
")
ej2[1:5, ]
# gain carrier
# 1 9 UA
# 2 16 UA
# 3 31 AA
# 4 -17 B6
# 5 -19 DL
SQL 最常用的特性之一是 group by 语句。这允许为另一个变量的不同组计算数值。打开脚本 02_group_by.R。
### GROUP BY
# Computing the average
ej3 = sqldf("
SELECT
avg(arr_delay) as mean_arr_delay,
avg(dep_delay) as mean_dep_delay,
carrier
FROM
flights
GROUP BY
carrier
")
# mean_arr_delay mean_dep_delay carrier
# 1 7.3796692 16.725769 9E
# 2 0.3642909 8.586016 AA
# 3 -9.9308886 5.804775 AS
# 4 9.4579733 13.022522 B6
# 5 1.6443409 9.264505 DL
# 6 15.7964311 19.955390 EV
# 7 21.9207048 20.215543 F9
# 8 20.1159055 18.726075 FL
# 9 -6.9152047 4.900585 HA
# 10 10.7747334 10.552041 MQ
# 11 11.9310345 12.586207 OO
# 12 3.5580111 12.106073 UA
# 13 2.1295951 3.782418 US
# 14 1.7644644 12.869421 VX
# 15 9.6491199 17.711744 WN
# 16 15.5569853 18.996330 YV
# Other aggregations
ej4 = sqldf("
SELECT
avg(arr_delay) as mean_arr_delay,
min(dep_delay) as min_dep_delay,
max(dep_delay) as max_dep_delay,
carrier
FROM
flights
GROUP BY
carrier
")
# We can compute the minimun, mean, and maximum values of a numeric value
ej4
# mean_arr_delay min_dep_delay max_dep_delay carrier
# 1 7.3796692 -24 747 9E
# 2 0.3642909 -24 1014 AA
# 3 -9.9308886 -21 225 AS
# 4 9.4579733 -43 502 B6
# 5 1.6443409 -33 960 DL
# 6 15.7964311 -32 548 EV
# 7 21.9207048 -27 853 F9
# 8 20.1159055 -22 602 FL
# 9 -6.9152047 -16 1301 HA
# 10 10.7747334 -26 1137 MQ
# 11 11.9310345 -14 154 OO
# 12 3.5580111 -20 483 UA
# 13 2.1295951 -19 500 US
# 14 1.7644644 -20 653 VX
# 15 9.6491199 -13 471 WN
# 16 15.5569853 -16 387 YV
### We could be also interested in knowing how many observations each carrier has
ej5 = sqldf("
SELECT
carrier, count(*) as count
FROM
flights
GROUP BY
carrier
")
ej5
# carrier count
# 1 9E 18460
# 2 AA 32729
# 3 AS 714
# 4 B6 54635
# 5 DL 48110
# 6 EV 54173
# 7 F9 685
# 8 FL 3260
# 9 HA 342
# 10 MQ 26397
# 11 OO 32
# 12 UA 58665
# 13 US 20536
# 14 VX 5162
# 15 WN 12275
# 16 YV 601
SQL 最有用的特性是连接。连接意味着我们希望使用一列将表 A 和表 B 合并到一个表中以匹配两个表的值。有不同类型的连接,实际上,开始使用这些将是最有用的:内连接和左外连接。
# Let’s create two tables: A and B to demonstrate joins.
A = data.frame(c1 = 1:4, c2 = letters[1:4])
B = data.frame(c1 = c(2,4,5,6), c2 = letters[c(2:5)])
A
# c1 c2
# 1 a
# 2 b
# 3 c
# 4 d
B
# c1 c2
# 2 b
# 4 c
# 5 d
# 6 e
### INNER JOIN
# This means to match the observations of the column we would join the tables by.
inner = sqldf("
SELECT
A.c1, B.c2
FROM
A INNER JOIN B
ON A.c1 = B.c1
")
# Only the rows that match c1 in both A and B are returned
inner
# c1 c2
# 2 b
# 4 c
### LEFT OUTER JOIN
# the left outer join, sometimes just called left join will return the
# first all the values of the column used from the A table
left = sqldf("
SELECT
A.c1, B.c2
FROM
A LEFT OUTER JOIN B
ON A.c1 = B.c1
")
# Only the rows that match c1 in both A and B are returned
left
# c1 c2
# 1 <NA>
# 2 b
# 3 <NA>
# 4 c
大数据分析 – 图表和图形
分析数据的第一种方法是对其进行可视化分析。这样做的目的通常是找到变量之间的关系以及变量的单变量描述。我们可以将这些策略划分为 –
- 单变量分析
- 多变量分析
单变量图形方法
单变量是一个统计术语。实际上,这意味着我们要独立于其余数据分析变量。允许有效执行此操作的图是 –
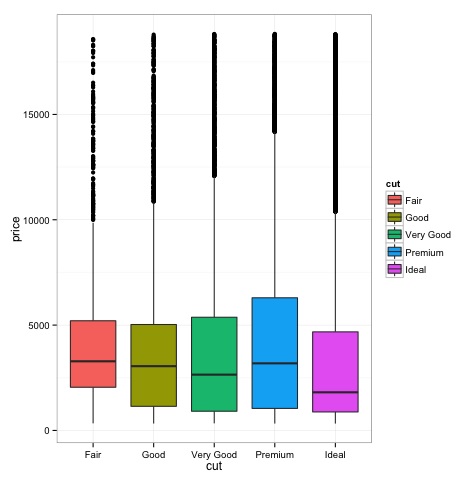
箱线图
箱线图通常用于比较分布。这是目视检查分布之间是否存在差异的好方法。我们可以看看不同切工的钻石价格是否有差异。
# We will be using the ggplot2 library for plotting
library(ggplot2)
data("diamonds")
# We will be using the diamonds dataset to analyze distributions of numeric variables
head(diamonds)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
# 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
# 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
# 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
# 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
### Box-Plots
p = ggplot(diamonds, aes(x = cut, y = price, fill = cut)) +
geom_box-plot() +
theme_bw()
print(p)
我们可以在图中看到,不同切工类型的钻石价格分布存在差异。
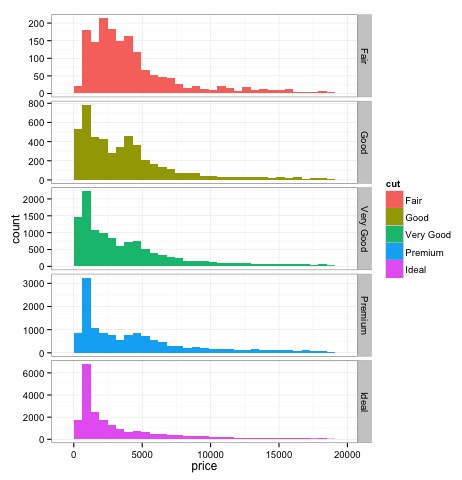
直方图
source('01_box_plots.R')
# We can plot histograms for each level of the cut factor variable using
facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ .) +
theme_bw()
p
# the previous plot doesn’t allow to visuallize correctly the data because of
the differences in scale
# we can turn this off using the scales argument of facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ ., scales = 'free') +
theme_bw()
p
png('02_histogram_diamonds_cut.png')
print(p)
dev.off()
上述代码的输出如下 –
多元图形方法
探索性数据分析中的多元图形方法的目标是发现不同变量之间的关系。有两种常用的方法可以实现这一点:绘制数值变量的相关矩阵或简单地将原始数据绘制为散点图矩阵。
为了证明这一点,我们将使用钻石数据集。要遵循代码,请打开脚本bda/part2/charts/03_multivariate_analysis.R。
library(ggplot2)
data(diamonds)
# Correlation matrix plots
keep_vars = c('carat', 'depth', 'price', 'table')
df = diamonds[, keep_vars]
# compute the correlation matrix
M_cor = cor(df)
# carat depth price table
# carat 1.00000000 0.02822431 0.9215913 0.1816175
# depth 0.02822431 1.00000000 -0.0106474 -0.2957785
# price 0.92159130 -0.01064740 1.0000000 0.1271339
# table 0.18161755 -0.29577852 0.1271339 1.0000000
# plots
heat-map(M_cor)
代码将产生以下输出 –
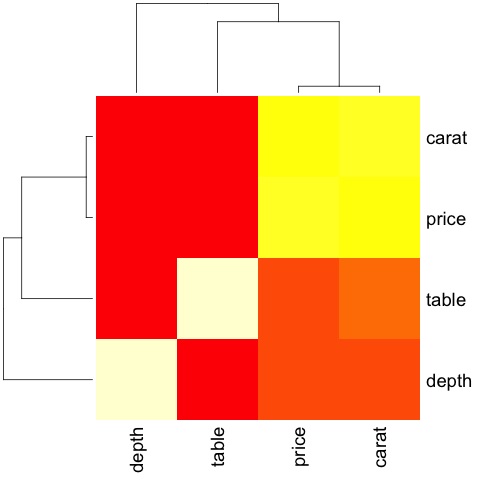
这是一个总结,它告诉我们价格和插入符号之间有很强的相关性,而其他变量之间的相关性不大。
当我们有大量变量时,相关矩阵会很有用,在这种情况下,绘制原始数据是不切实际的。如前所述,也可以显示原始数据 –
library(GGally) ggpairs(df)
我们可以在图中看到热图中显示的结果得到确认,价格和克拉变量之间的相关性为 0.922。
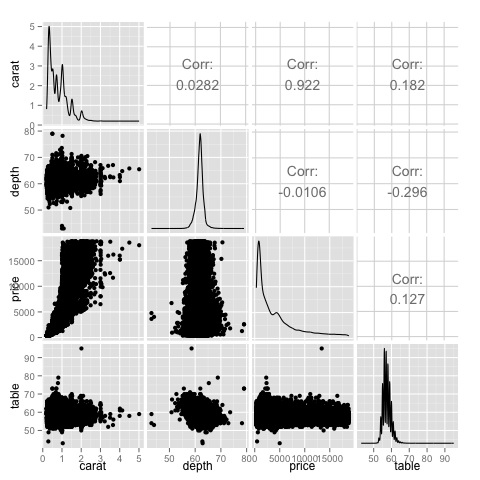
可以在位于散点图矩阵 (3, 1) 索引中的克拉价格散点图中可视化这种关系。
大数据分析 – 数据分析工具
有多种工具可以让数据科学家有效地分析数据。通常数据分析的工程方面侧重于数据库,数据科学家侧重于可以实现数据产品的工具。以下部分讨论了不同工具的优势,重点是数据科学家在实践中最常使用的统计包。
R 编程语言
R 是一种开源编程语言,专注于统计分析。在统计能力上与SAS、SPSS等商业工具竞争。它被认为是其他编程语言(如 C、C++ 或 Fortran)的接口。
R 的另一个优点是有大量可用的开源库。在 CRAN 中可以免费下载 6000 多个包,在Github 中提供各种各样的 R 包。
在性能方面,R 对于密集型操作很慢,因为有大量可用的库,代码的慢部分是用编译语言编写的。但是,如果您打算执行需要编写深度 for 循环的操作,那么 R 将不是您的最佳选择。出于数据分析的目的,有一些不错的库,例如data.table、glmnet、ranger、xgboost、ggplot2、caret,它们允许使用 R 作为更快的编程语言的接口。
用于数据分析的 Python
Python 是一种通用编程语言,它包含大量专门用于数据分析的库,例如pandas、scikit-learn、theano、numpy和scipy。
R 中可用的大部分内容也可以在 Python 中完成,但我们发现 R 更易于使用。如果您正在处理大型数据集,通常 Python 是比 R 更好的选择。Python 可以非常有效地用于逐行清理和处理数据。这在 R 中是可能的,但它在脚本任务方面不如 Python 高效。
对于机器学习,scikit-learn是一个很好的环境,它提供了大量的算法,可以毫无问题地处理中等规模的数据集。与 R 的等效库 (caret) 相比,scikit-learn具有更清晰、更一致的 API。
朱莉娅
Julia 是一种用于技术计算的高级、高性能动态编程语言。它的语法与 R 或 Python 非常相似,因此如果您已经在使用 R 或 Python,那么在 Julia 中编写相同的代码应该非常简单。该语言非常新,并且在过去几年中显着增长,因此目前绝对是一种选择。
我们会推荐 Julia 用于计算密集型算法的原型设计,例如神经网络。它是一个很好的研究工具。在生产中实现模型方面,Python 可能有更好的选择。然而,这已经不再是一个问题,因为有 Web 服务在 R、Python 和 Julia 中进行模型实现的工程。
SAS
SAS 是一种仍在用于商业智能的商业语言。它具有允许用户编写各种应用程序的基本语言。它包含相当多的商业产品,使非专家用户无需编程即可使用神经网络库等复杂工具。
除了商业工具的明显缺点之外,SAS 不能很好地扩展到大型数据集。即使是中等规模的数据集也会出现 SAS 问题并导致服务器崩溃。只有当您使用小型数据集并且用户不是专家数据科学家时,才推荐使用 SAS。对于高级用户,R 和 Python 提供了更高效的环境。
SPSS
SPSS,目前是IBM 用于统计分析的产品。它主要用于分析调查数据,对于无法编程的用户来说,它是一个不错的选择。它的使用可能和 SAS 一样简单,但在实现模型方面,它更简单,因为它提供了一个 SQL 代码来为模型评分。此代码通常效率不高,但这是一个开始,而 SAS 销售的产品分别为每个数据库的模型评分。对于小数据和缺乏经验的团队,SPSS 是与 SAS 一样好的选择。
然而,该软件相当有限,使用 R 或 Python 的有经验的用户将提高几个数量级的生产力。
Matlab,八度
还有其他可用的工具,例如 Matlab 或其开源版本 (Octave)。这些工具主要用于研究。就功能而言,R 或 Python 可以完成 Matlab 或 Octave 中可用的所有功能。如果您对他们提供的支持感兴趣,则购买该产品的许可证才有意义。
大数据分析 – 统计方法
在分析数据时,可以采用统计方法。执行基本分析所需的基本工具是 –
- 相关分析
- 方差分析
- 假设检验
处理大型数据集时,不会出现问题,因为这些方法的计算量并不大,相关性分析除外。在这种情况下,总是可以取样并且结果应该是可靠的。
相关分析
相关分析旨在找出数值变量之间的线性关系。这可以在不同的情况下使用。一个常见的用途是探索性数据分析,在本书的 16.0.2 节中有一个这种方法的基本示例。首先,上述示例中使用的相关度量基于Pearson 系数。然而,还有另一个有趣的相关性指标不受异常值影响。该指标称为斯皮尔曼相关性。
的Spearman相关度量是更稳健的对异常值比Pearson法的存在,并给出数值变量之间的线性关系的更好的估计,当数据不是正态分布。
library(ggplot2)
# Select variables that are interesting to compare pearson and spearman
correlation methods.
x = diamonds[, c('x', 'y', 'z', 'price')]
# From the histograms we can expect differences in the correlations of both
metrics.
# In this case as the variables are clearly not normally distributed, the
spearman correlation
# is a better estimate of the linear relation among numeric variables.
par(mfrow = c(2,2))
colnm = names(x)
for(i in 1:4) {
hist(x[[i]], col = 'deepskyblue3', main = sprintf('Histogram of %s', colnm[i]))
}
par(mfrow = c(1,1))
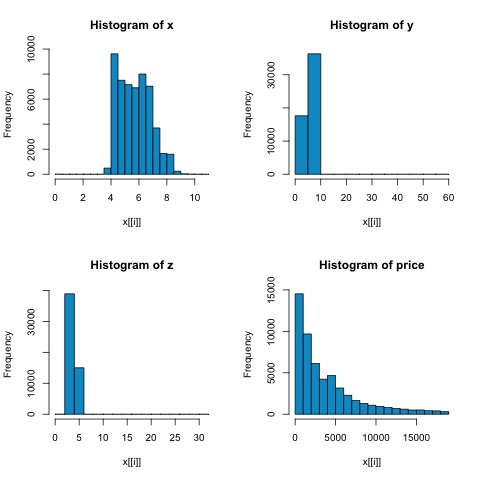
从下图中的直方图,我们可以预期两个指标的相关性存在差异。在这种情况下,由于变量显然不是正态分布的,spearman 相关性是对数值变量之间线性关系的更好估计。
为了计算 R 中的相关性,打开包含此代码部分的文件bda/part2/statistical_methods/correlation/correlation.R。
## Correlation Matrix - Pearson and spearman cor_pearson <- cor(x, method = 'pearson') cor_spearman <- cor(x, method = 'spearman') ### Pearson Correlation print(cor_pearson) # x y z price # x 1.0000000 0.9747015 0.9707718 0.8844352 # y 0.9747015 1.0000000 0.9520057 0.8654209 # z 0.9707718 0.9520057 1.0000000 0.8612494 # price 0.8844352 0.8654209 0.8612494 1.0000000 ### Spearman Correlation print(cor_spearman) # x y z price # x 1.0000000 0.9978949 0.9873553 0.9631961 # y 0.9978949 1.0000000 0.9870675 0.9627188 # z 0.9873553 0.9870675 1.0000000 0.9572323 # price 0.9631961 0.9627188 0.9572323 1.0000000
卡方检验
卡方检验允许我们测试两个随机变量是否独立。这意味着每个变量的概率分布不会影响另一个。为了评估 R 中的测试,我们首先需要创建一个列联表,然后将表传递给chisq.test R函数。
例如,让我们检查变量之间是否存在关联:来自钻石数据集的切割和颜色。该测试正式定义为 –
- H0:可变切工和钻石是独立的
- H1:可变切工和钻石不是独立的
我们会假设这两个变量的名称之间存在关系,但测试可以给出一个客观的“规则”,说明这个结果的重要性与否。
在下面的代码片段中,我们发现测试的 p 值为 2.2e-16,实际上几乎为零。然后在运行测试进行蒙特卡罗模拟后,我们发现 p 值为 0.0004998,仍远低于阈值 0.05。这个结果意味着我们拒绝原假设 (H0),因此我们认为变量cut和color不是独立的。
library(ggplot2) # Use the table function to compute the contingency table tbl = table(diamonds$cut, diamonds$color) tbl # D E F G H I J # Fair 163 224 312 314 303 175 119 # Good 662 933 909 871 702 522 307 # Very Good 1513 2400 2164 2299 1824 1204 678 # Premium 1603 2337 2331 2924 2360 1428 808 # Ideal 2834 3903 3826 4884 3115 2093 896 # In order to run the test we just use the chisq.test function. chisq.test(tbl) # Pearson’s Chi-squared test # data: tbl # X-squared = 310.32, df = 24, p-value < 2.2e-16 # It is also possible to compute the p-values using a monte-carlo simulation # It's needed to add the simulate.p.value = TRUE flag and the amount of simulations chisq.test(tbl, simulate.p.value = TRUE, B = 2000) # Pearson’s Chi-squared test with simulated p-value (based on 2000 replicates) # data: tbl # X-squared = 310.32, df = NA, p-value = 0.0004998
T检验
t 检验的思想是评估一个数字变量#分布在不同组名义变量之间是否存在差异。为了证明这一点,我将选择因子变量 cut 的 Fair 和 Ideal 水平的水平,然后我们将比较这两组之间的数值变量的值。
data = diamonds[diamonds$cut %in% c('Fair', 'Ideal'), ]
data$cut = droplevels.factor(data$cut) # Drop levels that aren’t used from the
cut variable
df1 = data[, c('cut', 'price')]
# We can see the price means are different for each group
tapply(df1$price, df1$cut, mean)
# Fair Ideal
# 4358.758 3457.542
t 检验在 R 中使用t.test函数实现。t.test 的公式接口是最简单的使用方法,其思想是数字变量由组变量解释。
例如:t.test(numeric_variable ~ group_variable, data = data)。在前面的示例中,numeric_variable是price,group_variable是cut。
从统计的角度来看,我们正在测试两组之间数值变量的分布是否存在差异。正式的假设检验是用一个零假设 (H0) 和一个备择假设 (H1) 来描述的。
-
H0:公平组和理想组之间价格变量的分布没有差异
-
H1 Fair 和 Ideal 组之间价格变量的分布存在差异
可以使用以下代码在 R 中实现以下内容 –
t.test(price ~ cut, data = data) # Welch Two Sample t-test # # data: price by cut # t = 9.7484, df = 1894.8, p-value < 2.2e-16 # alternative hypothesis: true difference in means is not equal to 0 # 95 percent confidence interval: # 719.9065 1082.5251 # sample estimates: # mean in group Fair mean in group Ideal # 4358.758 3457.542 # Another way to validate the previous results is to just plot the distributions using a box-plot plot(price ~ cut, data = data, ylim = c(0,12000), col = 'deepskyblue3')
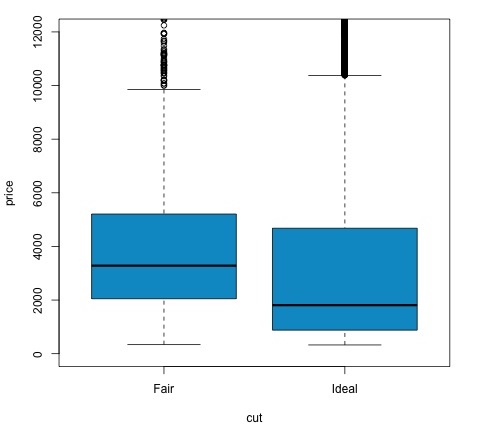
我们可以通过检查 p 值是否低于 0.05 来分析测试结果。如果是这种情况,我们保留备择假设。这意味着我们发现了两个削减因子水平之间的价格差异。根据级别的名称,我们会预期这个结果,但我们不会预期失败组中的平均价格会高于理想组中的平均价格。我们可以通过比较每个因素的均值来看到这一点。
的情节命令产生的曲线图,显示了价格和切变量之间的关系。这是一个箱线图;我们已经在 16.0.1 节中介绍了这个图,但它基本上显示了我们正在分析的两个切割水平的价格变量的分布。
方差分析
方差分析(ANOVA)是一种通过比较各组的均值和方差来分析组间分布差异的统计模型,该模型由Ronald Fisher开发。方差分析提供了几个组的均值是否相等的统计检验,因此将 t 检验推广到两个以上的组。
ANOVA 可用于比较三个或更多组的统计显着性,因为进行多个双样本 t 检验会增加发生统计 I 类错误的机会。
在提供数学解释方面,需要以下内容来理解测试。
Xij = x + (xi − x) + (xij − x)
这导致以下模型 –
Xij = μ + αi + ∈ij
其中 μ 是大均值,αi是第 i 组均值。误差项∈ij假设为正态分布的 iid。测试的零假设是 –
α1 = α2 = … = αk
在计算测试统计量方面,我们需要计算两个值 –
- 组间差异的平方和 –
$$SSD_B = \sum_{i}^{k} \sum_{j}^{n}(\bar{x_{\bar{i}}} – \bar{x})^2$$
- 组内平方和
$$SSD_W = \sum_{i}^{k} \sum_{j}^{n}(\bar{x_{\bar{ij}}} – \bar{x_{\bar{i}}})^ 2$$
固态硬盘在哪里B 具有 k−1 和 SSD 的自由度W具有 N−k 的自由度。然后我们可以定义每个度量的均方差。
小姐B = 固态硬盘B / (k – 1)
小姐w = 固态硬盘w / (N – k)
最后,ANOVA中的检验统计量定义为上述两个量的比值
F = MSB / 小姐w
它遵循具有k-1和N-k自由度的F 分布。如果原假设为真,则 F 可能接近 1。否则,组间均方 MSB 可能很大,从而导致 F 值很大。
基本上,方差分析会检查总方差的两个来源,并查看哪一部分贡献更大。这就是为什么它被称为方差分析,尽管其目的是比较组均值。
在计算统计量方面,在 R 中实际上相当简单。以下示例将演示如何完成并绘制结果。
library(ggplot2)
# We will be using the mtcars dataset
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
# Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
# Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
# Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
# Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
# Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
# Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
# Let's see if there are differences between the groups of cyl in the mpg variable.
data = mtcars[, c('mpg', 'cyl')]
fit = lm(mpg ~ cyl, data = mtcars)
anova(fit)
# Analysis of Variance Table
# Response: mpg
# Df Sum Sq Mean Sq F value Pr(>F)
# cyl 1 817.71 817.71 79.561 6.113e-10 ***
# Residuals 30 308.33 10.28
# Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 .
# Plot the distribution
plot(mpg ~ as.factor(cyl), data = mtcars, col = 'deepskyblue3')
代码将产生以下输出 –
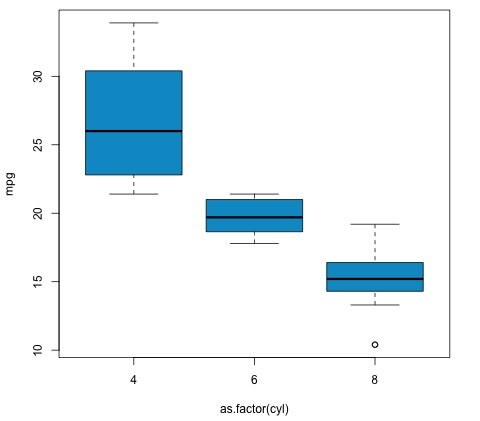
我们在示例中得到的 p 值明显小于 0.05,因此 R 返回符号“***”来表示这一点。这意味着我们拒绝原假设,并且我们发现cyl变量的不同组之间 mpg 均值之间存在差异。
用于数据分析的机器学习
机器学习是计算机科学的一个子领域,处理模式识别、计算机视觉、语音识别、文本分析等任务,并与统计学和数学优化有着密切的联系。应用包括开发搜索引擎、垃圾邮件过滤、光学字符识别 (OCR) 等。数据挖掘、模式识别和统计学习领域的界限并不明确,基本上都是指类似的问题。
机器学习可以分为两种类型的任务 –
- 监督学习
- 无监督学习
监督学习
监督学习是指一种问题,其中输入数据定义为矩阵X,我们对预测响应y感兴趣。其中X = {x1, X2, …, Xn}有n 个预测变量并有两个值y = {c1, C2} .
一个示例应用程序是使用人口统计特征作为预测变量来预测网络用户点击广告的概率。这通常被称为预测点击率 (CTR)。然后y = {click, doesn’t − click}并且预测变量可以是使用的 IP 地址、他进入站点的日期、用户的城市、国家以及其他可用的功能。
无监督学习
无监督学习解决了在没有类可供学习的情况下找到彼此相似的组的问题。有几种方法可以学习从预测变量到查找在每个组中共享相似实例且彼此不同的组的映射。
无监督学习的一个示例应用是客户细分。例如,在电信行业中,一项常见任务是根据用户对电话的使用情况对用户进行细分。这将允许营销部门针对每个群体使用不同的产品。
大数据分析 – 朴素贝叶斯分类器
朴素贝叶斯是一种构建分类器的概率技术。朴素贝叶斯分类器的特征假设是考虑给定类变量,特定特征的值独立于任何其他特征的值。
尽管前面提到的假设过于简单,朴素贝叶斯分类器在复杂的现实世界情况下也有很好的结果。朴素贝叶斯的一个优点是它只需要少量的训练数据来估计分类所需的参数,并且分类器可以增量训练。
朴素贝叶斯是一个条件概率模型:给定一个要分类的问题实例,用向量x = (x1, …, Xn) 代表一些 n 个特征(自变量),它为 K 个可能的结果或类别中的每一个分配给这个实例概率。
$$p(C_k|x_1,….., x_n)$$
上述公式的问题在于,如果特征数量 n 很大或者一个特征可以具有大量值,那么基于概率表建立这样的模型是不可行的。因此,我们重新制定模型以使其更简单。使用贝叶斯定理,条件概率可以分解为 –
$$p(C_k|x) = \frac{p(C_k)p(x|C_k)}{p(x)}$$
这意味着在上述独立性假设下,类变量 C 的条件分布是 –
$$p(C_k|x_1,….., x_n)\: = \: \frac{1}{Z}p(C_k)\prod_{i = 1}^{n}p(x_i|C_k) $$
其中证据 Z = p( x ) 是一个仅依赖于 x 的缩放因子1, …, Xn,如果特征变量的值已知,则为常数。一个常见的规则是选择最有可能的假设;这被称为最大后验或 MAP 决策规则。相应的分类器,贝叶斯分类器,是为某些 k 分配类标签 $\hat{y} = C_k$ 的函数,如下所示 –
$$\hat{y} = argmax\: p(C_k)\prod_{i = 1}^{n}p(x_i|C_k)$$
在 R 中实现算法是一个简单的过程。以下示例演示了如何训练朴素贝叶斯分类器并将其用于垃圾邮件过滤问题的预测。
以下脚本在bda/part3/naive_bayes/naive_bayes.R文件中可用。
# Install these packages
pkgs = c("klaR", "caret", "ElemStatLearn")
install.packages(pkgs)
library('ElemStatLearn')
library("klaR")
library("caret")
# Split the data in training and testing
inx = sample(nrow(spam), round(nrow(spam) * 0.9))
train = spam[inx,]
test = spam[-inx,]
# Define a matrix with features, X_train
# And a vector with class labels, y_train
X_train = train[,-58]
y_train = train$spam
X_test = test[,-58]
y_test = test$spam
# Train the model
nb_model = train(X_train, y_train, method = 'nb',
trControl = trainControl(method = 'cv', number = 3))
# Compute
preds = predict(nb_model$finalModel, X_test)$class
tbl = table(y_test, yhat = preds)
sum(diag(tbl)) / sum(tbl)
# 0.7217391
从结果可以看出,朴素贝叶斯模型的准确率为 72%。这意味着模型正确分类了 72% 的实例。
大数据分析 – K-Means 聚类
k-means 聚类旨在将 n 个观测值划分为 k 个聚类,其中每个观测值属于具有最近均值的聚类,作为聚类的原型。这导致将数据空间划分为 Voronoi 单元。
给定一组观测值(x1, X2, …, Xn),其中每个观测值是一个 d 维实向量,k 均值聚类旨在将 n 个观测值划分为 k 个组G = {G1, G2, …, Gk},以便最小化定义如下平方(WCSS)的内簇总和-
$$argmin \: \sum_{i = 1}^{k} \sum_{x \in S_{i}}\parallel x – \mu_{i}\parallel ^2$$
后面的公式显示了最小化的目标函数,以便在 k-means 聚类中找到最佳原型。公式的直觉是我们希望找到彼此不同的组,并且每个组的每个成员都应该与每个集群的其他成员相似。
以下示例演示了如何在 R 中运行 k-means 聚类算法。
library(ggplot2)
# Prepare Data
data = mtcars
# We need to scale the data to have zero mean and unit variance
data <- scale(data)
# Determine number of clusters
wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:dim(data)[2]) {
wss[i] <- sum(kmeans(data, centers = i)$withinss)
}
# Plot the clusters
plot(1:dim(data)[2], wss, type = "b", xlab = "Number of Clusters",
ylab = "Within groups sum of squares")
为了找到合适的 K 值,我们可以绘制不同 K 值的组内平方和。该度量通常随着添加更多组而减少,我们想找到一个点,其中组内减少的总和平方开始缓慢减少。在图中,这个值最好用 K = 6 来表示。
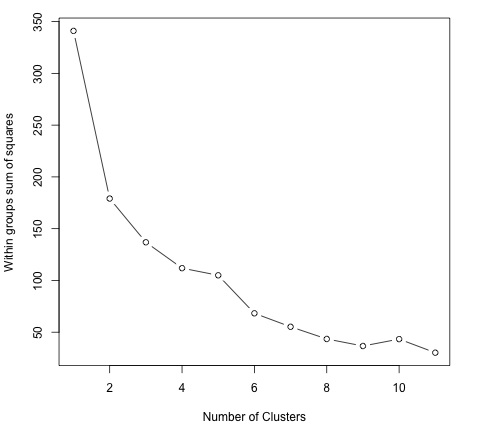
现在已经定义了 K 的值,需要使用该值运行算法。
# K-Means Cluster Analysis fit <- kmeans(data, 5) # 5 cluster solution # get cluster means aggregate(data,by = list(fit$cluster),FUN = mean) # append cluster assignment data <- data.frame(data, fit$cluster)
大数据分析-关联规则
让我=我1, 一世2, …, 一世n是一组称为项的 n 个二进制属性。令D = t1, t2, …, tm是一组称为数据库的事务。D 中的每个交易都有一个唯一的交易 ID,并包含 I 中项目的一个子集。规则定义为 X ⇒ Y 形式的蕴涵,其中 X, Y ⊆ I 和 X ∩ Y = ∅。
项目集(对于短项目集)X 和 Y 被称为规则的先行(左侧或 LHS)和结果(右侧或 RHS)。
为了说明这些概念,我们使用超市领域的一个小例子。项目集是 I = {牛奶、面包、黄油、啤酒},包含这些项目的小型数据库如下表所示。
| Transaction ID | 项目 |
|---|---|
| 1 | 牛奶、面包 |
| 2 | 牛油面包 |
| 3 | 啤酒 |
| 4 | 牛奶、面包、黄油 |
| 5 | 牛油面包 |
超市的一个示例规则可以是 {milk, bread} ⇒ {butter} 意味着如果购买了牛奶和面包,顾客也会购买黄油。为了从所有可能规则的集合中选择感兴趣的规则,可以使用对重要性和兴趣的各种度量的约束。最著名的约束是支持度和置信度的最小阈值。
项集 X 的支持度 supp(X) 定义为包含该项集的数据集中事务的比例。在表 1 的示例数据库中,项目集 {milk, bread} 的支持率为 2/5 = 0.4,因为它出现在所有事务的 40% 中(5 个事务中有 2 个)。查找频繁项集可以看作是对无监督学习问题的简化。
规则的置信度定义为 conf(X ⇒ Y ) = supp(X ∪ Y )/supp(X)。例如,规则 {milk, bread} ⇒ {butter} 在表 1 的数据库中的置信度为 0.2/0.4 = 0.5,这意味着对于 50% 的包含牛奶和面包的交易,该规则是正确的。置信度可以解释为概率 P(Y|X) 的估计,即在这些交易也包含 LHS 的情况下,在交易中找到规则的 RHS 的概率。
在位于bda/part3/apriori.R的脚本中,可以找到实现apriori 算法的代码。
# Load the library for doing association rules
# install.packages(’arules’)
library(arules)
# Data preprocessing
data("AdultUCI")
AdultUCI[1:2,]
AdultUCI[["fnlwgt"]] <- NULL
AdultUCI[["education-num"]] <- NULL
AdultUCI[[ "age"]] <- ordered(cut(AdultUCI[[ "age"]], c(15,25,45,65,100)),
labels = c("Young", "Middle-aged", "Senior", "Old"))
AdultUCI[[ "hours-per-week"]] <- ordered(cut(AdultUCI[[ "hours-per-week"]],
c(0,25,40,60,168)), labels = c("Part-time", "Full-time", "Over-time", "Workaholic"))
AdultUCI[[ "capital-gain"]] <- ordered(cut(AdultUCI[[ "capital-gain"]],
c(-Inf,0,median(AdultUCI[[ "capital-gain"]][AdultUCI[[ "capitalgain"]]>0]),Inf)),
labels = c("None", "Low", "High"))
AdultUCI[[ "capital-loss"]] <- ordered(cut(AdultUCI[[ "capital-loss"]],
c(-Inf,0, median(AdultUCI[[ "capital-loss"]][AdultUCI[[ "capitalloss"]]>0]),Inf)),
labels = c("none", "low", "high"))
为了使用 apriori 算法生成规则,我们需要创建一个交易矩阵。以下代码显示了如何在 R 中执行此操作。
# Convert the data into a transactions format
Adult <- as(AdultUCI, "transactions")
Adult
# transactions in sparse format with
# 48842 transactions (rows) and
# 115 items (columns)
summary(Adult)
# Plot frequent item-sets
itemFrequencyPlot(Adult, support = 0.1, cex.names = 0.8)
# generate rules
min_support = 0.01
confidence = 0.6
rules <- apriori(Adult, parameter = list(support = min_support, confidence = confidence))
rules
inspect(rules[100:110, ])
# lhs rhs support confidence lift
# {occupation = Farming-fishing} => {sex = Male} 0.02856148 0.9362416 1.4005486
# {occupation = Farming-fishing} => {race = White} 0.02831579 0.9281879 1.0855456
# {occupation = Farming-fishing} => {native-country 0.02671881 0.8758389 0.9759474
= United-States}
大数据分析 – 决策树
决策树是一种用于监督学习问题(例如分类或回归)的算法。决策树或分类树是其中每个内部(非叶)节点都标有输入特征的树。来自标记有特征的节点的弧被标记为特征的每个可能值。树的每个叶子都标有一个类或这些类的概率分布。
可以通过基于属性值测试将源集拆分为子集来“学习”树。以递归方式在每个派生子集上重复此过程,称为递归分区。当节点上的子集具有与目标变量完全相同的值,或者当分裂不再为预测增加值时,递归完成。这种自上而下归纳决策树的过程是贪心算法的一个例子,也是学习决策树最常见的策略。
数据挖掘中使用的决策树有两种主要类型 –
-
分类树– 当响应是一个名义变量时,例如电子邮件是否是垃圾邮件。
-
回归树– 当预测结果可以被认为是一个实数(例如工人的工资)。
决策树是一种简单的方法,因此存在一些问题。这个问题之一是决策树产生的结果模型的高方差。为了缓解这个问题,开发了决策树的集成方法。目前广泛使用的有两组集成方法 –
-
装袋决策树– 这些树用于通过重复对训练数据进行重采样和替换来构建多个决策树,并对树进行投票以进行共识预测。这种算法被称为随机森林。
-
提升决策树– 梯度提升结合了弱学习器;在这种情况下,决策树以迭代方式转化为单个强学习器。它为数据拟合一个弱树,并迭代地不断拟合弱学习器,以纠正先前模型的错误。
# Install the party package
# install.packages('party')
library(party)
library(ggplot2)
head(diamonds)
# We will predict the cut of diamonds using the features available in the
diamonds dataset.
ct = ctree(cut ~ ., data = diamonds)
# plot(ct, main="Conditional Inference Tree")
# Example output
# Response: cut
# Inputs: carat, color, clarity, depth, table, price, x, y, z
# Number of observations: 53940
#
# 1) table <= 57; criterion = 1, statistic = 10131.878
# 2) depth <= 63; criterion = 1, statistic = 8377.279
# 3) table <= 56.4; criterion = 1, statistic = 226.423
# 4) z <= 2.64; criterion = 1, statistic = 70.393
# 5) clarity <= VS1; criterion = 0.989, statistic = 10.48
# 6) color <= E; criterion = 0.997, statistic = 12.829
# 7)* weights = 82
# 6) color > E
#Table of prediction errors
table(predict(ct), diamonds$cut)
# Fair Good Very Good Premium Ideal
# Fair 1388 171 17 0 14
# Good 102 2912 499 26 27
# Very Good 54 998 3334 249 355
# Premium 44 711 5054 11915 1167
# Ideal 22 114 3178 1601 19988
# Estimated class probabilities
probs = predict(ct, newdata = diamonds, type = "prob")
probs = do.call(rbind, probs)
head(probs)
大数据分析 – 逻辑回归
逻辑回归是一种分类模型,其中响应变量是分类的。它是一种来自统计学的算法,用于有监督的分类问题。在逻辑回归中,我们寻求在以下方程中找到参数的向量 β,以最小化成本函数。
$$logit(p_i) = ln \left ( \frac{p_i}{1 – p_i} \right ) = \beta_0 + \beta_1x_{1,i} + … + \beta_kx_{k,i}$$
以下代码演示了如何在 R 中拟合逻辑回归模型。我们将在这里使用垃圾邮件数据集来演示逻辑回归,这与用于朴素贝叶斯的相同。
从准确率方面的预测结果来看,我们发现回归模型在测试集中达到了 92.5% 的准确率,而朴素贝叶斯分类器达到了 72%。
library(ElemStatLearn) head(spam) # Split dataset in training and testing inx = sample(nrow(spam), round(nrow(spam) * 0.8)) train = spam[inx,] test = spam[-inx,] # Fit regression model fit = glm(spam ~ ., data = train, family = binomial()) summary(fit) # Call: # glm(formula = spam ~ ., family = binomial(), data = train) # # Deviance Residuals: # Min 1Q Median 3Q Max # -4.5172 -0.2039 0.0000 0.1111 5.4944 # Coefficients: # Estimate Std. Error z value Pr(>|z|) # (Intercept) -1.511e+00 1.546e-01 -9.772 < 2e-16 *** # A.1 -4.546e-01 2.560e-01 -1.776 0.075720 . # A.2 -1.630e-01 7.731e-02 -2.108 0.035043 * # A.3 1.487e-01 1.261e-01 1.179 0.238591 # A.4 2.055e+00 1.467e+00 1.401 0.161153 # A.5 6.165e-01 1.191e-01 5.177 2.25e-07 *** # A.6 7.156e-01 2.768e-01 2.585 0.009747 ** # A.7 2.606e+00 3.917e-01 6.652 2.88e-11 *** # A.8 6.750e-01 2.284e-01 2.955 0.003127 ** # A.9 1.197e+00 3.362e-01 3.559 0.000373 *** # Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1 ### Make predictions preds = predict(fit, test, type = ’response’) preds = ifelse(preds > 0.5, 1, 0) tbl = table(target = test$spam, preds) tbl # preds # target 0 1 # email 535 23 # spam 46 316 sum(diag(tbl)) / sum(tbl) # 0.925
大数据分析 – 时间序列分析
时间序列是由日期或时间戳索引的分类或数字变量的观察序列。时间序列数据的一个明显例子是股票价格的时间序列。在下表中,我们可以看到时间序列数据的基本结构。在这种情况下,观察结果每小时记录一次。
| Timestamp | 股票价格 |
|---|---|
| 2015-10-11 09:00:00 | 100 |
| 2015-10-11 10:00:00 | 110 |
| 2015-10-11 11:00:00 | 105 |
| 2015-10-11 12:00:00 | 90 |
| 2015-10-11 13:00:00 | 120 |
通常,时间序列分析的第一步是绘制序列,这通常使用折线图完成。
时间序列分析最常见的应用是使用数据的时间结构预测数值的未来值。这意味着,可用的观测值用于预测未来的值。
数据的时间顺序意味着传统的回归方法没有用。为了建立稳健的预测,我们需要考虑数据时间顺序的模型。
最广泛使用的时间序列分析模型称为自回归移动平均(ARMA)。该模型由两部分组成,自回归(AR) 部分和移动平均(MA) 部分。该模型通常被称为ARMA(p, q)模型,其中p是自回归部分的阶数,q是移动平均部分的阶数。
自回归模型
的AR(P)被读取为阶数p的自回归模型。在数学上它写为 –
$$X_t = c + \sum_{i = 1}^{P} \phi_i X_{t – i} + \varepsilon_{t}$$
其中{φ1, …, φp} 是要估计的参数,c 是常数,随机变量 εt代表白噪声。需要对参数值进行一些约束,以便模型保持平稳。
移动平均线
符号MA(Q)指令的移动平均模型q –
$$X_t = \mu + \varepsilon_t + \sum_{i = 1}^{q} \theta_i \varepsilon_{t – i}$$
其中 θ1, …, θq 是模型的参数,μ 是 X 的期望t, 和 εt, εt − 1, … 是白噪声误差项。
自回归移动平均线
的ARMA(P,Q)模型结合p自回归项和q移动平均而言。在数学上,模型用以下公式表示 –
$$X_t = c + \varepsilon_t + \sum_{i = 1}^{P} \phi_iX_{t – 1} + \sum_{i = 1}^{q} \theta_i \varepsilon_{ti}$$
我们可以看到ARMA(p, q)模型是AR(p)和MA(q)模型的组合。
为了给出模型的一些直觉,考虑方程的 AR 部分试图估计 X 的参数t − i 为了预测变量在 X 中的值的观察t. 它最终是过去值的加权平均值。MA 部分使用相同的方法,但具有先前观测值的误差,εt − i. 所以最终模型的结果是一个加权平均。
以下代码片段演示了如何在 R 中实现ARMA(p, q)。
# install.packages("forecast")
library("forecast")
# Read the data
data = scan('fancy.dat')
ts_data <- ts(data, frequency = 12, start = c(1987,1))
ts_data
plot.ts(ts_data)
绘制数据通常是找出数据中是否存在时间结构的第一步。从图中我们可以看出,每年年底都有很强的尖峰。
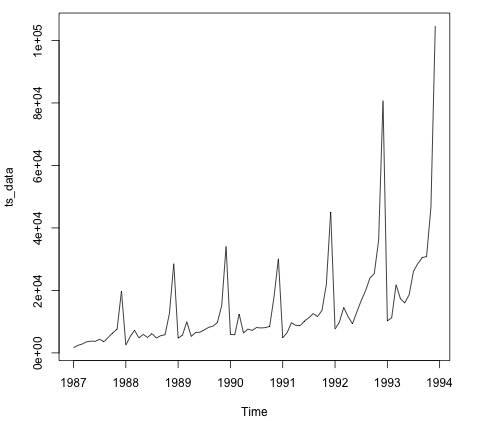
以下代码将 ARMA 模型拟合到数据中。它运行多种模型组合并选择误差较小的一种。
# Fit the ARMA model fit = auto.arima(ts_data) summary(fit) # Series: ts_data # ARIMA(1,1,1)(0,1,1)[12] # Coefficients: # ar1 ma1 sma1 # 0.2401 -0.9013 0.7499 # s.e. 0.1427 0.0709 0.1790 # # sigma^2 estimated as 15464184: log likelihood = -693.69 # AIC = 1395.38 AICc = 1395.98 BIC = 1404.43 # Training set error measures: # ME RMSE MAE MPE MAPE MASE ACF1 # Training set 328.301 3615.374 2171.002 -2.481166 15.97302 0.4905797 -0.02521172
大数据分析 – 文本分析
在本章中,我们将使用本书第 1 部分中抓取的数据。该数据包含描述自由职业者简介的文本,以及他们以美元计价的小时费率。以下部分的想法是拟合一个模型,该模型给定自由职业者的技能,我们能够预测其小时工资。
下面的代码显示了如何在词袋矩阵中转换在这种情况下具有用户技能的原始文本。为此,我们使用了一个名为 tm 的 R 库。这意味着对于语料库中的每个单词,我们都会根据每个变量的出现次数创建变量。
library(tm)
library(data.table)
source('text_analytics/text_analytics_functions.R')
data = fread('text_analytics/data/profiles.txt')
rate = as.numeric(data$rate)
keep = !is.na(rate)
rate = rate[keep]
### Make bag of words of title and body
X_all = bag_words(data$user_skills[keep])
X_all = removeSparseTerms(X_all, 0.999)
X_all
# <<DocumentTermMatrix (documents: 389, terms: 1422)>>
# Non-/sparse entries: 4057/549101
# Sparsity : 99%
# Maximal term length: 80
# Weighting : term frequency - inverse document frequency (normalized) (tf-idf)
### Make a sparse matrix with all the data
X_all <- as_sparseMatrix(X_all)
现在我们将文本表示为一个稀疏矩阵,我们可以拟合一个模型来给出一个稀疏解。这种情况的一个很好的替代方法是使用 LASSO(最小绝对收缩和选择运算符)。这是一个回归模型,能够选择最相关的特征来预测目标。
train_inx = 1:200 X_train = X_all[train_inx, ] y_train = rate[train_inx] X_test = X_all[-train_inx, ] y_test = rate[-train_inx] # Train a regression model library(glmnet) fit <- cv.glmnet(x = X_train, y = y_train, family = 'gaussian', alpha = 1, nfolds = 3, type.measure = 'mae') plot(fit) # Make predictions predictions = predict(fit, newx = X_test) predictions = as.vector(predictions[,1]) head(predictions) # 36.23598 36.43046 51.69786 26.06811 35.13185 37.66367 # We can compute the mean absolute error for the test data mean(abs(y_test - predictions)) # 15.02175
现在我们有一个模型,给定一组技能,可以预测自由职业者的时薪。如果收集到更多数据,模型的性能将会提高,但实现此管道的代码将是相同的。
大数据分析 – 在线学习
在线学习是机器学习的一个子领域,它允许将监督学习模型扩展到海量数据集。基本思想是我们不需要读取内存中的所有数据来拟合模型,我们只需要一次读取每个实例。
在这种情况下,我们将展示如何使用逻辑回归实现在线学习算法。与大多数监督学习算法一样,有一个最小化的成本函数。在逻辑回归中,成本函数定义为 –
$$J(\theta) \: = \: \frac{-1}{m} \left [ \sum_{i = 1}^{m}y^{(i)}log(h_{\theta}( x^{(i)})) + (1 – y^{(i)}) log(1 – h_{\theta}(x^{(i)})) \right ]$$
其中J(θ)代表成本函数,hθ(x)代表假设。在逻辑回归的情况下,它用以下公式定义 –
$$h_\theta(x) = \frac{1}{1 + e^{\theta^T x}}$$
现在我们已经定义了成本函数,我们需要找到一个算法来最小化它。实现这一目标的最简单算法称为随机梯度下降。逻辑回归模型权重的算法更新规则定义为 –
$$\theta_j : = \theta_j – \alpha(h_\theta(x) – y)x$$
下面的算法有几种实现方式,但在vawpal wabbit库中实现的一种是迄今为止最发达的一种。该库允许训练大规模回归模型并使用少量 RAM。用创作者自己的话来说,它被描述为:“Vowpal Wabbit (VW) 项目是一个由 Microsoft Research 和(以前的)Yahoo! Research 赞助的快速核外学习系统”。
我们将使用来自Kaggle比赛的 Titanic 数据集。原始数据可以在bda/part3/vw文件夹中找到。在这里,我们有两个文件 –
- 我们有训练数据 (train_titanic.csv),和
- 未标记的数据以进行新的预测(test_titanic.csv)。
为了将 csv 格式转换为vowpal wabbit输入格式,请使用csv_to_vowpal_wabbit.py python 脚本。您显然需要为此安装python。导航到bda/part3/vw文件夹,打开终端并执行以下命令 –
python csv_to_vowpal_wabbit.py
请注意,对于本节,如果您使用的是 Windows,则需要安装 Unix 命令行,请输入cygwin网站。
打开终端以及文件夹bda/part3/vw并执行以下命令 –
vw train_titanic.vw -f model.vw --binary --passes 20 -c -q ff --sgd --l1 0.00000001 --l2 0.0000001 --learning_rate 0.5 --loss_function logistic
让我们分解一下vw 调用的每个参数的含义。
-
-f model.vw – 表示我们将模型保存在 model.vw 文件中以便稍后进行预测
-
–binary – 将损失报告为带有 -1,1 标签的二元分类
-
–passes 20 – 数据被使用 20 次来学习权重
-
-c – 创建缓存文件
-
-q ff – 在 f 命名空间中使用二次特征
-
–sgd – 使用常规/经典/简单随机梯度下降更新,即非自适应、非标准化和非不变。
-
–l1 –l2 – L1 和 L2 范数正则化
-
–learning_rate 0.5 – 更新规则公式中定义的学习率α
以下代码显示了在命令行中运行回归模型的结果。在结果中,我们得到了平均对数损失和算法性能的小报告。
-loss_function logistic creating quadratic features for pairs: ff using l1 regularization = 1e-08 using l2 regularization = 1e-07 final_regressor = model.vw Num weight bits = 18 learning rate = 0.5 initial_t = 1 power_t = 0.5 decay_learning_rate = 1 using cache_file = train_titanic.vw.cache ignoring text input in favor of cache input num sources = 1 average since example example current current current loss last counter weight label predict features 0.000000 0.000000 1 1.0 -1.0000 -1.0000 57 0.500000 1.000000 2 2.0 1.0000 -1.0000 57 0.250000 0.000000 4 4.0 1.0000 1.0000 57 0.375000 0.500000 8 8.0 -1.0000 -1.0000 73 0.625000 0.875000 16 16.0 -1.0000 1.0000 73 0.468750 0.312500 32 32.0 -1.0000 -1.0000 57 0.468750 0.468750 64 64.0 -1.0000 1.0000 43 0.375000 0.281250 128 128.0 1.0000 -1.0000 43 0.351562 0.328125 256 256.0 1.0000 -1.0000 43 0.359375 0.367188 512 512.0 -1.0000 1.0000 57 0.274336 0.274336 1024 1024.0 -1.0000 -1.0000 57 h 0.281938 0.289474 2048 2048.0 -1.0000 -1.0000 43 h 0.246696 0.211454 4096 4096.0 -1.0000 -1.0000 43 h 0.218922 0.191209 8192 8192.0 1.0000 1.0000 43 h finished run number of examples per pass = 802 passes used = 11 weighted example sum = 8822 weighted label sum = -2288 average loss = 0.179775 h best constant = -0.530826 best constant’s loss = 0.659128 total feature number = 427878
现在我们可以使用我们训练的model.vw用新数据生成预测。
vw -d test_titanic.vw -t -i model.vw -p predictions.txt
上一个命令中生成的预测未标准化以适应 [0, 1] 范围。为了做到这一点,我们使用了 sigmoid 变换。
# Read the predictions
preds = fread('vw/predictions.txt')
# Define the sigmoid function
sigmoid = function(x) {
1 / (1 + exp(-x))
}
probs = sigmoid(preds[[1]])
# Generate class labels
preds = ifelse(probs > 0.5, 1, 0)
head(preds)
# [1] 0 1 0 0 1 0
