笔记列表:
- apache storm简介
- apache storm核心概念
- apache storm群集体系结构
- apache storm工作流
- apachestorm分布式消息系统
- apache storm安装
- apache storm工作示例
- 阿帕奇风暴三叉戟
- twitter上的阿帕奇风暴
- 雅虎金融的阿帕奇风暴
- apache storm应用程序
- apache storm快速指南
- apache storm有用资源
- 阿帕奇风暴讨论
- apache tajo简介
- apache tajo体系结构
- apache tajo安装
- apache tajo配置设置
- apache tajo shell命令
- apache tajo数据类型
- apache tajo运算符
- apache tajo sql函数
- apache tajo数学函数
- apache tajo字符串函数
- apache tajo datetime函数
- apache tajo json函数
- apache tajo数据库创建
- apache tajo表管理
- apache tajo sql语句
- apache tajo聚合和窗口函数
- apache tajo sql查询
- apache tajo存储插件
- apache tajo与hbase的集成
- apache tajo与hive的集成
- apache-tajo-openstack-swift集成
- ApacheTajoJDBC接口
- apache tajo自定义函数
- apache tajo快速指南
- apache tajo有用的资源
- apache tajo讨论
Apache Storm-快速指南
Apache Storm-简介
什么是Apache Storm?
Apache Storm是一个分布式实时大数据处理系统。Storm设计为以容错和水平可伸缩方法处理大量数据。它是具有最高摄取率能力的流数据框架。尽管Storm是无状态的,但它通过Apache ZooKeeper管理分布式环境和集群状态。它很简单,您可以并行对实时数据执行各种操作。
Apache Storm继续成为实时数据分析的领导者。Storm易于设置,操作,并且可以确保通过拓扑至少处理一次每条消息。
Apache Storm与Hadoop
基本上,Hadoop和Storm框架用于分析大数据。它们两者相辅相成,并且在某些方面有所不同。Apache Storm会执行除持久性之外的所有操作,而Hadoop在所有方面都擅长,但在实时计算方面比较落后。下表比较了Storm和Hadoop的属性。
| 风暴 | Hadoop的 |
|---|---|
| 实时流处理 | 批量处理 |
| 无状态 | 有状态的 |
| 主/从架构与基于ZooKeeper的协调。主节点称为nimbus,从节点为主管。 | 基于/不基于ZooKeeper的协调的主从架构。主节点是作业跟踪器,从节点是任务跟踪器。 |
| Storm流传输过程每秒可以访问群集上成千上万的消息。 | Hadoop分布式文件系统(HDFS)使用MapReduce框架处理耗时数分钟或数小时的大量数据。 |
| 风暴拓扑将一直运行,直到被用户关闭或意外的不可恢复的故障为止。 | MapReduce作业按顺序执行,并最终完成。 |
| 两者都是分布式的并且容错的 | |
| 如果灵气/主管死了,重新启动会使它从停止的地方继续,因此不会受到影响。 | 如果JobTracker死亡,则所有正在运行的作业都将丢失。 |
Apache Storm的用例
Apache Storm以实时大数据流处理而闻名。因此,大多数公司都将Storm用作其系统的组成部分。一些值得注意的例子如下-
Twitter -Twitter将Apache Storm用于其“ Publisher Analytics产品”范围。“发布商分析产品”处理Twitter平台中的每条推文和单击。Apache Storm已与Twitter基础架构深度集成。
NaviSite -NaviSite正在使用Storm进行事件日志监视/审计系统。系统中生成的每个日志都将通过Storm。Storm将根据配置的正则表达式集检查消息,如果存在匹配项,则该特定消息将保存到数据库中。
Wego -Wego是位于新加坡的旅行元搜索引擎。与旅行相关的数据来自世界各地,时机不同。Storm帮助Wego搜索实时数据,解决并发问题并为最终用户找到最佳匹配。
Apache Storm的好处
这是Apache Storm提供的好处的列表-
-
Storm是开源,强大且用户友好的。它既可以用于小型公司,也可以用于大型公司。
-
Storm是容错的,灵活的,可靠的,并且支持任何编程语言。
-
允许实时流处理。
-
风暴之快令人难以置信,因为它具有处理数据的巨大能力。
-
通过线性添加资源,即使在负载增加的情况下,Storm也可以保持性能。它具有高度的可扩展性。
-
Storm会在几秒钟或几分钟内执行数据刷新和端到端交付响应,具体取决于问题。它具有非常低的延迟。
-
Storm具有运营情报。
-
即使集群中的任何已连接节点死亡或消息丢失,Storm也可提供有保证的数据处理。
Apache Storm-核心概念
Apache Storm从一端读取实时数据的原始流,并将其通过一系列小型处理单元,然后在另一端输出已处理的/有用的信息。
下图描述了Apache Storm的核心概念。
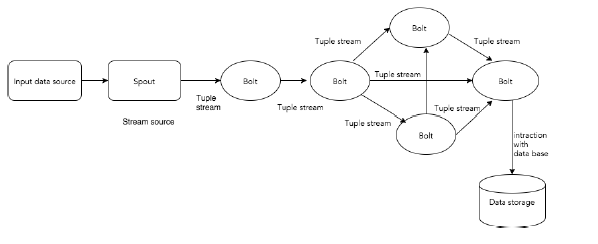
现在让我们仔细看看Apache Storm的组件-
| 组件 | 描述 |
|---|---|
| 元组 | 元组是Storm中的主要数据结构。它是有序元素的列表。默认情况下,元组支持所有数据类型。通常,将其建模为一组用逗号分隔的值,然后传递给Storm集群。 |
| 溪流 | 流是无序的元组序列。 |
| 出水嘴 | 流的来源。通常,Storm从原始数据源(例如Twitter Streaming API,Apache Kafka队列,Kestrel队列等)接受输入数据。否则,您可以编写spout以从数据源读取数据。“ ISpout”是实现喷口的核心接口,其中一些特定的接口是IRichSpout,BaseRichSpout,KafkaSpout等。 |
| 螺栓 | 螺栓是逻辑处理单元。喷口将数据传递到螺栓,然后螺栓过程产生新的输出流。螺栓可以执行过滤,聚合,联接,与数据源和数据库交互的操作。螺栓接收数据并发出一个或多个螺栓。“ IBolt”是用于实现螺栓的核心接口。一些常见的接口是IRichBolt,IBasicBolt等。 |
让我们以“ Twitter分析”的实时示例为例,看看如何在Apache Storm中对其进行建模。下图描述了该结构。
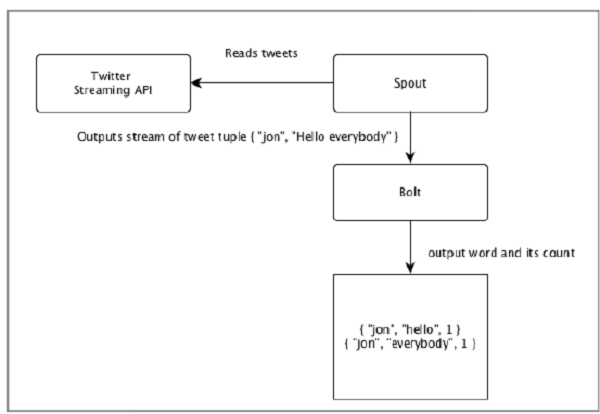
“ Twitter分析”的输入来自Twitter Streaming API。Spout将使用Twitter Streaming API阅读用户的推文,并以元组流的形式输出。喷口中的一个元组将具有一个Twitter用户名和一个以逗号分隔值的鸣叫。然后,该元组流将被转发到Bolt,而Bolt将把tweet拆分为单个单词,计算单词计数,并将信息保留到配置的数据源中。现在,我们可以通过查询数据源轻松获得结果。
拓扑结构
喷嘴和螺栓连接在一起,形成一个拓扑。实时应用程序逻辑是在Storm拓扑中指定的。简而言之,拓扑是有向图,其中顶点是计算,边是数据流。
一个简单的拓扑结构从喷口开始。喷口将数据发射到一个或多个螺栓。螺栓表示拓扑中具有最小处理逻辑的节点,螺栓的输出可以作为输入发射到另一个螺栓中。
Storm会使拓扑始终运行,直到您杀死拓扑为止。Apache Storm的主要工作是运行拓扑,并将在给定的时间运行任意数量的拓扑。
任务
现在,您对喷口和螺栓有了基本的了解。它们是拓扑的最小逻辑单元,并且拓扑是使用单个喷口和螺栓阵列构建的。应该以特定顺序正确执行它们,以使拓扑成功运行。Storm将每个喷口和螺栓的执行称为“任务”。简而言之,一项任务是执行喷口或螺栓。在给定的时间,每个喷嘴和螺栓可以在多个单独的线程中运行多个实例。
工人
拓扑以分布式方式在多个工作程序节点上运行。Storm将任务平均分布在所有工作节点上。工作节点的作用是侦听作业,并在新作业到达时启动或停止进程。
流分组
数据流从喷嘴流向螺栓,或从一个螺栓流向另一螺栓。流分组控制元组在拓扑中的路由方式,并帮助我们了解元组在拓扑中的流动。有四个内置分组,如下所述。
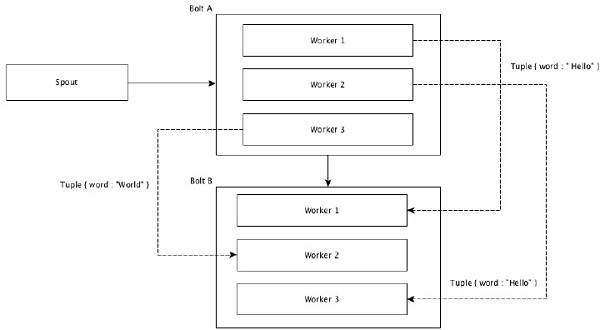
随机分组
在随机分组中,相等数量的元组在执行螺栓的所有工作人员中随机分布。下图描述了该结构。
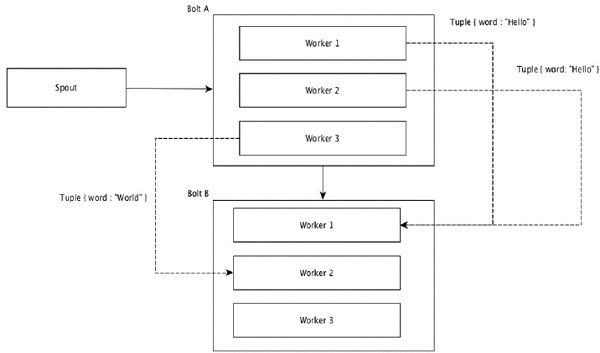
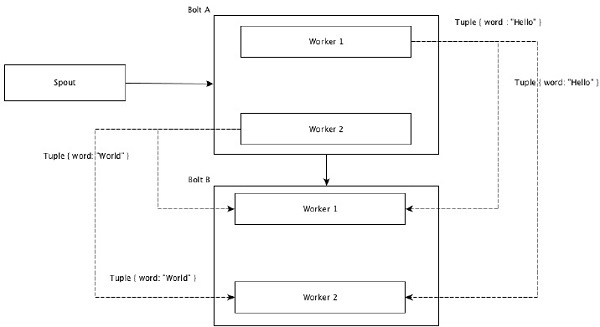
现场分组
元组中具有相同值的字段被分组在一起,其余元组保留在外部。然后,具有相同字段值的元组被发送到执行螺栓的同一工人。例如,如果流按字段“ word”分组,则具有相同字符串“ Hello”的元组将移至同一工作程序。下图显示了字段分组的工作方式。
全球分组
所有流都可以分组并转发到一个螺栓。此分组将由源的所有实例生成的元组发送到单个目标实例(特别是选择ID最低的工作程序)。
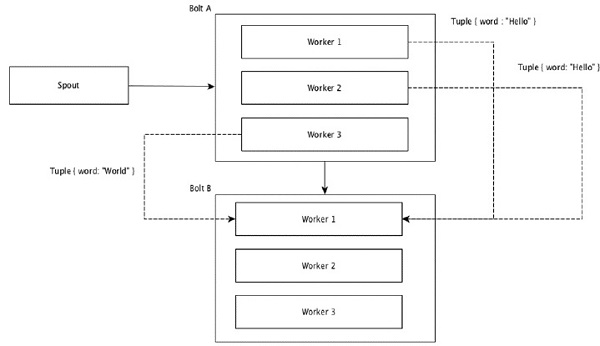
所有分组
所有分组将每个元组的单个副本发送到接收螺栓的所有实例。这种分组用于将信号发送到螺栓。所有分组对于联接操作都是有用的。
Apache Storm-集群体系结构
Apache Storm的主要亮点之一是它是一种容错的,快速的,没有“单一故障点”(SPOF)分布式应用程序的应用程序。我们可以根据需要在许多系统中安装Apache Storm,以增加应用程序的容量。
让我们看一下Apache Storm集群的设计方式及其内部架构。下图描述了集群设计。
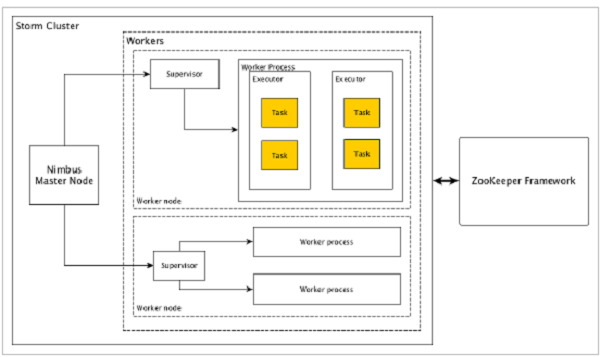
Apache Storm具有两种类型的节点,即Nimbus(主节点)和Supervisor(工作节点)。Nimbus是Apache Storm的核心组件。Nimbus的主要工作是运行Storm拓扑。Nimbus分析拓扑并收集要执行的任务。然后,它将任务分配给可用的主管。
主管将具有一个或多个工作程序。主管将任务委托给工人流程。工作进程将根据需要生成任意数量的执行程序并运行任务。Apache Storm使用内部分布式消息传递系统在灵气与主管之间进行通信。
| 组件 | 描述 |
|---|---|
| 雨云 | Nimbus是Storm集群的主节点。群集中的所有其他节点称为工作节点。主节点负责在所有工作节点之间分配数据,将任务分配给工作节点并监视故障。 |
| 导师 | 遵循nimbus给出的指令的节点称为Supervisor。一个主管有多个工作进程和它管理工作进程,完成由灵气交给的任务。 |
| 工人过程 | 工作进程将执行与特定拓扑相关的任务。工作进程不会单独运行任务,而是创建执行程序并要求他们执行特定任务。一个工作进程将有多个执行程序。 |
| 执行者 | 执行者不过是工作进程产生的单个线程。执行者可以执行一个或多个任务,但只能执行特定的喷嘴或螺栓。 |
| 任务 | 任务执行实际的数据处理。因此,它既可以是喷嘴,也可以是螺栓。 |
| ZooKeeper框架 |
Apache ZooKeeper是集群(节点组)使用的一项服务,以在它们之间进行协调并使用可靠的同步技术维护共享数据。Nimbus是无状态的,因此它取决于ZooKeeper来监视工作节点状态。 ZooKeeper帮助主管与灵气互动。负责维护灵气和主管的状态。 |
风暴本质上是无状态的。即使无状态性质也有其自身的缺点,它实际上可以帮助Storm以最快,最好的方式处理实时数据。
风暴并不是完全没有状态的。它将状态存储在Apache ZooKeeper中。由于该状态在Apache ZooKeeper中可用,因此发生故障的雨云总线可以重新启动并从其离开的地方开始工作。通常,服务监视工具(如monit)将监视Nimbus,并在出现任何故障时重新启动它。
Apache Storm还具有一种称为Trident Topology的高级拓扑,具有状态维护功能,并且还提供了如Pig这样的高级API。我们将在接下来的章节中讨论所有这些功能。
Apache Storm-工作流程
正常工作的Storm集群应具有一个灵气和一个或多个主管。另一个重要的节点是Apache ZooKeeper,它将用于在灵气和主管之间进行协调。
现在让我们仔细看看Apache Storm的工作流程-
-
最初,灵气将等待“风暴拓扑”被提交给它。
-
提交拓扑后,它将处理拓扑并收集所有要执行的任务以及任务执行的顺序。
-
然后,灵气将把任务平均分配给所有可用的主管。
-
在特定的时间间隔内,所有主管都将向心律图发送心跳,以告知他们仍然活着。
-
当主管死亡时,没有向心电图发送心跳,则云雨水会将任务分配给另一位主管。
-
当灵气本身死亡时,主管将完成已经分配的任务,而不会出现任何问题。
-
一旦完成所有任务,主管将等待新任务进入。
-
同时,失效的灵气将通过服务监控工具自动重启。
-
重新启动的雨云将从停止的地方继续。同样,失效的主管也可以自动重新启动。由于灵气和主管都可以自动重新启动,并且它们都将像以前一样继续运行,因此可以确保Storm至少处理一次所有任务。
-
一旦处理完所有拓扑,灵气就等待新的拓扑到达,类似地,主管也等待新的任务。
默认情况下,Storm群集中有两种模式-
-
本地模式-此模式用于开发,测试和调试,因为它是查看所有拓扑组件一起工作的最简单方法。在这种模式下,我们可以调整参数,使我们能够查看拓扑如何在不同的Storm配置环境中运行。在本地模式下,风暴拓扑在单个JVM中的本地计算机上运行。
-
生产模式-在这种模式下,我们将拓扑提交到工作风暴集群,该集群由许多进程组成,通常在不同的计算机上运行。正如Storm的工作流程中所讨论的,工作群集将无限期运行,直到关闭为止。
风暴-分布式消息系统
Apache Storm处理实时数据,输入通常来自消息队列系统。外部分布式消息传递系统将提供实时计算所需的输入。Spout将从消息系统中读取数据,并将其转换为元组,然后输入到Apache Storm中。有趣的事实是,Apache Storm在内部使用其自己的分布式消息传递系统进行其灵气与主管之间的通信。
什么是分布式消息传递系统?
分布式消息传递基于可靠消息队列的概念。消息在客户端应用程序和消息传递系统之间异步排队。分布式消息传递系统具有可靠性,可伸缩性和持久性的优点。
大多数消息传递模式遵循发布-订阅模型(简称为Pub-Sub),其中消息的发件人称为发布者,而想要接收消息的人称为订阅者。
一旦发件人发布了邮件,订户就可以在过滤选项的帮助下接收选定的邮件。通常,我们有两种类型的过滤,一种是基于主题的过滤,另一种是基于内容的过滤。
请注意,pub-sub模型只能通过消息进行通信。它是一个非常松散耦合的体系结构。即使发件人也不知道他们的订户是谁。许多消息模式使消息代理可以交换发布消息以供许多订户及时访问。一个真实的例子是Dish TV,它发布了体育,电影,音乐等不同的频道,任何人都可以订阅自己的频道集,并在订阅频道可用时获取它们。
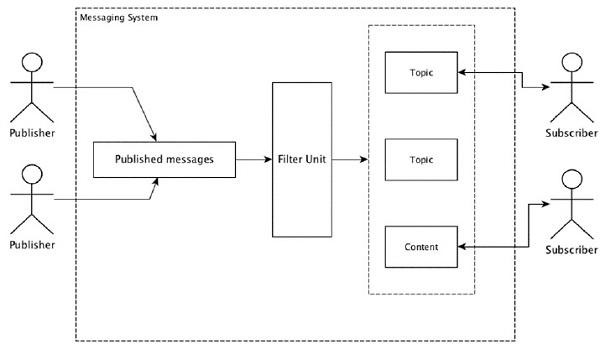
下表描述了一些流行的高吞吐量消息传递系统-
| 分布式消息传递系统 | 描述 |
|---|---|
| 阿帕奇·卡夫卡(Apache Kafka) | Kafka是在LinkedIn公司开发的,后来成为Apache的子项目。Apache Kafka基于启用代理的持久性分布式发布-订阅模型。Kafka快速,可扩展且高效。 |
| 兔子MQ | RabbitMQ是一个开源的分布式健壮消息传递应用程序。它易于使用,并且可以在所有平台上运行。 |
| JMS(Java消息服务) | JMS是一种开源API,它支持创建,读取消息以及将消息从一个应用程序发送到另一个应用程序。它提供有保证的消息传递,并遵循发布-订阅模型。 |
| ActiveMQ | ActiveMQ消息传递系统是JMS的开源API。 |
| 零MQ | ZeroMQ是无代理对等消息处理。它提供推拉,路由器经销商消息模式。 |
| 红est | Kestrel是一种快速,可靠且简单的分布式消息队列。 |
节俭协议
Thrift是在Facebook上构建的,用于跨语言服务开发和远程过程调用(RPC)。后来,它成为一个开源的Apache项目。Apache Thrift是一种界面定义语言,可以轻松地在定义的数据类型之上定义新的数据类型和服务实现。
Apache Thrift还是一个通信框架,它支持嵌入式系统,移动应用程序,Web应用程序和许多其他编程语言。与Apache Thrift相关的一些关键功能是其模块化,灵活性和高性能。此外,它可以在分布式应用程序中执行流式传输,消息传递和RPC。
Storm广泛使用Thrift协议进行内部通信和数据定义。风暴拓扑只是节流结构。在Apache Storm中运行拓扑的Storm Nimbus是Thrift服务。
Apache Storm-安装
现在让我们看看如何在您的计算机上安装Apache Storm框架。这里有三个majo步骤-
- 如果尚未安装Java,请在系统上安装它。
- 安装ZooKeeper框架。
- 安装Apache Storm框架。
步骤1-验证Java安装
使用以下命令检查系统上是否已安装Java。
$ java -version
如果Java已经存在,那么您将看到其版本号。否则,下载最新版本的JDK。
步骤1.1-下载JDK
使用以下链接下载最新版本的JDK-www.oracle.com
最新版本是JDK 8u 60,文件是“ jdk-8u60-linux-x64.tar.gz”。将文件下载到您的计算机上。
步骤1.2-提取文件
通常,文件正在下载到downloads文件夹中。使用以下命令解压缩tar设置。
$ cd /go/to/download/path $ tar -zxf jdk-8u60-linux-x64.gz
步骤1.3-移至opt目录
要使Java对所有用户可用,请将提取的Java内容移至“ / usr / local / java”文件夹。
$ su password: (type password of root user) $ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/
步骤1.4-设置路径
要设置路径和JAVA_HOME变量,请将以下命令添加到〜/ .bashrc文件。
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60 export PATH=$PATH:$JAVA_HOME/bin
现在,将所有更改应用于当前正在运行的系统。
$ source ~/.bashrc
步骤1.5-Java替代品
使用以下命令来更改Java替代方案。
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
步骤1.6
现在,使用步骤1中介绍的验证命令(java -version)验证Java安装。
第2步-ZooKeeper框架安装
步骤2.1-下载ZooKeeper
要在您的计算机上安装ZooKeeper框架,请访问以下链接并下载最新版本的ZooKeeper http://zookeeper.apache.org/releases.html
到目前为止,ZooKeeper的最新版本是3.4.6(ZooKeeper-3.4.6.tar.gz)。
步骤2.2-提取tar文件
使用以下命令解压缩tar文件-
$ cd opt/ $ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6 $ mkdir data
步骤2.3-创建配置文件
使用命令“ vi conf / zoo.cfg”打开名为“ conf / zoo.cfg”的配置文件,并将以下所有参数设置为起点。
$ vi conf/zoo.cfg tickTime=2000 dataDir=/path/to/zookeeper/data clientPort=2181 initLimit=5 syncLimit=2
配置文件成功保存后,即可启动ZooKeeper服务器。
步骤2.4-启动ZooKeeper服务器
使用以下命令启动ZooKeeper服务器。
$ bin/zkServer.sh start
执行此命令后,您将获得如下响应:
$ JMX enabled by default $ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED
步骤2.5-启动CLI
使用以下命令启动CLI。
$ bin/zkCli.sh
执行完上述命令后,您将连接到ZooKeeper服务器并获得以下响应。
Connecting to localhost:2181 ................ ................ ................ Welcome to ZooKeeper! ................ ................ WATCHER:: WatchedEvent state:SyncConnected type: None path:null [zk: localhost:2181(CONNECTED) 0]
步骤2.6-停止ZooKeeper服务器
连接服务器并执行所有操作后,可以使用以下命令停止ZooKeeper服务器。
bin/zkServer.sh stop
您已经在计算机上成功安装了Java和ZooKeeper。现在让我们看看安装Apache Storm框架的步骤。
第3步-Apache Storm Framework安装
步骤3.1下载风暴
要在您的计算机上安装Storm框架,请访问以下链接并下载Storm的最新版本http://storm.apache.org/downloads.html
到目前为止,Storm的最新版本是“ apache-storm-0.9.5.tar.gz”。
步骤3.2-提取tar文件
使用以下命令解压缩tar文件-
$ cd opt/ $ tar -zxf apache-storm-0.9.5.tar.gz $ cd apache-storm-0.9.5 $ mkdir data
步骤3.3-打开配置文件
当前版本的Storm包含位于“ conf / storm.yaml”的文件,该文件用于配置Storm守护程序。将以下信息添加到该文件。
$ vi conf/storm.yaml storm.zookeeper.servers: - "localhost" storm.local.dir: “/path/to/storm/data(any path)” nimbus.host: "localhost" supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
应用所有更改后,保存并返回到终端。
步骤3.4-启动Nimbus
$ bin/storm nimbus
步骤3.5-启动主管
$ bin/storm supervisor
步骤3.6启动UI
$ bin/storm ui
启动Storm用户界面应用程序后,在您喜欢的浏览器中输入URL http:// localhost:8080,您将看到Storm集群信息及其运行的拓扑。该页面应类似于以下屏幕截图。
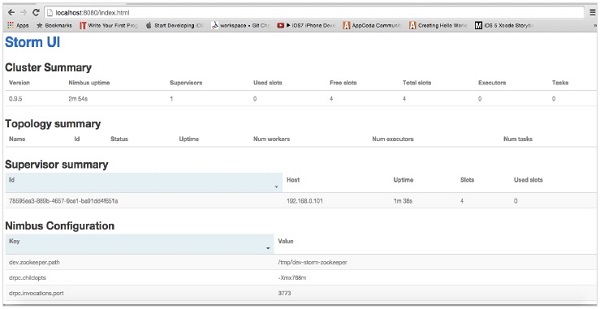
Apache Storm-工作示例
我们已经了解了Apache Storm的核心技术细节,现在是时候编写一些简单的场景了。
方案–移动呼叫日志分析器
移动呼叫及其持续时间将作为Apache Storm的输入,Storm将处理和分组同一呼叫者和接收者之间的呼叫及其总呼叫数。
壶嘴创作
Spout是用于数据生成的组件。基本上,喷口将实现IRichSpout接口。“ IRichSpout”界面具有以下重要方法-
-
开放式-为壶嘴提供执行环境。执行者将运行此方法来初始化喷口。
-
nextTuple-通过收集器发出生成的数据。
-
关闭-当口会关机时调用此方法。
-
clarifyOutputFields-声明元组的输出模式。
-
ack-确认已处理特定的元组
-
fail-指定特定元组不被处理并且不被重新处理。
打开
打开方法的签名如下-
open(Map conf, TopologyContext context, SpoutOutputCollector collector)
-
conf-为该喷嘴提供风暴配置。
-
context-提供有关拓扑中喷口位置,其任务ID,输入和输出信息的完整信息。
-
collector-使我们能够发出将由螺栓处理的元组。
nextTuple
nextTuple方法的签名如下-
nextTuple()
从与ack()和fail()方法相同的循环中定期调用nextTuple()。当没有工作要做时,它必须释放对线程的控制,以便其他方法有机会被调用。因此,nextTuple的第一行将检查处理是否完成。如果是这样,它应至少休眠一毫秒以减少返回之前的处理器负载。
关闭
close方法的签名如下-
close()
声明输出字段
clarifyOutputFields方法的签名如下-
declareOutputFields(OutputFieldsDeclarer declarer)
声明器-用于声明输出流ID,输出字段等。
此方法用于指定元组的输出模式。
确认
ack方法的签名如下-
ack(Object msgId)
此方法确认已处理特定的元组。
失败
nextTuple方法的签名如下-
ack(Object msgId)
此方法通知特定的元组尚未完全处理。Storm将重新处理特定的元组。
FakeCallLogReaderSpout
在我们的方案中,我们需要收集呼叫日志的详细信息。呼叫日志的信息包含在内。
- 来电者号码
- 接收方编号
- 期间
由于我们没有通话记录的实时信息,因此我们将生成伪造的通话记录。伪造的信息将使用Random类创建。完整的程序代码如下。
编码-FakeCallLogReaderSpout.java
import java.util.*; //import storm tuple packages import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; //import Spout interface packages import backtype.storm.topology.IRichSpout; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; //Create a class FakeLogReaderSpout which implement IRichSpout interface to access functionalities public class FakeCallLogReaderSpout implements IRichSpout { //Create instance for SpoutOutputCollector which passes tuples to bolt. private SpoutOutputCollector collector; private boolean completed = false; //Create instance for TopologyContext which contains topology data. private TopologyContext context; //Create instance for Random class. private Random randomGenerator = new Random(); private Integer idx = 0; @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.context = context; this.collector = collector; } @Override public void nextTuple() { if(this.idx <= 1000) { List<String> mobileNumbers = new ArrayList<String>(); mobileNumbers.add("1234123401"); mobileNumbers.add("1234123402"); mobileNumbers.add("1234123403"); mobileNumbers.add("1234123404"); Integer localIdx = 0; while(localIdx++ < 100 && this.idx++ < 1000) { String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4)); String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4)); while(fromMobileNumber == toMobileNumber) { toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4)); } Integer duration = randomGenerator.nextInt(60); this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration)); } } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("from", "to", "duration")); } //Override all the interface methods @Override public void close() {} public boolean isDistributed() { return false; } @Override public void activate() {} @Override public void deactivate() {} @Override public void ack(Object msgId) {} @Override public void fail(Object msgId) {} @Override public Map<String, Object> getComponentConfiguration() { return null; } }
螺栓创建
Bolt是一个将元组作为输入,处理该元组并生成新的元组作为输出的组件。螺栓将实现IRichBolt接口。在此程序中,两个螺栓类CallLogCreatorBolt和CallLogCounterBolt用于执行操作。
IRichBolt接口具有以下方法-
-
准备-为螺栓提供执行环境。执行者将运行此方法来初始化喷口。
-
执行-处理单个输入元组。
-
cleanup-螺栓即将关闭时调用。
-
clarifyOutputFields-声明元组的输出模式。
准备
准备方法的签名如下-
prepare(Map conf, TopologyContext context, OutputCollector collector)
-
conf-为该螺栓提供Storm配置。
-
上下文-提供有关拓扑中螺栓位置,其任务ID,输入和输出信息等的完整信息。
-
collector-使我们能够发出已处理的元组。
执行
execute方法的签名如下-
execute(Tuple tuple)
这里的元组是要处理的输入元组。
所述执行方法处理在一个时间的单个元组。元组数据可以通过Tuple类的getValue方法访问。不必立即处理输入元组。可以处理多个元组并将其作为单个输出元组输出。可以使用OutputCollector类来发出已处理的元组。
清理
清除方法的签名如下-
cleanup()
声明输出字段
clarifyOutputFields方法的签名如下-
declareOutputFields(OutputFieldsDeclarer declarer)
在这里,参数声明器用于声明输出流ID,输出字段等。
此方法用于指定元组的输出模式
通话记录创建者螺栓
呼叫日志创建者螺栓接收呼叫日志元组。呼叫日志元组具有呼叫者号码,接收者号码和呼叫持续时间。该螺栓简单地通过组合呼叫者号码和接收者号码来创建新值。新值的格式为“主叫方号码-接收方号码”,并将其命名为新字段“ call”。完整的代码如下。
编码-CallLogCreatorBolt.java
//import util packages import java.util.HashMap; import java.util.Map; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; //import Storm IRichBolt package import backtype.storm.topology.IRichBolt; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.tuple.Tuple; //Create a class CallLogCreatorBolt which implement IRichBolt interface public class CallLogCreatorBolt implements IRichBolt { //Create instance for OutputCollector which collects and emits tuples to produce output private OutputCollector collector; @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { this.collector = collector; } @Override public void execute(Tuple tuple) { String from = tuple.getString(0); String to = tuple.getString(1); Integer duration = tuple.getInteger(2); collector.emit(new Values(from + " - " + to, duration)); } @Override public void cleanup() {} @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("call", "duration")); } @Override public Map<String, Object> getComponentConfiguration() { return null; } }
通话记录计数器螺栓
呼叫日志计数器螺栓以元组形式接收呼叫及其持续时间。此螺栓在prepare方法中初始化字典(地图)对象。在execute方法中,它检查元组,并为元组中的每个新“调用”值在字典对象中创建一个新条目,并在字典对象中将值设置为1。对于字典中已经可用的条目,它只是增加其值。简单来说,此螺栓将调用及其计数保存在字典对象中。除了将调用及其计数保存在字典中之外,我们还可以将其保存到数据源中。完整的程序代码如下-
编码-CallLogCounterBolt.java
import java.util.HashMap; import java.util.Map; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.IRichBolt; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.tuple.Tuple; public class CallLogCounterBolt implements IRichBolt { Map<String, Integer> counterMap; private OutputCollector collector; @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { this.counterMap = new HashMap<String, Integer>(); this.collector = collector; } @Override public void execute(Tuple tuple) { String call = tuple.getString(0); Integer duration = tuple.getInteger(1); if(!counterMap.containsKey(call)){ counterMap.put(call, 1); }else{ Integer c = counterMap.get(call) + 1; counterMap.put(call, c); } collector.ack(tuple); } @Override public void cleanup() { for(Map.Entry<String, Integer> entry:counterMap.entrySet()){ System.out.println(entry.getKey()+" : " + entry.getValue()); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("call")); } @Override public Map<String, Object> getComponentConfiguration() { return null; } }
创建拓扑
Storm拓扑基本上是Thrift结构。TopologyBuilder类提供了创建复杂拓扑的简单方法。TopologyBuilder类具有设置喷口(setSpout)和设置螺栓(setBolt)的方法。最后,TopologyBuilder具有createTopology来创建拓扑。使用以下代码片段创建拓扑-
TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout()); builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt()) .shuffleGrouping("call-log-reader-spout"); builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt()) .fieldsGrouping("call-log-creator-bolt", new Fields("call"));
shuffleGrouping和fieldsGrouping方法有助于为喷口和螺栓设置流分组。
本地集群
出于开发目的,我们可以使用“ LocalCluster”对象创建本地集群,然后使用“ LocalCluster”类的“ submitTopology”方法提交拓扑。“ submitTopology”的参数之一是“ Config”类的实例。“ Config”类用于在提交拓扑之前设置配置选项。此配置选项将在运行时与集群配置合并,并通过prepare方法发送到所有任务(喷嘴和螺栓)。将拓扑提交到集群后,我们将等待10秒钟,等待集群计算提交的拓扑,然后使用“ LocalCluster”的“ shutdown”方法关闭集群。完整的程序代码如下-
编码-LogAnalyserStorm.java
import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; //import storm configuration packages import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; //Create main class LogAnalyserStorm submit topology. public class LogAnalyserStorm { public static void main(String[] args) throws Exception{ //Create Config instance for cluster configuration Config config = new Config(); config.setDebug(true); // TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout()); builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt()) .shuffleGrouping("call-log-reader-spout"); builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt()) .fieldsGrouping("call-log-creator-bolt", new Fields("call")); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology()); Thread.sleep(10000); //Stop the topology cluster.shutdown(); } }
生成和运行应用程序
完整的应用程序具有四个Java代码。他们是-
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
可以使用以下命令构建应用程序-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.java
可以使用以下命令运行该应用程序-
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStorm
输出
一旦启动该应用程序,它将输出有关集群启动过程,喷口和螺栓处理以及最后集群关闭过程的完整详细信息。在“ CallLogCounterBolt”中,我们已打印呼叫及其计数详细信息。此信息将在控制台上显示,如下所示:
1234123402 - 1234123401 : 78 1234123402 - 1234123404 : 88 1234123402 - 1234123403 : 105 1234123401 - 1234123404 : 74 1234123401 - 1234123403 : 81 1234123401 - 1234123402 : 81 1234123403 - 1234123404 : 86 1234123404 - 1234123401 : 63 1234123404 - 1234123402 : 82 1234123403 - 1234123402 : 83 1234123404 - 1234123403 : 86 1234123403 - 1234123401 : 93
非JVM语言
Storm拓扑由Thrift接口实现,可轻松以任何语言提交拓扑。Storm支持Ruby,Python和许多其他语言。让我们看一下python绑定。
Python绑定
Python是一种通用的解释型,交互式,面向对象的高级编程语言。Storm支持Python来实现其拓扑。Python支持发射,锚定,确认和记录操作。
如您所知,可以用任何语言定义螺栓。用另一种语言编写的螺栓被作为子流程执行,Storm通过stdin / stdout上的JSON消息与这些子流程进行通信。首先获取一个支持python绑定的示例螺栓WordCount。
public static class WordCount implements IRichBolt { public WordSplit() { super("python", "splitword.py"); } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } }
在这里,WordCount类实现了IRichBolt接口,并使用指定的超级方法参数“ splitword.py”的python实现运行。现在创建一个名为“ splitword.py”的python实现。
import storm class WordCountBolt(storm.BasicBolt): def process(self, tup): words = tup.values[0].split(" ") for word in words: storm.emit([word]) WordCountBolt().run()
这是Python的示例实现,它对给定句子中的单词进行计数。同样,您也可以绑定其他支持语言。
Apache Storm-三叉戟
三叉戟是Storm的扩展。像暴风雨一样,Trident也由Twitter开发。开发Trident的主要原因是在Storm之上提供高级抽象以及状态流处理和低延迟分布式查询。
Trident使用喷口和螺栓,但是这些低级组件在执行之前由Trident自动生成。Trident具有功能,过滤器,联接,分组和聚合。
Trident将流作为一系列批处理(称为事务)进行处理。通常,这些小批量的大小将在数千或数百万个元组的数量级上,具体取决于输入流。这样,Trident与Storm不同,后者执行逐个元组处理。
批处理概念与数据库事务非常相似。每个交易都分配有交易ID。一旦完成所有处理,该事务即被视为成功。但是,处理事务元组之一失败将导致重新传输整个事务。对于每个批次,Trident将在事务开始时调用beginCommit,并在事务结束时提交。
三叉戟拓扑
Trident API提供了一个简单的选项,可使用“ TridentTopology”类创建Trident拓扑。基本上,Trident拓扑从spout接收输入流,并对流执行有序的操作顺序(过滤,聚合,分组等)。“三叉戟元组”替换了“风暴元组”,而“操作”替换了“螺栓”。可以创建一个简单的Trident拓扑,如下所示-
TridentTopology topology = new TridentTopology();
三叉戟元组
三叉戟元组是值的命名列表。TridentTuple接口是Trident拓扑的数据模型。TridentTuple接口是Trident拓扑可以处理的基本数据单元。
三叉戟喷口
Trident喷口与Storm喷口相似,具有使用Trident功能的其他选项。实际上,我们仍然可以使用在Storm拓扑中使用的IRichSpout,但是它本质上是非事务性的,我们将无法使用Trident提供的优势。
具有使用Trident功能的所有功能的基本喷嘴是“ ITridentSpout”。它支持事务性和不透明的事务性语义。其他喷嘴是IBatchSpout,IPartitionedTridentSpout和IOpaquePartitionedTridentSpout。
除了这些通用的喷嘴外,Trident还提供了许多Trident喷嘴的示例实现。其中之一是FeederBatchSpout喷口,我们可以使用它轻松地发送三叉戟元组的命名列表,而不必担心批处理,并行性等。
FeederBatchSpout的创建和数据馈送可以如下所示进行:
TridentTopology topology = new TridentTopology(); FeederBatchSpout testSpout = new FeederBatchSpout( ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”)); topology.newStream("fixed-batch-spout", testSpout) testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));
三叉戟行动
Trident依靠“ Trident操作”来处理三叉戟元组的输入流。Trident API具有许多内置操作来处理从简单到复杂的流处理。这些操作的范围从简单的验证到三叉戟元组的复杂分组和聚合。让我们经历最重要和最常用的操作。
筛选
筛选器是用于执行输入验证任务的对象。Trident过滤器获取三叉戟元组字段的子集作为输入,并根据是否满足某些条件来返回true或false。如果返回true,则将元组保留在输出流中;否则,将保留元组。否则,将元组从流中删除。Filter基本上将从BaseFilter类继承,并实现isKeep方法。这是过滤器操作的示例实现-
public class MyFilter extends BaseFilter { public boolean isKeep(TridentTuple tuple) { return tuple.getInteger(1) % 2 == 0; } } input [1, 2] [1, 3] [1, 4] output [1, 2] [1, 4]
可以使用“每种”方法在拓扑中调用过滤器功能。“字段”类可用于指定输入(三叉戟元组的子集)。示例代码如下-
TridentTopology topology = new TridentTopology(); topology.newStream("spout", spout) .each(new Fields("a", "b"), new MyFilter())
功能
函数是用于对单个三叉戟元组执行简单操作的对象。它接受三叉戟元组字段的子集,并发出零个或多个新的三叉戟元组字段。
函数基本上继承自BaseFunction类,并实现execute方法。下面给出了一个示例实现-
public class MyFunction extends BaseFunction { public void execute(TridentTuple tuple, TridentCollector collector) { int a = tuple.getInteger(0); int b = tuple.getInteger(1); collector.emit(new Values(a + b)); } } input [1, 2] [1, 3] [1, 4] output [1, 2, 3] [1, 3, 4] [1, 4, 5]
就像过滤器操作一样,可以使用每种方法在拓扑中调用函数操作。示例代码如下-
TridentTopology topology = new TridentTopology(); topology.newStream("spout", spout) .each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));
聚合
聚合是用于对输入批处理或分区或流执行聚合操作的对象。三叉戟有三种类型的聚合。它们如下-
-
聚合-孤立地聚合每批三叉戟元组。在聚合过程中,最初使用全局分组对元组进行重新分区,以将同一批的所有分区合并为一个分区。
-
partitionAggregate-聚集每个分区,而不是整批三叉戟元组。分区聚合的输出完全替换了输入元组。分区聚合的输出包含单个字段元组。
-
persistentaggregate-在所有批处理中的所有三叉戟元组上进行聚合,并将结果存储在内存或数据库中。
TridentTopology topology = new TridentTopology(); // aggregate operation topology.newStream("spout", spout) .each(new Fields(“a, b"), new MyFunction(), new Fields(“d”)) .aggregate(new Count(), new Fields(“count”)) // partitionAggregate operation topology.newStream("spout", spout) .each(new Fields(“a, b"), new MyFunction(), new Fields(“d”)) .partitionAggregate(new Count(), new Fields(“count")) // persistentAggregate - saving the count to memory topology.newStream("spout", spout) .each(new Fields(“a, b"), new MyFunction(), new Fields(“d”)) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
可以使用CombinerAggregator,ReducerAggregator或通用Aggregator接口创建聚合操作。上例中使用的“计数”聚合器是内置聚合器之一,它是使用“ CombinerAggregator”实现的,实现如下-
public class Count implements CombinerAggregator<Long> { @Override public Long init(TridentTuple tuple) { return 1L; } @Override public Long combine(Long val1, Long val2) { return val1 + val2; } @Override public Long zero() { return 0L; } }
分组
分组操作是一种内置操作,可以通过groupBy方法调用。groupBy方法通过对指定字段执行partitionBy来对流进行重新分区,然后在每个分区内,将组字段相等的元组分组在一起。通常,我们将“ groupBy”与“ persistentAggregate”一起使用以获取分组的聚合。示例代码如下-
TridentTopology topology = new TridentTopology(); // persistentAggregate - saving the count to memory topology.newStream("spout", spout) .each(new Fields(“a, b"), new MyFunction(), new Fields(“d”)) .groupBy(new Fields(“d”) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
合并与加入
合并和合并可以分别使用“合并”和“合并”方法来完成。合并合并一个或多个流。联接与合并类似,不同之处在于联接从两侧使用三叉戟元组字段来检查和联接两个流。此外,加入只能在批处理级别下进行。示例代码如下-
TridentTopology topology = new TridentTopology(); topology.merge(stream1, stream2, stream3); topology.join(stream1, new Fields("key"), stream2, new Fields("x"), new Fields("key", "a", "b", "c"));
国家维护
Trident提供了一种状态维护机制。状态信息可以存储在拓扑本身中,否则,您也可以将其存储在单独的数据库中。原因是保持一种状态,如果在处理过程中任何元组失败,那么将重试失败的元组。这在更新状态时会产生问题,因为您不确定此元组的状态是否之前已更新。如果元组在更新状态之前失败,则重试该元组将使状态稳定。但是,如果元组在更新状态后失败,则重试相同的元组将再次增加数据库中的计数,并使状态不稳定。一个人需要执行以下步骤,以确保仅处理一次消息-
-
分批处理元组。
-
为每个批次分配一个唯一的ID。如果重试该批次,则会为其赋予相同的唯一ID。
-
状态更新按批次排序。例如,在完成第一批的状态更新之前,将无法进行第二批的状态更新。
分布式RPC
分布式RPC用于从Trident拓扑查询和检索结果。Storm具有内置的分布式RPC服务器。分布式RPC服务器从客户端接收RPC请求,并将其传递到拓扑。拓扑处理请求,并将结果发送到分布式RPC服务器,分布式RPC服务器将其重定向到客户端。Trident的分布式RPC查询的执行方式与普通RPC查询类似,不同之处在于这些查询是并行运行的。
什么时候使用三叉戟?
与许多用例一样,如果要求只处理一次查询,则可以通过在Trident中编写拓扑来实现。另一方面,在Storm的情况下,很难一次完成精确的处理。因此,对于那些只需要一次处理的用例,Trident将非常有用。Trident并非适用于所有用例,尤其是高性能用例,因为它增加了Storm的复杂性并管理状态。
三叉戟的工作实例
我们将把上一节中研究的呼叫日志分析器应用程序转换为Trident框架。与普通风暴相比,Trident应用程序将相对容易,这要归功于它的高级API。基本上,将需要Storm来执行Trident中的Function,Filter,Aggregate,GroupBy,Join和Merge操作中的任何一项。最后,我们将使用LocalDRPC类启动DRPC服务器,并使用LocalDRPC类的execute方法搜索一些关键字。
格式化通话信息
FormatCall类的目的是格式化包含“主叫方号码”和“接收方号码”的呼叫信息。完整的程序代码如下-
编码:FormatCall.java
import backtype.storm.tuple.Values; import storm.trident.operation.BaseFunction; import storm.trident.operation.TridentCollector; import storm.trident.tuple.TridentTuple; public class FormatCall extends BaseFunction { @Override public void execute(TridentTuple tuple, TridentCollector collector) { String fromMobileNumber = tuple.getString(0); String toMobileNumber = tuple.getString(1); collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber)); } }
CSV分割
CSVSplit类的目的是基于“逗号(,)”分割输入字符串,并发出字符串中的每个单词。此函数用于解析分布式查询的输入参数。完整的代码如下-
编码:CSVSplit.java
import backtype.storm.tuple.Values; import storm.trident.operation.BaseFunction; import storm.trident.operation.TridentCollector; import storm.trident.tuple.TridentTuple; public class CSVSplit extends BaseFunction { @Override public void execute(TridentTuple tuple, TridentCollector collector) { for(String word: tuple.getString(0).split(",")) { if(word.length() > 0) { collector.emit(new Values(word)); } } } }
日志分析器
这是主要的应用程序。最初,应用程序将使用FeederBatchSpout初始化TridentTopology和feed调用者信息。可以使用TridentTopology类的newStream方法创建Trident拓扑流。同样,可以使用TridentTopology类的newDRCPStream方法创建Trident拓扑DRPC流。可以使用LocalDRPC类创建一个简单的DRCP服务器。LocalDRPC具有execute方法来搜索某些关键字。完整的代码如下。
编码:LogAnalyserTrident.java
import java.util.*; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.LocalDRPC; import backtype.storm.utils.DRPCClient; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import storm.trident.TridentState; import storm.trident.TridentTopology; import storm.trident.tuple.TridentTuple; import storm.trident.operation.builtin.FilterNull; import storm.trident.operation.builtin.Count; import storm.trident.operation.builtin.Sum; import storm.trident.operation.builtin.MapGet; import storm.trident.operation.builtin.Debug; import storm.trident.operation.BaseFilter; import storm.trident.testing.FixedBatchSpout; import storm.trident.testing.FeederBatchSpout; import storm.trident.testing.Split; import storm.trident.testing.MemoryMapState; import com.google.common.collect.ImmutableList; public class LogAnalyserTrident { public static void main(String[] args) throws Exception { System.out.println("Log Analyser Trident"); TridentTopology topology = new TridentTopology(); FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber", "toMobileNumber", "duration")); TridentState callCounts = topology .newStream("fixed-batch-spout", testSpout) .each(new Fields("fromMobileNumber", "toMobileNumber"), new FormatCall(), new Fields("call")) .groupBy(new Fields("call")) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count")); LocalDRPC drpc = new LocalDRPC(); topology.newDRPCStream("call_count", drpc) .stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count")); topology.newDRPCStream("multiple_call_count", drpc) .each(new Fields("args"), new CSVSplit(), new Fields("call")) .groupBy(new Fields("call")) .stateQuery(callCounts, new Fields("call"), new MapGet(), new Fields("count")) .each(new Fields("call", "count"), new Debug()) .each(new Fields("count"), new FilterNull()) .aggregate(new Fields("count"), new Sum(), new Fields("sum")); Config conf = new Config(); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("trident", conf, topology.build()); Random randomGenerator = new Random(); int idx = 0; while(idx < 10) { testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", randomGenerator.nextInt(60)))); testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123403", randomGenerator.nextInt(60)))); testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123404", randomGenerator.nextInt(60)))); testSpout.feed(ImmutableList.of(new Values("1234123402", "1234123403", randomGenerator.nextInt(60)))); idx = idx + 1; } System.out.println("DRPC : Query starts"); System.out.println(drpc.execute("call_count","1234123401 - 1234123402")); System.out.println(drpc.execute("multiple_call_count", "1234123401 - 1234123402,1234123401 - 1234123403")); System.out.println("DRPC : Query ends"); cluster.shutdown(); drpc.shutdown(); // DRPCClient client = new DRPCClient("drpc.server.location", 3772); } }
生成和运行应用程序
完整的应用程序包含三个Java代码。它们如下-
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
可以使用以下命令来构建应用程序-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.java
可以使用以下命令运行该应用程序-
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTrident
输出
一旦启动应用程序,该应用程序将输出有关群集启动过程,操作处理,DRPC服务器和客户端信息以及最后群集关闭过程的完整详细信息。该输出将显示在控制台上,如下所示。
DRPC : Query starts [["1234123401 - 1234123402",10]] DEBUG: [1234123401 - 1234123402, 10] DEBUG: [1234123401 - 1234123403, 10] [[20]] DRPC : Query ends
Twitter中的Apache Storm
在本章的此处,我们将讨论Apache Storm的实时应用程序。我们将看到如何在Twitter中使用Storm。
推特
Twitter是一种在线社交网络服务,它提供了一个发送和接收用户推文的平台。注册用户可以阅读和发布推文,但未注册用户只能阅读推文。Hashtag用于通过在相关关键字之前添加#来按关键字对推文进行分类。现在,让我们以实时场景为例,查找每个主题使用最多的主题标签。
壶嘴创作
喷口的目的是尽快获得人们提交的推文。Twitter提供了“ Twitter Streaming API”,这是一个基于Web服务的工具,用于实时检索人们提交的推文。可以使用任何编程语言访问Twitter Streaming API。
twitter4j是一个开源的非官方Java库,它提供了一个基于Java的模块,可以轻松访问Twitter Streaming API。twitter4j提供了一个基于侦听器的框架来访问这些推文。要访问Twitter Streaming API,我们需要登录Twitter开发人员帐户,并应获得以下OAuth身份验证详细信息。
- 客户键
- 客户秘密
- AccessToken
- AccessTookenSecret
Storm在其入门工具包中提供了一个Twitter喷口TwitterSampleSpout。我们将使用它来检索推文。喷口需要OAuth身份验证详细信息和至少一个关键字。喷口将基于关键字发出实时推文。完整的程序代码如下。
编码:TwitterSampleSpout.java
import java.util.Map; import java.util.concurrent.LinkedBlockingQueue; import twitter4j.FilterQuery; import twitter4j.StallWarning; import twitter4j.Status; import twitter4j.StatusDeletionNotice; import twitter4j.StatusListener; import twitter4j.TwitterStream; import twitter4j.TwitterStreamFactory; import twitter4j.auth.AccessToken; import twitter4j.conf.ConfigurationBuilder; import backtype.storm.Config; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichSpout; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.utils.Utils; @SuppressWarnings("serial") public class TwitterSampleSpout extends BaseRichSpout { SpoutOutputCollector _collector; LinkedBlockingQueue<Status> queue = null; TwitterStream _twitterStream; String consumerKey; String consumerSecret; String accessToken; String accessTokenSecret; String[] keyWords; public TwitterSampleSpout(String consumerKey, String consumerSecret, String accessToken, String accessTokenSecret, String[] keyWords) { this.consumerKey = consumerKey; this.consumerSecret = consumerSecret; this.accessToken = accessToken; this.accessTokenSecret = accessTokenSecret; this.keyWords = keyWords; } public TwitterSampleSpout() { // TODO Auto-generated constructor stub } @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { queue = new LinkedBlockingQueue<Status>(1000); _collector = collector; StatusListener listener = new StatusListener() { @Override public void onStatus(Status status) { queue.offer(status); } @Override public void onDeletionNotice(StatusDeletionNotice sdn) {} @Override public void onTrackLimitationNotice(int i) {} @Override public void onScrubGeo(long l, long l1) {} @Override public void onException(Exception ex) {} @Override public void onStallWarning(StallWarning arg0) { // TODO Auto-generated method stub } }; ConfigurationBuilder cb = new ConfigurationBuilder(); cb.setDebugEnabled(true) .setOAuthConsumerKey(consumerKey) .setOAuthConsumerSecret(consumerSecret) .setOAuthAccessToken(accessToken) .setOAuthAccessTokenSecret(accessTokenSecret); _twitterStream = new TwitterStreamFactory(cb.build()).getInstance(); _twitterStream.addListener(listener); if (keyWords.length == 0) { _twitterStream.sample(); }else { FilterQuery query = new FilterQuery().track(keyWords); _twitterStream.filter(query); } } @Override public void nextTuple() { Status ret = queue.poll(); if (ret == null) { Utils.sleep(50); } else { _collector.emit(new Values(ret)); } } @Override public void close() { _twitterStream.shutdown(); } @Override public Map<String, Object> getComponentConfiguration() { Config ret = new Config(); ret.setMaxTaskParallelism(1); return ret; } @Override public void ack(Object id) {} @Override public void fail(Object id) {} @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("tweet")); } }
标签阅读器螺栓
spout发出的tweet将转发到HashtagReaderBolt,后者将处理该tweet并发出所有可用的hashtag。HashtagReaderBolt使用twitter4j提供的getHashTagEntities方法。getHashTagEntities读取鸣叫并返回主题标签列表。完整的程序代码如下-
编码:HashtagReaderBolt.java
import java.util.HashMap; import java.util.Map; import twitter4j.*; import twitter4j.conf.*; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.IRichBolt; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.tuple.Tuple; public class HashtagReaderBolt implements IRichBolt { private OutputCollector collector; @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { this.collector = collector; } @Override public void execute(Tuple tuple) { Status tweet = (Status) tuple.getValueByField("tweet"); for(HashtagEntity hashtage : tweet.getHashtagEntities()) { System.out.println("Hashtag: " + hashtage.getText()); this.collector.emit(new Values(hashtage.getText())); } } @Override public void cleanup() {} @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("hashtag")); } @Override public Map<String, Object> getComponentConfiguration() { return null; } }
标签螺栓
发出的主题标签将转发到HashtagCounterBolt。该螺栓将处理所有主题标签,并使用Java Map对象将每个主题标签及其计数保存在内存中。完整的程序代码如下。
编码:HashtagCounterBolt.java
import java.util.HashMap; import java.util.Map; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.IRichBolt; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.tuple.Tuple; public class HashtagCounterBolt implements IRichBolt { Map<String, Integer> counterMap; private OutputCollector collector; @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { this.counterMap = new HashMap<String, Integer>(); this.collector = collector; } @Override public void execute(Tuple tuple) { String key = tuple.getString(0); if(!counterMap.containsKey(key)){ counterMap.put(key, 1); }else{ Integer c = counterMap.get(key) + 1; counterMap.put(key, c); } collector.ack(tuple); } @Override public void cleanup() { for(Map.Entry<String, Integer> entry:counterMap.entrySet()){ System.out.println("Result: " + entry.getKey()+" : " + entry.getValue()); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("hashtag")); } @Override public Map<String, Object> getComponentConfiguration() { return null; } }
提交拓扑
提交拓扑是主要应用程序。Twitter拓扑由TwitterSampleSpout,HashtagReaderBolt和HashtagCounterBolt组成。以下程序代码显示了如何提交拓扑。
编码:TwitterHashtagStorm.java
import java.util.*; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; public class TwitterHashtagStorm { public static void main(String[] args) throws Exception{ String consumerKey = args[0]; String consumerSecret = args[1]; String accessToken = args[2]; String accessTokenSecret = args[3]; String[] arguments = args.clone(); String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length); Config config = new Config(); config.setDebug(true); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey, consumerSecret, accessToken, accessTokenSecret, keyWords)); builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt()) .shuffleGrouping("twitter-spout"); builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt()) .fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag")); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("TwitterHashtagStorm", config, builder.createTopology()); Thread.sleep(10000); cluster.shutdown(); } }
生成和运行应用程序
完整的应用程序具有四个Java代码。它们如下-
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
您可以使用以下命令编译应用程序-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.java
使用以下命令执行应用程序-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:. TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret> <keyword1> <keyword2> … <keywordN>
输出
该应用程序将打印当前可用的主题标签及其计数。输出应类似于以下内容-
Result: jazztastic : 1 Result: foodie : 1 Result: Redskins : 1 Result: Recipe : 1 Result: cook : 1 Result: android : 1 Result: food : 2 Result: NoToxicHorseMeat : 1 Result: Purrs4Peace : 1 Result: livemusic : 1 Result: VIPremium : 1 Result: Frome : 1 Result: SundayRoast : 1 Result: Millennials : 1 Result: HealthWithKier : 1 Result: LPs30DaysofGratitude : 1 Result: cooking : 1 Result: gameinsight : 1 Result: Countryfile : 1 Result: androidgames : 1
Yahoo中的Apache Storm!金融
雅虎!财经是互联网上领先的商业新闻和金融数据网站。它是Yahoo!的一部分!并提供有关金融新闻,市场统计数据,国际市场数据以及其他任何人都可以访问的金融资源的信息。
如果您是注册的Yahoo! 用户,则可以自定义Yahoo! 财务可以利用其某些产品。雅虎!Finance API用于查询Yahoo!的财务数据。
此API显示的数据与实时数据相比延迟了15分钟,并且每1分钟更新一次其数据库,以访问当前与库存相关的信息。现在,让我们以一家公司的实时情况为例,看看当其股票价值低于100时如何发出警报。
壶嘴创作
壶嘴的目的是获得公司的详细信息,然后将价格撒到螺栓上。您可以使用以下程序代码创建喷嘴。
编码:YahooFinanceSpout.java
import java.util.*; import java.io.*; import java.math.BigDecimal; //import yahoofinace packages import yahoofinance.YahooFinance; import yahoofinance.Stock; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.topology.IRichSpout; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; public class YahooFinanceSpout implements IRichSpout { private SpoutOutputCollector collector; private boolean completed = false; private TopologyContext context; @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){ this.context = context; this.collector = collector; } @Override public void nextTuple() { try { Stock stock = YahooFinance.get("INTC"); BigDecimal price = stock.getQuote().getPrice(); this.collector.emit(new Values("INTC", price.doubleValue())); stock = YahooFinance.get("GOOGL"); price = stock.getQuote().getPrice(); this.collector.emit(new Values("GOOGL", price.doubleValue())); stock = YahooFinance.get("AAPL"); price = stock.getQuote().getPrice(); this.collector.emit(new Values("AAPL", price.doubleValue())); } catch(Exception e) {} } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("company", "price")); } @Override public void close() {} public boolean isDistributed() { return false; } @Override public void activate() {} @Override public void deactivate() {} @Override public void ack(Object msgId) {} @Override public void fail(Object msgId) {} @Override public Map<String, Object> getComponentConfiguration() { return null; } }
螺栓创建
这里的目的是在价格跌到100以下时处理给定公司的价格。当股价跌到100以下时,它使用Java Map对象将截止价格限制警报设置为true;否则为假。完整的程序代码如下-
编码:PriceCutOffBolt.java
import java.util.HashMap; import java.util.Map; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.IRichBolt; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.tuple.Tuple; public class PriceCutOffBolt implements IRichBolt { Map<String, Integer> cutOffMap; Map<String, Boolean> resultMap; private OutputCollector collector; @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { this.cutOffMap = new HashMap <String, Integer>(); this.cutOffMap.put("INTC", 100); this.cutOffMap.put("AAPL", 100); this.cutOffMap.put("GOOGL", 100); this.resultMap = new HashMap<String, Boolean>(); this.collector = collector; } @Override public void execute(Tuple tuple) { String company = tuple.getString(0); Double price = tuple.getDouble(1); if(this.cutOffMap.containsKey(company)){ Integer cutOffPrice = this.cutOffMap.get(company); if(price < cutOffPrice) { this.resultMap.put(company, true); } else { this.resultMap.put(company, false); } } collector.ack(tuple); } @Override public void cleanup() { for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){ System.out.println(entry.getKey()+" : " + entry.getValue()); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("cut_off_price")); } @Override public Map<String, Object> getComponentConfiguration() { return null; } }
提交拓扑
这是YahooFinanceSpout.java和PriceCutOffBolt.java连接在一起并生成拓扑的主要应用程序。以下程序代码显示了如何提交拓扑。
编码:YahooFinanceStorm.java
import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; public class YahooFinanceStorm { public static void main(String[] args) throws Exception{ Config config = new Config(); config.setDebug(true); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout()); builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt()) .fieldsGrouping("yahoo-finance-spout", new Fields("company")); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology()); Thread.sleep(10000); cluster.shutdown(); } }
生成和运行应用程序
完整的应用程序包含三个Java代码。它们如下-
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
可以使用以下命令构建应用程序-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.java
可以使用以下命令运行该应用程序-
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:. YahooFinanceStorm
输出
输出将类似于以下内容-
GOOGL : false AAPL : false INTC : true
Apache Storm-应用程序
Apache Storm框架支持当今许多最佳的工业应用程序。在本章中,我们将简要介绍Storm的一些最著名的应用程序。
克鲁特
Klout是一个应用程序,使用社交媒体分析通过Klout Score(介于1到100之间的数字值)基于在线社交影响力对其用户进行排名。Klout使用Apache Storm的内置Trident抽象来创建复杂的拓扑结构以传输数据。
天气频道
天气频道使用Storm拓扑来获取天气数据。它已与Twitter捆绑在一起,以在Twitter和移动应用程序上启用气象信息广告。OpenSignal是一家专门从事无线覆盖映射的公司。StormTag和WeatherSignal是OpenSignal创建的基于天气的项目。StormTag是一个附在钥匙串上的蓝牙气象站。设备收集的天气数据将发送到WeatherSignal应用程序和OpenSignal服务器。
电信业
电信提供商每秒处理数百万个电话。他们对掉线和声音质量差进行取证。呼叫详细记录以每秒数百万的速度流入,Apache Storm实时处理这些记录并识别任何麻烦的模式。风暴分析可用于不断提高通话质量。
其他教程链接:
- apache storm简介
- apache storm核心概念
- apache storm群集体系结构
- apache storm工作流
- apachestorm分布式消息系统
- apache storm安装
- apache storm工作示例
- 阿帕奇风暴三叉戟
- twitter上的阿帕奇风暴
- 雅虎金融的阿帕奇风暴
- apache storm应用程序
- apache storm快速指南
- apache storm有用资源
- 阿帕奇风暴讨论
- apache tajo简介
- apache tajo体系结构
- apache tajo安装
- apache tajo配置设置
- apache tajo shell命令
- apache tajo数据类型
- apache tajo运算符
- apache tajo sql函数
- apache tajo数学函数
- apache tajo字符串函数
- apache tajo datetime函数
- apache tajo json函数
- apache tajo数据库创建
- apache tajo表管理
- apache tajo sql语句
- apache tajo聚合和窗口函数
- apache tajo sql查询
- apache tajo存储插件
- apache tajo与hbase的集成
- apache tajo与hive的集成
- apache-tajo-openstack-swift集成
- ApacheTajoJDBC接口
- apache tajo自定义函数
- apache tajo快速指南
- apache tajo有用的资源
- apache tajo讨论
