Apache Flume – 获取 Twitter 数据
Apache Flume – 获取 Twitter 数据
使用 Flume,我们可以从各种服务中获取数据并将其传输到集中式存储(HDFS 和 HBase)。本章解释了如何使用 Apache Flume 从 Twitter 服务获取数据并将其存储在 HDFS 中。
正如 Flume 架构中所讨论的,网络服务器生成日志数据,这些数据由 Flume 中的代理收集。通道将此数据缓冲到接收器,最终将其推送到集中式存储。
在本章提供的示例中,我们将创建一个应用程序并使用 Apache Flume 提供的实验性 twitter 源从中获取推文。我们将使用内存通道来缓冲这些推文,并使用 HDFS 接收器将这些推文推送到 HDFS。
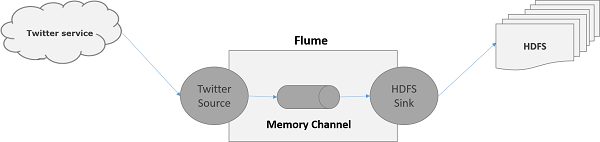
要获取 Twitter 数据,我们必须按照以下步骤操作 –
- 创建一个推特应用程序
- 安装/启动 HDFS
- 配置水槽
创建 Twitter 应用程序
为了从 Twitter 获取推文,需要创建一个 Twitter 应用程序。按照下面给出的步骤创建一个 Twitter 应用程序。
步骤1
要创建 Twitter 应用程序,请单击以下链接https://apps.twitter.com/。登录您的 Twitter 帐户。您将拥有一个 Twitter 应用程序管理窗口,您可以在其中创建、删除和管理 Twitter 应用程序。

第2步
单击“创建新应用程序”按钮。您将被重定向到一个窗口,您将在其中获得一个申请表,您必须在其中填写您的详细信息才能创建应用程序。在填写网站地址时,给出完整的 URL 模式,例如http://example.com。
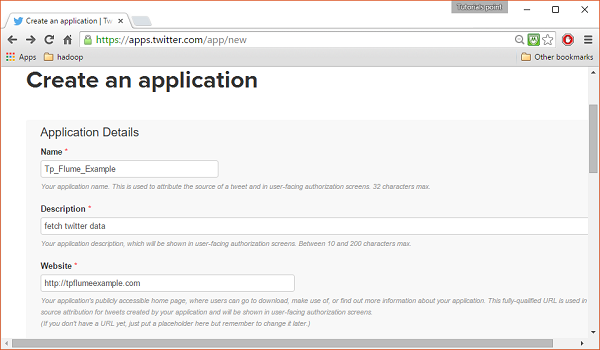
第 3 步
填写详细信息,完成后接受开发者协议,单击页面底部的创建您的 Twitter 应用程序按钮。如果一切顺利,将使用给定的详细信息创建一个应用程序,如下所示。
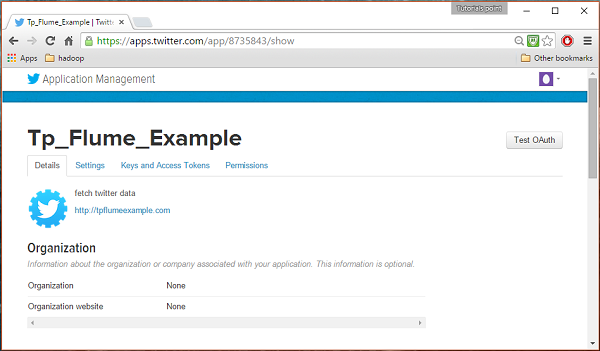
第四步
在页面底部的密钥和访问令牌选项卡下,您可以看到一个名为Create my access token的按钮。单击它以生成访问令牌。
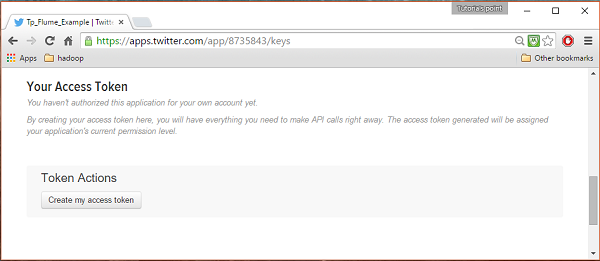
第 5 步
最后,单击页面右侧顶部的“测试 OAuth”按钮。这将打开一个页面,其中显示您的Consumer key、Consumer secret、Access token和Access token secret。复制这些详细信息。这些对于在 Flume 中配置代理很有用。
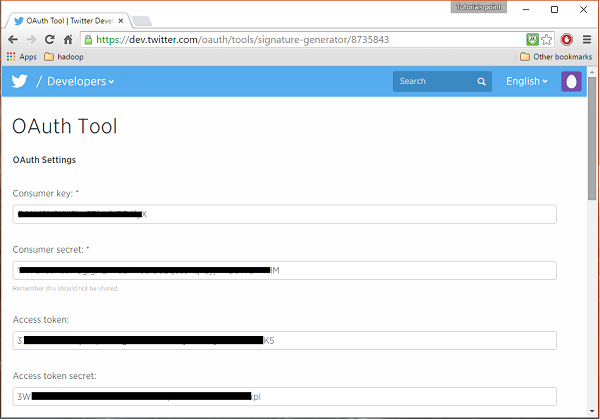
启动 HDFS
由于我们将数据存储在 HDFS 中,因此我们需要安装/验证 Hadoop。启动 Hadoop 并在其中创建一个文件夹来存储 Flume 数据。在配置 Flume 之前,请按照以下步骤操作。
步骤 1:安装/验证 Hadoop
安装Hadoop。如果您的系统中已经安装了 Hadoop,请使用 Hadoop version 命令验证安装,如下所示。
$ hadoop version
如果您的系统包含 Hadoop,并且您已经设置了路径变量,那么您将获得以下输出 –
Hadoop 2.6.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
第 2 步:启动 Hadoop
浏览Hadoop的sbin目录,启动yarn和Hadoop dfs(分布式文件系统),如下图。
cd /$Hadoop_Home/sbin/ $ start-dfs.sh localhost: starting namenode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out localhost: starting datanode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out Starting secondary namenodes [0.0.0.0] starting secondarynamenode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out $ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out localhost: starting nodemanager, logging to /home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.out
第 3 步:在 HDFS 中创建目录
在 Hadoop DFS 中,您可以使用命令mkdir创建目录。浏览它并在所需路径中创建一个名为twitter_data的目录,如下所示。
$cd /$Hadoop_Home/bin/ $ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_data
配置水槽
我们必须使用conf文件夹中的配置文件来配置源、通道和接收器。本章中给出的示例使用了 Apache Flume 提供的名为Twitter 1% Firehose内存通道和 HDFS 接收器的实验源。
Twitter 1% Firehose 来源
这个来源是高度实验性的。它使用流 API 连接到 1% 的示例 Twitter Firehose,并不断下载推文,将它们转换为 Avro 格式,并将 Avro 事件发送到下游 Flume 接收器。
默认情况下,我们将在安装 Flume 时获取此源。这个源对应的jar文件可以位于lib文件夹中,如下所示。
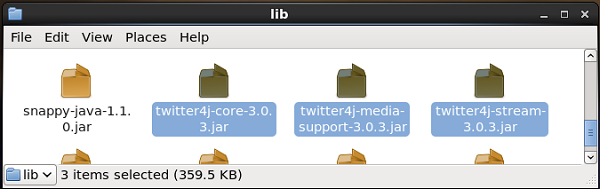
设置类路径
将classpath变量设置为Flume-env.sh文件中Flume的lib文件夹,如下图。
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*
此源需要Twitter 应用程序的消费者密钥、消费者机密、访问令牌和访问令牌机密等详细信息。在配置此源时,您必须为以下属性提供值 –
-
频道
-
源类型:org.apache.flume.source.twitter.TwitterSource
-
consumerKey – OAuth用户端密钥
-
consumerSecret – OAuth用户端密钥
-
accessToken – OAuth 访问令牌
-
accessTokenSecret – OAuth 令牌秘密
-
maxBatchSize – 推特批处理中应包含的推特消息的最大数量。默认值为 1000(可选)。
-
maxBatchDurationMillis – 关闭批处理之前等待的最大毫秒数。默认值为 1000(可选)。
渠道
我们正在使用内存通道。要配置内存通道,您必须为通道类型提供值。
-
type – 它保存通道的类型。在我们的示例中,类型为MemChannel。
-
容量– 它是存储在通道中的最大事件数。其默认值为 100(可选)。
-
TransactionCapacity – 它是通道接受或发送的最大事件数。其默认值为 100(可选)。
HDFS接收器
此接收器将数据写入 HDFS。要配置此接收器,您必须提供以下详细信息。
-
渠道
-
类型– hdfs
-
hdfs.path – HDFS 中要存储数据的目录的路径。
并且我们可以根据场景提供一些可选值。下面给出了我们在应用程序中配置的 HDFS 接收器的可选属性。
-
fileType – 这是我们的 HDFS 文件所需的文件格式。SequenceFile、DataStream和CompressedStream是此流可用的三种类型。在我们的示例中,我们使用的是DataStream。
-
writeFormat – 可以是文本或可写。
-
batchSize – 它是在将文件刷新到 HDFS 之前写入文件的事件数。其默认值为 100。
-
rollsize – 这是触发滚动的文件大小。它的默认值为 100。
-
rollCount – 它是在滚动之前写入文件的事件数。其默认值为 10。
示例 – 配置文件
下面给出了一个配置文件的例子。复制此内容并保存为twitter.conf在 Flume 的 conf 文件夹中。
# Naming the components on the current agent. TwitterAgent.sources = Twitter TwitterAgent.channels = MemChannel TwitterAgent.sinks = HDFS # Describing/Configuring the source TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql # Describing/Configuring the sink TwitterAgent.sinks.HDFS.type = hdfs TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/ TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000 TwitterAgent.sinks.HDFS.hdfs.rollSize = 0 TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000 # Describing/Configuring the channel TwitterAgent.channels.MemChannel.type = memory TwitterAgent.channels.MemChannel.capacity = 10000 TwitterAgent.channels.MemChannel.transactionCapacity = 100 # Binding the source and sink to the channel TwitterAgent.sources.Twitter.channels = MemChannel TwitterAgent.sinks.HDFS.channel = MemChannel
执行
浏览 Flume 主目录并执行如下所示的应用程序。
$ cd $FLUME_HOME $ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf Dflume.root.logger=DEBUG,console -n TwitterAgent
如果一切顺利,将开始将推文流式传输到 HDFS。下面给出的是获取推文时命令提示符窗口的快照。
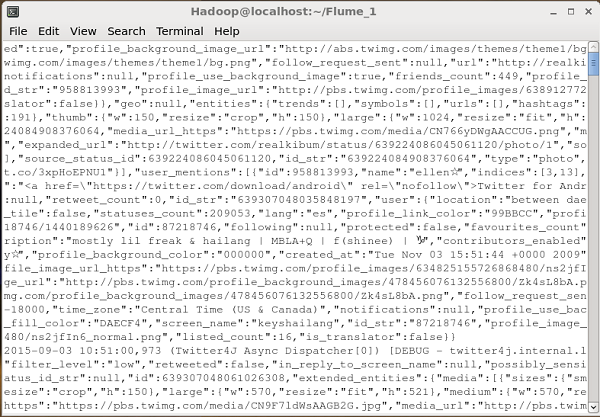
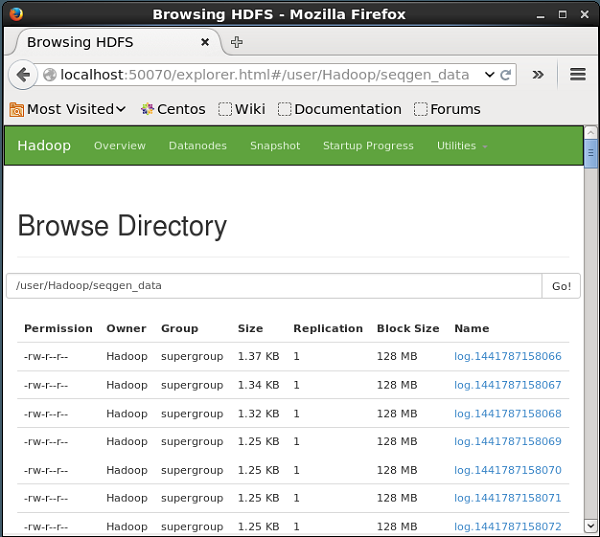
验证 HDFS
您可以使用下面给出的 URL 访问 Hadoop 管理 Web UI。
http://localhost:50070/
单击页面右侧名为Utilities的下拉菜单。您可以看到两个选项,如下面的快照所示。
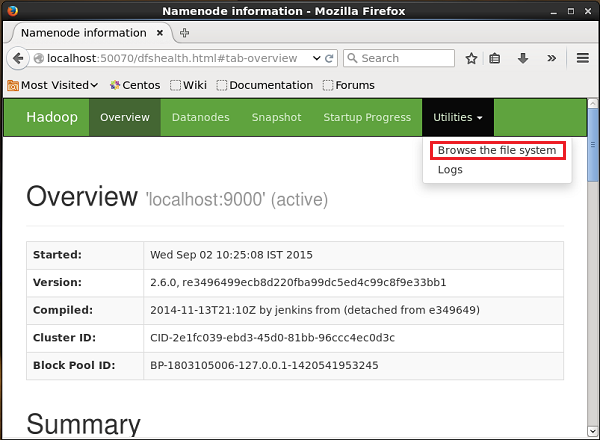
单击浏览文件系统并输入存储推文的 HDFS 目录的路径。在我们的示例中,路径将是/user/Hadoop/twitter_data/。然后,您可以看到存储在 HDFS 中的 Twitter 日志文件列表,如下所示。