OBIEE – 架构
OBIEE – 架构
Schema 是对整个数据库的逻辑描述。它包括所有类型记录的名称和描述,包括所有关联的数据项和聚合。与数据库非常相似,DW 也需要维护模式。数据库使用关系模型,而 DW 使用 Star、Snowflake 和 Fact Constellation 模式(Galaxy 模式)。
星型架构
在星型模式中,有多个非规范化形式的维度表仅连接到一个事实表。这些表以逻辑方式连接,以满足分析目的的某些业务需求。这些模式是多维结构,用于使用 BI 报告工具创建报告。
星型模式中的维度包含一组属性,事实表包含所有维度和测量值的外键。

在上面的 Star Schema 中,中间有一个事实表“Sales Fact”,并使用主键连接到 4 个维度表。维度表没有进一步规范化,这种表的连接在 DW 中称为星型模式。
事实表还包含度量值 – Dollar_sold 和 units_sold。
雪花架构
在雪花模式中,有多个标准化形式的维度表,它们仅连接到一个事实表。这些表以逻辑方式连接,以满足分析目的的某些业务需求。
Star 和 Snowflakes 模式之间的唯一区别是维度表被进一步规范化。规范化将数据拆分到附加表中。由于雪花模式中的规范化,减少了数据冗余,而不会丢失任何信息,因此易于维护并节省存储空间。
在上面的 Snowflakes Schema 示例中,进一步规范了 Product 和 Customer 表以节省存储空间。有时,当您执行需要直接处理规范化表中的行的查询时,它还提供性能优化,因此它不处理主维度表中的行,而直接进入 Schema 中的规范化表。
粒度
表中的粒度表示存储在表中的信息级别。数据的高粒度意味着数据处于或接近事务级别,具有更多细节。低粒度意味着数据具有低级别的信息。
事实表通常设计为低粒度级别。这意味着我们需要找到可以存储在事实表中的最低级别的信息。在日期维度中,粒度级别可以是年、月、季度、周期、周和日。
定义粒度的过程包括两个步骤 –
- 确定要包括的尺寸。
- 确定放置信息的每个维度的层次结构的位置。
缓慢变化的维度
缓慢变化的维度是指属性值随时间的变化。它是 DW 中常见的概念之一。
例子
Andy 是 XYZ Inc. 的员工。他于 2015 年 7 月首次位于纽约市。员工查找表中的原始条目具有以下记录 –
| Employee ID | 10001 |
|---|---|
| Name | 安迪 |
| Location | 纽约 |
后来,他搬到了加利福尼亚州洛杉矶。XYZ Inc. 现在应该如何修改其员工表以反映此更改?
这被称为“缓慢变化的维度”概念。
有三种方法可以解决此类问题 –
解决方案1
新记录替换原始记录。没有旧记录的痕迹存在。
渐变维度,新信息简单地覆盖了原始信息。换句话说,没有保留任何历史记录。
| Employee ID | 10001 |
|---|---|
| Name | 安迪 |
| Location | 加利福尼亚州洛杉矶 |
-
好处– 这是处理缓慢变化维度问题的最简单方法,因为无需跟踪旧信息。
-
缺点– 所有历史信息都丢失了。
-
使用– 当 DW 不需要跟踪历史信息时,应使用解决方案 1。
解决方案2
一条新记录被输入到员工维度表中。因此,员工安迪被视为两个人。
将新记录添加到表中以表示新信息,并且原始记录和新记录都将出现。新记录获得自己的主键如下 –
| Employee ID | 10001 | 10002 |
|---|---|---|
| Name | 安迪 | 安迪 |
| Location | 纽约 | 加利福尼亚州洛杉矶 |
-
好处– 这种方法允许我们存储所有历史信息。
-
缺点– 表的大小增长得更快。当表的行数非常多时,表的空间和性能可能是一个问题。
-
使用– 当 DW 需要保留历史数据时,应使用解决方案 2。
解决方案3
Employee 维度中的原始记录被修改以反映更改。
将有两列表示特定属性,一列表示原始值,另一列表示新值。还会有一列指示当前值何时变为活动状态。
| Employee ID | 名称 | 原位置 | 新地点 | 搬家日期 |
|---|---|---|---|---|
| 10001 | 安迪 | 纽约 | 加利福尼亚州洛杉矶 | 2015 年 7 月 |
-
好处– 这不会增加表格的大小,因为新信息已更新。这使我们能够保留历史信息。
-
缺点– 当属性值更改不止一次时,此方法不会保留所有历史记录。
-
使用– 解决方案 3 仅应在 DW 需要保留历史更改信息时使用。
正常化
规范化是在不丢失任何信息的情况下将表分解为冗余较少的较小表的过程。所以数据库规范化是组织数据库的属性和表以最小化数据冗余(重复数据)的过程。
标准化的目的
-
它用于消除某些类型的数据(冗余/复制)以提高一致性。
-
通过以简化形式保留与对象类型相对应的表,它提供了最大的灵活性来满足未来的信息需求。
-
它产生了一个更清晰可读的数据模型。
优点
- 数据的完整性。
- 增强数据一致性。
- 减少数据冗余和所需空间。
- 降低更新成本。
- 响应临时查询的最大灵活性。
- 减少每个块的总行数。
缺点
数据库中的查询性能缓慢,因为必须执行连接才能从多个规范化表中检索相关数据。
您必须了解数据模型才能在多个表之间执行正确的连接。
例子
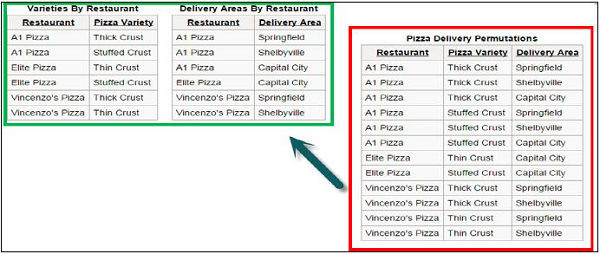
在上面的示例中,绿色块内的表表示红色块内的表的规范化表。绿色块中的表冗余较少,行数也较少,不会丢失任何信息。
