大数据分析 – 数据生命周期
大数据分析 – 数据生命周期
传统数据挖掘生命周期
为了提供一个框架来组织组织所需的工作并从大数据中提供清晰的见解,将其视为具有不同阶段的循环很有用。它绝不是线性的,这意味着所有阶段都相互关联。这个循环与CRISP 方法中描述的更传统的数据挖掘循环有表面上的相似之处。
CRISP-DM 方法论
在CRISP-DM方法是代表了数据挖掘跨行业标准流程,是数据挖掘专家使用它们来处理传统的BI数据挖掘的问题,介绍了常用的手法周期。它仍在传统的 BI 数据挖掘团队中使用。
请看下图。它显示了 CRISP-DM 方法所描述的周期的主要阶段以及它们是如何相互关联的。
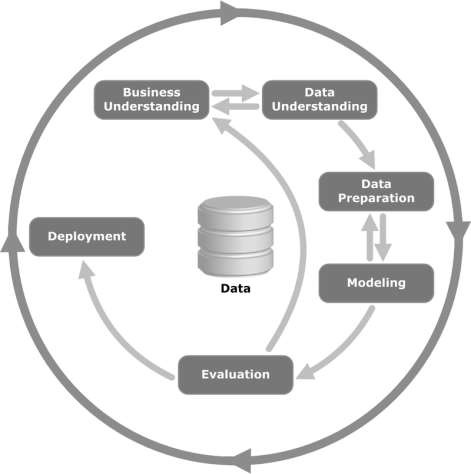
CRISP-DM 于 1996 年构想,次年作为 ESPRIT 资助计划下的欧盟项目开始实施。该项目由五家公司牵头:SPSS、Teradata、戴姆勒股份公司、NCR Corporation 和 OHRA(一家保险公司)。该项目最终被并入SPSS。该方法论针对如何指定数据挖掘项目非常详细。
现在让我们更多地了解 CRISP-DM 生命周期中涉及的每个阶段 –
-
业务理解– 此初始阶段侧重于从业务角度理解项目目标和要求,然后将这些知识转换为数据挖掘问题定义。初步计划旨在实现目标。可以使用决策模型,尤其是使用决策模型和符号标准构建的模型。
-
数据理解– 数据理解阶段从初始数据收集开始,然后进行活动以熟悉数据,识别数据质量问题,发现对数据的初步见解,或检测有趣的子集以形成隐藏的假设信息。
-
数据准备– 数据准备阶段涵盖从初始原始数据构建最终数据集(将被馈送到建模工具的数据)的所有活动。数据准备任务可能会执行多次,并且没有任何规定的顺序。任务包括表、记录和属性选择以及建模工具的数据转换和清理。
-
建模– 在此阶段,选择并应用各种建模技术,并将其参数校准为最佳值。通常,对于相同的数据挖掘问题类型有多种技术。一些技术对数据的形式有特定的要求。因此,往往需要退回到数据准备阶段。
-
评估– 在项目的这个阶段,从数据分析的角度来看,您已经构建了一个看起来高质量的模型(或多个模型)。在进行模型的最终部署之前,重要的是彻底评估模型并审查构建模型所执行的步骤,以确保其正确实现业务目标。
一个关键目标是确定是否存在一些尚未充分考虑的重要业务问题。在此阶段结束时,应就数据挖掘结果的使用做出决定。
-
部署– 模型的创建通常不是项目的结束。即使模型的目的是增加对数据的了解,所获得的知识也需要以对客户有用的方式进行组织和呈现。
根据要求,部署阶段可以像生成报告一样简单,也可以像实施可重复的数据评分(例如段分配)或数据挖掘过程一样复杂。
在许多情况下,执行部署步骤的是客户,而不是数据分析师。即使分析师部署了模型,客户也必须预先了解需要执行的操作,以便实际使用创建的模型。
SEMMA方法论
SEMMA 是 SAS 开发的另一种数据挖掘建模方法。它代表着小号充足,ē Xplore数据库,中号odify,中号奥德尔,和一个小规模企业。以下是其阶段的简要说明 –
-
Sample – 该过程从数据采样开始,例如,选择用于建模的数据集。数据集应该足够大以包含足够的信息来检索,但又要足够小以有效使用。此阶段还处理数据分区。
-
探索– 此阶段通过在数据可视化的帮助下发现变量之间的预期和意外关系以及异常来涵盖对数据的理解。
-
修改– 修改阶段包含选择、创建和转换变量以准备数据建模的方法。
-
模型– 在模型阶段,重点是对准备好的变量应用各种建模(数据挖掘)技术,以创建可能提供所需结果的模型。
-
评估– 建模结果的评估显示了所创建模型的可靠性和实用性。
CRISM-DM 和 SEMMA 之间的主要区别在于 SEMMA 侧重于建模方面,而 CRISP-DM 更重视建模之前的周期阶段,例如理解要解决的业务问题、理解和预处理要解决的数据。用作输入,例如机器学习算法。
大数据生命周期
在当今的大数据环境中,以前的方法要么不完整,要么不理想。例如,SEMMA 方法完全忽略了不同数据源的数据收集和预处理。这些阶段通常构成成功的大数据项目的大部分工作。
大数据分析周期可以通过以下阶段来描述 –
- 业务问题定义
- 研究
- 人力资源评估
- 数据采集
- 数据处理
- 数据存储
- 探索性数据分析
- 建模和评估的数据准备
- 造型
- 执行
在本节中,我们将介绍大数据生命周期的每个阶段。
业务问题定义
这是传统 BI 和大数据分析生命周期中的常见问题。通常,定义问题并正确评估它可能为组织带来多少潜在收益是大数据项目的一个重要阶段。提到这一点似乎很明显,但必须评估项目的预期收益和成本。
研究
分析其他公司在相同情况下的做法。这涉及寻找对贵公司合理的解决方案,即使它涉及调整其他解决方案以适应贵公司拥有的资源和要求。在这个阶段,应该定义未来阶段的方法论。
人力资源评估
一旦定义了问题,就可以继续分析当前员工是否能够成功完成项目。传统的 BI 团队可能无法提供所有阶段的最佳解决方案,因此如果需要将项目的一部分外包或雇用更多人员,则应在开始项目之前考虑。
数据采集
这部分是大数据生命周期的关键;它定义了交付结果数据产品所需的配置文件类型。数据收集是该过程的重要步骤;它通常涉及从不同来源收集非结构化数据。举个例子,它可能涉及编写一个爬虫来从网站检索评论。这涉及处理文本,可能是不同语言的文本,通常需要大量时间才能完成。
数据处理
一旦数据被检索到,例如,从网络,它需要以易于使用的格式存储。为了继续评论示例,让我们假设数据是从不同站点检索的,每个站点都有不同的数据显示。
假设一个数据源根据星级评分给出评论,因此可以将其理解为响应变量y ∈ {1, 2, 3, 4, 5}的映射。另一个数据源使用两个箭头系统给出评论,一个用于向上投票,另一个用于向下投票。这意味着形式为y ∈ {positive, negative}的响应变量。
为了组合这两个数据源,必须做出决定以使这两个响应表示等效。这可能涉及将第一个数据源响应表示转换为第二个形式,将一颗星视为负数,将五颗星视为正数。这个过程通常需要大量的时间分配才能高质量地交付。
数据存储
处理完数据后,有时需要将其存储在数据库中。关于这一点,大数据技术提供了大量替代方案。最常见的替代方法是使用 Hadoop 文件系统进行存储,它为用户提供有限版本的 SQL,称为 HIVE 查询语言。从用户的角度来看,这允许大多数分析任务以与在传统 BI 数据仓库中完成的方式类似的方式完成。其他需要考虑的存储选项是 MongoDB、Redis 和 SPARK。
周期的这个阶段与人力资源知识在实施不同架构的能力方面有关。传统数据仓库的修改版本仍在大规模应用中使用。例如,teradata 和 IBM 提供可以处理 TB 级数据的 SQL 数据库;开源解决方案如 postgreSQL 和 MySQL 仍在用于大规模应用程序。
尽管不同存储在后台的工作方式存在差异,但从客户端来看,大多数解决方案都提供 SQL API。因此,对 SQL 有一个很好的理解仍然是大数据分析的关键技能。
这个先验阶段似乎是最重要的话题,实际上,事实并非如此。它甚至不是一个必不可少的阶段。可以实现一个处理实时数据的大数据解决方案,所以在这种情况下,我们只需要收集数据来开发模型,然后实时实现它。因此根本不需要正式存储数据。
探索性数据分析
一旦数据以一种可以从中检索洞察力的方式被清理和存储,数据探索阶段是强制性的。这个阶段的目标是理解数据,这通常是通过统计技术和绘制数据来完成的。这是评估问题定义是否有意义或可行的好阶段。
建模和评估的数据准备
此阶段涉及对先前检索到的清理数据进行整形,并使用统计预处理进行缺失值插补、异常值检测、归一化、特征提取和特征选择。
造型
前一阶段应该已经生成了几个用于训练和测试的数据集,例如一个预测模型。这个阶段涉及尝试不同的模型并期待解决手头的业务问题。在实践中,通常希望模型能够提供对业务的一些洞察。最后,选择最佳模型或模型组合来评估其在遗漏数据集上的性能。
执行
在这个阶段,开发的数据产品在公司的数据管道中实施。这涉及在数据产品工作时设置验证方案,以跟踪其性能。例如,在实施预测模型的情况下,此阶段将涉及将模型应用于新数据,一旦响应可用,则评估模型。
