介绍
在构建现代无状态应用程序时,容器化应用程序组件是在分布式平台上部署和扩展的第一步。如果您在开发中使用了Docker Compose,您将通过以下方式对应用程序进行现代化和容器化:
- 从代码中提取必要的配置信息。
- 卸载应用程序的状态。
- 打包您的应用程序以供重复使用。
您还将编写服务定义,指定容器映像的运行方式。
要在Kubernetes等分布式平台上运行您的服务,您需要将 Compose 服务定义转换为 Kubernetes 对象。这将使您能够灵活地扩展您的应用程序。一个工具,可以加快翻译流程Kubernetes是kompose,一个转换工具,可以帮助开发人员撰写移动工作流程,以协作型集装箱像Kubernetes或OpenShift。
在本教程中,您将使用 kompose将 Compose 服务转换为 Kubernetes对象。您将使用 kompose 提供的对象定义作为起点并进行调整以确保您的设置以 Kubernetes 期望的方式使用Secrets、Services和PersistentVolumeClaims。在本教程结束时,您将拥有一个单实例Rails应用程序,其中包含一个在 Kubernetes 集群上运行的PostgreSQL数据库。此设置将反映使用 Docker Compose 容器化用于开发的 Ruby on Rails 应用程序中描述的代码的功能 并且将是构建可根据您的需求扩展的生产就绪解决方案的良好起点。
先决条件
- 启用了基于角色的访问控制 (RBAC) 的 Kubernetes 1.19+ 集群。此设置将使用DigitalOcean Kubernetes 集群,但您可以使用另一种方法自由创建集群。
kubectl安装在本地机器或开发服务器上并配置为连接到集群的命令行工具。您可以kubectl在官方文档中阅读有关安装的更多信息。- Docker安装在您的本地机器或开发服务器上。如果您使用的是 Ubuntu 20.04,请按照如何在 Ubuntu 20.04 上安装和使用 Docker 的步骤 1 和 2 进行操作;否则,请按照官方文档获取有关在其他操作系统上安装的信息。确保将您的非 root 用户添加到
docker组中,如链接教程的步骤 2 中所述。 - 一个Docker Hub帐户。有关如何进行此设置的概述,请参阅此介绍给泊坞枢纽。
步骤 1 — 安装 kompose
要开始使用 kompose,请导航到该项目的 GitHub发布页面,并将链接复制到当前版本(撰写本文时为1.22.0版)。将此链接粘贴到以下curl命令中以下载最新版本的 kompose:
- curl -L https://github.com/kubernetes/kompose/releases/download/v1.22.0/kompose-linux-amd64 -o kompose
在非 Linux 系统上安装的详细信息,请参阅安装说明。
使二进制可执行文件:
- chmod +x kompose
将其移至您的PATH:
- sudo mv ./kompose /usr/local/bin/kompose
要验证它是否已正确安装,您可以进行版本检查:
- kompose version
如果安装成功,您将看到如下输出:
Output1.22.0 (955b78124)
随着kompose安装并准备使用,现在就可以克隆Node.js的项目代码,你将被翻译成Kubernetes。
步骤 2 — 克隆和打包应用程序
要将我们的应用程序与 Kubernetes 一起使用,我们需要克隆项目代码并打包应用程序,以便kubelet服务可以拉取映像。
我们的第一步是从DigitalOcean 社区 GitHub 帐户克隆rails-sidekiq 存储库。此存储库包含使用 Docker Compose 容器化用于开发的 Ruby on Rails 应用程序中描述的设置中的代码,该代码使用演示 Rails 应用程序来演示如何使用 Docker Compose 设置开发环境。您可以在Rails on Containers系列中找到有关应用程序本身的更多信息。
将存储库克隆到名为 的目录中rails_project:
- git clone https://github.com/do-community/rails-sidekiq.git rails_project
导航到rails_project目录:
- cd rails_project
现在从compose-workflow分支签出本教程的代码:
- git checkout compose-workflow
OutputBranch 'compose-workflow' set up to track remote branch 'compose-workflow' from 'origin'.
Switched to a new branch 'compose-workflow'
该rails_project目录包含用于处理用户输入的鲨鱼信息应用程序的文件和目录。它已被现代化以使用容器:敏感和特定的配置信息已从应用程序代码中删除并重构为在运行时注入,应用程序的状态已卸载到 PostgreSQL 数据库。
有关设计现代无状态应用程序的更多信息,请参阅为 Kubernetes 构建应用程序和为 Kubernetes现代化应用程序。
项目目录包括Dockerfile构建应用程序映像的说明。现在让我们构建镜像,以便您可以将其推送到您的 Docker Hub 帐户并在您的 Kubernetes 设置中使用它。
使用该docker build命令,构建带有-t标志的映像,这允许您使用令人难忘的名称对其进行标记。在这种情况下,使用您的 Docker Hub 用户名标记图像并为其命名rails-kubernetes或您自己选择的名称:
- docker build -t your_dockerhub_user/rails-kubernetes .
将.在命令指定构建上下文是当前目录。
构建映像需要一两分钟。完成后,检查您的图像:
- docker images
您将看到以下输出:
OutputREPOSITORY TAG IMAGE ID CREATED SIZE
your_dockerhub_user/rails-kubernetes latest 24f7e88b6ef2 2 days ago 606MB
alpine latest d6e46aa2470d 6 weeks ago 5.57MB
接下来,登录您在先决条件中创建的 Docker Hub 帐户:
- docker login -u your_dockerhub_user
出现提示时,输入您的 Docker Hub 帐户密码。以这种方式登录将~/.docker/config.json使用您的 Docker Hub 凭据在用户的主目录中创建一个文件。
使用docker push命令将应用程序映像推送到 Docker Hub 。记得your_dockerhub_user用你自己的 Docker Hub 用户名替换:
- docker push your_dockerhub_user/rails-kubernetes
您现在拥有了一个应用程序镜像,您可以使用该镜像通过 Kubernetes 运行您的应用程序。下一步是将您的应用程序服务定义转换为 Kubernetes 对象。
第 3 步 – 使用 kompose 将 Compose 服务转换为 Kubernetes 对象
我们的 Docker Compose 文件(此处称为docker-compose.yml)列出了将使用 Compose 运行我们的服务的定义。一个服务的撰写是一个正在运行的容器,服务定义包含关于每个容器的图像将如何运行的信息。在这一步中,我们将通过使用kompose来创建yaml文件将这些定义转换为 Kubernetes 对象。这些文件将包含描述其所需状态的 Kubernetes 对象的规范。
我们将使用这些文件来创建不同类型的对象:Services,它将确保运行我们容器的Pod保持可访问性;Deployments,其中将包含有关 Pod 所需状态的信息;一个PersistentVolumeClaim来提供存储,我们的数据库的数据; 在运行时注入的环境变量的ConfigMap;以及我们应用程序数据库用户和密码的Secret。其中一些定义将在kompose为我们创建的文件中,而其他定义将需要我们自己创建。
首先,我们需要修改docker-compose.yml文件中的一些定义以使用 Kubernetes。我们将在我们的app服务定义中包含对我们新建的应用程序映像的引用,并删除我们用于在 Compose 开发中运行应用程序容器的绑定安装、卷和其他命令。此外,我们将重新定义两个容器的重启策略,以符合Kubernetes 期望的行为。
如果您按照本教程中的步骤操作并compose-workflow使用 git签出分支,那么您docker-compose.yml的工作目录中应该有一个文件。
如果您没有docker-compose.yml,请务必访问本系列的上一个教程,使用 Docker Compose 容器化用于开发的 Ruby on Rails 应用程序,并将链接部分中的内容粘贴到新docker-compose.yml文件中。
使用nano或您喜欢的编辑器打开文件:
- nano docker-compose.yml
app应用程序服务的当前定义如下所示:
. . .
services:
app:
build:
context: .
dockerfile: Dockerfile
depends_on:
- database
- redis
ports:
- "3000:3000"
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
. . .
对您的服务定义进行以下编辑:
- 将
build:行替换为image: your_dockerhub_user/rails-kubernetes - 删除以下
context: ., 和dockerfile: Dockerfile行。 - 删除
volumes列表。
完成的服务定义现在将如下所示:
. . .
services:
app:
image: your_dockerhub_user/rails-kubernetes
depends_on:
- database
- redis
ports:
- "3000:3000"
env_file: .env
environment:
RAILS_ENV: development
. . .
接下来,向下滚动到database服务定义并进行以下编辑:
- 移除
- ./init.sql:/docker-entrypoint-initdb.d/init.sql音量线。我们将使用我们将在步骤 4 中创建的 Secret 将我们的POSTGRES_USER和的值传递POSTGRES_PASSWORD给数据库容器,而不是使用来自本地 SQL 文件的值。 - 添加一个
ports:部分,使 PostgreSQL 在 Kubernetes 集群中的端口 5432 上可用。 - 添加一个
environment:部分,其中的PGDATA变量指向/var/lib/postgresql/data. 当 PostgreSQL 被配置为使用块存储时,这个设置是必需的,因为数据库引擎希望在子目录中找到它的数据文件。
该database服务的定义应该是这样的,当你完成修改:
. . .
database:
image: postgres:12.1
volumes:
- db_data:/var/lib/postgresql/data
ports:
- "5432:5432"
environment:
PGDATA: /var/lib/postgresql/data/pgdata
. . .
接下来,redis通过添加ports:具有默认 6379 端口的部分来编辑服务定义以公开其默认 TCP端口。添加该ports:部分将使 Redis 在您的 Kubernetes 集群中可用。您编辑的redis服务应类似于以下内容:
. . .
redis:
image: redis:5.0.7
ports:
- "6379:6379"
编辑完redis文件的部分后,继续进行sidekiq服务定义。与app服务一样,您需要从构建本地 docker 镜像切换到从 Docker Hub 拉取。对您的sidekiq服务定义进行以下编辑:
- 将
build:行替换为image: your_dockerhub_user/rails-kubernetes - 删除以下
context: ., 和dockerfile: Dockerfile行。 - 删除
volumes列表。
. . .
sidekiq:
image: your_dockerhub_user/rails-kubernetes
depends_on:
- app
- database
- redis
env_file: .env
environment:
RAILS_ENV: development
entrypoint: ./entrypoints/sidekiq-entrypoint.sh
最后,在文件底部,从顶级密钥中删除gem_cache和node_modules卷volumes。密钥现在看起来像这样:
. . .
volumes:
db_data:
完成编辑后保存并关闭文件。
作为参考,您完成的docker-compose.yml文件应包含以下内容:
version: '3'
services:
app:
image: your_dockerhub_user/rails-kubernetes
depends_on:
- database
- redis
ports:
- "3000:3000"
env_file: .env
environment:
RAILS_ENV: development
database:
image: postgres:12.1
volumes:
- db_data:/var/lib/postgresql/data
ports:
- "5432:5432"
environment:
PGDATA: /var/lib/postgresql/data/pgdata
redis:
image: redis:5.0.7
ports:
- "6379:6379"
sidekiq:
image: your_dockerhub_user/rails-kubernetes
depends_on:
- app
- database
- redis
env_file: .env
environment:
RAILS_ENV: development
entrypoint: ./entrypoints/sidekiq-entrypoint.sh
volumes:
db_data:
在翻译我们的服务定义之前,我们需要编写.env用于kompose使用我们的非敏感信息创建 ConfigMap的文件。请参阅第2步的集装化与码头工人撰写的开发Rails应用程序的Ruby此文件的更详细的解释。
在该教程中,我们添加.env到我们的.gitignore文件中以确保它不会复制到版本控制。这意味着当我们在本教程的第 2 步中克隆rails-sidekiq 存储库时,它没有复制过来。因此,我们现在需要重新创建它。
创建文件:
- nano .env
kompose将使用此文件为我们的应用程序创建一个 ConfigMap。但是,app我们不会从Compose 文件中的服务定义中分配所有变量,而只会为 PostgreSQL 和 Redis 添加设置。我们在步骤 4 中手动创建 Secret 对象时,将分别分配数据库名称、用户名和密码。
将以下端口和数据库名称信息添加到.env文件中。如果您愿意,可以随意重命名您的数据库:
DATABASE_HOST=database
DATABASE_PORT=5432
REDIS_HOST=redis
REDIS_PORT=6379
完成编辑后保存并关闭文件。
您现在已准备好使用您的对象规范创建文件。kompose提供多种翻译资源的选项。你可以:
- 创建
yaml基于文件中的服务定义的docker-compose.yml文件kompose convert。 - 直接使用
kompose up. - 创建一个头盔与图表
kompose convert -c。
现在,我们将我们的服务定义转换为yaml文件,然后添加和修改kompose创建的文件。
yaml使用以下命令将您的服务定义转换为文件:
- kompose convert
运行此命令后,kompose 将输出有关它已创建的文件的信息:
OutputINFO Kubernetes file "app-service.yaml" created
INFO Kubernetes file "database-service.yaml" created
INFO Kubernetes file "redis-service.yaml" created
INFO Kubernetes file "app-deployment.yaml" created
INFO Kubernetes file "env-configmap.yaml" created
INFO Kubernetes file "database-deployment.yaml" created
INFO Kubernetes file "db-data-persistentvolumeclaim.yaml" created
INFO Kubernetes file "redis-deployment.yaml" created
INFO Kubernetes file "sidekiq-deployment.yaml" created
其中包括yaml具有 Rails 应用程序服务、部署和 ConfigMap 以及db-dataPersistentVolumeClaim 和 PostgreSQL 数据库部署规范的文件。还包括分别用于 Redis 和 Sidekiq 的文件。
要将这些清单放在 Rails 项目的主目录之外,请创建一个名为的新目录k8s-manifests,然后使用该mv命令将生成的文件移动到其中:
- mkdir k8s-manifests
- mv *.yaml k8s-manifests
最后,cd进入k8s-manifests目录。从现在开始,我们将在此目录中工作以保持整洁:
- cd k8s-manifests
这些文件是一个很好的起点,但为了使我们的应用程序的功能与使用 Docker Compose 容器化用于开发的 Ruby on Rails 应用程序中描述的设置相匹配,我们需要对kompose生成的文件进行一些添加和更改。
第 4 步 – 创建 Kubernetes Secret
为了让我们的应用程序以我们期望的方式运行,我们需要对kompose创建的文件进行一些修改。这些更改中的第一个将为我们的数据库用户和密码生成一个 Secret,并将其添加到我们的应用程序和数据库部署中。Kubernetes 提供了两种使用环境变量的方法:ConfigMaps 和 Secrets。kompose已经使用我们在.env文件中包含的非机密信息创建了一个 ConfigMap ,因此我们现在将使用我们的机密信息创建一个 Secret:我们的数据库名称、用户名和密码。
手动创建 Secret 的第一步是将数据转换为base64,这是一种允许您统一传输数据(包括二进制数据)的编码方案。
首先将数据库名称转换为base64编码的数据:
- echo -n 'your_database_name' | base64
记下编码值。
接下来转换您的数据库用户名:
- echo -n 'your_database_username' | base64
再次记录您在输出中看到的值。
最后,转换您的密码:
- echo -n 'your_database_password' | base64
还要注意此处输出中的值。
为 Secret 打开一个文件:
- nano secret.yaml
注意: Kubernetes 对象通常使用YAML定义,它严格禁止制表符并需要两个空格进行缩进。如果您想检查你的任何格式yaml的文件,你可以使用棉短绒或使用测试语法的正确性kubectl create与--dry-run和--validate标志:
- kubectl create -f your_yaml_file.yaml --dry-run --validate=true
通常,在使用kubectl.
将以下代码添加到文件中以创建一个 Secret,该 Secret 将定义您的 DATABASE_NAME,DATABASE_USER并DATABASE_PASSWORD使用您刚刚创建的编码值。请务必将此处突出显示的占位符值替换为您编码的数据库名称、用户名和密码:
apiVersion: v1
kind: Secret
metadata:
name: database-secret
data:
DATABASE_NAME: your_database_name
DATABASE_PASSWORD: your_encoded_password
DATABASE_USER: your_encoded_username
我们已将 Secret 对象命名为database-secret,但您可以随意命名它。
这些秘密与 Rails 应用程序一起使用,以便它可以连接到 PostgreSQL。但是,数据库本身需要使用这些相同的值进行初始化。所以接下来,复制三行并将它们粘贴到文件的末尾。编辑最后三行并将DATABASE每个变量的前缀更改为POSTGRES. 最后将POSTGRES_NAME变量更改为 read POSTGRES_DB。
您的最终secret.yaml文件应包含以下内容:
apiVersion: v1
kind: Secret
metadata:
name: database-secret
data:
DATABASE_NAME: your_database_name
DATABASE_PASSWORD: your_encoded_password
DATABASE_USER: your_encoded_username
POSTGRES_DB: your_database_name
POSTGRES_PASSWORD: your_encoded_password
POSTGRES_USER: your_encoded_username
完成编辑后保存并关闭此文件。正如您对.env文件所做的那样,请确保添加secret.yaml到您的.gitignore文件中以使其不受版本控制。
随着secret.yaml写的,我们的下一步将是确保我们的应用程序和数据库部署都使用值,我们添加到文件中。让我们首先向我们的应用程序部署添加对 Secret 的引用。
打开名为的文件app-deployment.yaml:
- nano app-deployment.yaml
该文件的容器规范包括在env密钥下定义的以下环境变量:
apiVersion: apps/v1
kind: Deployment
. . .
spec:
containers:
- env:
- name: DATABASE_HOST
valueFrom:
configMapKeyRef:
key: DATABASE_HOST
name: env
- name: DATABASE_PORT
valueFrom:
configMapKeyRef:
key: DATABASE_PORT
name: env
- name: RAILS_ENV
value: development
- name: REDIS_HOST
valueFrom:
configMapKeyRef:
key: REDIS_HOST
name: env
- name: REDIS_PORT
valueFrom:
configMapKeyRef:
key: REDIS_PORT
name: env
. . .
我们需要添加对 Secret 的引用,以便我们的应用程序可以访问这些值。不像现有值那样包含configMapKeyRef指向我们的envConfigMap 的secretKeyRef键,我们将包含一个指向我们database-secret密钥中的值的键。
在- name: REDIS_PORT变量部分后添加以下 Secret 引用:
. . .
spec:
containers:
- env:
. . .
- name: REDIS_PORT
valueFrom:
configMapKeyRef:
key: REDIS_PORT
name: env
- name: DATABASE_NAME
valueFrom:
secretKeyRef:
name: database-secret
key: DATABASE_NAME
- name: DATABASE_PASSWORD
valueFrom:
secretKeyRef:
name: database-secret
key: DATABASE_PASSWORD
- name: DATABASE_USER
valueFrom:
secretKeyRef:
name: database-secret
key: DATABASE_USER
. . .
完成编辑后保存并关闭文件。与您的secrets.yaml文件一样,请务必使用以下方法验证您的编辑,kubectl以确保没有空格、制表符和缩进问题:
- kubectl create -f app-deployment.yaml --dry-run --validate=true
Outputdeployment.apps/app created (dry run)
接下来,我们将向database-deployment.yaml文件添加相同的值。
打开文件进行编辑:
- nano database-deployment.yaml
在此文件中,我们将为以下变量键添加对 Secret 的引用:POSTGRES_DB、POSTGRES_USER和POSTGRES_PASSWORD。该postgres图像使这些变量可用,以便您可以修改数据库实例的初始化。这将POSTGRES_DB创建一个在容器启动时可用的默认数据库。在POSTGRES_USER和POSTGRES_PASSWORD一起创建可以访问创建的数据库特权用户。
使用这些值意味着我们创建的用户可以访问 PostgreSQL 中该角色的所有管理和操作权限。在生产中工作时,您需要创建一个具有适当范围权限的专用应用程序用户。
在POSTGRES_DB,POSTGRES_USER和POSTGRES_PASSWORD变量下,添加对 Secret 值的引用:
apiVersion: apps/v1
kind: Deployment
. . .
spec:
containers:
- env:
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
- name: POSTGRES_DB
valueFrom:
secretKeyRef:
name: database-secret
key: POSTGRES_DB
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: database-secret
key: POSTGRES_PASSWORD
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: database-secret
key: POSTGRES_USER
. . .
完成编辑后保存并关闭文件。再次务必使用lint的编辑过的文件kubectl与--dry-run --validate=true参数。
设置好 Secret 后,您可以继续创建数据库服务并确保您的应用程序容器仅在数据库完全设置和初始化后才尝试连接到数据库。
步骤 5 — 修改 PersistentVolumeClaim 并公开应用程序前端
在运行我们的应用程序之前,我们将进行两项最终更改,以确保我们的数据库存储将被正确配置,并且我们可以使用 LoadBalancer 公开我们的应用程序前端。
首先,让我们修改storage resourcekompose 为我们创建的 PersistentVolumeClaim 中定义的。这个 Claim 允许我们动态地提供存储来管理我们应用程序的状态。
要使用 PersistentVolumeClaims,您必须创建并配置StorageClass以供应存储资源。在我们的例子中,因为我们正在使用DigitalOcean Kubernetes,我们的默认 StorageClassprovisioner设置为dobs.csi.digitalocean.com— DigitalOcean Block Storage。
我们可以通过键入以下内容来检查:
- kubectl get storageclass
如果您正在使用 DigitalOcean 集群,您将看到以下输出:
OutputNAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
do-block-storage (default) dobs.csi.digitalocean.com Delete Immediate true 76m
如果您不使用 DigitalOcean 集群,则需要创建一个 StorageClass 并配置provisioner您选择的一个。有关如何执行此操作的详细信息,请参阅官方文档。
当kompose创建db-data-persistentvolumeclaim.yaml,它设置storage resource的大小不符合我们的最低规格要求provisioner。因此,我们需要修改我们的 PersistentVolumeClaim 以使用最小可行的 DigitalOcean 块存储单元:1GB。请随意修改它以满足您的存储要求。
打开db-data-persistentvolumeclaim.yaml:
- nano db-data-persistentvolumeclaim.yaml
将storage值替换为1Gi:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
labels:
io.kompose.service: db-data
name: db-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
status: {}
另请注意accessMode:ReadWriteOnce表示作为此声明的结果提供的卷只能由单个节点读写。有关不同访问模式的更多信息,请参阅文档。
完成后保存并关闭文件。
接下来,打开app-service.yaml:
- nano app-service.yaml
我们将使用DigitalOcean Load Balancer 在外部公开此服务。如果您没有使用 DigitalOcean 集群,请查阅您的云提供商的相关文档以获取有关其负载均衡器的信息。或者,您可以按照官方Kubernetes 文档使用 设置高可用集群kubeadm,但在这种情况下,您将无法使用 PersistentVolumeClaims 来配置存储。
在 Service 规范中,指定LoadBalancer为 Service type:
apiVersion: v1
kind: Service
. . .
spec:
type: LoadBalancer
ports:
. . .
当我们创建app服务时,将自动创建一个负载均衡器,为我们提供一个外部 IP,我们可以在其中访问我们的应用程序。
完成编辑后保存并关闭文件。
准备好所有文件后,我们已准备好启动和测试应用程序。
注意:
如果您想将编辑过的 Kubernetes 清单与一组参考文件进行比较,以确保您的更改与本教程相符,配套的 Github 存储库包含一组经过测试的清单。您可以单独比较每个文件,也可以切换本地 git 分支以使用该kubernetes-workflow分支。
如果您选择切换分支,请务必将您的secrets.yaml文件复制到新的签出版本中,因为我们.gitignore在本教程的前面添加了它。
第 6 步 – 启动和访问应用程序
是时候创建我们的 Kubernetes 对象并测试我们的应用程序是否按预期工作。
要创建我们定义的对象,我们将使用kubectl create与-f标志,这将允许我们指定的文件kompose为我们创造,我们用写的文件一起。运行以下命令以创建 Rails 应用程序和 PostgreSQL 数据库、Redis 缓存、Sidekiq 服务和部署,以及您的 Secret、ConfigMap 和 PersistentVolumeClaim:
- kubectl create -f app-deployment.yaml,app-service.yaml,database-deployment.yaml,database-service.yaml,db-data-persistentvolumeclaim.yaml,env-configmap.yaml,redis-deployment.yaml,redis-service.yaml,secret.yaml,sidekiq-deployment.yaml
您会收到以下输出,表明对象已创建:
Outputdeployment.apps/app created
service/app created
deployment.apps/database created
service/database created
persistentvolumeclaim/db-data created
configmap/env created
deployment.apps/redis created
service/redis created
secret/database-secret created
deployment.apps/sidekiq created
要检查您的 Pod 是否正在运行,请键入:
- kubectl get pods
您不需要在此处指定命名空间,因为我们已经在default命名空间中创建了我们的对象。如果您正在使用多个命名空间,请确保-n在运行此kubectl create命令时包含该标志以及命名空间的名称。
当您的database容器启动时,您将看到类似于以下内容的输出(状态将为Pending或ContainerCreating):
OutputNAME READY STATUS RESTARTS AGE
app-854d645fb9-9hv7w 1/1 Running 0 23s
database-c77d55fbb-bmfm8 0/1 Pending 0 23s
redis-7d65467b4d-9hcxk 1/1 Running 0 23s
sidekiq-867f6c9c57-mcwks 1/1 Running 0 23s
启动数据库容器后,您将得到如下输出:
OutputNAME READY STATUS RESTARTS AGE
app-854d645fb9-9hv7w 1/1 Running 0 30s
database-c77d55fbb-bmfm8 1/1 Running 0 30s
redis-7d65467b4d-9hcxk 1/1 Running 0 30s
sidekiq-867f6c9c57-mcwks 1/1 Running 0 30s
该Running STATUS指示您的豆荚,势必节点和与这些荚相关的容器正在运行。READY指示 Pod 中正在运行的容器数量。有关更多信息,请参阅有关 Pod 生命周期的文档。
注意:
如果您在STATUS列中看到意外阶段,请记住您可以使用以下命令对 Pod 进行故障排除:
- kubectl describe pods your_pod
- kubectl logs your_pod
现在您的应用程序已启动并运行,所需的最后一步是运行 Rails 的数据库迁移。此步骤将为演示应用程序将模式加载到 PostgreSQL 数据库中。
要运行挂起的迁移,您将exec进入正在运行的应用程序 pod,然后调用该rake db:migrate命令。
首先,使用以下命令找到应用程序 pod 的名称:
- kubectl get pods
找到与您的应用程序对应的 pod,如以下输出中突出显示的 pod 名称:
OutputNAME READY STATUS RESTARTS AGE
app-854d645fb9-9hv7w 1/1 Running 0 30s
database-c77d55fbb-bmfm8 1/1 Running 0 30s
redis-7d65467b4d-9hcxk 1/1 Running 0 30s
sidekiq-867f6c9c57-mcwks 1/1 Running 0 30s
记下该 pod 名称后,您现在可以运行该kubectl exec命令来完成数据库迁移步骤。
使用以下命令运行迁移:
- kubectl exec your_app_pod_name -- rake db:migrate
您应该会收到类似于以下内容的输出,这表明数据库架构已加载:
Output== 20190927142853 CreateSharks: migrating =====================================
-- create_table(:sharks)
-> 0.0190s
== 20190927142853 CreateSharks: migrated (0.0208s) ============================
== 20190927143639 CreatePosts: migrating ======================================
-- create_table(:posts)
-> 0.0398s
== 20190927143639 CreatePosts: migrated (0.0421s) =============================
== 20191120132043 CreateEndangereds: migrating ================================
-- create_table(:endangereds)
-> 0.8359s
== 20191120132043 CreateEndangereds: migrated (0.8367s) =======================
运行容器并加载数据后,您现在可以访问该应用程序。要获取appLoadBalancer的 IP ,请键入:
- kubectl get svc
您将收到如下输出:
OutputNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
app LoadBalancer 10.245.73.142 your_lb_ip 3000:31186/TCP 21m
database ClusterIP 10.245.155.87 <none> 5432/TCP 21m
kubernetes ClusterIP 10.245.0.1 <none> 443/TCP 21m
redis ClusterIP 10.245.119.67 <none> 6379/TCP 21m
在EXTERNAL_IP与相关的app服务,您可以访问应用程序的IP地址。如果您<pending>在EXTERNAL_IP列中看到状态,则表示您的负载均衡器仍在创建中。
在该列中看到 IP 后,请在浏览器中导航到它:。http://your_lb_ip:3000
您应该会看到以下登录页面:
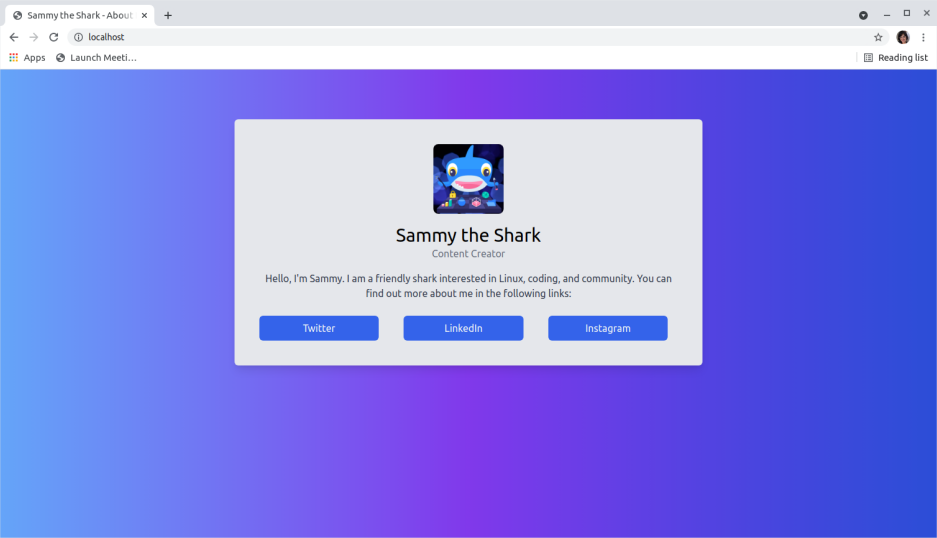
单击获取鲨鱼信息按钮。您将有一个带有按钮的页面来创建一条新鲨鱼:
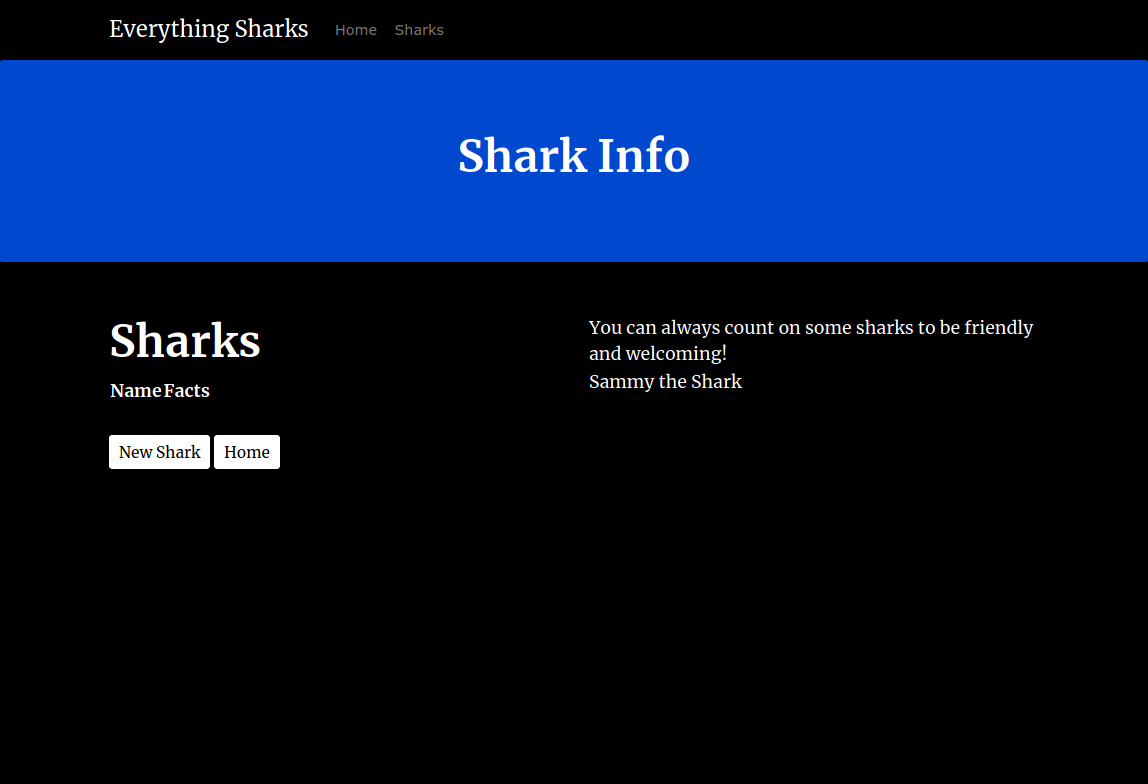
Click it and when prompted, enter the username and password from earlier in the tutorial series. If you did not change these values then the defaults are sammy and shark respectively.
In the form, add a shark of your choosing. To demonstrate, we will add Megalodon Shark to the Shark Name field, and Ancient to the Shark Character field:
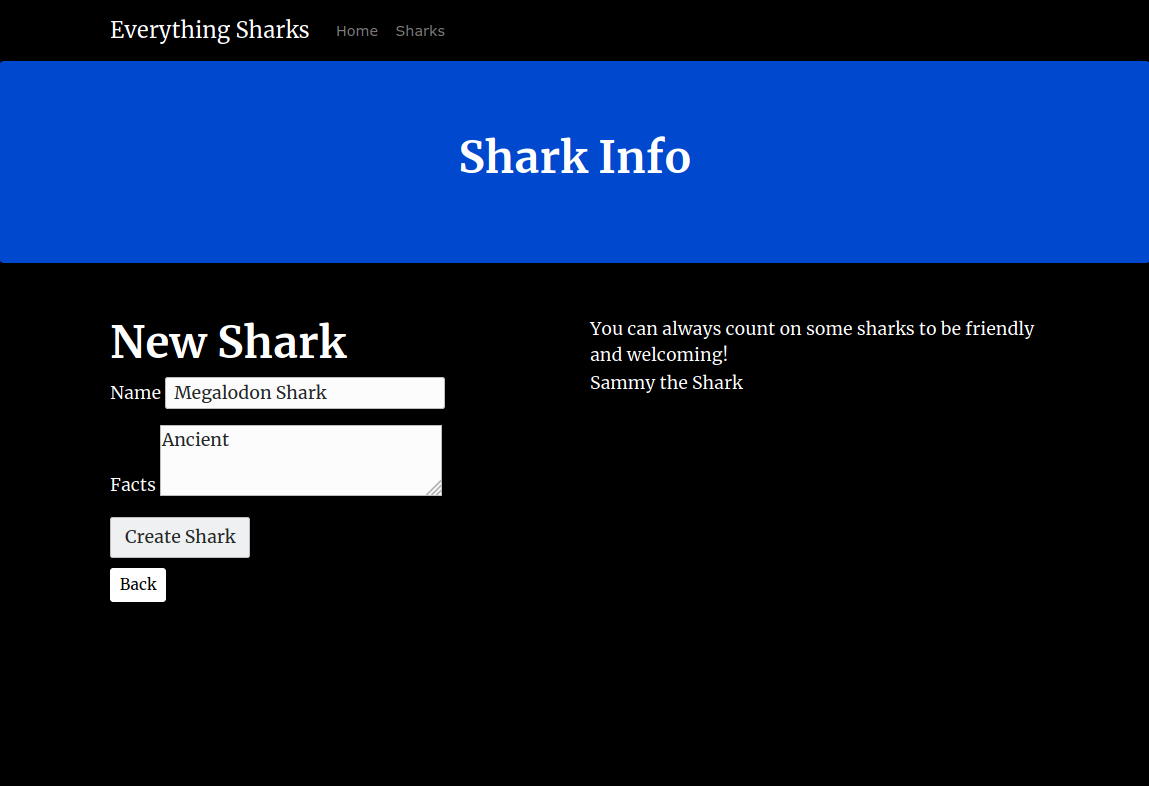
Click on the Submit button. You will see a page with this shark information displayed back to you:
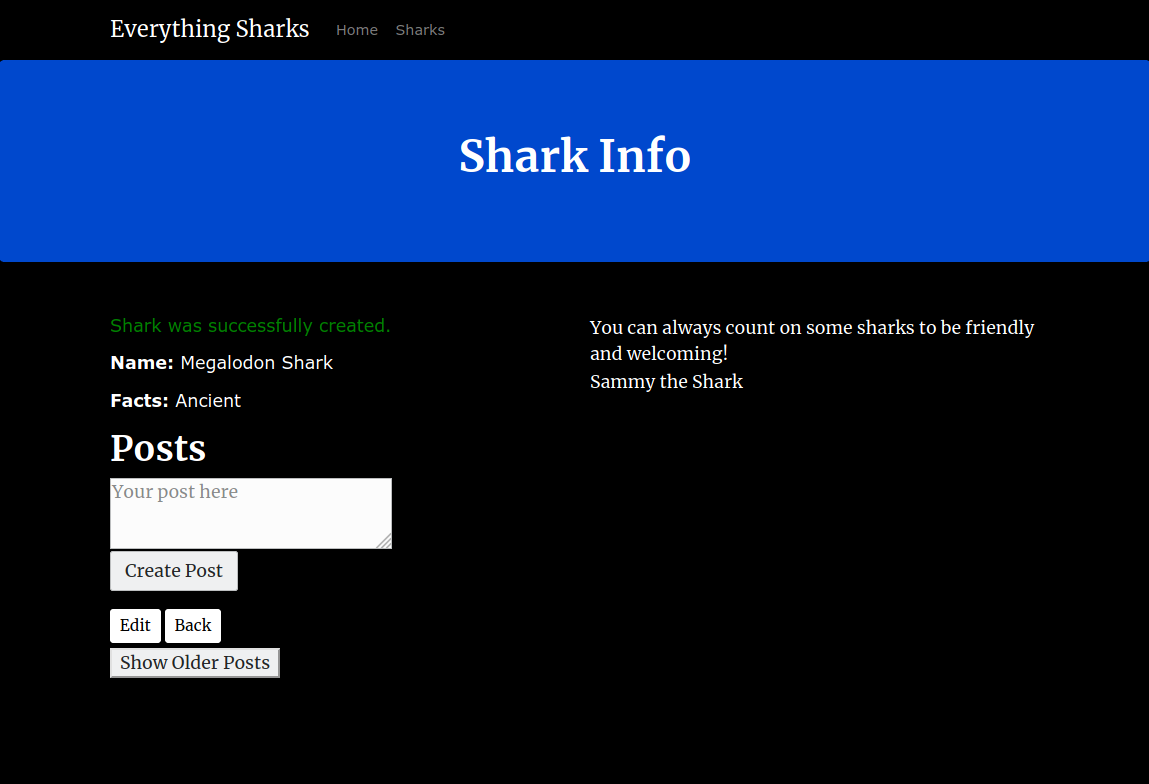
You now have a single instance setup of a Rails application with a PostgreSQL database running on a Kubernetes cluster. You also have a Redis cache and a Sidekiq worker to process data that users submit.
Conclusion
The files you have created in this tutorial are a good starting point to build from as you move toward production. As you develop your application, you can work on implementing the following:
- Centralized logging and monitoring. Please see the relevant discussion in Modernizing Applications for Kubernetes for a general overview. You can also look at How To Set Up an Elasticsearch, Fluentd and Kibana (EFK) Logging Stack on Kubernetes to learn how to set up a logging stack with Elasticsearch, Fluentd, and Kibana. Also check out An Introduction to Service Meshes for information about how service meshes like Istio implement this functionality.
- Ingress Resources to route traffic to your cluster. This is a good alternative to a LoadBalancer in cases where you are running multiple Services, which each require their own LoadBalancer, or where you would like to implement application-level routing strategies (A/B & canary tests, for example). For more information, check out How to Set Up an Nginx Ingress with Cert-Manager on DigitalOcean Kubernetes and the related discussion of routing in the service mesh context in An Introduction to Service Meshes.
- Kubernetes 对象的备份策略。有关使用Velero和 DigitalOcean 的 Kubernetes 产品实施备份的指南,请参阅如何使用 Velero 在 DigitalOcean 上备份和恢复 Kubernetes 集群。
