介绍
Nagios支持对“抖动”的host和服务进行可选检测。当服务或host更改状态的频率过高时,就会发生抖动,从而引发大量的问题和恢复通知。抖动可能表示配置问题(即,阈值设置得太低),服务故障或实际的网络问题。
抖动检测如何工作
在开始之前,我先说一下扑动检测很难实现。如何准确地确定对于特定host或服务的状态更改而言,“过于频繁”是什么意思?当我刚开始考虑实施抖动检测时,我试图找到一些有关如何/应该检测抖动的信息。我找不到有关其他人正在使用的信息(他们在使用任何信息吗?),所以我决定接受我认为合理的解决方案…
每当Nagios检查host或服务的状态时,它都会检查其启动或停止抖动。它通过以下方式做到这一点:
- 存储host或服务的最后21个检查的结果
- 分析历史检查结果并确定状态更改/转换发生的位置
- 使用状态转换来确定host或服务的状态变化百分比值(变化的度量)
- 将状态变化百分比与低和高拍动阈值进行比较
当host或服务的百分比状态变化首次超过高波动阈值时,便确定该host或服务已开始波动。
当host或服务的百分比状态低于低漂移阈值(假设它先前曾发生漂移)时,将确定该host或服务已停止漂移。
例
让我们更详细地描述抖动检测如何与服务一起工作…
下图显示了最近21次服务检查中服务状态的时间顺序历史记录。OK状态显示为绿色,WARNING状态显示为黄色,CRITICAL状态显示为红色,UNKNOWN状态显示为橙色。
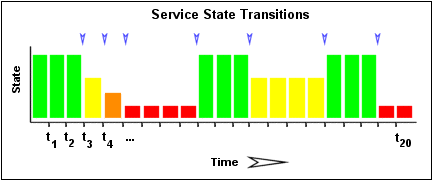
检查历史服务检查结果,以确定状态更改/转换发生的位置。当存档状态不同于按时间顺序在其之前的存档状态时,就会发生状态更改。由于我们将最后21个服务检查的结果保存在数组中,因此最多可能有20个状态更改。在此示例中,有7种状态更改,由上图中的蓝色箭头指示。
抖动检测逻辑使用状态更改来确定服务的总体状态更改百分比。这是服务波动/变化的度量。永不更改状态的服务的状态更改值为0%,而每次检查状态更改的服务的状态更改值为100%。大多数服务之间的状态变化百分比会有所不同。
在计算服务的状态变化百分比时,与较旧的状态变化相比,抖动检测算法将赋予新的状态变化更多的权重。具体地说,抖动检测例程当前被设计为使最新的可能状态变化比最旧的可能状态承载50%的重量。下图显示了在计算特定服务的总体状态变化百分比或总状态变化百分比时,相比于较早的状态变化,如何赋予最新状态变化更大的权重。
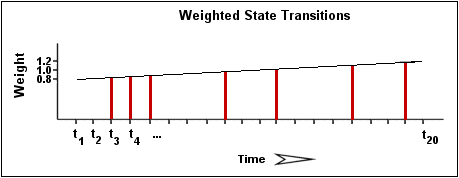
使用上面的图像,让我们计算服务状态变化百分比。您会注意到总共有7种状态变化(在t 3,t 4,t 5,t 9,t 12,t 16和t 19)。如果不随时间推移对状态变化进行任何加权,这将使我们的状态变化总数达到35%:
(观察到的7个状态更改/可能的20个状态更改)* 100 = 35%
由于抖动检测逻辑将为较新的状态变化提供比较早的状态变化更高的速率,因此在此示例中,实际计算出的状态变化百分比将略小于35%。假设状态变化的加权百分比为31%…
然后将计算出的服务状态变化百分比(31%)与波动阈值进行比较,以了解应该发生的情况:
- 如果该服务以前未发生过波动,并且31%等于或大于较高的波动阈值,则Nagios Core认为该服务才刚刚开始波动。
- 如果该服务以前曾发生过振荡,并且31%低于低振荡阈值,则Nagios Core认为该服务刚刚停止了振荡。
如果这两个条件均不满足,则抖动检测逻辑将不会对该服务执行任何其他操作,因为该服务当前未抖动或仍在抖动。
服务抖动检测
Nagios Core会检查服务被主动(或被动)检查时服务是否在振荡。
服务的拍动检测逻辑按上面的示例所述工作。
host的抖动检测
host抖动检测与服务抖动检测的工作方式相似,但有一个重要区别:Nagios Core将尝试检查host是否在以下情况发生扇动:
- (主动或被动)检查host
- 有时,当检查与该host关联的服务时。更具体地说,当自上次执行抖动检测以来至少经过了x量的时间时,其中x等于与host关联的所有服务的平均检查间隔。
为什么要这样做?对于服务,我们知道连续的抖动检测例程之间的最短时间将等于服务检查间隔。但是,您可能不会定期监控host,因此可能没有在抖动检测逻辑中使用的host检查间隔。同样,有意义的是,检查服务应计入检测host抖动。服务毕竟是host的属性或与host相关的事物。无论如何,这是我可以用来确定在host上执行皮瓣检测的频率的最佳方法,所以就可以了。
抖动检测阈值
Nagios Core使用几个变量来确定百分比状态变化阈值用于抖动检测。对于host和服务,都可以配置全局上限和下限阈值以及特定于host或服务的阈值。如果您不指定特定于host或服务的阈值,则Nagios Core将使用全局阈值进行抖动检测。
下表显示了全局和特定于host或服务的变量,这些变量控制抖动检测中使用的各种阈值。
| 对象类型 | 全局变量 | 特定于对象的变量 |
|---|---|---|
| 主办 | low_host_flap_threshold high_host_flap_threshold | low_flap_threshold high_flap_threshold |
| 服务 | low_service_flap_threshold high_service_flap_threshold | low_flap_threshold high_flap_threshold |
抖动检测所使用的状态
通常,Nagios Core会跟踪host或服务的最后21次检查的结果,而不管检查结果(host/服务状态)如何,以用于抖动检测逻辑。
提示:通过在host或服务定义中使用弗拉普_检测_选项指令,可以将某些host或服务状态排除在弗拉普检测逻辑之外。该指令允许您指定要用于抖动检测的host或服务状态(即“ UP”,“ DOWN”,“ OK”,“ CRITICAL”)。如果您不使用此伪指令,则所有host或服务状态都将在抖动检测中使用。
抖动处理
首次检测到服务或host出现抖动时,Nagios Core将:
- 记录一条消息,指出服务或host正在发生抖动。
- 向host或服务添加非持久注释,以表明它正在抖动。
- 向相应的联系人发送host或服务的“拍打开始”通知。
- 禁止服务或host的其他通知(这是通知逻辑中的过滤器之一)。
当服务或host停止抖动时,Nagios Core将:
- 记录一条消息,指示服务或host已停止抖动。
- 删除开始抖动时最初添加到服务或host的注释。
- 向相应的联系人发送host或服务的“拍击停止”通知。
- 删除有关服务或host的通知的块(通知仍将绑定到常规通知逻辑)。
启用抖动检测
为了在Nagios Core中启用抖动检测功能,您需要:
- 设置enable_flap_detection指令设置为1。
- 在host中设置弗拉普_检测_启用指令,服务定义设置为1。
如果要全局禁用抖动检测,请将enable_flap_detection指令设置为0。
如果只想禁用几个host或服务的抖动检测,请在host和/或服务定义中使用flap_detection_enabled指令。
