MongoDB – 快速指南
MongoDB – 快速指南
MongoDB – 概述
MongoDB 是一个跨平台、面向文档的数据库,提供高性能、高可用性和易于扩展。MongoDB 致力于集合和文档的概念。
数据库
数据库是集合的物理容器。每个数据库在文件系统上都有自己的一组文件。单个 MongoDB 服务器通常具有多个数据库。
收藏
集合是一组 MongoDB 文档。它相当于一个 RDBMS 表。集合存在于单个数据库中。集合不强制执行模式。集合中的文档可以有不同的字段。通常,集合中的所有文档都具有相似或相关的目的。
文档
文档是一组键值对。文档具有动态架构。动态模式意味着同一集合中的文档不需要具有相同的字段集或结构,并且集合文档中的公共字段可能包含不同类型的数据。
下表显示了 RDBMS 术语与 MongoDB 的关系。
| RDBMS | MongoDB |
|---|---|
| Database | 数据库 |
| Table | 收藏 |
| Tuple/Row | 文档 |
| column | 场地 |
| Table Join | 嵌入文件 |
| Primary Key | 主键(mongodb自身提供的默认键_id) |
| Database Server and Client | |
| Mysqld/Oracle | 蒙哥 |
| mysql/sqlplus | 蒙戈 |
样本文件
以下示例显示了一个博客站点的文档结构,它只是一个逗号分隔的键值对。
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}
_id是一个 12 字节的十六进制数,它确保每个文档的唯一性。您可以在插入文档时提供 _id。如果您不提供,那么 MongoDB 会为每个文档提供一个唯一的 ID。这 12 个字节的前 4 个字节用于当前时间戳,接下来的 3 个字节用于机器 ID,接下来的 2 个字节用于 MongoDB 服务器的进程 ID,其余 3 个字节是简单的增量值。
MongoDB – 优势
任何关系数据库都有一个典型的模式设计,显示表的数量和这些表之间的关系。而在 MongoDB 中,没有关系的概念。
MongoDB 相对于 RDBMS 的优势
-
Schema less – MongoDB 是一个文档数据库,其中一个集合保存不同的文档。文档的字段数、内容和大小可能因一个文档而异。
-
单个对象的结构清晰。
-
没有复杂的连接。
-
深度查询能力。MongoDB 支持使用与 SQL 几乎一样强大的基于文档的查询语言对文档进行动态查询。
-
调音。
-
易于扩展– MongoDB 易于扩展。
-
不需要将应用程序对象转换/映射到数据库对象。
-
使用内部存储器来存储(窗口化)工作集,从而能够更快地访问数据。
为什么要使用 MongoDB?
-
面向文档的存储– 数据以 JSON 样式文档的形式存储。
-
任何属性的索引
-
复制和高可用性
-
自动分片
-
丰富的查询
-
快速就地更新
-
MongoDB 的专业支持
在哪里使用 MongoDB?
- 大数据
- 内容管理和交付
- 移动和社会基础设施
- 用户数据管理
- 数据中心
MongoDB – 环境
现在让我们看看如何在 Windows 上安装 MongoDB。
在 Windows 上安装 MongoDB
要在 Windows 上安装 MongoDB,首先从https://www.mongodb.org/downloads下载最新版本的 MongoDB 。确保根据您的 Windows 版本获得正确版本的 MongoDB。要获取您的 Windows 版本,请打开命令提示符并执行以下命令。
C:\>wmic os get osarchitecture OSArchitecture 64-bit C:\>
32 位版本的 MongoDB 仅支持小于 2GB 的数据库,仅适用于测试和评估目的。
现在将下载的文件解压缩到 c:\ 驱动器或任何其他位置。确保解压文件夹的名称是 mongodb-win32-i386-[version] 或 mongodb-win32-x86_64-[version]。这里[version]是MongoDB下载的版本。
接下来,打开命令提示符并运行以下命令。
C:\>move mongodb-win64-* mongodb 1 dir(s) moved. C:\>
如果您在不同的位置提取了 MongoDB,请使用命令cd FOLDER/DIR转到该路径,然后运行上述给定的过程。
MongoDB 需要一个数据文件夹来存储其文件。MongoDB 数据目录的默认位置是 c:\data\db。因此,您需要使用命令提示符创建此文件夹。执行以下命令序列。
C:\>md data C:\md data\db
如果您必须将 MongoDB 安装在不同的位置,那么您需要通过在mongod.exe 中设置路径dbpath来指定\data\db的备用路径。同样,发出以下命令。
在命令提示符中,导航到 MongoDB 安装文件夹中的 bin 目录。假设我的安装文件夹是D:\set up\mongodb
C:\Users\XYZ>d: D:\>cd "set up" D:\set up>cd mongodb D:\set up\mongodb>cd bin D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"
这将在控制台输出上显示等待连接消息,这表明 mongod.exe 进程正在成功运行。
现在要运行 MongoDB,您需要打开另一个命令提示符并发出以下命令。
D:\set up\mongodb\bin>mongo.exe
MongoDB shell version: 2.4.6
connecting to: test
>db.test.save( { a: 1 } )
>db.test.find()
{ "_id" : ObjectId(5879b0f65a56a454), "a" : 1 }
>
这将表明 MongoDB 已安装并成功运行。下次运行 MongoDB 时,您只需发出命令。
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data" D:\set up\mongodb\bin>mongo.exe
在 Ubuntu 上安装 MongoDB
运行以下命令导入 MongoDB 公共 GPG 密钥 –
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
使用以下命令创建 /etc/apt/sources.list.d/mongodb.list 文件。
echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen' | sudo tee /etc/apt/sources.list.d/mongodb.list
现在发出以下命令来更新存储库 –
sudo apt-get update
接下来使用以下命令安装 MongoDB –
apt-get install mongodb-10gen = 2.2.3
在上面的安装中,2.2.3是目前发布的MongoDB版本。确保始终安装最新版本。至此MongoDB安装成功。
启动MongoDB
sudo service mongodb start
停止 MongoDB
sudo service mongodb stop
重启MongoDB
sudo service mongodb restart
要使用 MongoDB,请运行以下命令。
mongo
这将使您连接到正在运行的 MongoDB 实例。
MongoDB 帮助
要获取命令列表,请在 MongoDB 客户端中键入db.help()。这将为您提供一个命令列表,如下面的屏幕截图所示。
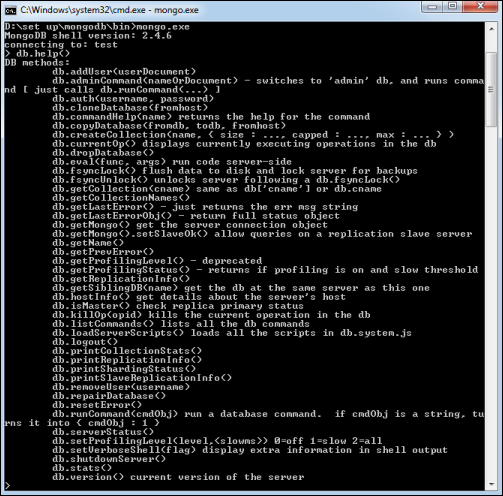
MongoDB 统计
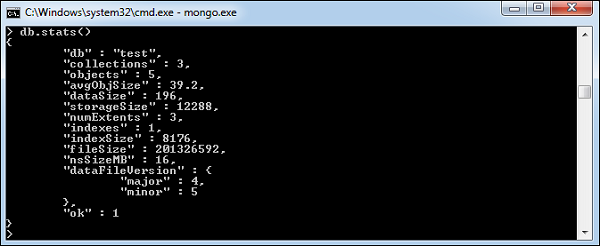
要获取有关 MongoDB 服务器的统计信息,请在 MongoDB 客户端中键入命令db.stats()。这将显示数据库名称、集合数量和数据库中的文档。命令的输出显示在以下屏幕截图中。
MongoDB – 数据建模
MongoDB 中的数据在同一个集合中有一个灵活的 schema.documents。它们不需要具有相同的一组字段或结构,并且集合文档中的公共字段可能包含不同类型的数据。
在 MongoDB 中设计 Schema 时的一些注意事项
-
根据用户要求设计您的架构。
-
如果您将一起使用对象,请将它们合并到一个文档中。否则将它们分开(但确保不需要连接)。
-
复制数据(但有限),因为与计算时间相比,磁盘空间便宜。
-
在写入时加入,而不是在读取时加入。
-
针对最常见的用例优化您的架构。
-
在模式中进行复杂的聚合。
例子
假设客户需要为他的博客/网站进行数据库设计,并查看 RDBMS 和 MongoDB 模式设计之间的差异。网站有以下要求。
- 每个帖子都有唯一的标题、描述和网址。
- 每篇文章都可以有一个或多个标签。
- 每个帖子都有其发布者的名称和喜欢的总数。
- 每个帖子都有用户给出的评论以及他们的姓名、消息、数据时间和喜欢。
- 在每个帖子上,可以有零个或多个评论。
在 RDBMS 模式中,针对上述要求的设计将至少包含三个表。
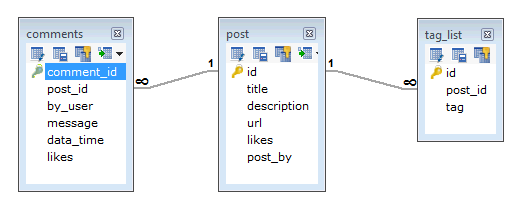
在 MongoDB 模式中,设计将有一个集合帖子和以下结构 –
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}
因此,在显示数据时,在 RDBMS 中您需要连接三个表,而在 MongoDB 中,数据将仅显示来自一个集合。
MongoDB – 创建数据库
在本章中,我们将看到如何在 MongoDB 中创建数据库。
使用命令
MongoDB使用 DATABASE_NAME用于创建数据库。如果不存在,该命令将创建一个新数据库,否则将返回现有数据库。
句法
使用 DATABASE语句的基本语法如下 –
use DATABASE_NAME
例子
如果要使用名称为<mydb>的数据库,则使用 DATABASE语句如下 –
>use mydb switched to db mydb
要检查您当前选择的数据库,请使用命令db
>db mydb
如果要检查数据库列表,请使用命令show dbs。
>show dbs local 0.78125GB test 0.23012GB
您创建的数据库 (mydb) 不在列表中。要显示数据库,您需要至少插入一个文档。
>db.movie.insert({"name":"tutorials point"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
在 MongoDB 中默认数据库是 test。如果您没有创建任何数据库,则集合将存储在测试数据库中。
MongoDB – 删除数据库
在本章中,我们将看到如何使用 MongoDB 命令删除数据库。
dropDatabase() 方法
MongoDB db.dropDatabase()命令用于删除现有数据库。
句法
dropDatabase()命令的基本语法如下 –
db.dropDatabase()
这将删除选定的数据库。如果您没有选择任何数据库,那么它将删除默认的“test”数据库。
例子
首先,使用命令show dbs检查可用数据库的列表。
>show dbs local 0.78125GB mydb 0.23012GB test 0.23012GB >
如果要删除新数据库<mydb>,则dropDatabase()命令如下 –
>use mydb
switched to db mydb
>db.dropDatabase()
>{ "dropped" : "mydb", "ok" : 1 }
>
现在检查数据库列表。
>show dbs local 0.78125GB test 0.23012GB >
MongoDB – 创建集合
在本章中,我们将看到如何使用 MongoDB 创建集合。
createCollection() 方法
MongoDB db.createCollection(name, options)用于创建集合。
句法
createCollection()命令的基本语法如下 –
db.createCollection(name, options)
在命令中,name是要创建的集合的名称。选项是一个文档,用于指定集合的配置。
| Parameter | 类型 | 描述 |
|---|---|---|
| Name | 细绳 | 要创建的集合的名称 |
| Options | 文档 | (可选)指定有关内存大小和索引的选项 |
Options 参数是可选的,因此您只需指定集合的名称。以下是您可以使用的选项列表 –
| Field | 类型 | 描述 |
|---|---|---|
| capped | 布尔值 | (可选)如果为 true,则启用上限集合。上限集合是一个固定大小的集合,当它达到最大大小时会自动覆盖其最旧的条目。如果指定 true,则还需要指定 size 参数。 |
| autoIndexId | 布尔值 | (可选)如果为 true,则自动在 _id 字段上创建索引。默认值为 false。 |
| size | 数字 | (可选)指定上限集合的最大大小(以字节为单位)。如果 Capped 为 true,则您还需要指定此字段。 |
| max | 数字 | (可选)指定上限集合中允许的最大文档数。 |
在插入文档时,MongoDB 首先检查上限集合的 size 字段,然后检查 max 字段。
例子
没有选项的createCollection()方法的基本语法如下 –
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>
您可以使用命令show collections检查创建的集合。
>show collections mycollection system.indexes
下面的例子展示了createCollection()方法的语法和几个重要的选项 –
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>
在 MongoDB 中,您不需要创建集合。当您插入某个文档时,MongoDB 会自动创建集合。
>db.tutorialspoint.insert({"name" : "tutorialspoint"})
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>
MongoDB – 删除集合
在本章中,我们将看到如何使用 MongoDB 删除集合。
drop() 方法
MongoDB 的db.collection.drop()用于从数据库中删除一个集合。
句法
drop()命令的基本语法如下 –
db.COLLECTION_NAME.drop()
例子
首先,将可用集合检查到您的数据库mydb 中。
>use mydb switched to db mydb >show collections mycol mycollection system.indexes tutorialspoint >
现在删除名为mycollection的集合。
>db.mycollection.drop() true >
再次将集合列表检查到数据库中。
>show collections mycol system.indexes tutorialspoint >
drop() 方法返回true,如果选择的集合删除成功,否则返回false。
MongoDB – 数据类型
MongoDB 支持多种数据类型。其中一些是 –
-
String – 这是最常用的数据类型来存储数据。MongoDB 中的字符串必须是 UTF-8 有效的。
-
Integer – 此类型用于存储数值。整数可以是 32 位或 64 位,具体取决于您的服务器。
-
Boolean – 此类型用于存储布尔值(真/假)。
-
Double – 此类型用于存储浮点值。
-
Min/Max keys – 此类型用于将值与最低和最高 BSON 元素进行比较。
-
Arrays – 这种类型用于将数组或列表或多个值存储到一个键中。
-
时间戳– ctimestamp。这对于在修改或添加文档时进行记录非常方便。
-
Object – 此数据类型用于嵌入文档。
-
Null – 此类型用于存储 Null 值。
-
符号– 此数据类型与字符串相同;但是,它通常保留给使用特定符号类型的语言。
-
日期– 此数据类型用于以 UNIX 时间格式存储当前日期或时间。您可以通过创建 Date 对象并将日、月、年传入其中来指定自己的日期时间。
-
对象 ID – 此数据类型用于存储文档的 ID。
-
二进制数据– 此数据类型用于存储二进制数据。
-
代码– 此数据类型用于将 JavaScript 代码存储到文档中。
-
正则表达式– 此数据类型用于存储正则表达式。
MongoDB – 插入文档
在本章中,我们将学习如何在 MongoDB 集合中插入文档。
insert() 方法
要将数据插入到 MongoDB 集合中,您需要使用 MongoDB 的insert()或save()方法。
句法
insert()命令的基本语法如下 –
>db.COLLECTION_NAME.insert(document)
例子
>db.mycol.insert({
_id: ObjectId(7df78ad8902c),
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
这里mycol是我们的集合名称,如上一章中创建的。如果数据库中不存在该集合,则 MongoDB 将创建该集合,然后将文档插入其中。
在插入的文档中,如果我们不指定_id参数,那么MongoDB会为这个文档分配一个唯一的ObjectId。
_id 是 12 字节的十六进制数,对于集合中的每个文档都是唯一的。12 个字节划分如下 –
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id, 3 bytes incrementer)
要在单个查询中插入多个文档,您可以在 insert() 命令中传递一组文档。
例子
>db.post.insert([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Database',
description: "NoSQL database doesn't have tables",
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 20,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2013,11,10,2,35),
like: 0
}
]
}
])
要插入文档,您也可以使用db.post.save(document)。如果您没有在文档中指定_id,那么save()方法将与insert()方法相同。如果您指定 _id,那么它将替换包含 _id 的整个文档数据,如 save() 方法中指定的那样。
MongoDB – 查询文档
在本章中,我们将学习如何从 MongoDB 集合中查询文档。
find() 方法
要从 MongoDB 集合中查询数据,您需要使用 MongoDB 的find()方法。
句法
find()方法的基本语法如下 –
>db.COLLECTION_NAME.find()
find()方法将以非结构化方式显示所有文档。
漂亮()方法
要以格式化的方式显示结果,您可以使用pretty()方法。
句法
>db.mycol.find().pretty()
例子
>db.mycol.find().pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>
除了 find() 方法,还有findOne()方法,它只返回一个文档。
RDBMS Where 子句在 MongoDB 中的等价物
要根据某些条件查询文档,可以使用以下操作。
| Operation | 句法 | 例子 | RDBMS 等价物 |
|---|---|---|---|
| Equality | {<键>:<值>} | db.mycol.find({“by”:”tutorials point”}).pretty() | where by = ‘教程点’ |
| Less Than | {<key>:{$lt:<value>}} | db.mycol.find({“likes”:{$lt:50}}).pretty() | 喜欢 < 50 |
| Less Than Equals | {<key>:{$lte:<value>}} | db.mycol.find({“likes”:{$lte:50}}).pretty() | 其中喜欢 <= 50 |
| Greater Than | {<key>:{$gt:<value>}} | db.mycol.find({“likes”:{$gt:50}}).pretty() | 喜欢 > 50 |
| Greater Than Equals | {<key>:{$gte:<value>}} | db.mycol.find({“likes”:{$gte:50}}).pretty() | 喜欢 >= 50 |
| Not Equals | {<key>:{$ne:<value>}} | db.mycol.find({“likes”:{$ne:50}}).pretty() | 哪里喜欢!= 50 |
在 MongoDB 中
句法
在find()方法中,如果通过用 ” 分隔它们来传递多个键,那么 MongoDB 会将其视为AND条件。以下是AND的基本语法–
>db.mycol.find(
{
$and: [
{key1: value1}, {key2:value2}
]
}
).pretty()
例子
以下示例将显示由“tutorials point”编写且标题为“MongoDB 概览”的所有教程。
>db.mycol.find({$and:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty() {
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
对于上面给出的示例,等效的 where 子句将是‘ where by = ‘tutorials point’ AND title = ‘MongoDB Overview’ ‘。您可以在 find 子句中传递任意数量的键值对。
或在 MongoDB 中
句法
根据 OR 条件查询文档,需要使用$or关键字。以下是OR的基本语法–
>db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
例子
以下示例将显示由“tutorials point”编写或标题为“MongoDB 概览”的所有教程。
>db.mycol.find({$or:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>
一起使用 AND 和 OR
例子
以下示例将显示点赞数大于 10 且标题为“MongoDB 概览”或“教程点”的文档。等效的 SQL where 子句是‘where likes>10 AND (by = ‘tutorials point’ OR title = ‘MongoDB Overview’)’
>db.mycol.find({"likes": {$gt:10}, $or: [{"by": "tutorials point"},
{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>
MongoDB – 更新文档
MongoDB 的update()和save()方法用于将文档更新为集合。update() 方法更新现有文档中的值,而 save() 方法用 save() 方法中传递的文档替换现有文档。
MongoDB Update() 方法
update() 方法更新现有文档中的值。
句法
update()方法的基本语法如下 –
>db.COLLECTION_NAME.update(SELECTION_CRITERIA, UPDATED_DATA)
例子
考虑 mycol 集合具有以下数据。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例将设置标题为“MongoDB 概览”的文档的新标题“新 MongoDB 教程”。
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>
默认情况下,MongoDB 将仅更新单个文档。要更新多个文档,您需要将参数 ‘multi’ 设置为 true。
>db.mycol.update({'title':'MongoDB Overview'},
{$set:{'title':'New MongoDB Tutorial'}},{multi:true})
MongoDB Save() 方法
在保存()方法替换在save()方法通过了新的文件现有的文档。
句法
MongoDB save()方法的基本语法如下所示 –
>db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})
例子
以下示例将使用 _id ‘5983548781331adf45ec5’ 替换文档。
>db.mycol.save(
{
"_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"
}
)
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>
MongoDB – 删除文档
在本章中,我们将学习如何使用 MongoDB 删除文档。
remove() 方法
MongoDB 的remove()方法用于从集合中删除文档。remove() 方法接受两个参数。一个是删除标准,第二个是 justOne 标志。
-
删除标准– (可选)根据文档的删除标准将被删除。
-
justOne – (可选)如果设置为 true 或 1,则仅删除一个文档。
句法
remove()方法的基本语法如下 –
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)
例子
考虑 mycol 集合具有以下数据。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例将删除标题为“MongoDB 概览”的所有文档。
>db.mycol.remove({'title':'MongoDB Overview'})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>
只删除一个
如果有多条记录并且只想删除第一条记录,则在remove()方法中设置justOne参数。
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
删除所有文档
如果您不指定删除条件,那么 MongoDB 将从集合中删除整个文档。这相当于 SQL 的 truncate 命令。
>db.mycol.remove({})
>db.mycol.find()
>
MongoDB – 投影
在 MongoDB 中,投影意味着只选择必要的数据,而不是选择文档的全部数据。如果文档有 5 个字段,而您只需要显示 3 个,则仅从中选择 3 个字段。
find() 方法
MongoDB 的find()方法(在MongoDB 查询文档中解释)接受第二个可选参数,即您要检索的字段列表。在 MongoDB 中,当您执行find()方法时,它会显示文档的所有字段。为了限制这一点,您需要设置一个值为 1 或 0 的字段列表。1 用于显示字段,而 0 用于隐藏字段。
句法
带投影的find()方法的基本语法如下 –
>db.COLLECTION_NAME.find({},{KEY:1})
例子
考虑集合 mycol 具有以下数据 –
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例将在查询文档时显示文档的标题。
>db.mycol.find({},{"title":1,_id:0})
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
{"title":"Tutorials Point Overview"}
>
请注意_id字段在执行find()方法时始终显示,如果您不想要该字段,则需要将其设置为 0。
MongoDB – 限制记录
在本章中,我们将学习如何使用 MongoDB 限制记录。
Limit() 方法
要限制 MongoDB 中的记录,您需要使用limit()方法。该方法接受一个数字类型参数,即您要显示的文档数。
句法
limit()方法的基本语法如下 –
>db.COLLECTION_NAME.find().limit(NUMBER)
例子
考虑集合 myycol 具有以下数据。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例将在查询文档时仅显示两个文档。
>db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
>
如果您没有在limit()方法中指定 number 参数,那么它将显示集合中的所有文档。
MongoDB Skip() 方法
除了 limit() 方法之外,还有一种方法skip()也接受数字类型的参数,用于跳过文档的数量。
句法
skip()方法的基本语法如下 –
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
例子
以下示例将仅显示第二个文档。
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1)
{"title":"NoSQL Overview"}
>
请注意,skip()方法中的默认值为0。
MongoDB – 排序记录
在本章中,我们将学习如何在 MongoDB 中对记录进行排序。
sort() 方法
要在 MongoDB 中对文档进行排序,您需要使用sort()方法。该方法接受包含字段列表及其排序顺序的文档。使用 1 和 -1 来指定排序顺序。1 用于升序,而 -1 用于降序。
句法
sort()方法的基本语法如下 –
>db.COLLECTION_NAME.find().sort({KEY:1})
例子
考虑集合 myycol 具有以下数据。
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
以下示例将按标题降序显示文档。
>db.mycol.find({},{"title":1,_id:0}).sort({"title":-1})
{"title":"Tutorials Point Overview"}
{"title":"NoSQL Overview"}
{"title":"MongoDB Overview"}
>
请注意,如果您不指定排序首选项,则sort()方法将按升序显示文档。
MongoDB – 索引
索引支持查询的高效解析。如果没有索引,MongoDB 必须扫描集合的每个文档以选择那些与查询语句匹配的文档。这种扫描效率极低,需要 MongoDB 来处理大量数据。
索引是特殊的数据结构,它以易于遍历的形式存储数据集的一小部分。索引存储特定字段或字段集的值,按索引中指定的字段值排序。
ensureIndex() 方法
要创建索引,您需要使用 MongoDB 的 ensureIndex() 方法。
句法
ensureIndex()方法的基本语法如下()。
>db.COLLECTION_NAME.ensureIndex({KEY:1})
这里的 key 是要在其上创建索引的字段的名称,1 是升序。要按降序创建索引,您需要使用 -1。
例子
>db.mycol.ensureIndex({"title":1})
>
在ensureIndex()方法中,您可以传递多个字段,以在多个字段上创建索引。
>db.mycol.ensureIndex({"title":1,"description":-1})
>
ensureIndex()方法还接受选项列表(可选)。以下是列表 –
| Parameter | 类型 | 描述 |
|---|---|---|
| background | 布尔值 | 在后台构建索引,以便构建索引不会阻止其他数据库活动。指定 true 以在后台构建。默认值为false。 |
| unique | 布尔值 | 创建唯一索引,以便集合不接受插入索引键或键匹配索引中现有值的文档。指定 true 以创建唯一索引。默认值为false。 |
| name | 细绳 | 索引的名称。如果未指定,MongoDB 通过连接索引字段的名称和排序顺序来生成索引名称。 |
| dropDups | 布尔值 | 在可能有重复的字段上创建唯一索引。MongoDB 仅索引第一次出现的键,并从集合中删除包含该键后续出现的所有文档。指定 true 以创建唯一索引。默认值为false。 |
| sparse | 布尔值 | 如果为 true,则索引仅引用具有指定字段的文档。这些索引使用较少的空间,但在某些情况下(特别是排序)表现不同。默认值为false。 |
| expireAfterSeconds | 整数 | 指定一个值(以秒为单位)作为 TTL 来控制 MongoDB 在此集合中保留文档的时间。 |
| v | 索引版本 | 索引版本号。默认索引版本取决于创建索引时运行的 MongoDB 版本。 |
| weights | 文档 | 权重是一个范围从 1 到 99,999 的数字,表示该字段相对于其他索引字段在分数方面的重要性。 |
| default_language | 细绳 | 对于文本索引,确定停用词列表的语言以及词干分析器和分词器的规则。默认值为english。 |
| language_override | 细绳 | 对于文本索引,指定文档中包含的字段的名称,要覆盖默认语言的语言。默认值为语言。 |
MongoDB – 聚合
聚合操作处理数据记录并返回计算结果。聚合操作将来自多个文档的值组合在一起,并且可以对分组的数据执行各种操作以返回单个结果。在 SQL count(*) 和 group by 中相当于 mongodb 聚合。
聚合()方法
对于MongoDB 中的聚合,您应该使用aggregate()方法。
句法
Aggregate()方法的基本语法如下 –
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
例子
在集合中,您有以下数据 –
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
现在从上面的集合中,如果您想显示一个列表,说明每个用户编写了多少教程,那么您将使用以下聚合()方法 –
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "tutorials point",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
>
上述用例的 Sql 等效查询将是select by_user, count(*) from mycol group by by_user。
在上面的示例中,我们按字段by_user对文档进行了分组,并且每次出现 by_user 时,sum 的先前值都会增加。以下是可用聚合表达式的列表。
| Expression | 描述 | 例子 |
|---|---|---|
| $sum | 总结集合中所有文档的定义值。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$sum : “$likes”}}}]) |
| $avg | 计算集合中所有文档的所有给定值的平均值。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$avg : “$likes”}}}]) |
| $min | 从集合中的所有文档中获取相应值的最小值。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$min : “$likes”}}}]) |
| $max | 从集合中的所有文档中获取相应值的最大值。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$max : “$likes”}}}]) |
| $push | 将值插入到结果文档中的数组中。 | db.mycol.aggregate([{$group : {_id : “$by_user”, url : {$push: “$url”}}}]) |
| $addToSet | 将值插入到结果文档中的数组中,但不创建重复项。 | db.mycol.aggregate([{$group : {_id : “$by_user”, url : {$addToSet : “$url”}}}]) |
| $first | 根据分组从源文档中获取第一个文档。通常,这仅与某些先前应用的“$sort”阶段一起使用才有意义。 | db.mycol.aggregate([{$group : {_id : “$by_user”, first_url : {$first : “$url”}}}]) |
| $last | 根据分组从源文档中获取最后一个文档。通常,这仅与某些先前应用的“$sort”阶段一起使用才有意义。 | db.mycol.aggregate([{$group : {_id : “$by_user”, last_url : {$last : “$url”}}}]) |
管道概念
在 UNIX 命令中,shell 管道意味着可以对某些输入执行操作并将输出用作下一个命令的输入等等。MongoDB 也支持聚合框架中的相同概念。有一组可能的阶段,每个阶段都被视为一组文档作为输入,并生成一组结果文档(或管道末端的最终结果 JSON 文档)。然后可以将其用于下一个阶段,依此类推。
以下是聚合框架中可能的阶段 –
-
$project – 用于从集合中选择一些特定的字段。
-
$match – 这是一个过滤操作,因此可以减少作为输入提供给下一阶段的文档数量。
-
$group – 如上所述进行实际聚合。
-
$sort – 对文档进行排序。
-
$skip – 有了这个,可以在给定数量的文档的文档列表中向前跳过。
-
$limit – 这限制了要查看的文档数量,从当前位置开始按给定数字。
-
$unwind – 这用于展开使用数组的文档。使用数组时,数据是预先连接的,并且此操作将撤消以再次拥有单个文档。因此,在这个阶段,我们将增加下一阶段的文件数量。
MongoDB – 复制
复制是跨多个服务器同步数据的过程。复制通过不同数据库服务器上的多个数据副本提供冗余并提高数据可用性。复制保护数据库免受单个服务器的丢失。复制还允许您从硬件故障和服务中断中恢复。有了额外的数据副本,您可以将其中一份专门用于灾难恢复、报告或备份。
为什么要复制?
- 为了确保您的数据安全
- 数据的高 (24*7) 可用性
- 灾难恢复
- 无需停机维护(如备份、索引重建、压缩)
- 读取缩放(要读取的额外副本)
- 副本集对应用程序透明
MongoDB 中的复制如何工作
MongoDB 通过使用副本集来实现复制。副本集是一组托管相同数据集的mongod实例。在副本中,一个节点是接收所有写操作的主节点。所有其他实例(例如次要实例)应用来自主要实例的操作,以便它们具有相同的数据集。副本集只能有一个主节点。
-
副本集是一组两个或多个节点(一般最少需要 3 个节点)。
-
在副本集中,一个节点是主节点,其余节点是辅助节点。
-
所有数据从主节点复制到辅助节点。
-
在自动故障转移或维护时,为primary建立选举并选举一个新的primary节点。
-
故障节点恢复后,再次加入副本集,作为辅助节点。
MongoDB 复制的典型图表显示在其中客户端应用程序始终与主节点交互,然后主节点将数据复制到辅助节点。
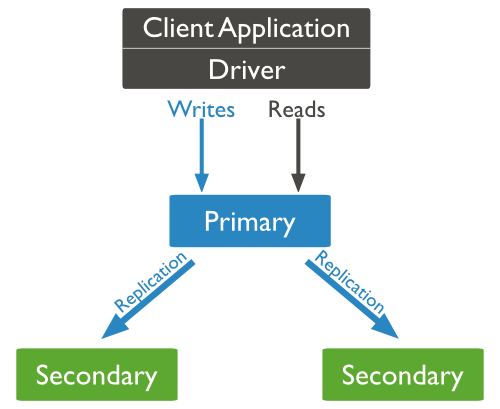
副本集特征
- N 个节点的集群
- 任何一个节点都可以是主节点
- 所有写操作都转到主
- 自动故障转移
- 自动恢复
- 初选共识选举
设置副本集
在本教程中,我们将把独立的 MongoDB 实例转换为副本集。要转换为副本集,以下是步骤 –
-
关闭已经运行的 MongoDB 服务器。
-
通过指定 –replSet 选项启动 MongoDB 服务器。以下是 –replSet 的基本语法 –
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
例子
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0
-
它将在端口 27017 上启动一个名为 rs0 的 mongod 实例。
-
现在启动命令提示符并连接到这个 mongod 实例。
-
在 Mongo 客户端中,发出命令rs.initiate()以启动新的副本集。
-
要检查副本集配置,请发出命令rs.conf()。要检查副本集的状态,请发出命令rs.status()。
将成员添加到副本集
要将成员添加到副本集,请在多台机器上启动 mongod 实例。现在启动一个 mongo 客户端并发出命令rs.add()。
句法
rs.add()命令的基本语法如下 –
>rs.add(HOST_NAME:PORT)
例子
假设您的 mongod 实例名称是mongod1.net并且它在端口27017上运行。要将此实例添加到副本集,请在 Mongo 客户端中发出命令rs.add()。
>rs.add("mongod1.net:27017")
>
只有在连接到主节点时才能将 mongod 实例添加到副本集。要检查您是否已连接到主服务器,请在 mongo 客户端中发出命令db.isMaster()。
MongoDB – 分片
分片是跨多台机器存储数据记录的过程,它是 MongoDB 满足数据增长需求的方法。随着数据大小的增加,单台机器可能不足以存储数据,也无法提供可接受的读写吞吐量。分片解决了水平扩展的问题。通过分片,您可以添加更多机器来支持数据增长和读写操作的需求。
为什么要分片?
- 在复制中,所有写入都转到主节点
- 延迟敏感的查询仍由主处理
- 单个副本集限制为 12 个节点
- 当活动数据集很大时,内存不够大
- 本地磁盘不够大
- 垂直扩展太昂贵
MongoDB 中的分片
下图显示了使用分片集群在 MongoDB 中的分片。
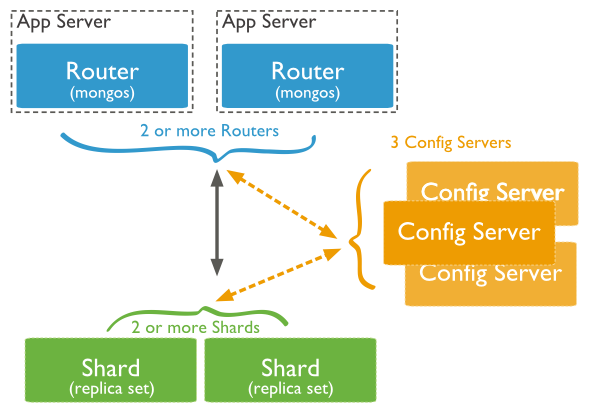
在下图中,有三个主要组件 –
-
碎片– 碎片用于存储数据。它们提供高可用性和数据一致性。在生产环境中,每个分片都是一个单独的副本集。
-
配置服务器– 配置服务器存储集群的元数据。此数据包含集群数据集到分片的映射。查询路由器使用此元数据将操作定位到特定分片。在生产环境中,分片集群恰好有 3 个配置服务器。
-
查询路由器– 查询路由器基本上是 mongo 实例,与客户端应用程序的接口和对适当分片的直接操作。查询路由器处理并将操作定位到分片,然后将结果返回给客户端。一个分片集群可以包含多个查询路由器来划分客户端请求负载。客户端向一个查询路由器发送请求。通常,一个分片集群有许多查询路由器。
MongoDB – 创建备份
在本章中,我们将看到如何在 MongoDB 中创建备份。
转储 MongoDB 数据
要在 MongoDB 中创建数据库备份,您应该使用mongodump命令。此命令会将服务器的整个数据转储到转储目录中。有许多选项可供您限制数据量或创建远程服务器的备份。
句法
mongodump命令的基本语法如下 –
>mongodump
例子
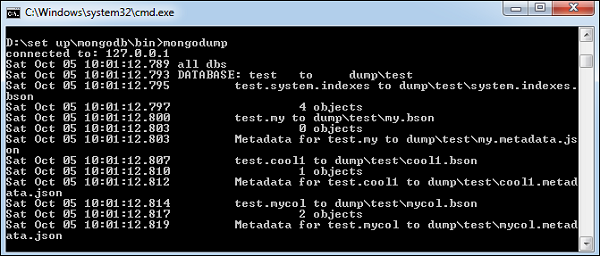
启动你的 mongod 服务器。假设您的 mongod 服务器在 localhost 和端口 27017 上运行,打开命令提示符并转到您的 mongodb 实例的 bin 目录并键入命令mongodump
考虑 mycol 集合具有以下数据。
>mongodump
该命令将连接到运行在127.0.0.1和端口27017的服务器,并将服务器的所有数据返回到目录/bin/dump/。以下是命令的输出 –
以下是可与mongodump命令一起使用的可用选项列表。
| Syntax | 描述 | 例子 |
|---|---|---|
| mongodump –host HOST_NAME –port PORT_NUMBER | 该命令将备份指定 mongod 实例的所有数据库。 | mongodump –host tutorialspoint.com –port 27017 |
| mongodump –dbpath DB_PATH –out BACKUP_DIRECTORY | 此命令将仅备份指定路径下的指定数据库。 | mongodump –dbpath /data/db/ –out /data/backup/ |
| mongodump –collection COLLECTION –db DB_NAME | 此命令将仅备份指定数据库的指定集合。 | mongodump –collection mycol –db 测试 |
恢复数据
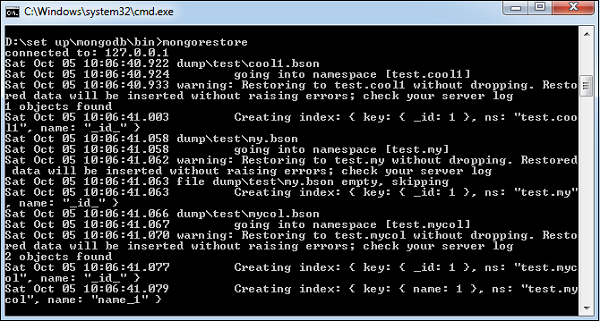
使用MongoDB 的mongorestore命令恢复备份数据。此命令从备份目录恢复所有数据。
句法
mongorestore命令的基本语法是 –
>mongorestore
以下是命令的输出 –
MongoDB – 部署
当您准备 MongoDB 部署时,您应该尝试了解您的应用程序将如何在生产中保持。开发一种一致的、可重复的方法来管理部署环境是一个好主意,这样您就可以在投入生产后最大程度地减少任何意外。
最好的方法包括对您的设置进行原型设计、进行负载测试、监控关键指标以及使用该信息来扩展您的设置。该方法的关键部分是主动监控您的整个系统——这将帮助您了解您的生产系统在部署之前将如何运行,并确定您需要在何处增加容量。例如,深入了解内存使用的潜在峰值,有助于在写锁开始之前扑灭它。
为了监控您的部署,MongoDB 提供了以下一些命令 –
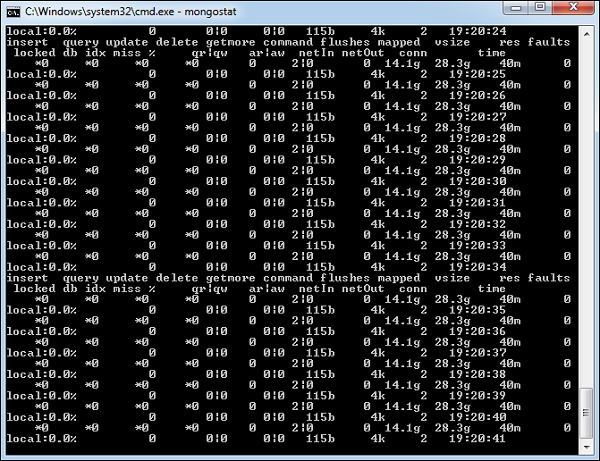
mongostat
此命令检查所有正在运行的 mongod 实例的状态并返回数据库操作的计数器。这些计数器包括插入、查询、更新、删除和游标。命令还会显示您何时遇到页面错误,并展示您的锁定百分比。这意味着您的内存不足,达到写入容量或有一些性能问题。
要运行该命令,请启动您的 mongod 实例。在另一个命令提示符下,转到mongodb 安装的bin目录并键入mongostat。
D:\set up\mongodb\bin>mongostat
以下是命令的输出 –
mongotop
此命令在集合的基础上跟踪和报告 MongoDB 实例的读写活动。默认情况下,mongotop 每秒返回信息,您可以相应地更改它。您应该检查此读写活动是否符合您的应用程序意图,并且您没有一次向数据库触发太多写入、从磁盘读取太频繁或超出您的工作集大小。
要运行该命令,请启动您的 mongod 实例。在另一个命令提示符下,转到mongodb 安装的bin目录并键入mongotop。
D:\set up\mongodb\bin>mongotop
以下是命令的输出 –
要将mongotop命令更改为不那么频繁地返回信息,请在 mongotop 命令后指定一个特定的数字。
D:\set up\mongodb\bin>mongotop 30
上面的示例将每 30 秒返回一次值。
除了 MongoDB 工具外,10gen 还提供免费的托管监控服务,即 MongoDB 管理服务 (MMS),该服务提供一个仪表板并让您查看整个集群的指标。
MongoDB – Java
在本章中,我们将学习如何设置 MongoDB JDBC 驱动程序。
安装
在您的 Java 程序中开始使用 MongoDB 之前,您需要确保在机器上安装了 MongoDB JDBC 驱动程序和 Java。您可以查看 Java 教程以在您的机器上安装 Java。现在,让我们检查如何设置 MongoDB JDBC 驱动程序。
-
您需要从下载 mongo.jar路径下载 jar。确保下载它的最新版本。
-
您需要将 mongo.jar 包含到您的类路径中。
连接到数据库
要连接数据库,您需要指定数据库名称,如果该数据库不存在,则 MongoDB 会自动创建它。
以下是连接到数据库的代码片段 –
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ConnectToDB {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Credentials ::"+ credential);
}
}
现在,让我们编译并运行上面的程序来创建我们的数据库 myDb,如下所示。
$javac ConnectToDB.java $java ConnectToDB
执行时,上述程序为您提供以下输出。
Connected to the database successfully
Credentials ::MongoCredential{
mechanism = null,
userName = 'sampleUser',
source = 'myDb',
password = <hidden>,
mechanismProperties = {}
}
创建集合
要创建集合,请使用com.mongodb.client.MongoDatabase类的createCollection()方法。
以下是创建集合的代码片段 –
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class CreatingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
//Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
//Creating a collection
database.createCollection("sampleCollection");
System.out.println("Collection created successfully");
}
}
在编译时,上面的程序会给你以下结果 –
Connected to the database successfully Collection created successfully
获取/选择一个集合
要从数据库中获取/选择集合,请使用com.mongodb.client.MongoDatabase类的getCollection()方法。
以下是获取/选择集合的程序 –
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class selectingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collection created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("myCollection");
System.out.println("Collection myCollection selected successfully");
}
}
在编译时,上面的程序会给你以下结果 –
Connected to the database successfully Collection created successfully Collection myCollection selected successfully
插入文档
要将文档插入 MongoDB,使用com.mongodb.client.MongoCollection类的insert()方法。
以下是插入文档的代码片段 –
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class InsertingDocument {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
Document document = new Document("title", "MongoDB")
.append("id", 1)
.append("description", "database")
.append("likes", 100)
.append("url", "http://www.tutorialspoint.com/mongodb/")
.append("by", "tutorials point");
collection.insertOne(document);
System.out.println("Document inserted successfully");
}
}
在编译时,上面的程序会给你以下结果 –
Connected to the database successfully Collection sampleCollection selected successfully Document inserted successfully
检索所有文件
要从集合中选择所有文档,请使用com.mongodb.client.MongoCollection类的find()方法。此方法返回一个游标,因此您需要迭代此游标。
以下是选择所有文件的程序 –
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class RetrievingAllDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}
在编译时,上面的程序会给你以下结果 –
Document{{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 100,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}
Document{{
_id = 7452239959673a32646baab8,
title = RethinkDB,
id = 2,
description = database,
likes = 200,
url = http://www.tutorialspoint.com/rethinkdb/, by = tutorials point
}}
更新文件
要从集合中更新文档,请使用com.mongodb.client.MongoCollection类的updateOne()方法。
以下是选择第一个文档的程序 –
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.Updates;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class UpdatingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection myCollection selected successfully");
collection.updateOne(Filters.eq("id", 1), Updates.set("likes", 150));
System.out.println("Document update successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}
在编译时,上面的程序会给你以下结果 –
Document update successfully...
Document {{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 150,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}
删除文档
要从集合中删除文档,您需要使用com.mongodb.client.MongoCollection类的deleteOne()方法。
以下是删除文档的程序 –
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DeletingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Deleting the documents
collection.deleteOne(Filters.eq("id", 1));
System.out.println("Document deleted successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println("Inserted Document: "+i);
System.out.println(it.next());
i++;
}
}
}
在编译时,上面的程序会给你以下结果 –
Connected to the database successfully Collection sampleCollection selected successfully Document deleted successfully...
删除集合
要从数据库中删除集合,您需要使用com.mongodb.client.MongoCollection类的drop()方法。
以下是删除集合的程序 –
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DropingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collections created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
// Dropping a Collection
collection.drop();
System.out.println("Collection dropped successfully");
}
}
在编译时,上面的程序会给你以下结果 –
Connected to the database successfully Collection sampleCollection selected successfully Collection dropped successfully
列出所有集合
要列出数据库中的所有集合,您需要使用com.mongodb.client.MongoDatabase类的listCollectionNames() 方法。
以下是列出数据库所有集合的程序 –
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ListOfCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Collection created successfully");
for (String name : database.listCollectionNames()) {
System.out.println(name);
}
}
}
在编译时,上面的程序会给你以下结果 –
Connected to the database successfully Collection created successfully myCollection myCollection1 myCollection5
其余的 MongoDB 方法save()、limit()、skip()、sort()等的工作方式与后续教程中的解释相同。
MongoDB – PHP
要在 PHP 中使用 MongoDB,您需要使用 MongoDB PHP 驱动程序。从 url Download PHP Driver 下载驱动程序。确保下载它的最新版本。现在解压缩存档并将 php_mongo.dll 放在您的 PHP 扩展目录中(默认为“ext”),并将以下行添加到您的 php.ini 文件中 –
extension = php_mongo.dll
建立连接并选择数据库
要建立连接,您需要指定数据库名称,如果数据库不存在,则 MongoDB 会自动创建它。
以下是连接到数据库的代码片段 –
<?php // connect to mongodb $m = new MongoClient(); echo "Connection to database successfully"; // select a database $db = $m->mydb; echo "Database mydb selected"; ?>
当程序执行时,它会产生以下结果 –
Connection to database successfully Database mydb selected
创建集合
以下是创建集合的代码片段 –
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->createCollection("mycol");
echo "Collection created succsessfully";
?>
当程序执行时,它会产生以下结果 –
Connection to database successfully Database mydb selected Collection created succsessfully
插入文档
要将文档插入 MongoDB,请使用insert()方法。
以下是插入文档的代码片段 –
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$document = array(
"title" => "MongoDB",
"description" => "database",
"likes" => 100,
"url" => "http://www.tutorialspoint.com/mongodb/",
"by" => "tutorials point"
);
$collection->insert($document);
echo "Document inserted successfully";
?>
当程序执行时,它会产生以下结果 –
Connection to database successfully Database mydb selected Collection selected succsessfully Document inserted successfully
查找所有文档
要从集合中选择所有文档,请使用 find() 方法。
以下是选择所有文档的代码片段 –
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$cursor = $collection->find();
// iterate cursor to display title of documents
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>
当程序执行时,它会产生以下结果 –
Connection to database successfully
Database mydb selected
Collection selected succsessfully {
"title": "MongoDB"
}
更新文档
要更新文档,您需要使用 update() 方法。
在以下示例中,我们将插入文档的标题更新为MongoDB Tutorial。以下是更新文档的代码片段 –
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now update the document
$collection->update(array("title"=>"MongoDB"),
array('$set'=>array("title"=>"MongoDB Tutorial")));
echo "Document updated successfully";
// now display the updated document
$cursor = $collection->find();
// iterate cursor to display title of documents
echo "Updated document";
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>
当程序执行时,它会产生以下结果 –
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document updated successfully
Updated document {
"title": "MongoDB Tutorial"
}
删除文档
要删除文档,您需要使用 remove() 方法。
在以下示例中,我们将删除标题为MongoDB Tutorial的文档。以下是删除文档的代码片段 –
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now remove the document
$collection->remove(array("title"=>"MongoDB Tutorial"),false);
echo "Documents deleted successfully";
// now display the available documents
$cursor = $collection->find();
// iterate cursor to display title of documents
echo "Updated document";
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>
当程序执行时,它会产生以下结果 –
Connection to database successfully Database mydb selected Collection selected succsessfully Documents deleted successfully
在上面的例子中,第二个参数是布尔类型,用于remove()方法的justOne字段。
其余的 MongoDB 方法findOne()、save()、limit()、skip()、sort()等的工作方式与上面解释的相同。
MongoDB – 关系
MongoDB 中的关系表示各种文档如何在逻辑上相互关联。关系可以通过嵌入和引用方法建模。这种关系可以是 1:1、1:N、N:1 或 N:N。
让我们考虑为用户存储地址的情况。因此,一个用户可以拥有多个地址,从而形成 1:N 关系。
以下是用户文档的示例文档结构–
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"name": "Tom Hanks",
"contact": "987654321",
"dob": "01-01-1991"
}
以下是地址文件的示例文件结构–
{
"_id":ObjectId("52ffc4a5d85242602e000000"),
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
}
建模嵌入式关系
在嵌入方式中,我们将地址文件嵌入到用户文件中。
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}
]
}
这种方法将所有相关数据保存在一个文档中,这使得检索和维护变得容易。可以在单个查询中检索整个文档,例如 –
>db.users.findOne({"name":"Tom Benzamin"},{"address":1})
注意在上面的查询中,db和users分别是数据库和集合。
缺点是,如果嵌入文档的大小持续增长过多,则会影响读/写性能。
建模引用关系
这是设计规范化关系的方法。在这种方法中,用户和地址文档将分别维护,但用户文档将包含一个字段,该字段将引用地址文档的id字段。
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}
如上所示,用户文档包含数组字段address_ids,其中包含对应地址的ObjectIds。使用这些 ObjectId,我们可以查询地址文档并从中获取地址详细信息。使用这种方法,我们将需要两个查询:首先从用户文档中获取address_ids字段,然后从地址集合中获取这些地址。
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
MongoDB – 数据库参考
正如 MongoDB 关系的最后一章所见,为了在 MongoDB 中实现规范化的数据库结构,我们使用了引用关系的概念,也称为手动引用,其中我们手动将引用文档的 id 存储在其他文档中。但是,如果文档包含来自不同集合的引用,我们可以使用MongoDB DBRefs。
DBRefs 与手动参考
作为一个示例场景,我们将使用 DBRefs 而不是手动引用,考虑一个数据库,我们将不同类型的地址(家庭、办公室、邮件等)存储在不同的集合(address_home、address_office、address_mailing 等)中。现在,当用户集合的文档引用地址时,它还需要根据地址类型指定要查看的集合。在文档引用来自多个集合的文档的这种情况下,我们应该使用 DBRefs。
使用 DBRefs
DBRefs 中有三个字段 –
-
$ref – 此字段指定引用文档的集合
-
$id – 此字段指定引用文档的 _id 字段
-
$db – 这是一个可选字段,包含引用文档所在的数据库的名称
考虑一个具有 DBRef 字段地址的示例用户文档,如代码片段所示 –
{
"_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home",
"$id": ObjectId("534009e4d852427820000002"),
"$db": "tutorialspoint"},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}
这里的地址DBRef字段指定引用的地址文档位于tutorialspoint数据库下的address_home集合中,id为534009e4d852427820000002。
以下代码在$ref参数(在我们的例子中为address_home)指定的集合中动态查找ID 由DBRef 中的$id参数指定的文档。
>var user = db.users.findOne({"name":"Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id":(dbRef.$id)})
上面的代码返回address_home集合中存在的以下地址文档–
{
"_id" : ObjectId("534009e4d852427820000002"),
"building" : "22 A, Indiana Apt",
"pincode" : 123456,
"city" : "Los Angeles",
"state" : "California"
}
MongoDB – 涵盖的查询
在本章中,我们将了解覆盖查询。
什么是涵盖查询?
根据官方 MongoDB 文档,涵盖的查询是一个查询,其中 –
- 查询中的所有字段都是索引的一部分。
- 查询中返回的所有字段都在同一个索引中。
由于查询中存在的所有字段都是索引的一部分,因此 MongoDB 匹配查询条件并使用相同的索引返回结果,而无需实际查看文档内部。由于索引存在于 RAM 中,与通过扫描文档获取数据相比,从索引中获取数据要快得多。
使用覆盖查询
要测试涵盖的查询,请考虑users集合中的以下文档–
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom Benzamin",
"user_name": "tombenzamin"
}
我们将首先创建一个复合索引用户上的字段集合性别和USER_NAME使用下面的查询-
>db.users.ensureIndex({gender:1,user_name:1})
现在,该索引将涵盖以下查询 –
>db.users.find({gender:"M"},{user_name:1,_id:0})
也就是说,对于上面的查询,MongoDB 不会去查找数据库文档。相反,它会非常快地从索引数据中获取所需的数据。
由于我们的索引不包含_id字段,因此我们已明确将其从查询的结果集中排除,因为 MongoDB 默认在每个查询中返回 _id 字段。因此,上面创建的索引中不会涵盖以下查询 –
>db.users.find({gender:"M"},{user_name:1})
最后,请记住,如果 –
- 任何索引字段都是一个数组
- 任何索引字段都是子文档
MongoDB – 分析查询
分析查询是衡量数据库和索引设计有效性的一个非常重要的方面。我们将了解常用的$explain和$hint查询。
使用 $explain
在$解释运营商提供查询的信息,在查询以及其他统计信息使用的索引。在分析索引的优化情况时,它非常有用。
在最后一章,我们已经创建了一个索引用户收集的领域性别和USER_NAME使用下面的查询-
>db.users.ensureIndex({gender:1,user_name:1})
我们现在将在以下查询中使用$explain –
>db.users.find({gender:"M"},{user_name:1,_id:0}).explain()
上面的解释()查询返回以下分析结果 –
{
"cursor" : "BtreeCursor gender_1_user_name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 0,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 0,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : true,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"gender" : [
[
"M",
"M"
]
],
"user_name" : [
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
]
}
}
我们现在将查看此结果集中的字段 –
-
真正的价值indexOnly表示此查询使用索引。
-
的光标字段指定用于光标的类型。BTreeCursor 类型表示使用了一个索引,并给出了所使用索引的名称。BasicCursor 表示在不使用任何索引的情况下进行了完整扫描。
-
n表示返回的匹配文档数。
-
nscannedObjects表示扫描的文档总数。
-
nscanned表示扫描的文档或索引条目的总数。
使用 $hint
在$提示操作力的查询优化器使用指定索引运行查询。当您想要测试具有不同索引的查询的性能时,这尤其有用。例如,下面的查询指定的字段的索引性别和USER_NAME用于这个查询-
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})
使用 $explain 分析上述查询 –
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()
MongoDB – 原子操作
原子操作的模型数据
维持原子性的推荐方法是保留所有相关信息,这些信息经常使用嵌入式文档在单个文档中一起更新。这将确保单个文档的所有更新都是原子的。
考虑以下产品文档 –
{
"_id":1,
"product_name": "Samsung S3",
"category": "mobiles",
"product_total": 5,
"product_available": 3,
"product_bought_by": [
{
"customer": "john",
"date": "7-Jan-2014"
},
{
"customer": "mark",
"date": "8-Jan-2014"
}
]
}
在本文档中,我们在product_bought_by字段中嵌入了购买产品的客户信息。现在,每当新客户购买产品时,我们将首先使用product_available字段检查产品是否仍然可用。如果可用,我们将减少 product_available 字段的值,并在 product_bought_by 字段中插入新客户的嵌入文档。我们将使用findAndModify命令来实现此功能,因为它会在同一个 go 中搜索和更新文档。
>db.products.findAndModify({
query:{_id:2,product_available:{$gt:0}},
update:{
$inc:{product_available:-1},
$push:{product_bought_by:{customer:"rob",date:"9-Jan-2014"}}
}
})
我们的嵌入文档方法和使用 findAndModify 查询确保产品购买信息仅在产品可用时更新。并且整个事务都在同一个查询中,是原子的。
与此相反,请考虑我们可能单独保留产品可用性和有关谁购买了产品的信息的场景。在这种情况下,我们将首先使用第一个查询检查产品是否可用。然后在第二个查询中我们将更新购买信息。但是,在执行这两个查询之间,可能有其他用户购买了该产品并且不再可用。在不知道这一点的情况下,我们的第二个查询将根据第一个查询的结果更新购买信息。这将导致数据库不一致,因为我们销售的产品不可用。
MongoDB – 高级索引
考虑用户集合的以下文档–
{
"address": {
"city": "Los Angeles",
"state": "California",
"pincode": "123"
},
"tags": [
"music",
"cricket",
"blogs"
],
"name": "Tom Benzamin"
}
上面的文档包含一个地址子文档和一个标签数组。
索引数组字段
假设我们要根据用户的标签搜索用户文档。为此,我们将在集合中的标签数组上创建一个索引。
在数组上创建索引依次为其每个字段创建单独的索引条目。因此,在我们的例子中,当我们在标签数组上创建索引时,将为其值 music、cricket 和 blog 创建单独的索引。
要在标签数组上创建索引,请使用以下代码 –
>db.users.ensureIndex({"tags":1})
创建索引后,我们可以像这样搜索集合的标签字段 –
>db.users.find({tags:"cricket"})
要验证是否使用了正确的索引,请使用以下解释命令 –
>db.users.find({tags:"cricket"}).explain()
上面的命令导致 “cursor” : “BtreeCursor tags_1” 确认使用了正确的索引。
索引子文档字段
假设我们要根据城市、州和密码字段搜索文档。由于所有这些字段都是地址子文档字段的一部分,我们将在子文档的所有字段上创建索引。
要在子文档的所有三个字段上创建索引,请使用以下代码 –
>db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1})
创建索引后,我们可以使用此索引搜索任何子文档字段,如下所示 –
>db.users.find({"address.city":"Los Angeles"})
请记住,查询表达式必须遵循指定索引的顺序。所以上面创建的索引将支持以下查询 –
>db.users.find({"address.city":"Los Angeles","address.state":"California"})
它还将支持以下查询 –
>db.users.find({"address.city":"LosAngeles","address.state":"California",
"address.pincode":"123"})
MongoDB – 索引限制
在本章中,我们将了解索引限制及其其他组件。
额外开销
每个索引都会占用一些空间,并且会导致每次插入、更新和删除的开销。因此,如果您很少将集合用于读取操作,那么不使用索引是有意义的。
内存使用
由于索引存储在 RAM 中,因此您应该确保索引的总大小不超过 RAM 限制。如果总大小增加 RAM 大小,它将开始删除一些索引,从而导致性能损失。
查询限制
不能在使用的查询中使用索引 –
- 正则表达式或否定运算符,如 $nin、$not 等。
- 算术运算符,如 $mod 等。
- $where 子句
因此,始终建议检查查询的索引使用情况。
索引键限制
从 2.6 版本开始,如果现有索引字段的值超过索引键限制,MongoDB 将不会创建索引。
插入超过索引键限制的文档
如果此文档的索引字段值超出索引键限制,MongoDB 将不会将任何文档插入到索引集合中。mongorestore 和 mongoimport 实用程序的情况也是如此。
最大范围
- 一个集合的索引不能超过 64 个。
- 索引名称的长度不能超过 125 个字符。
- 一个复合索引最多可以索引 31 个字段。
MongoDB – 对象 ID
在之前的所有章节中,我们一直在使用 MongoDB 对象 ID。在本章中,我们将了解 ObjectId 的结构。
一个的ObjectId是具有以下结构的12字节的BSON型-
- 前 4 个字节代表自 unix 纪元以来的秒数
- 接下来的 3 个字节是机器标识符
- 接下来的 2 个字节由进程 ID 组成
- 最后 3 个字节是一个随机计数器值
MongoDB 使用 ObjectIds 作为每个文档的_id字段的默认值,它是在创建任何文档时生成的。ObjectId 的复杂组合使所有 _id 字段都是唯一的。
创建新的 ObjectId
要生成新的 ObjectId,请使用以下代码 –
>newObjectId = ObjectId()
上述语句返回以下唯一生成的 id –
ObjectId("5349b4ddd2781d08c09890f3")
除了 MongoDB 生成 ObjectId,您还可以提供 12 字节的 id –
>myObjectId = ObjectId("5349b4ddd2781d08c09890f4")
创建文档的时间戳
由于 _id ObjectId 默认存储 4 字节的时间戳,因此在大多数情况下,您不需要存储任何文档的创建时间。您可以使用 getTimestamp 方法获取文档的创建时间 –
>ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()
这将以 ISO 日期格式返回此文档的创建时间 –
ISODate("2014-04-12T21:49:17Z")
将 ObjectId 转换为字符串
在某些情况下,您可能需要字符串格式的 ObjectId 值。要将 ObjectId 转换为字符串,请使用以下代码 –
>newObjectId.str
上面的代码将返回 Guid 的字符串格式 –
5349b4ddd2781d08c09890f3
MongoDB – Map Reduce
根据 MongoDB 文档,Map-reduce是一种数据处理范例,用于将大量数据压缩为有用的聚合结果。MongoDB 使用mapReduce命令进行 map-reduce 操作。MapReduce 一般用于处理大数据集。
MapReduce 命令
以下是基本 mapReduce 命令的语法 –
>db.collection.mapReduce(
function() {emit(key,value);}, //map function
function(key,values) {return reduceFunction}, { //reduce function
out: collection,
query: document,
sort: document,
limit: number
}
)
map-reduce 函数首先查询集合,然后映射结果文档以发出键值对,然后根据具有多个值的键进行缩减。
在上述语法中 –
-
map是一个 javascript 函数,它用一个键映射一个值并发出一个键值对
-
reduce是一个 javascript 函数,用于减少或分组具有相同键的所有文档
-
out指定map-reduce查询结果的位置
-
查询指定选择文档的可选选择标准
-
sort指定可选的排序条件
-
limit指定要返回的可选最大文档数
使用 MapReduce
考虑以下存储用户帖子的文档结构。该文档存储用户的 user_name 和帖子的状态。
{
"post_text": "tutorialspoint is an awesome website for tutorials",
"user_name": "mark",
"status":"active"
}
现在,我们将在我们的帖子集合上使用 mapReduce 函数来选择所有活动帖子,根据 user_name 将它们分组,然后使用以下代码计算每个用户的帖子数量 –
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
)
上面的 mapReduce 查询输出以下结果 –
{
"result" : "post_total",
"timeMillis" : 9,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 2,
"output" : 2
},
"ok" : 1,
}
结果显示总共有 4 个文档与查询匹配(状态:“活动”),map 函数发出 4 个具有键值对的文档,最后 reduce 函数将具有相同键的映射文档分组为 2 个。
要查看此 mapReduce 查询的结果,请使用 find 运算符 –
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
).find()
上面的查询给出了以下结果,表明用户tom和mark都有两个处于活动状态的帖子 –
{ "_id" : "tom", "value" : 2 }
{ "_id" : "mark", "value" : 2 }
以类似的方式,MapReduce 查询可用于构建大型复杂聚合查询。自定义 Javascript 函数的使用利用了非常灵活和强大的 MapReduce。
MongoDB – 文本搜索
从 2.4 版开始,MongoDB 开始支持文本索引来搜索字符串内容。该文本搜索通过降低所产生停止的话就像使用词干技术,以寻找在字符串字段中指定词语一,一个的,等。目前,MongoDB的支持大约15种语言。
启用文本搜索
最初,文本搜索是一项实验性功能,但从 2.6 版开始,该配置默认启用。但是,如果您使用的是以前版本的 MongoDB,则必须使用以下代码启用文本搜索 –
>db.adminCommand({setParameter:true,textSearchEnabled:true})
创建文本索引
考虑包含帖子文本及其标签的帖子集合下的以下文档–
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}
我们将在 post_text 字段上创建一个文本索引,以便我们可以在帖子的文本中搜索 –
>db.posts.ensureIndex({post_text:"text"})
使用文本索引
现在我们已经在 post_text 字段上创建了文本索引,我们将搜索文本中包含单词tutorialspoint 的所有帖子。
>db.posts.find({$text:{$search:"tutorialspoint"}})
上面的命令返回以下结果文档,在其帖子文本中包含单词tutorialspoint –
{
"_id" : ObjectId("53493d14d852429c10000002"),
"post_text" : "enjoy the mongodb articles on tutorialspoint",
"tags" : [ "mongodb", "tutorialspoint" ]
}
{
"_id" : ObjectId("53493d1fd852429c10000003"),
"post_text" : "writing tutorials on mongodb",
"tags" : [ "mongodb", "tutorial" ]
}
如果您使用的是旧版本的 MongoDB,则必须使用以下命令 –
>db.posts.runCommand("text",{search:" tutorialspoint "})
与普通搜索相比,使用文本搜索大大提高了搜索效率。
删除文本索引
要删除现有的文本索引,首先使用以下查询找到索引的名称 –
>db.posts.getIndexes()
从上述查询中获取索引名称后,运行以下命令。此处,post_text_text是索引的名称。
>db.posts.dropIndex("post_text_text")
MongoDB – 正则表达式
所有语言都经常使用正则表达式来搜索任何字符串中的模式或单词。MongoDB 还提供了使用$regex运算符进行字符串模式匹配的正则表达式功能。MongoDB 使用 PCRE(Perl Compatible Regular Expression)作为正则表达式语言。
与文本搜索不同,我们不需要做任何配置或命令来使用正则表达式。
考虑包含帖子文本及其标签的帖子集合下的以下文档结构–
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}
使用正则表达式
以下正则表达式查询搜索所有包含字符串tutorialspoint的帖子–
>db.posts.find({post_text:{$regex:"tutorialspoint"}})
相同的查询也可以写为 –
>db.posts.find({post_text:/tutorialspoint/})
使用不区分大小写的正则表达式
为了使搜索不区分大小写,我们使用值为$i的$options参数。以下命令将查找具有单词tutorialspoint 的字符串,无论大小写 –
>db.posts.find({post_text:{$regex:"tutorialspoint",$options:"$i"}})
此查询返回的结果之一是以下文档,其中包含不同情况下的tutorialspoint一词–
{
"_id" : ObjectId("53493d37d852429c10000004"),
"post_text" : "hey! this is my post on TutorialsPoint",
"tags" : [ "tutorialspoint" ]
}
对数组元素使用正则表达式
我们也可以在数组字段上使用正则表达式的概念。这在我们实现标签的功能时尤为重要。因此,如果您想搜索所有带有以教程一词开头的标签的帖子(教程或教程或教程点或教程php),您可以使用以下代码 –
>db.posts.find({tags:{$regex:"tutorial"}})
优化正则表达式查询
-
如果文档字段被索引,则查询将使用索引值来匹配正则表达式。与扫描整个集合的正则表达式相比,这使得搜索速度非常快。
-
如果正则表达式是前缀表达式,则所有匹配项均以特定字符串字符开头。例如,如果正则表达式是^tut,那么查询必须只搜索那些以tut开头的字符串。
与 RockMongo 合作
RockMongo 是一个 MongoDB 管理工具,您可以使用它来管理您的服务器、数据库、集合、文档、索引等等。它提供了一种非常用户友好的方式来阅读、编写和创建文档。它类似于 PHP 和 MySQL 的 PHPMyAdmin 工具。
下载 RockMongo
你可以从这里下载最新版本的 RockMongo:https : //github.com/iwind/rockmongo
安装 RockMongo
下载后,您可以在服务器根文件夹中解压缩包并将解压缩的文件夹重命名为rockmongo。打开任何 Web 浏览器并从文件夹 rockmongo访问index.php页面。分别输入 admin/admin 作为用户名/密码。
与 RockMongo 合作
我们现在将研究一些您可以使用 RockMongo 执行的基本操作。
创建新数据库
要创建新数据库,请单击“数据库”选项卡。单击创建新数据库。在下一个屏幕上,提供新数据库的名称并单击Create。您将看到在左侧面板中添加了一个新数据库。
创建新集合
要在数据库中创建新集合,请从左侧面板单击该数据库。单击顶部的“新收藏”链接。提供所需的集合名称。不用担心 Is Capped、Size 和 Max 的其他字段。单击“创建”。将创建一个新集合,您将能够在左侧面板中看到它。
创建新文档
要创建新文档,请单击要在其下添加文档的集合。当您单击一个集合时,您将能够看到该集合中列出的所有文档。要创建新文档,请单击顶部的插入链接。您可以以 JSON 或数组格式输入文档数据,然后单击Save。
导出/导入数据
要导入/导出任何集合的数据,请单击该集合,然后单击顶部面板上的导出/导入链接。按照以下说明以 zip 格式导出数据,然后导入相同的 zip 文件以重新导入数据。
MongoDB – GridFS
GridFS是用于存储和检索大型文件(如图像、音频文件、视频文件等)的 MongoDB 规范。它是一种存储文件的文件系统,但其数据存储在 MongoDB 集合中。GridFS 能够存储甚至大于其 16MB 文档大小限制的文件。
GridFS 将文件分成多个块,并将每个数据块存储在一个单独的文档中,每个文件的最大大小为 255k。
GridFS 默认使用两个集合fs.files和fs.chunks来存储文件的元数据和块。每个块由其唯一的 _id ObjectId 字段标识。fs.files 作为父文档。fs.chunks 文档中的files_id字段将块链接到其父块。
以下是 fs.files 集合的示例文档 –
{
"filename": "test.txt",
"chunkSize": NumberInt(261120),
"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),
"md5": "7b762939321e146569b07f72c62cca4f",
"length": NumberInt(646)
}
该文档指定文件名、块大小、上传日期和长度。
以下是 fs.chunks 文档的示例文档 –
{
"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),
"n": NumberInt(0),
"data": "Mongo Binary Data"
}
将文件添加到 GridFS
现在,我们将使用put命令使用 GridFS 存储一个 mp3 文件。为此,我们将使用MongoDB 安装文件夹的 bin 文件夹中的mongofiles.exe实用程序。
打开命令提示符,导航到 MongoDB 安装文件夹的 bin 文件夹中的 mongofiles.exe 并键入以下代码 –
>mongofiles.exe -d gridfs put song.mp3
此处,gridfs是将存储文件的数据库的名称。如果数据库不存在,MongoDB 将自动动态创建一个新文档。Song.mp3 是上传文件的名称。要查看数据库中的文件文档,您可以使用查找查询 –
>db.fs.files.find()
上面的命令返回以下文档 –
{
_id: ObjectId('534a811bf8b4aa4d33fdf94d'),
filename: "song.mp3",
chunkSize: 261120,
uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",
length: 10401959
}
我们还可以使用以下代码查看与存储文件相关的 fs.chunks 集合中存在的所有块,使用前一个查询中返回的文档 ID –
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})
在我的例子中,查询返回了 40 个文档,这意味着整个 mp3 文档被分成 40 个数据块。
MongoDB – 上限集合
上限集合是固定大小的循环集合,它们遵循插入顺序以支持创建、读取和删除操作的高性能。通过循环,这意味着当分配给集合的固定大小用完时,它将开始删除集合中最旧的文档,而无需提供任何明确的命令。
如果更新导致文档大小增加,上限集合会限制对文档的更新。由于上限集合按磁盘存储的顺序存储文档,因此可以确保文档大小不会增加磁盘上分配的大小。上限集合最适合存储日志信息、缓存数据或任何其他大量数据。
创建上限集合
要创建一个有上限的集合,我们使用普通的 createCollection 命令,但ipped选项为true并指定集合的最大大小(以字节为单位)。
>db.createCollection("cappedLogCollection",{capped:true,size:10000})
除了集合大小,我们还可以使用max参数限制集合中的文档数量–
>db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})
如果要检查集合是否有上限,请使用以下isCapped命令 –
>db.cappedLogCollection.isCapped()
如果您计划将现有集合转换为上限,则可以使用以下代码进行操作 –
>db.runCommand({"convertToCapped":"posts",size:10000})
此代码会将我们现有的收藏帖子转换为有上限的收藏。
查询上限集合
默认情况下,对上限集合的查找查询将按插入顺序显示结果。但是,如果您希望以相反的顺序检索文档,请使用sort命令,如下面的代码所示 –
>db.cappedLogCollection.find().sort({$natural:-1})
关于有上限的集合,还有其他一些值得了解的要点 –
-
我们无法从有上限的集合中删除文档。
-
上限集合中不存在默认索引,甚至在 _id 字段中也不存在。
-
在插入新文档时,MongoDB 不必实际在磁盘上寻找可以容纳新文档的位置。它可以在集合的尾部盲目插入新文档。这使得在上限集合中的插入操作非常快。
-
类似地,在读取文档时,MongoDB 以与磁盘上存在的顺序相同的顺序返回文档。这使得读取操作非常快。
MongoDB – 自动递增序列
MongoDB 没有开箱即用的自动增量功能,如 SQL 数据库。默认情况下,它使用_id字段的 12 字节 ObjectId作为主键来唯一标识文档。但是,在某些情况下,我们可能希望 _id 字段具有除 ObjectId 之外的一些自动递增值。
由于这不是 MongoDB 中的默认功能,我们将按照 MongoDB 文档的建议,通过使用计数器集合以编程方式实现此功能。
使用计数器集合
考虑以下产品文档。我们希望 _id 字段是一个自动递增的整数序列,从 1,2,3,4 到 n。
{
"_id":1,
"product_name": "Apple iPhone",
"category": "mobiles"
}
为此,创建一个计数器集合,它将跟踪所有序列字段的最后一个序列值。
>db.createCollection("counters")
现在,我们将在 counters 集合中插入以下文档,并将productid作为其键 –
{
"_id":"productid",
"sequence_value": 0
}
字段sequence_value跟踪序列的最后一个值。
使用以下代码在计数器集合中插入此序列文档 –
>db.counters.insert({_id:"productid",sequence_value:0})
创建 Javascript 函数
现在,我们将创建一个函数getNextSequenceValue,它将序列名称作为其输入,将序列号增加 1 并返回更新后的序列号。在我们的例子中,序列名称是productid。
>function getNextSequenceValue(sequenceName){
var sequenceDocument = db.counters.findAndModify({
query:{_id: sequenceName },
update: {$inc:{sequence_value:1}},
new:true
});
return sequenceDocument.sequence_value;
}
使用 JavaScript 函数
我们现在将在创建新文档并将返回的序列值分配为文档的 _id 字段时使用函数 getNextSequenceValue。
使用以下代码插入两个示例文档 –
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Apple iPhone",
"category":"mobiles"
})
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Samsung S3",
"category":"mobiles"
})
如您所见,我们使用了 getNextSequenceValue 函数来设置 _id 字段的值。
为了验证功能,让我们使用 find 命令获取文档 –
>db.products.find()
上述查询返回以下具有自动递增 _id 字段的文档 –
{ "_id" : 1, "product_name" : "Apple iPhone", "category" : "mobiles"}
{ "_id" : 2, "product_name" : "Samsung S3", "category" : "mobiles" }
