Kibana – 快速指南
Kibana – 快速指南
Kibana – 概述
Kibana是一个开源的基于浏览器的可视化工具,主要用于分析以折线图、条形图、饼图、热图、区域图、坐标图、仪表、目标、时间轴等形式的大量日志。易于预测或查看输入源的错误趋势或其他重要事件的变化。Kibana 与 Elasticsearch 和 Logstash 同步工作,它们共同构成了所谓的ELK堆栈。
什么是 ELK 堆栈?
ELK代表 Elasticsearch、Logstash 和 Kibana。ELK是全球用于日志分析的流行日志管理平台之一。在 ELK 堆栈中,Logstash 从不同的输入源中提取日志数据或其他事件。它处理事件,然后将它们存储在 Elasticsearch 中。
Kibana是一个可视化工具,它从 Elasticsearch 访问日志,并能够以折线图、条形图、饼图等形式展示给用户。
ELK Stack 的基本流程如下图所示 –
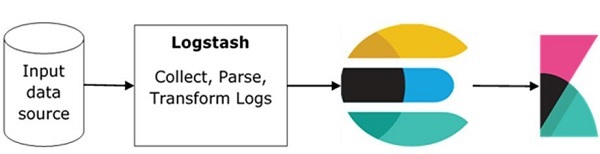
Logstash 负责从归档日志的所有远程源收集数据并将其推送到 Elasticsearch。
Elasticsearch 充当收集数据的数据库,Kibana 使用来自 Elasticsearch 的数据以条形图、饼图、热图的形式向用户表示数据,如下所示 –
它实时向用户显示数据,例如,每天或每小时。Kibana UI 用户友好,初学者很容易理解。
Kibana 的特点
Kibana 为其用户提供以下功能 –
可视化
Kibana 有很多方法可以轻松地将数据可视化。一些常用的有垂直条形图、水平条形图、饼图、折线图、热图等。
仪表盘
当我们准备好可视化时,所有这些都可以放在一个板上 – 仪表板。一起观察不同的部分可以让您清楚地了解到底发生了什么。
开发工具
您可以使用开发工具处理索引。初学者可以从开发工具添加虚拟索引,也可以添加、更新、删除数据并使用索引来创建可视化。
报告
所有以可视化和仪表板形式的数据都可以转换为报告(CSV 格式),嵌入代码或以 URL 的形式与他人共享。
过滤器和搜索查询
您可以使用过滤器和搜索查询从仪表板或可视化工具获取特定输入所需的详细信息。
插件
您可以添加第三方插件以在 Kibana 中添加一些新的可视化或其他 UI。
坐标和区域地图
Kibana 中的坐标和区域地图有助于在地理地图上显示可视化,从而提供真实的数据视图。
时狮
Timelion,也称为时间线,是另一种可视化工具,主要用于基于时间的数据分析。为了使用时间线,我们需要使用简单的表达式语言,它可以帮助我们连接到索引并对数据执行计算以获得我们需要的结果。它有助于在周、月等方面将数据与前一个周期进行比较。
帆布
Canvas 是 Kibana 的另一个强大功能。使用画布可视化,您可以用不同的颜色组合、形状、文本、多页(基本上称为工作板)来表示您的数据。
Kibana 的优势
Kibana 为其用户提供以下优势 –
-
包含基于开源浏览器的可视化工具,主要用于以折线图、条形图、饼图、热图等形式分析大量日志。
-
简单易懂,初学者易懂。
-
易于将可视化和仪表板转换为报告。
-
画布可视化有助于以简单的方式分析复杂的数据。
-
Kibana 中的 Timelion 可视化有助于向后比较数据以更好地了解性能。
Kibana 的缺点
-
如果版本不匹配,向 Kibana 添加插件会非常繁琐。
-
当您想从旧版本升级到新版本时,您往往会遇到问题。
Kibana – 环境设置
要开始使用 Kibana,我们需要安装 Logstash、Elasticsearch 和 Kibana。在本章中,我们将在这里尝试了解 ELK 堆栈的安装。
我们将在这里讨论以下安装 –
- 弹性搜索安装
- Logstash 安装
- Kibana 安装
弹性搜索安装
我们的库中有关于 Elasticsearch 的详细文档。您可以在此处查看elasticsearch 安装。您必须按照教程中提到的步骤安装 Elasticsearch。
安装完成后,按如下方式启动 elasticsearch 服务器 –
步骤1
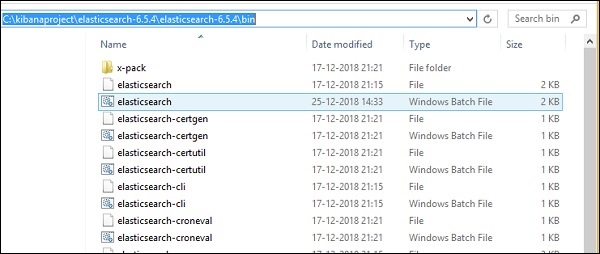
对于 Windows
> cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin > elasticsearch
请注意对于 windows 用户,JAVA_HOME 变量必须设置为 java jdk 路径。
对于 Linux
$ cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin $ elasticsearch
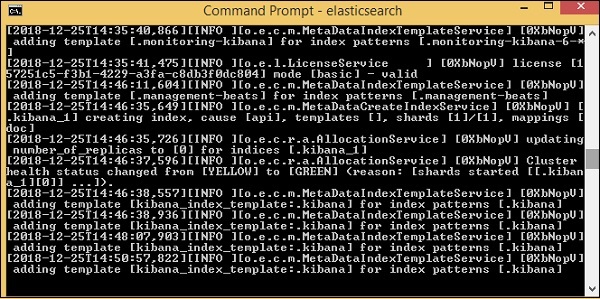
elasticsearch 的默认端口是 9200。完成后,您可以在 localhost http://localhost:9200/上的端口 9200 处检查 elasticsearch,如下所示 –
Logstash 安装
对于Logstash安装,按照此elasticsearch安装这已经是我们的图书馆现有的。
Kibana 安装
前往 Kibana 官方网站 – https://www.elastic.co/products/kibana
单击右上角的下载链接,它将显示如下屏幕 –
单击 Kibana 的下载按钮。请注意,要使用 Kibana,我们需要 64 位机器,它不适用于 32 位。
在本教程中,我们将使用 Kibana 版本 6。下载选项适用于 Windows、Mac 和 Linux。您可以根据自己的选择下载。
创建一个文件夹并解压 kibana 的 tar/zip 下载。我们将使用在 elasticsearch 中上传的示例数据。因此,现在让我们看看如何启动 elasticsearch 和 kibana。为此,请转到 Kibana 解压后的文件夹。
对于 Windows
> cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin > kibana
对于 Linux
$ cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin $ kibana
Kibana 启动后,用户可以看到以下屏幕 –
在控制台中看到就绪信号后,您可以使用http://localhost:5601/在浏览器中打开 Kibana 。 kibana 可用的默认端口是 5601。
Kibana 的用户界面如下所示 –
在下一章中,我们将学习如何使用 Kibana 的 UI。要了解 Kibana UI 上的 Kibana 版本,请转到左侧的管理选项卡,它会显示我们当前使用的 Kibana 版本。
Kibana – Elk Stack 简介
Kibana 是一个开源的可视化工具,主要用于以线图、条形图、饼图、热图等形式分析大量日志。 Kibana 与 Elasticsearch 和 Logstash 同步工作,共同形成所谓的ELK堆栈。
ELK代表 Elasticsearch、Logstash 和 Kibana。ELK是全球用于日志分析的流行日志管理平台之一。
在 ELK 堆栈中 –
-
Logstash从不同的输入源中提取日志数据或其他事件。它处理事件,然后将其存储在 Elasticsearch 中。
-
Kibana是一个可视化工具,它从 Elasticsearch 访问日志,并能够以折线图、条形图、饼图等形式展示给用户。
在本教程中,我们将与 Kibana 和 Elasticsearch 密切合作,以不同的形式可视化数据。
在本章中,让我们了解如何与 ELK 堆栈一起工作。此外,您还将看到如何 –
- 将 CSV 数据从 Logstash 加载到 Elasticsearch。
- 在 Kibana 中使用来自 Elasticsearch 的索引。
将 CSV 数据从 Logstash 加载到 Elasticsearch
我们将使用 CSV 数据通过 Logstash 将数据上传到 Elasticsearch。为了进行数据分析,我们可以从 kaggle.com 网站获取数据。Kaggle.com 站点上传了所有类型的数据,用户可以使用它进行数据分析。
我们从这里获取了 countries.csv 数据:https :
//www.kaggle.com/fernandol/countries-of-the-world。您可以下载 csv 文件并使用它。
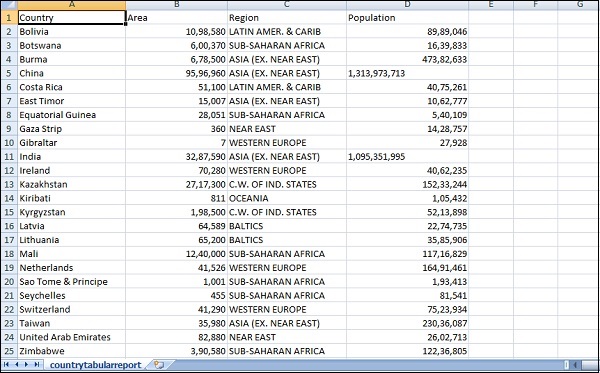
我们将要使用的 csv 文件具有以下详细信息。
文件名 – countrydata.csv
列 – “国家”、“地区”、“人口”、“地区”
您还可以创建一个虚拟的 csv 文件并使用它。我们将使用logstash 将这些数据从countriesdata.csv转储到elasticsearch 。
在终端中启动 elasticsearch 和 Kibana 并保持运行。我们必须为 logstash 创建配置文件,该文件将包含有关 CSV 文件列的详细信息以及其他详细信息,如下面的 logstash-config 文件所示 –
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}
在配置文件中,我们创建了 3 个组件 –
输入
我们需要指定输入文件的路径,在我们的例子中是一个 csv 文件。将存储 csv 文件的路径提供给路径字段。
筛选
将使用带有分隔符的 csv 组件,在我们的例子中是逗号,还有可用于我们的 csv 文件的列。由于 logstash 将所有传入的数据视为 string ,如果我们希望将任何列用作 integer ,则必须使用 mutate 指定相同的 float ,如上所示。
输出
对于输出,我们需要指定我们需要放置数据的位置。在这里,在我们的例子中,我们使用的是 elasticsearch。需要提供给 elasticsearch 的数据是它运行的主机,我们将其称为 localhost。中的下一个字段是索引,我们将其命名为国家/地区-currentdate。一旦数据在 Elasticsearch 中更新,我们必须在 Kibana 中使用相同的索引。
将上述配置文件保存为logstash_countries.config。请注意,我们需要在下一步中将此配置的路径提供给 logstash 命令。
要将数据从 csv 文件加载到 elasticsearch,我们需要启动 elasticsearch 服务器 –
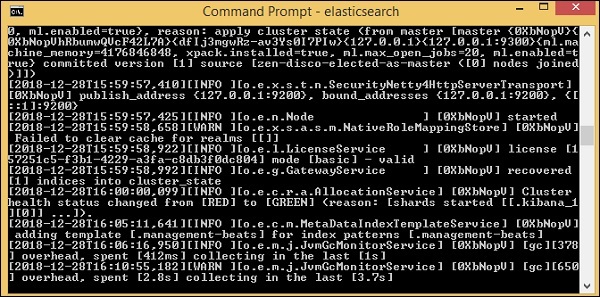
现在,在浏览器中运行http://localhost:9200以确认 elasticsearch 是否运行成功。
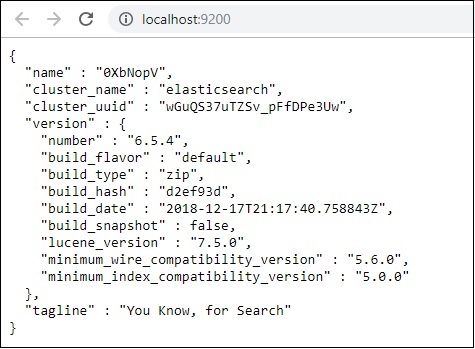
我们正在运行elasticsearch。现在转到安装logstash的路径并运行以下命令将数据上传到elasticsearch。
> logstash -f logstash_countries.conf
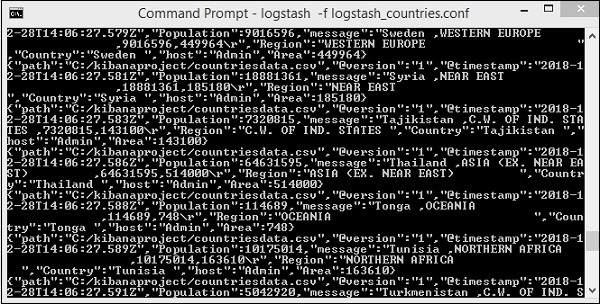
上面的屏幕显示了从 CSV 文件加载到 Elasticsearch 的数据。要知道我们是否在 Elasticsearch 中创建了索引,我们可以检查如下 –
我们可以看到如上图所示创建的 countriesdata-28.12.2018 索引。

该指数的详细信息 – countries-28.12.2018 如下 –
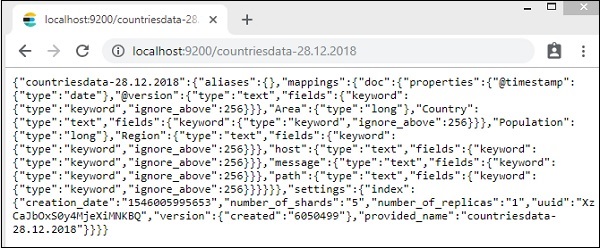
请注意,当数据从 logstash 上传到 elasticsearch 时,会创建带有属性的映射详细信息。
在 Kibana 中使用来自 Elasticsearch 的数据
目前,我们在 localhost 上运行 Kibana,端口 5601 – http://localhost:5601。Kibana 的 UI 显示在此处 –
请注意,我们已经将 Kibana 连接到 Elasticsearch,我们应该能够在 Kibana 中看到
索引 :countries- 28.12.2018。
在 Kibana UI 中,单击左侧的管理菜单选项 –
现在,单击索引管理 –
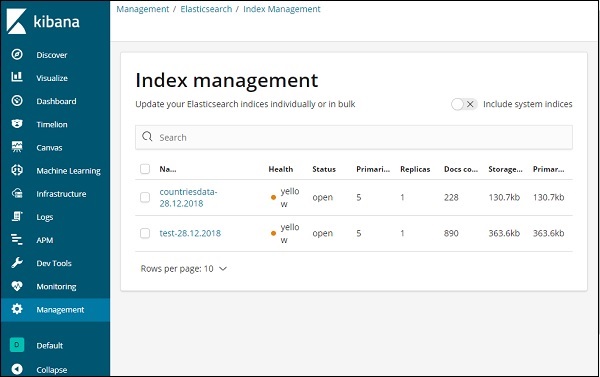
Elasticsearch 中的索引显示在索引管理中。我们将在 Kibana 中使用的索引是 countrydata-28.12.2018。
因此,既然我们已经在 Kibana 中拥有了 elasticsearch 索引,接下来将了解如何使用 Kibana 中的索引以饼图、条形图、折线图等形式可视化数据。
Kibana – 加载示例数据
我们已经看到了如何将数据从 logstash 上传到 elasticsearch。我们将在这里使用 logstash 和 elasticsearch 上传数据。但是关于我们需要使用的具有日期、经度和纬度字段的数据,我们将在接下来的章节中学习。如果我们没有 CSV 文件,我们还将了解如何直接在 Kibana 中上传数据。
在本章中,我们将涵盖以下主题 –
- 在 Elasticsearch 中使用 Logstash 上传具有日期、经度和纬度字段的数据
- 使用开发工具上传批量数据
使用 Logstash 上传 Elasticsearch 中具有字段的数据
我们将使用 CSV 格式的数据,同样取自 Kaggle.com,它处理可用于分析的数据。
此处使用的家庭医疗访问数据来自 Kaggle.com 网站。
以下是 CSV 文件可用的字段 –
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude","Longitude", "Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
Home_visits.csv 如下 –
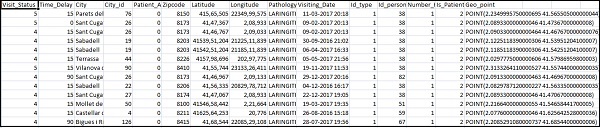
以下是与 logstash 一起使用的 conf 文件 –
input {
file {
path => "C:/kibanaproject/home_visits.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns =>
["Visit_Status","Time_Delay","City","City_id","Patient_Age",
"Zipcode","Latitude","Longitude","Pathology","Visiting_Date",
"Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
}
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "medicalvisits-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}
默认情况下,logstash 将所有要在 elasticsearch 中上传的内容视为字符串。如果您的 CSV 文件有日期字段,您需要执行以下操作以获取日期格式。
对于日期字段 –
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
在地理位置的情况下,elasticsearch 的理解与 –
"location": {
"lat":41.565505000000044,
"lon": 2.2349995750000695
}
所以我们需要确保我们有elasticsearch需要的格式的经度和纬度。所以首先我们需要将经度和纬度转换为浮点数,然后重命名它,以便它可以作为带有lat和lon的location json 对象的一部分。此处显示相同的代码 –
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
要将字段转换为整数,请使用以下代码 –
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
处理好字段后,运行以下命令在 elasticsearch 中上传数据 –
- 进入 Logstash bin 目录并运行以下命令。
logstash -f logstash_homevisists.conf
- 完成后,您应该在elasticsearch中看到logstash conf文件中提到的索引,如下所示 –
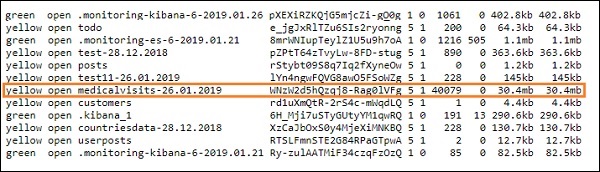
我们现在可以在上面上传的索引上创建索引模式,并进一步使用它来创建可视化。
使用开发工具上传批量数据
我们将使用 Kibana UI 中的开发工具。Dev Tools 有助于在 Elasticsearch 中上传数据,而无需使用 Logstash。我们可以使用 Dev Tools 在 Kibana 中发布、放置、删除、搜索我们想要的数据。
在本节中,我们将尝试在 Kibana 本身中加载示例数据。我们可以用它来练习示例数据并使用 Kibana 功能来更好地理解 Kibana。
让我们从以下 url 中获取 json 数据并将其上传到 Kibana。同样,您可以尝试在 Kibana 中加载任何示例 json 数据。
在我们开始上传示例数据之前,我们需要有带索引的 json 数据,以便在 elasticsearch 中使用。当我们使用 logstash 上传它时,logstash 会注意添加索引,用户不必担心 elasticsearch 所需的索引。
普通 Json 数据
[
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"},
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I.London. The palace."},
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the
EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
]
与 Kibana 一起使用的 json 代码必须索引如下 –
{"index":{"_index":"shakespeare","_id":0}}
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_id":1}}
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"",
"text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_id":2}}
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL
of WESTMORELAND, SIR WALTER BLUNT, and others"}
请注意,jsonfile 中有一个额外的数据 – {“index”:{“_index”:”nameofindex”,”_id”:key}}。
要转换任何与 elasticsearch 兼容的示例 json 文件,这里我们在 php 中有一个小代码,它将输出给定为 elasticsearch 想要的格式的 json 文件 –
PHP代码
<?php
$myfile = fopen("todo.json", "r") or die("Unable to open file!"); // your json
file here
$alldata = fread($myfile,filesize("todo.json"));
fclose($myfile);
$farray = json_decode($alldata);
$afinalarray = [];
$index_name = "todo";
$i=0;
$myfile1 = fopen("todonewfile.json", "w") or die("Unable to open file!"); //
writes a new file to be used in kibana dev tool
foreach ($farray as $a => $value) {
$_index = json_decode('{"index": {"_index": "'.$index_name.'", "_id": "'.$i.'"}}');
fwrite($myfile1, json_encode($_index));
fwrite($myfile1, "\n");
fwrite($myfile1, json_encode($value));
fwrite($myfile1, "\n");
$i++;
}
?>
我们从https://jsonplaceholder.typicode.com/todos 中获取了 todo json 文件,并使用 php 代码转换为我们需要在 Kibana 中上传的格式。
要加载示例数据,请打开开发工具选项卡,如下所示 –
我们现在将使用如上所示的控制台。我们将通过php代码运行我们得到的json数据。
在开发工具中用于上传 json 数据的命令是 –
POST _bulk
请注意,我们正在创建的索引的名称是todo。
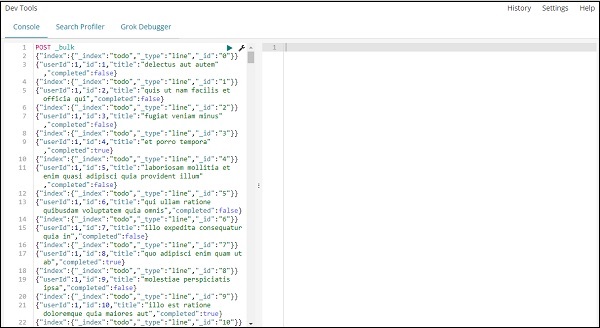
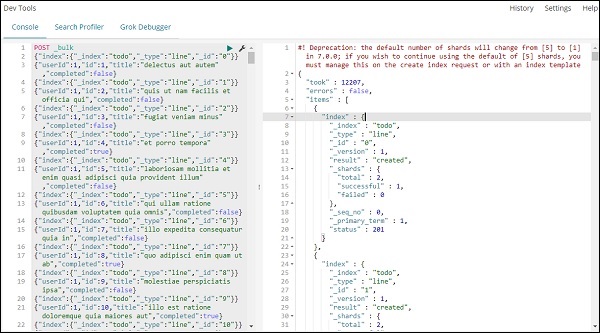
单击绿色按钮后,数据已上传,您可以检查是否在 elasticsearch 中创建了索引,如下所示 –

您可以在开发工具本身中检查相同的内容,如下所示 –
命令 –
GET /_cat/indices
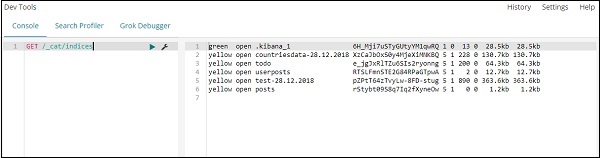
如果你想在你的 index:todo 中搜索一些东西,你可以这样做,如下所示 –
开发工具中的命令
GET /todo/_search
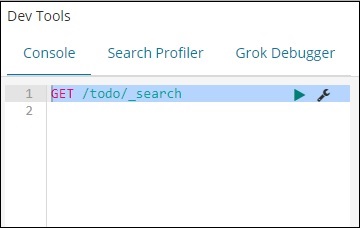
上述搜索的输出如下所示 –
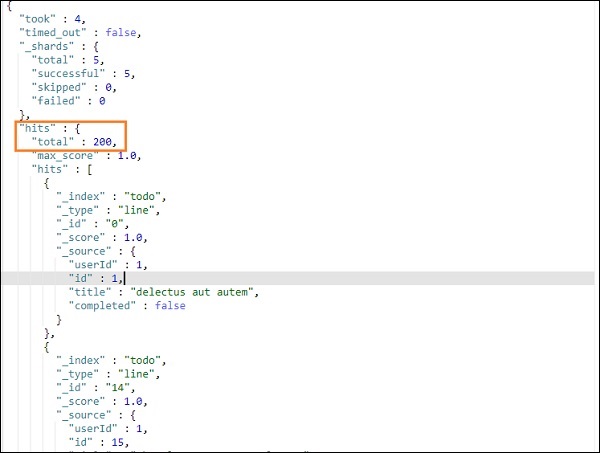
它给出了 todoindex 中存在的所有记录。我们得到的总记录是 200。
在 todo 索引中搜索记录
我们可以使用以下命令来做到这一点 –
GET /todo/_search
{
"query":{
"match":{
"title":"delectusautautem"
}
}
}
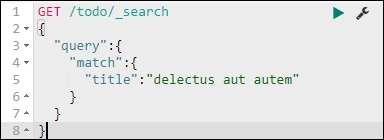
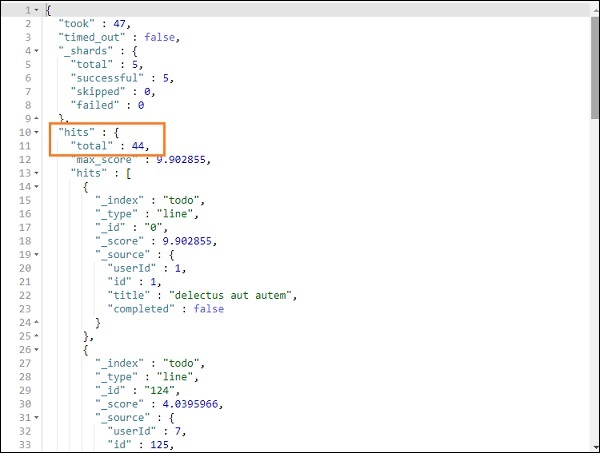
我们能够获取与我们给出的标题匹配的记录。
Kibana – 管理
Kibana 中的 Management 部分用于管理索引模式。在本章中,我们将讨论以下内容 –
- 创建没有时间过滤器字段的索引模式
- 使用时间过滤器字段创建索引模式
创建没有时间过滤器字段的索引模式
为此,请转到 Kibana UI 并单击管理 –
要使用 Kibana,我们首先必须创建从 elasticsearch 填充的索引。您可以从 Elasticsearch → 索引管理中获取所有可用的索引,如图所示 –
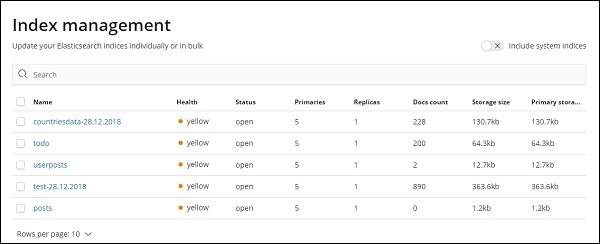
目前elasticsearch有上述指标。Docs 计数告诉我们每个索引中可用的记录数。如果有任何更新的索引,文档计数将不断变化。主存储告诉上传的每个索引的大小。
要在 Kibana 中创建新索引,我们需要单击索引模式,如下所示 –

单击索引模式后,我们会看到以下屏幕 –
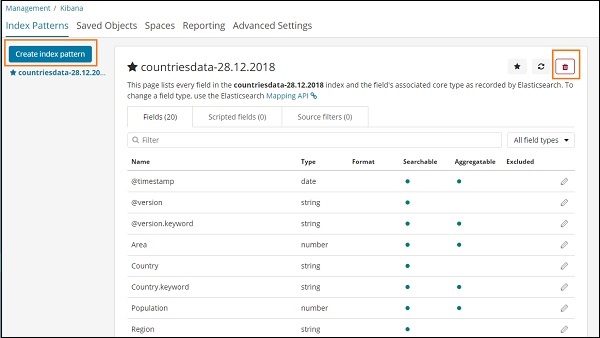
请注意,“创建索引模式”按钮用于创建新索引。回想一下,我们已经在教程开始时创建了 countrydata-28.12.2018。
使用时间过滤器字段创建索引模式
单击创建索引模式以创建新索引。
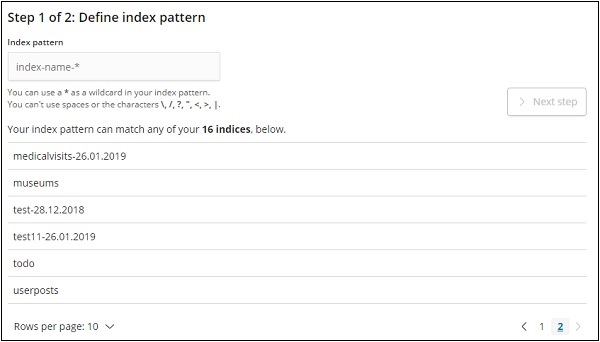
显示来自 elasticsearch 的索引,选择一个以创建新索引。
现在,点击下一步。
下一步是配置设置,您需要在其中输入以下内容 –
-
时间过滤字段名称用于根据时间过滤数据。下拉列表将显示索引中所有与时间和日期相关的字段。
在下图中,我们将Visiting_Date作为日期字段。选择Visiting_Date作为时间过滤器字段名称。
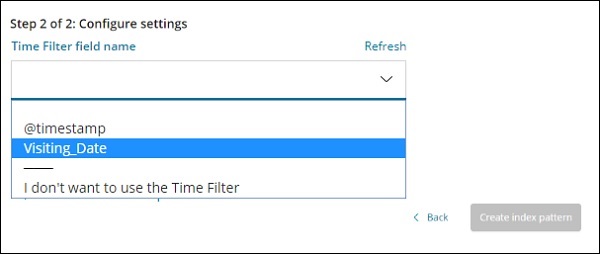
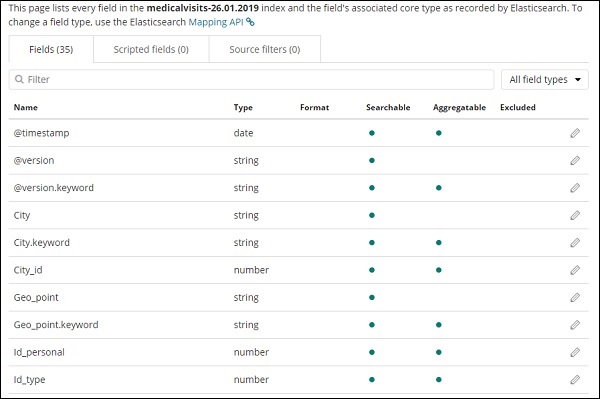
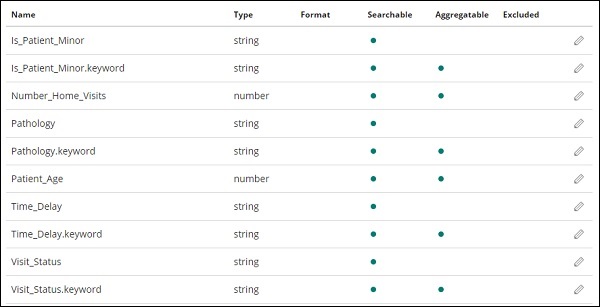
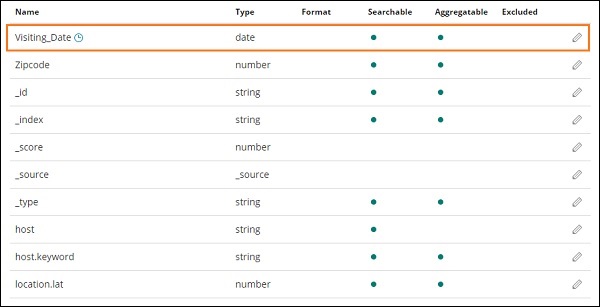
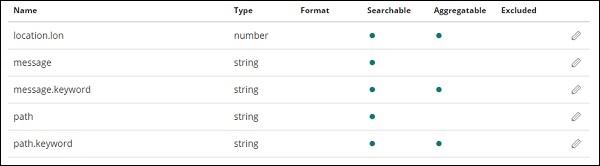
单击创建索引模式按钮以创建索引。完成后,它将显示您的索引 medicalvisits-26.01.2019 中存在的所有字段,如下所示 –
我们在索引 medicalvisits-26.01.2019 中有以下字段 –
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude ","Longitude","Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_ Visits","Is_Patient_Minor","Geo_point"].
该指数包含家庭医疗访问的所有数据。从 logstash 插入时,elasticsearch 添加了一些额外的字段。
Kibana – 探索
本章讨论 Kibana UI 中的 Discover Tab。我们将详细了解以下概念 –
- 没有日期字段的索引
- 带日期字段的索引
没有日期字段的索引
在左侧菜单中选择发现,如下所示 –
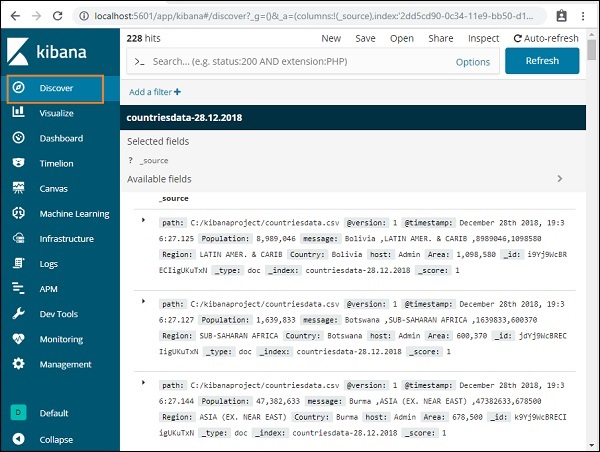
在右侧,它显示了我们在上一章中创建的countrydata-28.12.2018索引中可用数据的详细信息。
在左上角,它显示了可用的记录总数 –

我们可以在此选项卡中获取索引(countriesdata-28.12.2018)内数据的详细信息。在上面显示的屏幕的左上角,我们可以看到新建、保存、打开、共享、检查和自动刷新等按钮。
如果您单击自动刷新,它将显示如下所示的屏幕 –
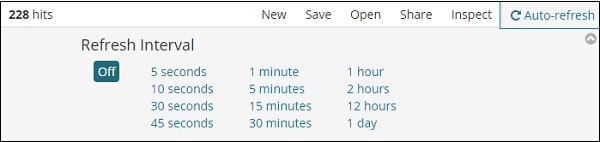
您可以通过单击上方的秒、分或小时来设置自动刷新间隔。Kibana 将在您设置的每个间隔计时器后自动刷新屏幕并获取新数据。
来自index:countriesdata-28.12.2018的数据显示如下 –
所有字段和数据都按行显示。单击箭头展开行,它将以表格格式或 JSON 格式为您提供详细信息

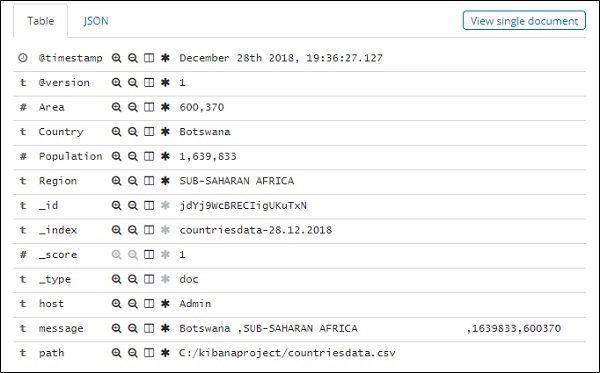
JSON 格式
左侧有一个按钮,称为查看单个文档。
如果单击它,它将显示页面内的行或行中的数据,如下所示 –
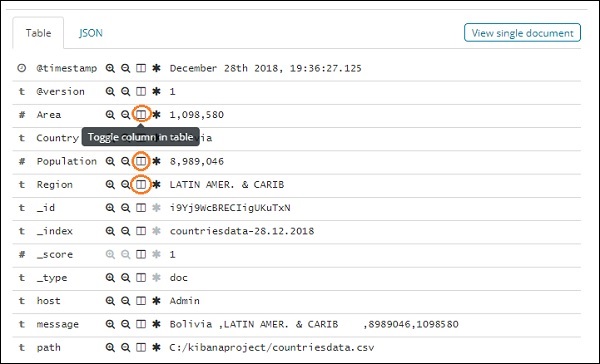
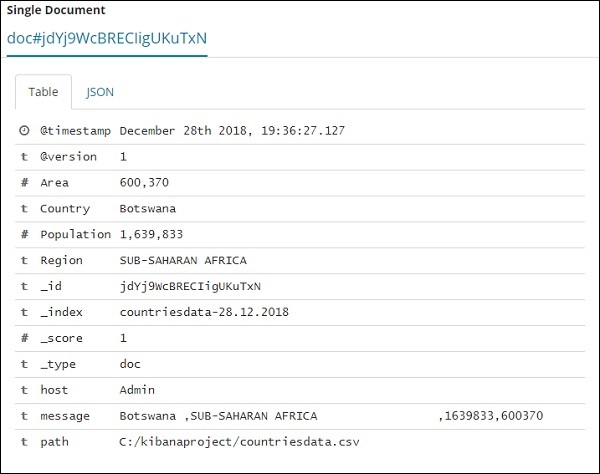
尽管我们在这里获得了所有数据详细信息,但很难逐一逐一查看。
现在让我们尝试以表格格式获取数据。展开一行并单击每个字段中可用的切换列选项的一种方法如下所示 –
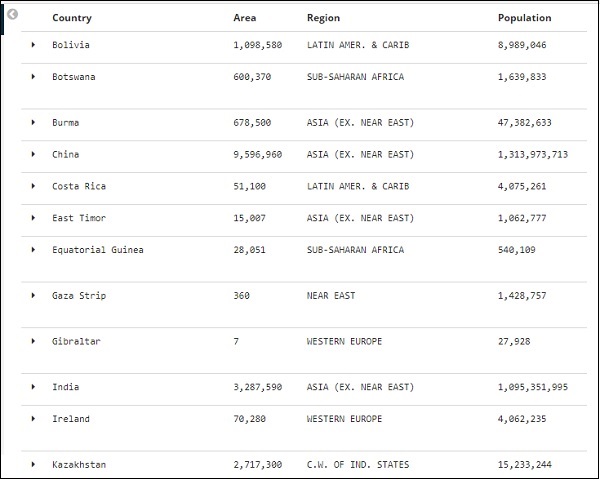
单击每个可用的表选项中的切换列,您会注意到数据以表格格式显示 –

在这里,我们选择了 Country、Area、Region 和 Population 字段。折叠展开的行,您现在应该会看到表格格式的所有数据。
我们选择的字段显示在屏幕左侧,如下所示 –
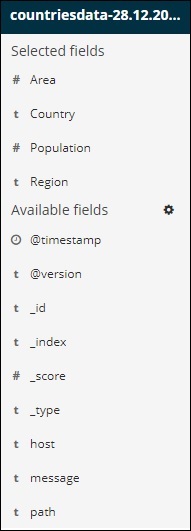
请注意,有 2 个选项 – Selected fields和Available fields。我们选择以表格格式显示的字段是所选字段的一部分。如果您想删除任何字段,您可以单击删除按钮,该按钮将在所选字段选项中的字段名称中看到。
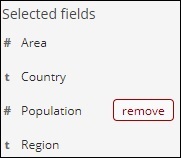
删除后,该字段将在可用字段中可用,您可以通过单击添加按钮添加回来,该按钮将显示在您想要的字段中。您还可以使用此方法通过从可用字段中选择所需字段以表格格式获取数据。
我们在 Discover 中有一个可用的搜索选项,我们可以使用它来搜索索引内的数据。让我们在这里尝试与搜索选项相关的示例 –
假设您想搜索印度国家,您可以执行以下操作 –
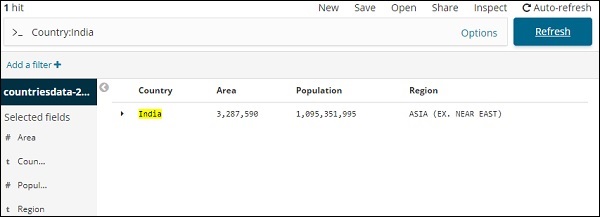
您可以键入搜索详细信息,然后单击“更新”按钮。如果您想搜索以 Aus 开头的国家,您可以按如下方式进行 –

点击更新查看结果
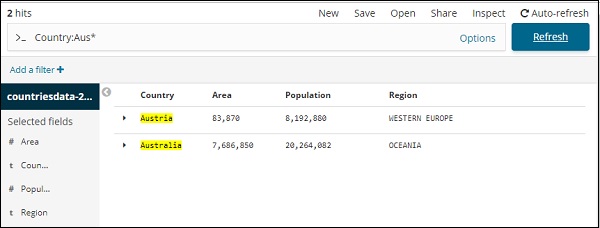
在这里,我们有两个以 Aus* 开头的国家/地区。搜索字段有一个选项按钮,如上所示。当用户单击它时,它会显示一个切换按钮,打开时该按钮有助于编写搜索查询。
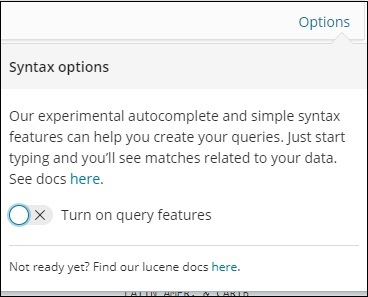
打开查询功能并在搜索中键入字段名称,它将显示该字段可用的选项。
例如,Country 字段是一个字符串,它显示字符串字段的以下选项 –
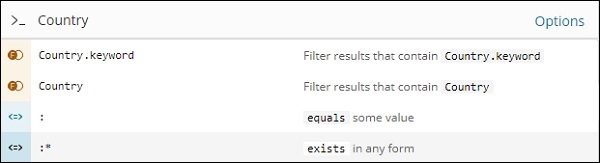
同样,区域是一个数字字段,它显示数字字段的以下选项 –
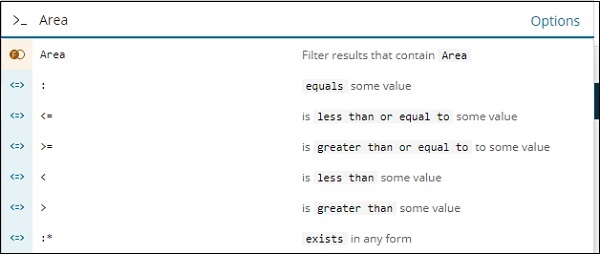
您可以尝试不同的组合并根据您在“发现”字段中的选择过滤数据。可以使用“保存”按钮保存“发现”选项卡内的数据,以便将来使用。
要保存发现中的数据,请单击右上角的保存按钮,如下所示 –
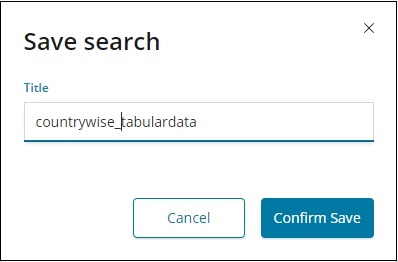
为您的搜索指定标题,然后单击“确认保存”以保存它。保存后,下次访问“发现”选项卡时,您可以单击右上角的“打开”按钮以获取保存的标题,如下所示 –
您还可以使用右上角的共享按钮与他人共享数据。如果单击它,您可以找到如下所示的共享选项 –
您可以使用 CSV 报告或以固定链接的形式共享它。
onclick CSV 报告可用的选项是 –
单击生成 CSV 以获取要与他人共享的报告。
永久链接的可用选项如下 –
快照选项将提供一个 Kibana 链接,该链接将显示当前搜索中可用的数据。
Saved object 选项将提供一个 Kibana 链接,该链接将显示您搜索中最近可用的数据。
快照 – http://localhost:5601/goto/309a983483fccd423950cfb708fabfa5保存的对象:http://localhost:5601/app/kibana#/discover/40bd89d0-10b1-11e9-9876-4f37()e
您可以使用“发现”选项卡和可用的搜索选项,获得的结果可以保存并与他人共享。
带日期字段的索引
转到“发现”选项卡并选择索引:medicalvisits-26.01.2019
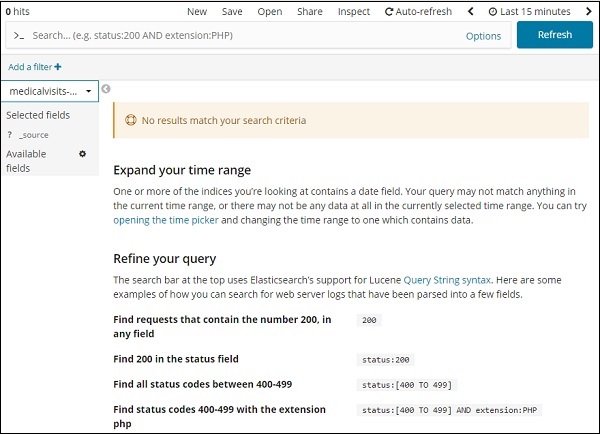
它在我们选择的索引的最后 15 分钟内显示了消息 – “没有结果符合您的搜索条件”。该指数有 2015、2016、2017 和 2018 年的数据。
更改时间范围,如下所示 –
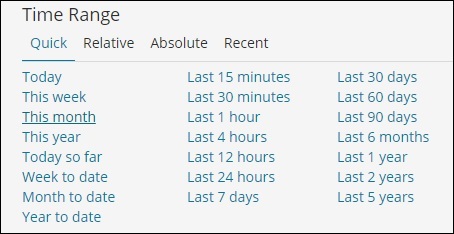
单击“绝对”选项卡。
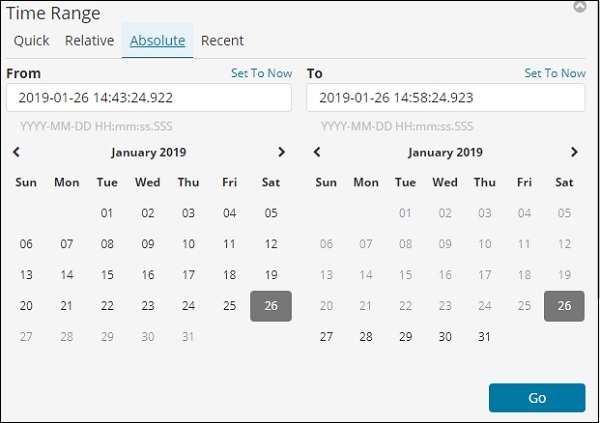
选择日期 From − 1st Jan 2017 和 To − 31st Dec2017,因为我们将分析 2017 年的数据。
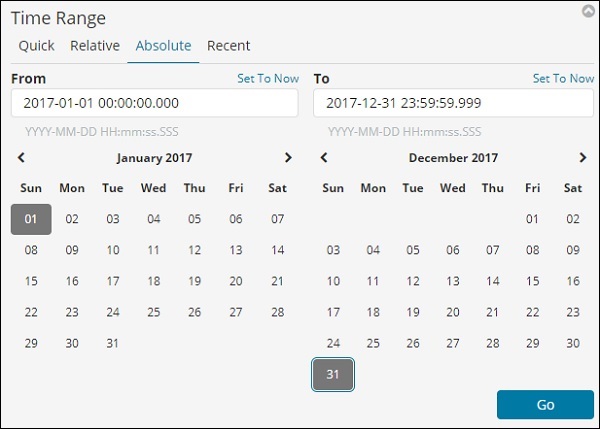
单击 Go 按钮以添加时间范围。它将显示您的数据和条形图如下 –
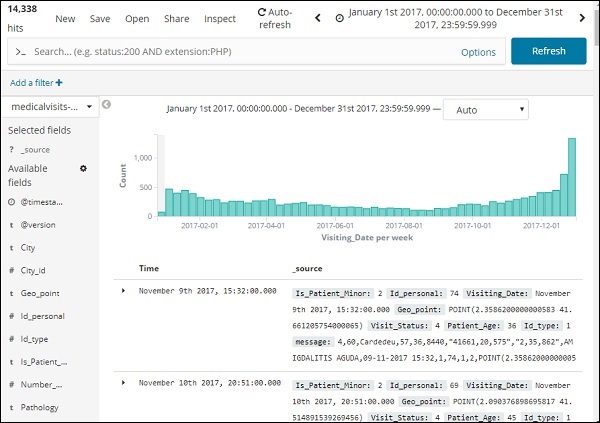
这是 2017 年的月度数据 –
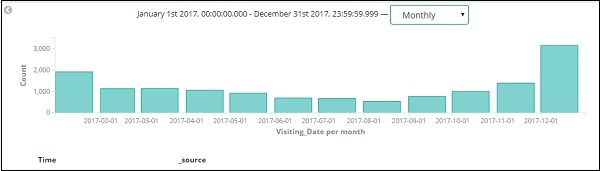
由于我们还将时间与日期一起存储,因此我们也可以按小时和分钟过滤数据。
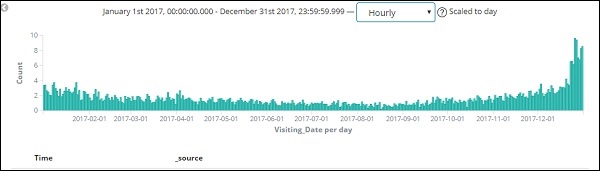
上图显示了 2017 年的每小时数据。
这里是索引中显示的字段 – medicalvisits-26.01.2019

我们在左侧有可用字段,如下所示 –
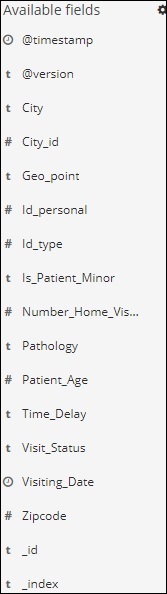
您可以从可用字段中选择字段并将数据转换为表格格式,如下所示。在这里,我们选择了以下字段 –
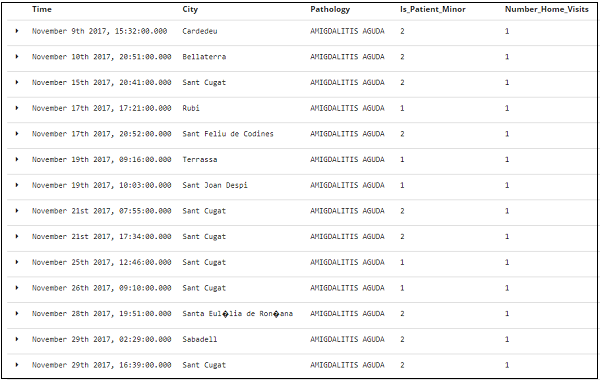
上述字段的表格数据显示在此处 –
Kibana – 聚合和指标
您在学习 Kibana 期间经常遇到的两个术语是 Bucket 和 Metrics Aggregation。本章讨论它们在 Kibana 中扮演的角色以及有关它们的更多详细信息。
什么是 Kibana 聚合?
聚合是指从特定搜索查询或过滤器获得的文档集合或一组文档。聚合构成了在 Kibana 中构建所需可视化的主要概念。
无论何时执行任何可视化,您都需要确定标准,这意味着您希望以何种方式对数据进行分组以对其执行指标。
在本节中,我们将讨论两种类型的聚合 –
- 桶聚合
- 指标聚合
桶聚合
一个bucket主要由一个key和一个document组成。当执行聚合时,文档被放置在各自的桶中。所以最后你应该有一个桶列表,每个桶都有一个文档列表。在 Kibana 中创建可视化时您将看到的 Bucket Aggregation 列表如下所示 –
桶聚合具有以下列表 –
- 日期直方图
- 日期范围
- 过滤器
- 直方图
- IPv4 范围
- 范围
- 重要条款
- 条款
在创建时,您需要为 Bucket Aggregation 决定其中之一,即对存储桶内的文档进行分组。
例如,为了进行分析,请考虑我们在本教程开始时上传的国家/地区数据。国家索引中可用的字段是国家名称、地区、人口、地区。在国家数据中,我们有国家名称及其人口、地区和面积。
让我们假设我们想要区域明智的数据。然后,每个地区可用的国家成为我们的搜索查询,因此在这种情况下,该地区将形成我们的桶。下面的框图显示 R1、R2、R3、R4、R5 和 R6 是我们得到的存储桶,而 c1、c2 ..c25 是文档列表,它们是存储桶 R1 到 R6 的一部分。
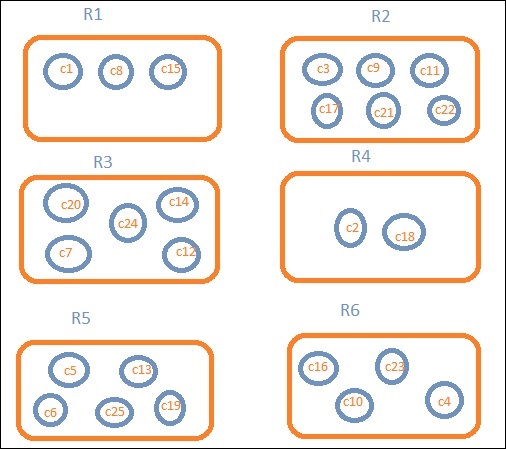
我们可以看到每个桶里都有一些圆圈。它们是基于搜索条件的一组文档,并被认为落入每个桶中。在存储桶 R1 中,我们有文档 c1、c8 和 c15。这些文件是属于该地区的国家,其他国家也一样。因此,如果我们计算 Bucket R1 中的国家/地区,它是 3,R2 为 6,R3 为 6,R4 为 2,R5 为 5,R6 为 4。
因此,通过桶聚合,我们可以聚合桶中的文档,并在这些桶中拥有一个文档列表,如上所示。
到目前为止,我们拥有的 Bucket Aggregation 列表是 –
- 日期直方图
- 日期范围
- 过滤器
- 直方图
- IPv4 范围
- 范围
- 重要条款
- 条款
现在让我们一一详细讨论如何形成这些桶。
日期直方图
日期直方图聚合用于日期字段。因此,您用于可视化的索引,如果该索引中有日期字段,则只能使用此聚合类型。这是一个多桶聚合,这意味着您可以将一些文档作为 1 个以上桶的一部分。有一个用于此聚合的间隔,详细信息如下所示 –
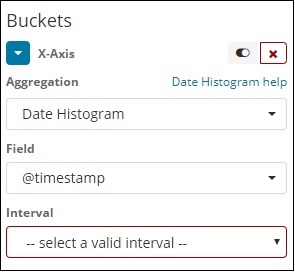
当您选择 Buckets Aggregation 作为日期直方图时,它将显示字段选项,该选项仅提供与日期相关的字段。选择字段后,您需要选择具有以下详细信息的间隔 –
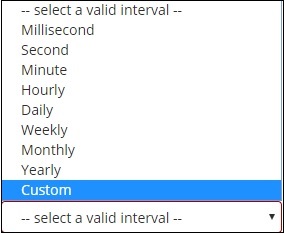
因此,来自所选索引并基于所选字段和间隔的文档将对存储桶中的文档进行分类。例如,如果您选择间隔为每月,则将基于日期的文档转换为桶,并基于月份,即 Jan-Dec 将文档放入桶中。这里 Jan,Feb,..Dec 将是桶。
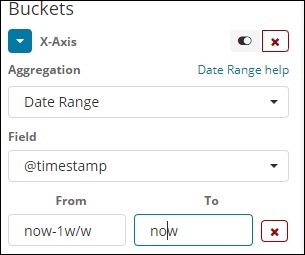
日期范围
您需要一个日期字段才能使用此聚合类型。在这里,我们将有一个日期范围,即要给出的日期和截止日期。存储桶将根据给定的表格和日期提供其文档。
过滤器
使用过滤器类型聚合,将根据过滤器形成桶。在这里,您将获得一个基于过滤条件形成的多存储桶,一个文档可以存在于一个或多个存储桶中。
使用过滤器,用户可以在过滤器选项中编写他们的查询,如下所示 –
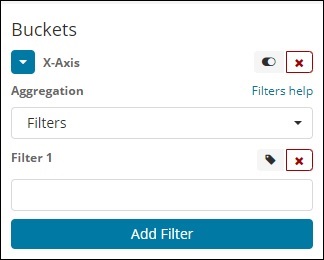
您可以使用添加过滤器按钮添加您选择的多个过滤器。
直方图
这种类型的聚合应用于数字字段,它将根据应用的间隔对存储桶中的文档进行分组。例如,0-50,50-100,100-150 等。
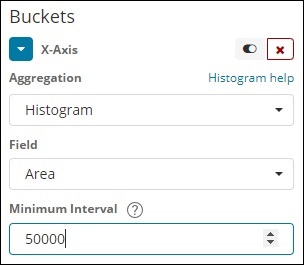
IPv4 范围
这种类型的聚合主要用于 IP 地址。
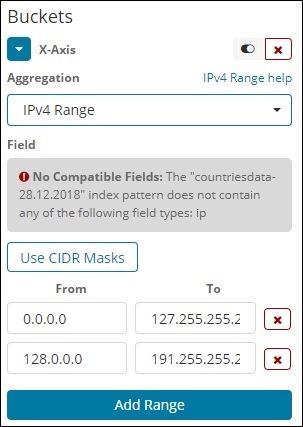
我们拥有的索引 contriesdata-28.12.2018 没有 IP 类型的字段,因此它显示如上所示的消息。如果您碰巧有 IP 字段,则可以在其中指定 From 和 To 值,如上所示。
范围
这种类型的聚合需要字段的类型为数字。您需要指定范围,文档将列在该范围内的桶中。
如果需要,您可以通过单击“添加范围”按钮来添加更多范围。
重要条款
这种类型的聚合主要用于字符串字段。
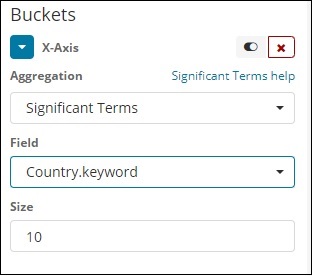
条款
这种类型的聚合用于所有可用的字段,即数字、字符串、日期、布尔值、IP 地址、时间戳等。请注意,这是我们将在我们将在此处理的所有可视化中使用的聚合教程。
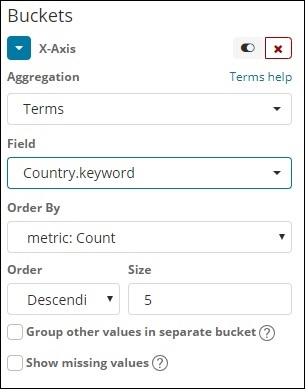
我们有一个选项顺序,我们将根据我们选择的指标对数据进行分组。大小是指要在可视化中显示的桶数。
接下来,让我们谈谈度量聚合。
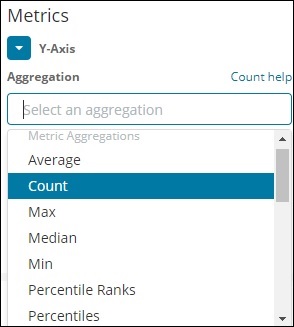
指标聚合
度量聚合主要是指对存储桶中存在的文档进行的数学计算。例如,如果您选择一个数字字段,您可以对其进行的度量计算是 COUNT、SUM、MIN、MAX、AVERAGE 等。
我们将讨论的度量聚合列表在此处给出 –
在本节中,让我们讨论我们将经常使用的重要内容 –
- 平均数
- 数数
- 最大限度
- 最小
- 和
该指标将应用于我们上面已经讨论过的单个存储桶聚合。
接下来,让我们在这里讨论指标聚合列表 –
平均数
这将给出存储桶中存在的文档值的平均值。例如 –

R1 到 R6 是桶。在 R1 中,我们有 c1、c8 和 c15。考虑c1的值是300,c8是500,c15是700,现在得到R1桶的平均值
R1 = c1 的值 + c8 的值 + c15 的值 / 3 = 300 + 500 + 700 / 3 = 500。
存储桶 R1 的平均值为 500。如果您考虑国家数据,则文档的值可能是该地区该国家/地区的面积。
数数
这将给出 Bucket 中存在的文档计数。假设您想要该地区存在的国家/地区的数量,它将是存储桶中存在的文档总数。例如,R1 将是 3、R2 = 6、R3 = 5、R4 = 2、R5 = 5 和 R6 = 4。
最大限度
这将给出存储桶中存在的文档的最大值。考虑上面的例子,如果我们在区域桶中有区域明智的国家数据。每个地区的最大值将是面积最大的国家。因此,每个地区都有一个国家,即 R1 到 R6。
在
这将给出存储桶中存在的文档的最小值。考虑上面的例子,如果我们在区域桶中有区域明智的国家数据。每个地区的最小值将是面积最小的国家。因此,每个地区都有一个国家,即 R1 到 R6。
和
这将给出存储桶中存在的文档值的总和。例如,如果您考虑上面的示例,如果我们想要该地区的总面积或国家/地区,它将是该地区现有文件的总和。
例如,要知道区域 R1 中的国家总数,它将是 3、R2 = 6、R3 = 5、R4 = 2、R5 = 5 和 R6 = 4。
如果我们的文档包含该地区的面积,则 R1 到 R6 将汇总该地区的国家/地区面积。
Kibana – 创建可视化
我们可以以条形图、折线图、饼图等形式可视化我们拥有的数据。在本章中,我们将了解如何创建可视化。
创建可视化
转到 Kibana 可视化,如下所示 –
我们没有创建任何可视化,所以它显示为空白,并且有一个按钮可以创建一个。
点击按钮创建一个如上图所示的可视化,它会带你到如下图所示的屏幕 –
您可以在此处选择可视化数据所需的选项。我们将在接下来的章节中详细了解它们中的每一个。现在将选择饼图开始。
选择可视化类型后,现在您需要选择要处理的索引,它将带您进入如下所示的屏幕 –
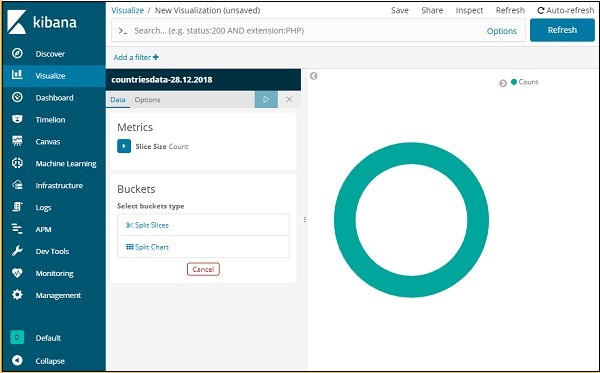
现在我们有一个默认的饼图。我们将使用 countriesdata-28.12.2018 以饼图格式获取国家数据中可用的区域计数。
桶和度量聚合
左侧有指标,我们将选择作为计数。在 Buckets 中,有 2 个选项 Split slices 和 split chart。我们将使用选项拆分切片。
现在,选择拆分切片,它将显示以下选项 –
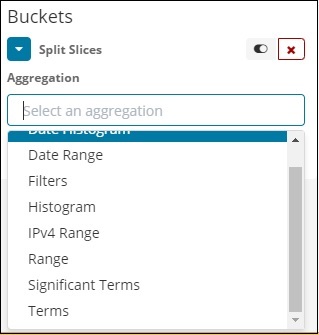
现在,选择聚合作为术语,它将显示更多要输入的选项,如下所示 –
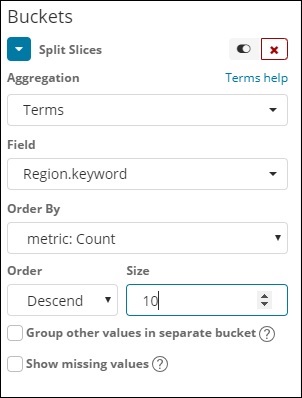
字段下拉列表将选择 index:countriesdata 中的所有字段。我们选择了 Region 字段和 Order By。请注意,我们选择了 Order By 的指标 Count。我们将对其进行降序排序,并将大小取为 10。这意味着在这里,我们将从国家指数中获得前 10 位地区的数量。
现在,单击下面突出显示的分析按钮,您应该会在右侧看到更新的饼图。
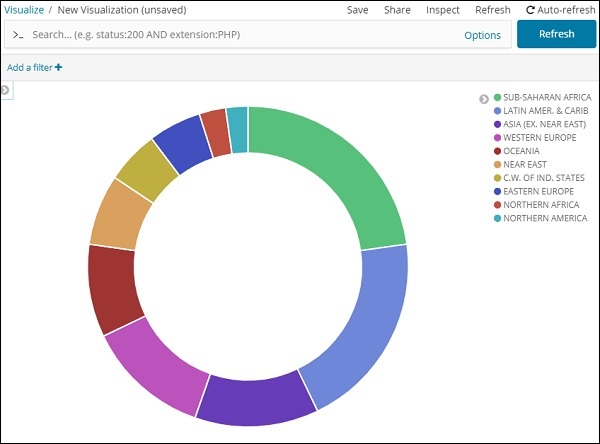
饼图显示
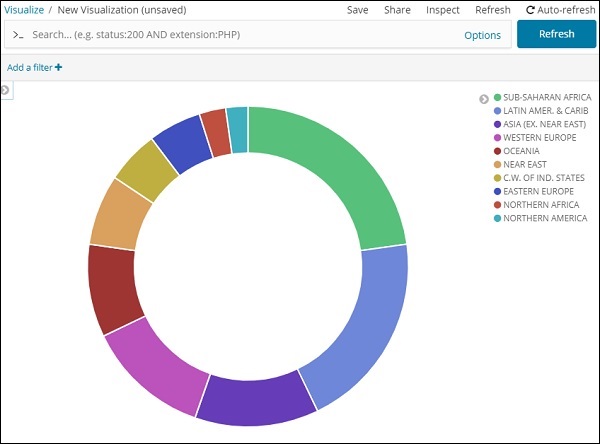
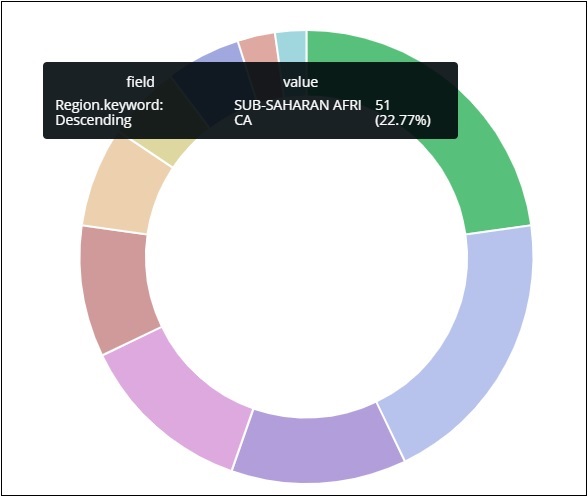
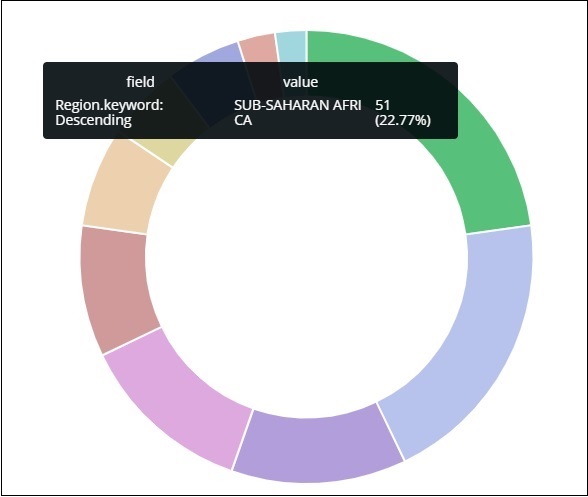
所有区域都用颜色列在右上角,饼图中显示相同的颜色。如果您将鼠标悬停在饼图上,它将给出区域的计数以及区域的名称,如下所示 –
所以它告诉我们,从我们上传的国家数据来看,22.77% 的地区被撒哈拉以南非洲地区占据。
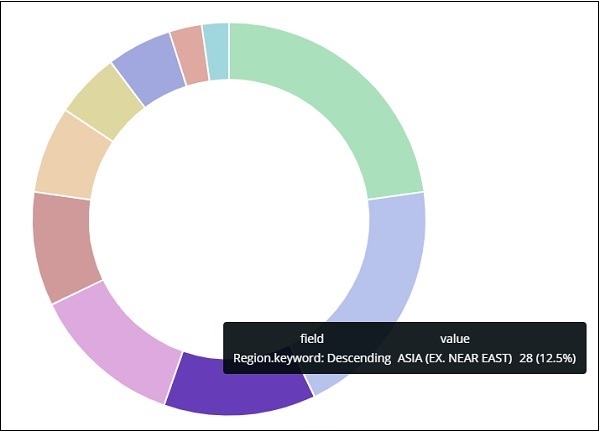
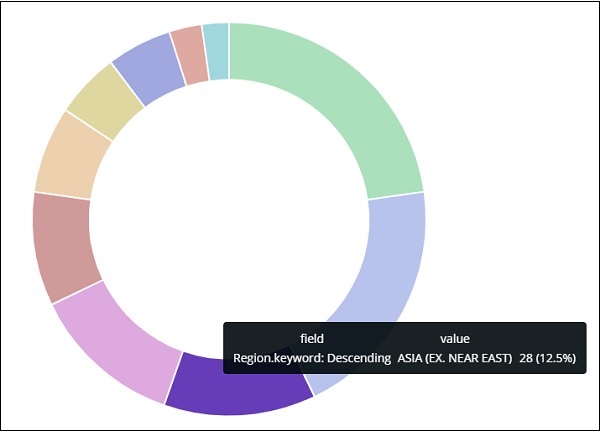
亚洲地区占 12.5%,总数为 28。
现在我们可以通过单击右上角的保存按钮来保存可视化,如下所示 –

现在,保存可视化,以便以后使用。
我们还可以使用如下所示的搜索选项获取我们想要的数据 –
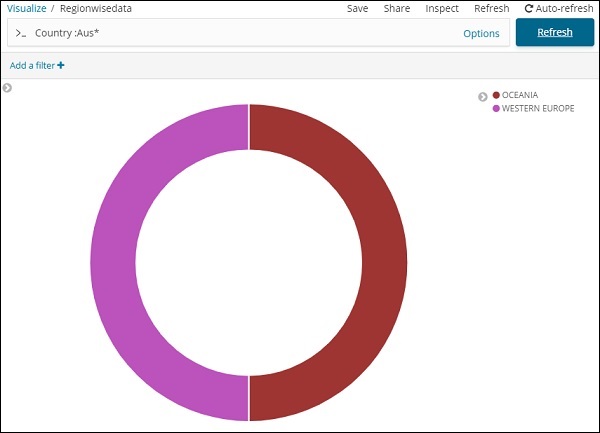
我们已经过滤了以 Aus* 开头的国家/地区的数据。我们将在接下来的章节中更多地了解饼图和其他可视化。
Kibana – 使用图表
让我们探索和了解可视化中最常用的图表。
- 水平条形图
- 垂直条形图
- 饼形图
以下是创建上述可视化要遵循的步骤。让我们从单杠开始。
水平条形图
打开 Kibana 并单击左侧的 Visualize 选项卡,如下所示 –
单击 + 按钮创建新的可视化 –
单击上面列出的水平栏。您必须选择要可视化的索引。
选择如上图所示的countriesdata-28.12.2018索引。在选择索引时,它会显示如下所示的屏幕 –
它显示默认计数。现在,让我们绘制一个水平图,我们可以在其中看到排名前 10 位的国家智能人口的数据。
为此,我们需要在 Y 和 X 轴上选择我们想要的。因此,选择 Bucket 和 Metric Aggregation –
现在,如果您单击 Y 轴,它将显示如下所示的屏幕 –
现在,从此处显示的选项中选择所需的聚合 –
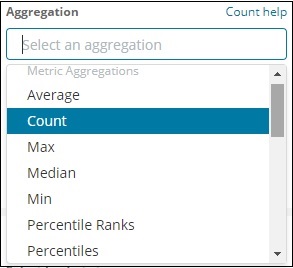
请注意,这里我们将选择 Max 聚合,因为我们希望根据可用的最大人口显示数据。
接下来我们必须选择需要最大值的字段。在索引countriesdata-28.12.2018 中,我们只有 2 个数字字段——面积和人口。
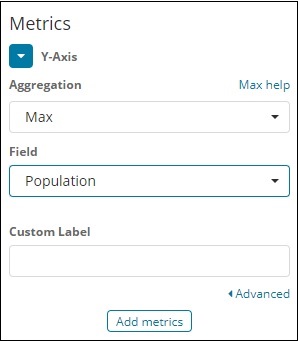
由于我们想要最大人口,我们选择人口字段,如下所示 –
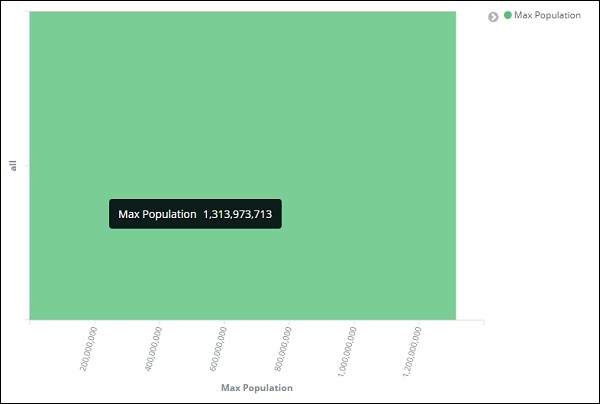
这样,我们就完成了 Y 轴。我们为 Y 轴获得的输出如下所示 –
现在让我们选择 X 轴,如下所示 –
如果您选择 X 轴,您将获得以下输出 –
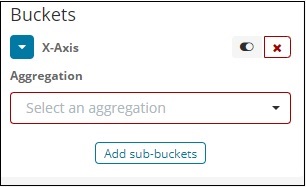
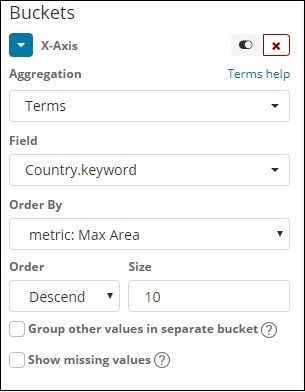
选择聚合作为术语。
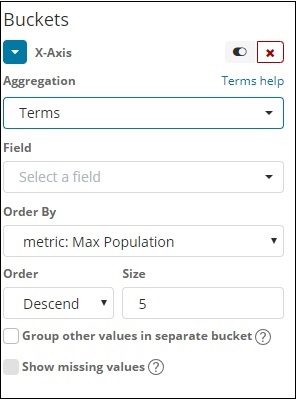
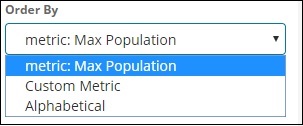
从下拉列表中选择字段。我们想要国家明智的人口,所以选择国家领域。订购我们有以下选项 –
我们将按最大人口选择顺序,因为希望首先显示人口最多的国家,依此类推。添加我们想要的数据后,单击 Metrics 数据顶部的应用更改按钮,如下所示 –
单击应用更改后,我们会看到水平图,其中我们可以看到中国是人口最多的国家,其次是印度、美国等。
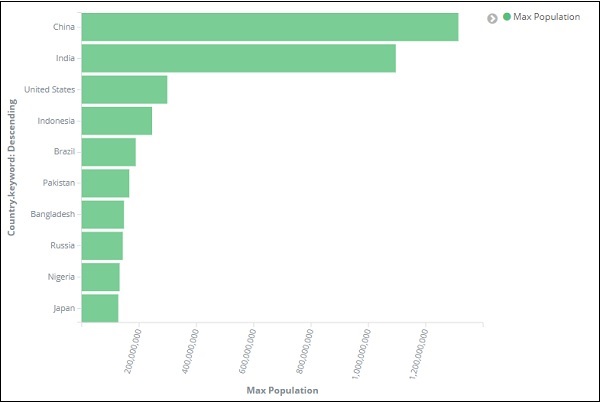
同样,您可以通过选择所需的字段来绘制不同的图形。接下来,我们将此可视化保存为 max_population 以供稍后用于创建仪表板。
在下一节中,我们将创建垂直条形图。
垂直条形图
单击 Visualize 选项卡并使用垂直条和索引创建一个新的可视化,如countriesdata-28.12.2018。
在此垂直条形图可视化中,我们将创建带有国家/地区区域的条形图,即国家/地区将显示为最高区域。
所以让我们选择 Y 轴和 X 轴,如下所示 –
Y轴
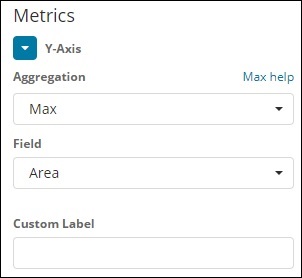
X轴
当我们在此处应用更改时,我们可以看到如下所示的输出 –
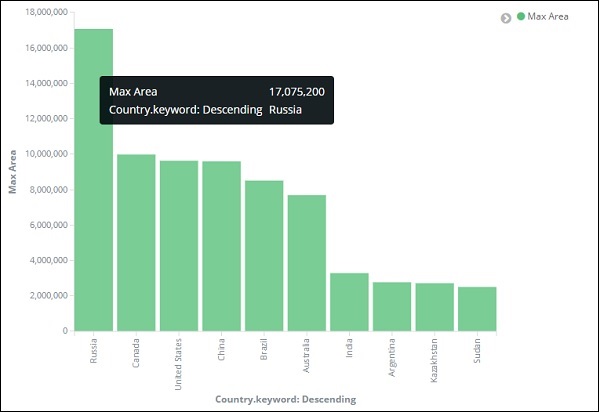
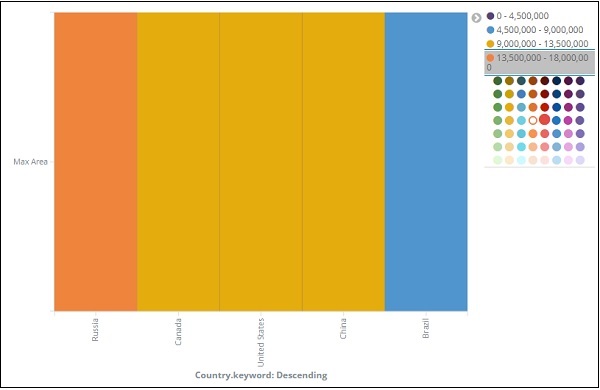
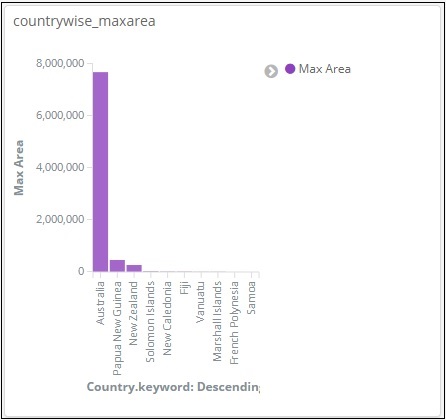
从图中可以看出,俄罗斯的面积最大,其次是加拿大和美国。请注意,此数据是从索引国家数据及其虚拟数据中选取的,因此数字可能与实时数据不正确。
让我们将此可视化保存为countrywise_maxarea以便稍后与仪表板一起使用。
接下来,让我们处理饼图。
饼形图
所以首先创建一个可视化并选择索引为国家数据的饼图。我们将以饼图格式显示国家数据中可用区域的数量。
左侧有指标,将给出计数。在 Buckets 中,有 2 个选项:拆分切片和拆分图表。现在,我们将使用选项拆分切片。
现在,如果您选择拆分切片,它将显示以下选项 –
选择聚合作为术语,它将显示更多要输入的选项,如下所示 –
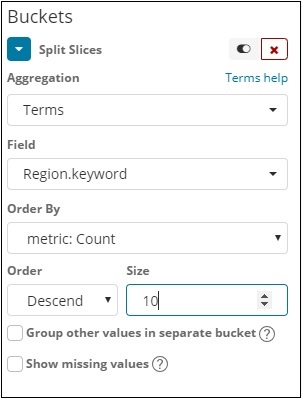
字段下拉列表将包含所选索引中的所有字段。我们选择了我们选择为计数的 Region 字段和 Order By。我们将按降序对其进行排序,大小为 10。因此,我们将从国家/地区索引中获取 10 个地区的数量。
现在,单击下面突出显示的播放按钮,您应该会看到右侧更新的饼图。
饼图显示
所有区域都用颜色列在右上角,饼图中显示相同的颜色。如果您将鼠标悬停在饼图上,它将给出区域的计数以及区域的名称,如下所示 –
因此,它告诉我们在我们上传的国家数据中,22.77% 的地区被撒哈拉以南非洲地区占据。
从饼图中观察到亚洲地区覆盖率为 12.5%,计数为 28。
现在我们可以通过单击右上角的保存按钮来保存可视化,如下所示 –

现在,保存可视化,以便稍后在仪表板中使用。
Kibana – 使用图形
在本章中,我们将讨论可视化中使用的两种类型的图 –
- 线形图
- 区域
线形图
首先,让我们创建一个可视化,选择一个折线图来显示数据并使用contriesdata作为索引。我们需要创建 Y 轴和 X 轴,其详细信息如下所示 –
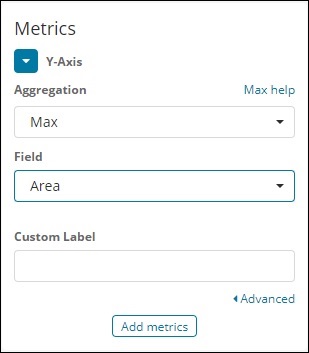
Y轴用
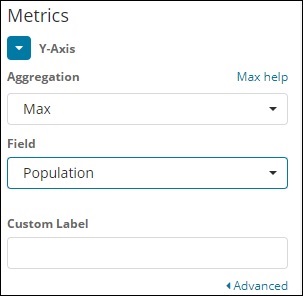
请注意,我们已将 Max 作为聚合。所以这里我们将用折线图来展示数据。现在,我们将绘制图表,以显示国家的最大人口。我们采用的领域是人口,因为我们需要最大的国家明智的人口。
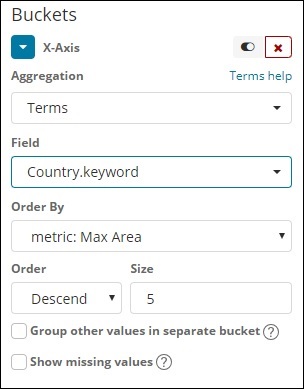
X轴用
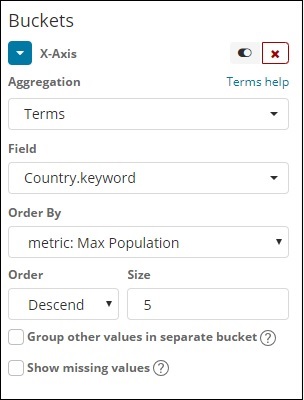
在 x 轴上,我们将条款作为聚合,Country.keyword 作为字段和指标:Order By 的最大人口,订单大小为 5。因此它将绘制人口最多的 5 个国家。应用更改后,您可以看到如下所示的折线图 –
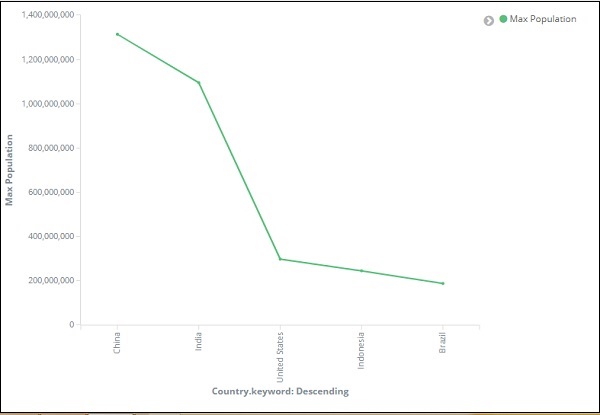
所以我们在中国有最大人口,其次是印度、美国、印度尼西亚和巴西,成为人口最多的 5 个国家。
现在,让我们保存此折线图,以便稍后在仪表板中使用。
单击确认保存,您可以保存可视化。
面积图
转到可视化并选择带有索引的区域作为国家数据。我们需要选择Y轴和X轴。我们将为国家绘制最大面积的面积图。
所以这里的 X 轴和 Y 轴将如下所示 –
单击应用更改按钮后,我们可以看到的输出如下所示 –
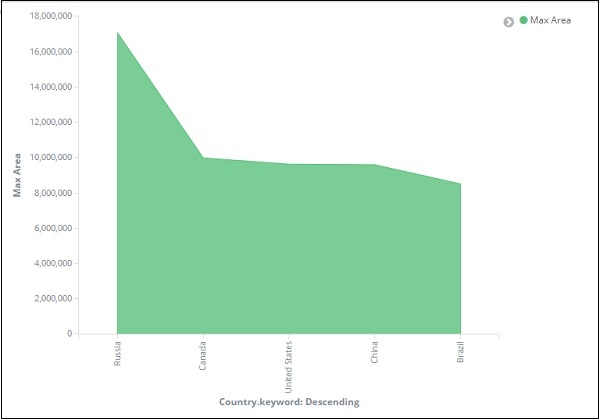
从图中可以看出,俄罗斯的面积最大,其次是加拿大、美国、中国和巴西。保存可视化以供以后使用。
Kibana – 使用热图
在本章中,我们将了解如何使用热图。热图将以不同颜色显示数据指标中所选范围的数据表示。
热图入门
首先,我们需要通过单击左侧的可视化选项卡来创建可视化,如下所示 –
选择可视化类型作为热图,如上所示。它会要求您选择索引,如下所示 –
如上图选择索引countriesdata-28.12.2018。一旦选择了索引,我们就有了要选择的数据,如下所示 –
选择指标如下所示 –
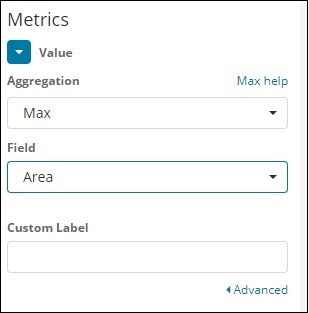
从下拉列表中选择最大聚合,如下所示 –
我们选择了 Max,因为我们想根据国家/地区绘制 Max Area。
现在将选择桶的值,如下所示 –
现在,让我们选择 X 轴,如下所示 –
我们使用聚合作为术语,字段作为国家和按最大区域排序。单击“应用更改”,如下所示 –
如果单击应用更改,热图如下所示 –
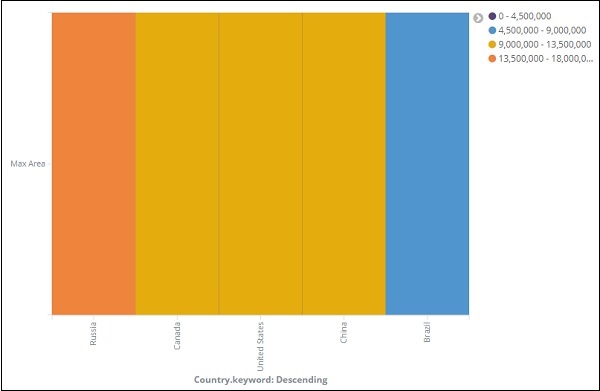
热图以不同颜色显示,区域范围显示在右侧。您可以通过单击区域范围旁边的小圆圈来更改颜色,如下所示 –
Kibana – 使用坐标图
Kibana 中的坐标地图将向您显示地理区域并根据您指定的聚合用圆圈标记该区域。
为坐标图创建索引
用于坐标图的 Bucket 聚合是 geohash 聚合。对于这种类型的聚合,您要使用的索引应该有一个 geo point 类型的字段。地理点是纬度和经度的组合。
我们将使用 Kibana 开发工具创建索引并向其添加批量数据。我们将添加映射并添加我们需要的 geo_point 类型。
我们将要使用的数据显示在此处 –
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.39327140161001", "city": "Esplugas de Llobregat"}
现在,在 Kibana Dev Tools 中运行以下命令,如下所示 –
PUT /cities
{
"mappings": {
"_doc": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
}
POST /cities/_city/_bulk?refresh
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.3s9327140161001", "city": "Esplugas de Llobregat"}
现在,在 Kibana 开发工具中运行上述命令 –
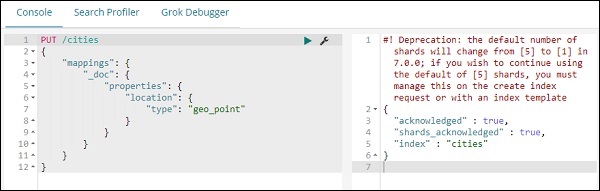
以上将创建 _doc 类型的索引名称城市,字段 location 是 geo_point 类型。
现在让我们向索引添加数据:城市 –
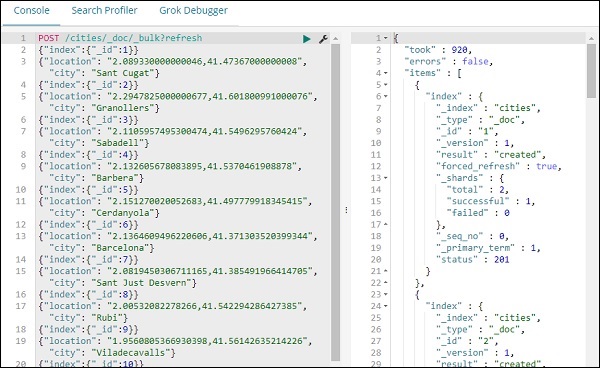
我们已经完成了使用数据创建索引名称引用的工作。现在让我们使用管理选项卡为城市创建索引模式。
此处显示了城市索引中字段的详细信息 –
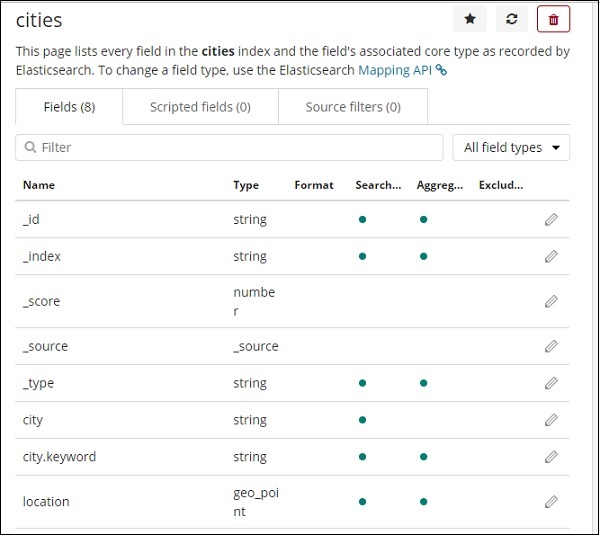
我们可以看到 location 是 geo_point 类型。我们现在可以使用它来创建可视化。
坐标地图入门
转到可视化并选择坐标图。
选择索引模式城市并配置聚合指标和存储桶,如下所示 –
如果单击“分析”按钮,您可以看到以下屏幕 –
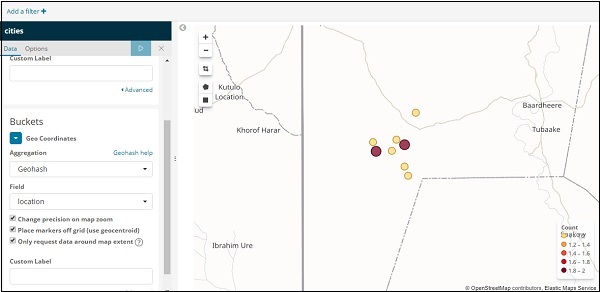
根据经度和纬度,圆圈绘制在地图上,如上图所示。
Kibana – 使用区域地图
通过此可视化,您可以看到地理世界地图上表示的数据。在本章中,让我们详细了解这一点。
为区域地图创建索引
我们将创建一个新索引来处理区域地图可视化。我们要上传的数据显示在这里 –
{"index":{"_id":1}}
{"country": "China", "population": "1313973713"}
{"index":{"_id":2}}
{"country": "India", "population": "1095351995"}
{"index":{"_id":3}}
{"country": "United States", "population": "298444215"}
{"index":{"_id":4}}
{"country": "Indonesia", "population": "245452739"}
{"index":{"_id":5}}
{"country": "Brazil", "population": "188078227"}
{"index":{"_id":6}}
{"country": "Pakistan", "population": "165803560"}
{"index":{"_id":7}}
{"country": "Bangladesh", "population": "147365352"}
{"index":{"_id":8}}
{"country": "Russia", "population": "142893540"}
{"index":{"_id":9}}
{"country": "Nigeria", "population": "131859731"}
{"index":{"_id":10}}
{"country": "Japan", "population": "127463611"}
请注意,我们将在开发工具中使用 _bulk upload 来上传数据。
现在,转到 Kibana Dev Tools 并执行以下查询 –
PUT /allcountries
{
"mappings": {
"_doc": {
"properties": {
"country": {"type": "keyword"},
"population": {"type": "integer"}
}
}
}
}
POST /allcountries/_doc/_bulk?refresh
{"index":{"_id":1}}
{"country": "China", "population": "1313973713"}
{"index":{"_id":2}}
{"country": "India", "population": "1095351995"}
{"index":{"_id":3}}
{"country": "United States", "population": "298444215"}
{"index":{"_id":4}}
{"country": "Indonesia", "population": "245452739"}
{"index":{"_id":5}}
{"country": "Brazil", "population": "188078227"}
{"index":{"_id":6}}
{"country": "Pakistan", "population": "165803560"}
{"index":{"_id":7}}
{"country": "Bangladesh", "population": "147365352"}
{"index":{"_id":8}}
{"country": "Russia", "population": "142893540"}
{"index":{"_id":9}}
{"country": "Nigeria", "population": "131859731"}
{"index":{"_id":10}}
{"country": "Japan", "population": "127463611"}
接下来,让我们创建索引所有国家。我们已将国家/地区字段类型指定为关键字–
PUT /allcountries
{
"mappings": {
"_doc": {
"properties": {
"country": {"type": "keyword"},
"population": {"type": "integer"}
}
}
}
}
注意– 要使用区域地图,我们需要指定要与聚合一起使用的字段类型作为关键字。
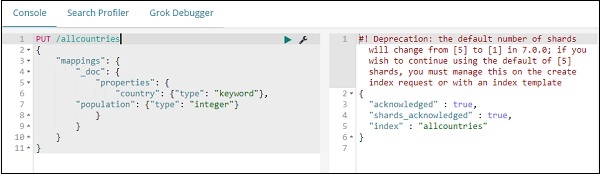
完成后,使用 _bulk 命令上传数据。
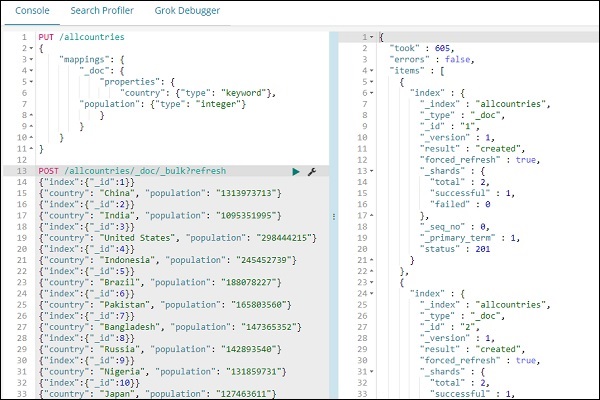
我们现在将创建索引模式。转到 Kibana Management 选项卡并选择创建索引模式。
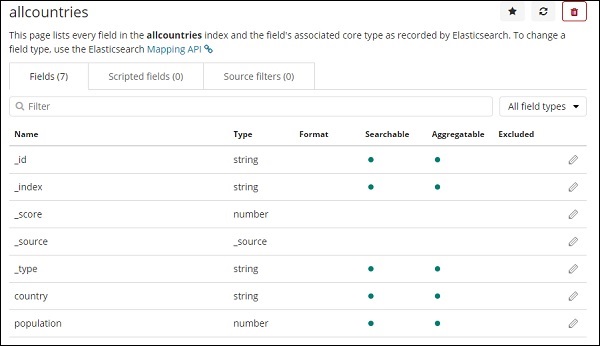
以下是所有国家/地区索引中显示的字段。
区域地图入门
我们现在将使用区域地图创建可视化。转到可视化并选择区域地图。
完成后选择索引作为所有国家并继续。
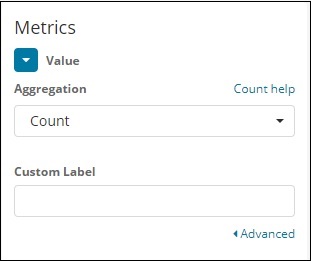
选择聚合指标和桶指标,如下所示 –
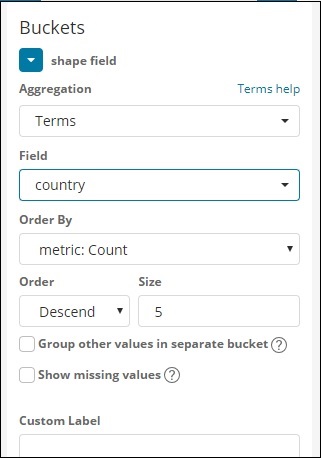
在这里,我们选择了字段作为国家/地区,因为我想在世界地图上显示相同的内容。
区域地图的矢量地图和连接字段
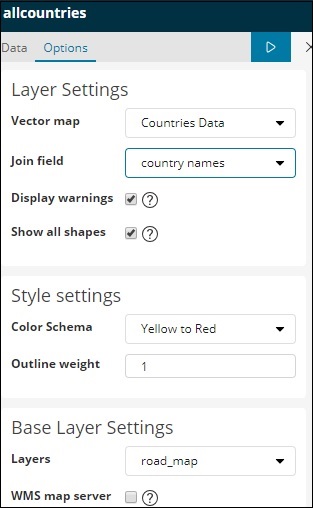
对于区域地图,我们还需要选择选项选项卡,如下所示 –
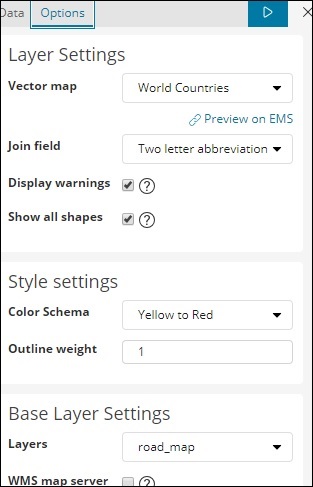
选项选项卡具有在世界地图上绘制数据所需的图层设置配置。
矢量地图具有以下选项 –
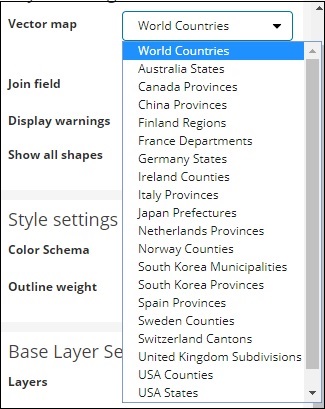
在这里我们将选择世界国家,因为我有国家数据。
加入字段具有以下详细信息 –
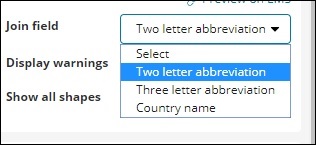
在我们的索引中,我们有国家/地区名称,因此我们将选择国家/地区名称。
在样式设置中,您可以选择要为国家/地区显示的颜色 –
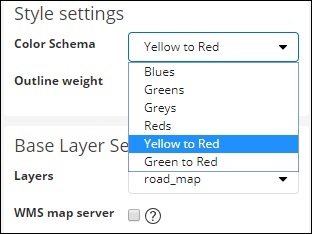
我们将选择红人。我们不会触及其余的细节。
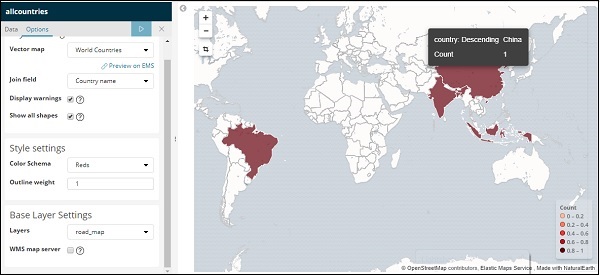
现在,单击“分析”按钮以查看绘制在世界地图上的国家的详细信息,如下所示 –
Kibana 中的自托管矢量地图和连接字段
您还可以为矢量地图和连接字段添加您自己的 Kibana 设置。为此,请从 kibana 配置文件夹转到 kibana.yml 并添加以下详细信息 –
regionmap:
includeElasticMapsService: false
layers:
- name: "Countries Data"
url: "http://localhost/kibana/worldcountries.geojson"
attribution: "INRAP"
fields:
- name: "Country"
description: "country names"
选项选项卡中的矢量地图将填充上述数据而不是默认数据。请注意,给定的 URL 必须启用 CORS,以便 Kibana 可以下载相同的内容。使用的 json 文件应该是坐标连续的方式。例如 –
https://vector.maps.elastic.co/blob/5659313586569216?elastic_tile_service_tos=agree
区域地图矢量地图详细信息自托管时的选项选项卡如下所示 –
Kibana – 使用 Guage 和 Goal
仪表可视化告诉您对数据考虑的指标如何落入预定义的范围内。
目标可视化说明您的目标以及您的数据指标如何朝着目标前进。
使用仪表
要开始使用 Gauge,请转到可视化并从 Kibana UI 中选择可视化选项卡。
单击仪表并选择要使用的索引。
我们将处理medicalvisits-26.01.2019索引。
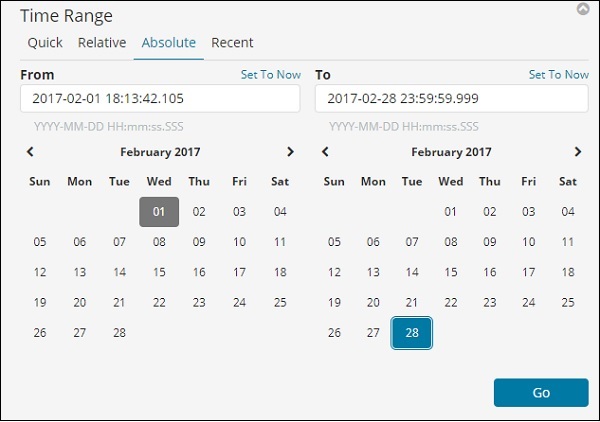
选择2017年2月的时间范围
现在您可以选择指标和存储桶聚合。
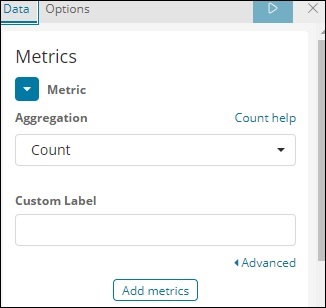
我们选择了度量聚合作为计数。
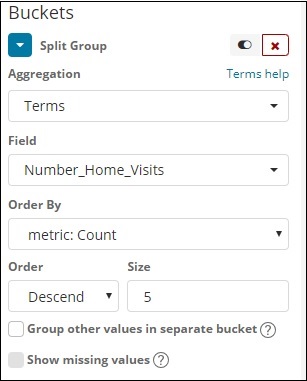
我们选择了条款和字段的存储桶聚合是 Number_Home_Visits。
从数据选项选项卡中,选择的选项如下所示 –
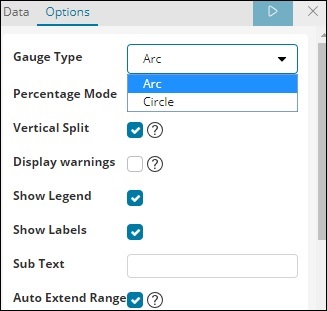
仪表类型可以是圆形或弧形。我们选择了 arc 和 rest 作为默认值。
我们添加的预定义范围显示在此处 –
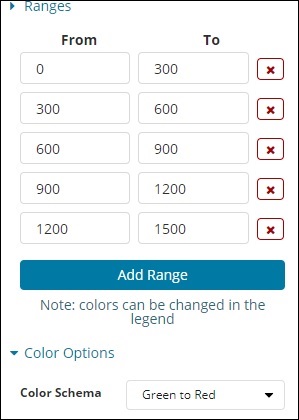
选择的颜色是绿色到红色。
现在,单击分析按钮以查看仪表形式的可视化,如下所示 –
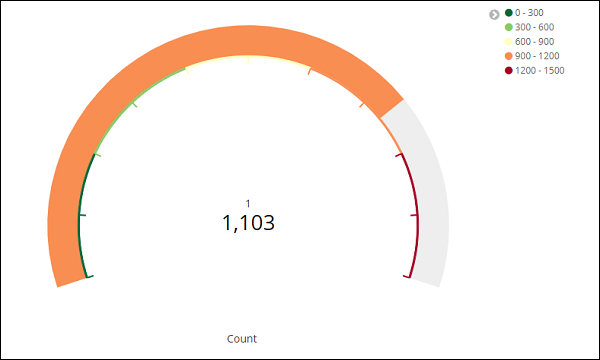
使用目标
转到可视化选项卡并选择目标,如下所示 –
选择目标并选择索引。
使用medicalvisits-26.01.2019作为索引。
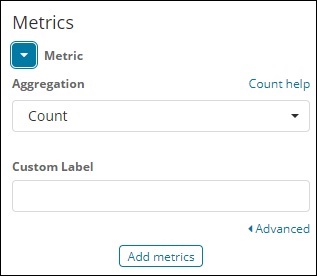
选择指标聚合和桶聚合。
指标聚合
我们选择了 Count 作为度量聚合。
桶聚合
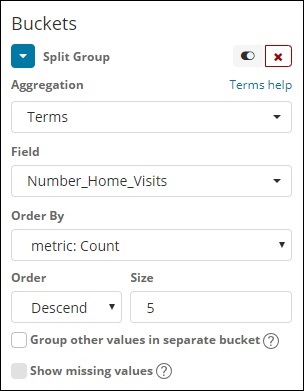
我们选择了条款作为桶聚合,字段是 Number_Home_Visits。
选择的选项如下 –
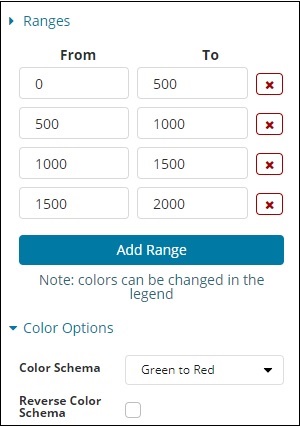
选择的范围如下 –
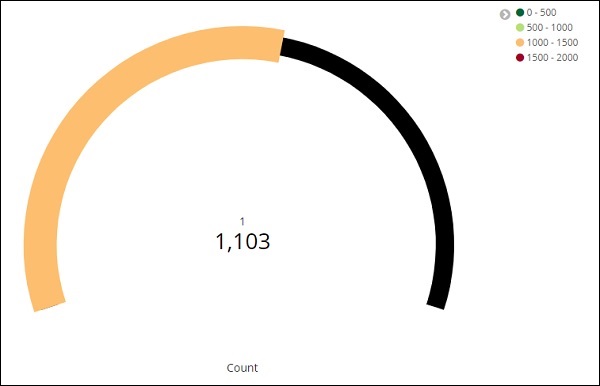
单击分析,您会看到目标显示如下 –
Kibana – 使用 Canvas
Canvas 是 Kibana 的另一个强大功能。使用画布可视化,您可以用不同的颜色组合、形状、文本、多页设置等来表示您的数据。
我们需要数据显示在画布中。现在,让我们加载一些 Kibana 中已有的示例数据。
为 Canvas 创建加载示例数据
要获取示例数据,请转到 Kibana 主页并单击添加示例数据,如下所示 –

单击加载数据集和 Kibana 仪表板。它将带您进入如下所示的屏幕 –
单击示例电子商务订单的添加按钮。加载示例数据需要一些时间。完成后,您将收到一条警告消息,显示“已加载示例电子商务数据”。
开始使用画布可视化
现在转到画布可视化,如下所示 –
单击画布,它将显示如下所示的屏幕 –
我们添加了电子商务和网络流量示例数据。我们可以创建新的工作台或使用现有的工作台。
在这里,我们将选择现有的。选择电子商务收入跟踪工作台名称,它将显示如下所示的屏幕 –
![]()
在 Canvas 中克隆现有工作板
我们将克隆工作板,以便我们可以对其进行更改。要克隆现有的工作台,请单击左下角显示的工作台的名称 –
单击名称并选择克隆选项,如下所示 –
单击克隆按钮,它将创建电子商务收入跟踪工作台的副本。您可以找到它,如下所示 –
在本节中,让我们了解如何使用工作台。如果你看到上面的工作台,它有 2 页。所以在画布中我们可以在多个页面中表示数据。
第 2 页显示如下 –

选择第 1 页并单击左侧显示的总销售额,如下所示 –
在右侧,您将获得与之相关的数据 –
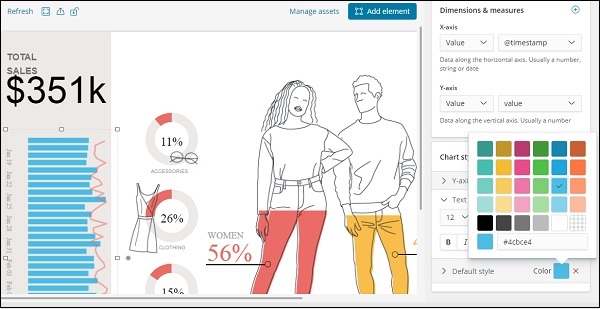
现在使用的默认样式是绿色。我们可以在这里更改颜色并检查相同的显示。
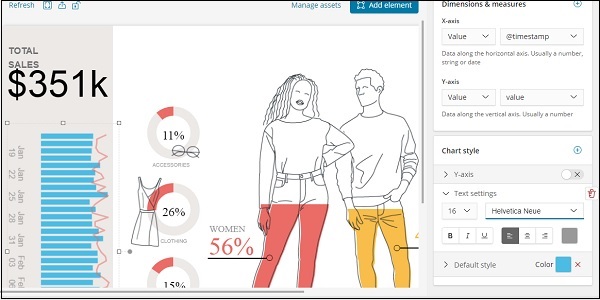
我们还更改了文本设置的字体和大小,如下所示 –
在画布内向工作板添加新页面
要将新页面添加到工作台,请执行如下操作 –
创建页面后,如下所示 –
单击添加元素,它将显示所有可能的可视化,如下所示 –
我们添加了两个元素数据表和面积图,如下所示
您可以向同一页面添加更多数据元素,也可以添加更多页面。
Kibana – 创建仪表板
在我们之前的章节中,我们已经看到了如何以竖条、横条、饼图等形式创建可视化。在本章中,让我们学习如何以 Dashboard 的形式将它们组合在一起。仪表板是您创建的可视化的集合,因此您可以一次查看所有内容。
仪表板入门
要在 Kibana 中创建仪表板,请单击可用的仪表板选项,如下所示 –
现在,单击“创建新仪表板”按钮,如上所示。它将带我们到屏幕,如下所示 –
请注意,到目前为止我们还没有创建任何仪表板。顶部有一些选项,我们可以在其中保存、取消、添加、选项、共享、自动刷新,还可以更改在仪表板上获取数据的时间。我们将通过单击上面显示的添加按钮来创建一个新的仪表板。
向仪表板添加可视化
当我们单击添加按钮(左上角)时,它会向我们显示我们创建的可视化,如下所示 –
选择要添加到仪表板的可视化。我们将选择前三个可视化,如下所示 –
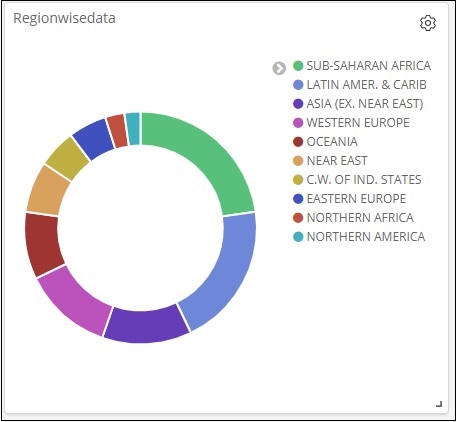
这就是它在屏幕上的显示方式 –
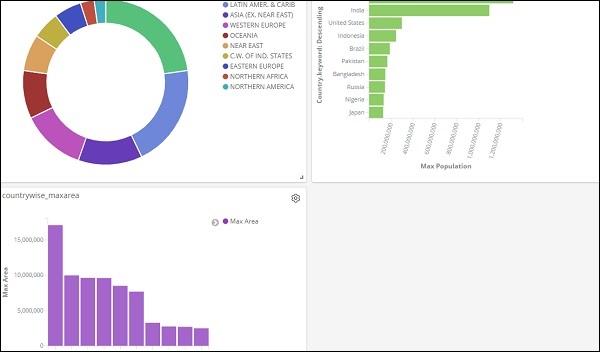
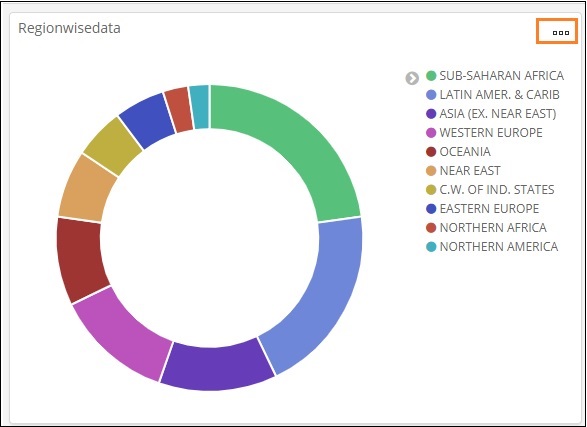
因此,作为用户,您可以获得有关我们上传的数据的整体详细信息 – 国家明智的字段国家名称、地区名称、地区和人口。
所以现在我们知道所有可用的区域,按降序排列的最大人口国家,最大面积等。
这只是我们上传的示例数据可视化,但在现实世界中,跟踪业务的详细信息变得非常容易,例如您有一个网站,每月或每天都有数百万次点击,您想跟踪销售情况每天、每小时、每分钟、几秒钟都完成,如果您的 ELK 堆栈就位,Kibana 可以按照您的意愿每小时、每分钟、几秒钟在您眼前展示您的销售可视化。它显示在现实世界中发生的实时数据。
总的来说,Kibana 在每天、每小时或每分钟提取有关您的业务交易的准确详细信息方面发挥着非常重要的作用,因此公司可以了解进展情况。
保存仪表盘
您可以使用顶部的保存按钮保存仪表板。
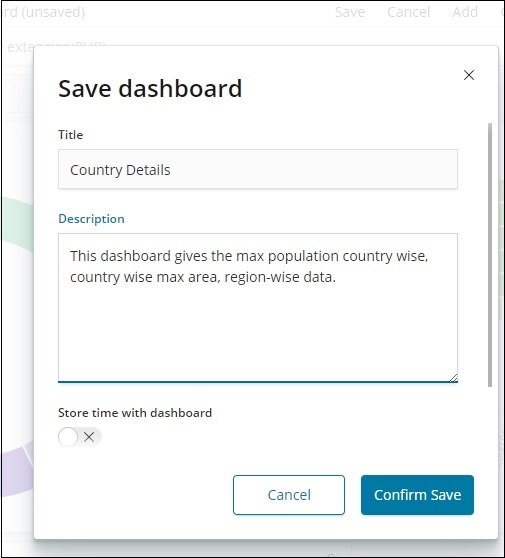
有一个标题和描述,您可以在其中输入仪表板的名称和一个简短的描述,用于说明仪表板的作用。现在,单击确认保存以保存仪表板。
更改仪表板的时间范围
目前您可以看到显示的数据是最近 15 分钟。请注意,这是一个没有任何时间字段的静态数据,因此显示的数据不会改变。当您将数据连接到实时系统更改时间时,也会显示数据反映。
默认情况下,您将看到最后 15 分钟,如下所示 –
单击最后 15 分钟,它将显示您可以根据自己的选择进行选择的时间范围。
请注意,有快速、相对、绝对和最近选项。以下屏幕截图显示了快速选项的详细信息 –
现在,单击“相对”以查看可用选项 –
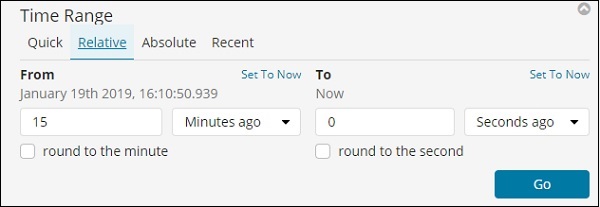
您可以在此处以分钟、小时、秒、月、年为单位指定 From 和 To 日期。
绝对选项具有以下详细信息 –
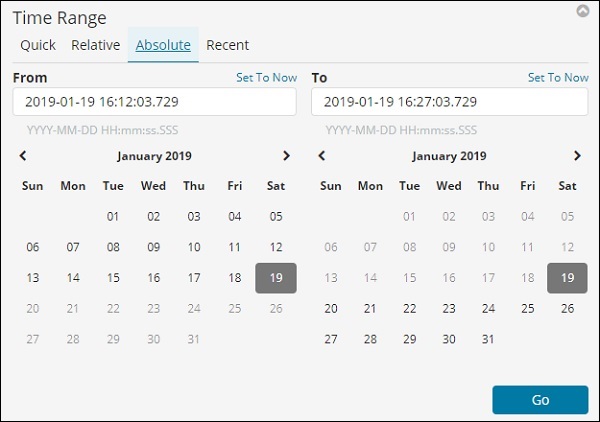
您可以看到日历选项并可以选择日期范围。
最近选项将返回最近 15 分钟选项以及您最近选择的其他选项。选择时间范围将更新该时间范围内的数据。
在仪表板中使用搜索和过滤器
我们还可以在仪表板上使用搜索和过滤器。在搜索中假设如果我们想获取特定区域的详细信息,我们可以添加如下所示的搜索 –

在上面的搜索中,我们使用了 Region 字段,想要显示 region:OCEANIA 的详细信息。
我们得到以下结果 –
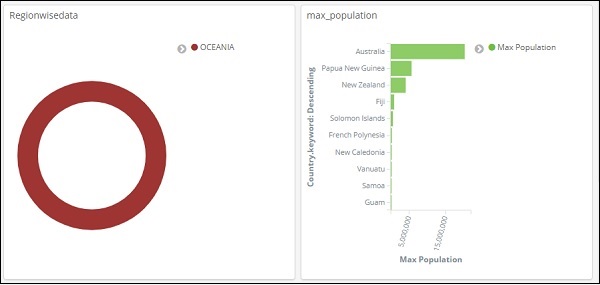
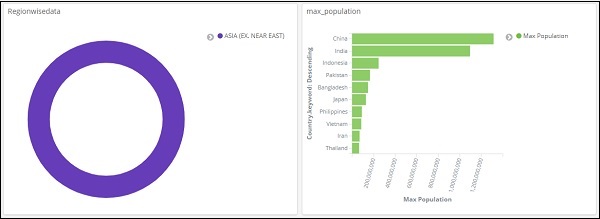
看上面的数据,我们可以说在大洋洲地区,澳大利亚的人口和面积最大。
同样,我们可以添加一个过滤器,如下所示 –
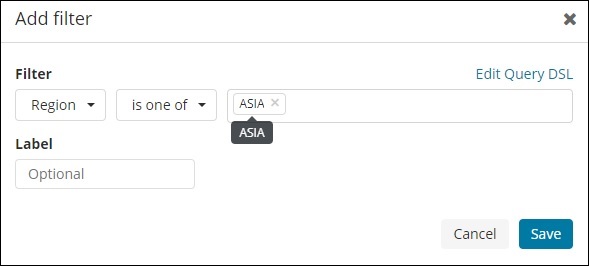
接下来,单击添加过滤器按钮,它将显示索引中可用字段的详细信息,如下所示 –
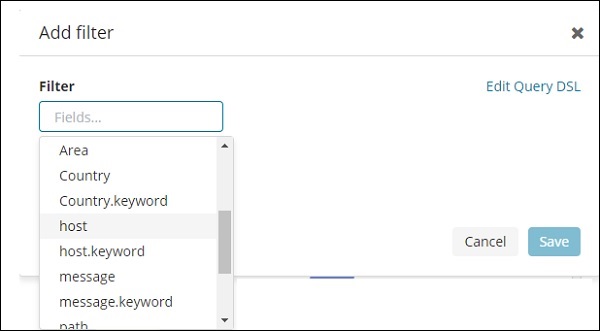
选择要过滤的字段。我将使用 Region 字段来获取 ASIA 区域的详细信息,如下所示 –
保存过滤器,您应该看到过滤器如下 –
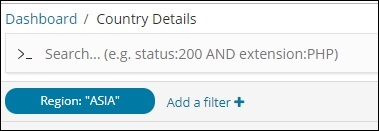
现在将根据添加的过滤器显示数据 –
您还可以添加更多过滤器,如下所示 –
您可以通过单击禁用复选框来禁用过滤器,如下所示。

您可以通过单击相同的复选框来激活过滤器。观察到有删除按钮来删除过滤器。编辑按钮可编辑过滤器或更改过滤器选项。
对于显示的可视化,您会注意到三个点,如下所示 –
单击它,它将显示如下所示的选项 –
检查和全屏
单击“检查”,它以表格格式提供区域的详细信息,如下所示 –
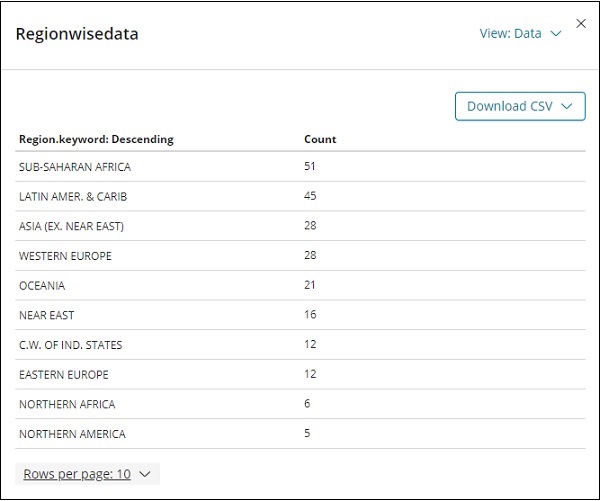
有一个选项可以下载 CSV 格式的可视化,以防您想在 Excel 工作表中看到它。
下一个选项全屏将以全屏模式获得可视化,如下所示 –
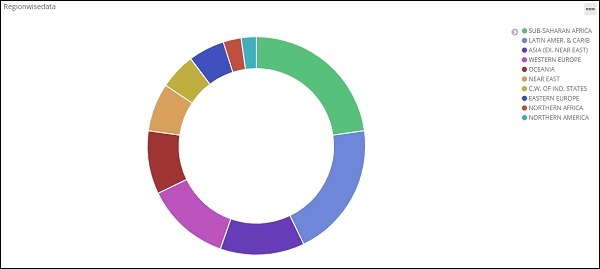
您可以使用相同的按钮退出全屏模式。
共享仪表板
我们可以使用共享按钮共享仪表板。单击共享按钮,您将获得如下显示 –
您还可以使用嵌入代码在您的网站上显示仪表板,或使用永久链接作为与他人共享的链接。
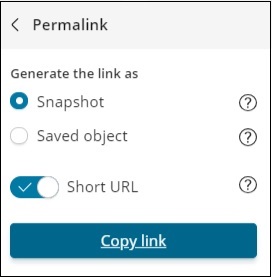
网址如下 –
http://localhost:5601/goto/519c1a088d5d0f8703937d754923b84b
Kibana – Timelion
Timelion,也称为时间线,是另一种可视化工具,主要用于基于时间的数据分析。为了使用时间轴,我们需要使用简单的表达式语言,这将帮助我们连接到索引并对数据执行计算以获得我们需要的结果。
我们可以在哪里使用 Timelion?
当您想要比较时间相关数据时,可以使用 Timelion。例如,您有一个网站,并且每天都会收到您的浏览量。您想分析数据,其中您想将当前周数据与前一周(即周一至周一、周二至周二等)进行比较,以了解视图的差异以及流量。
Timelion 入门
要开始使用 Timelion,请单击 Timelion,如下所示 –

Timelion 默认显示所有索引的时间线,如下所示 –
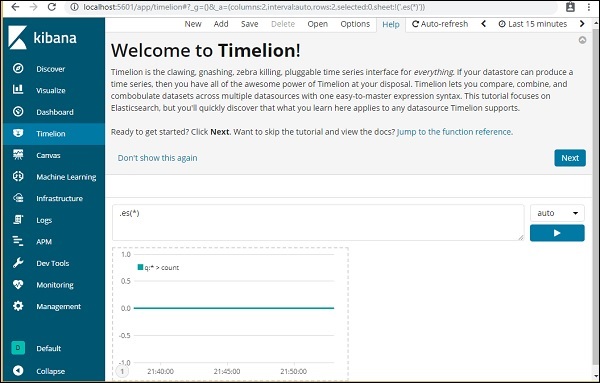
Timelion 使用表达式语法。
注意– es(*) => 表示所有索引。
要获取可与 Timelion 一起使用的功能的详细信息,只需单击文本区域,如下所示 –

它为您提供了与表达式语法一起使用的函数列表。
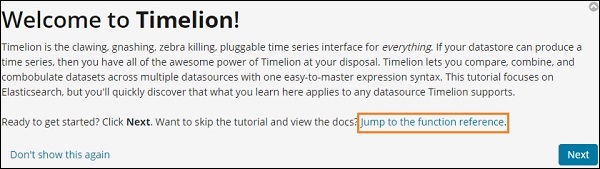
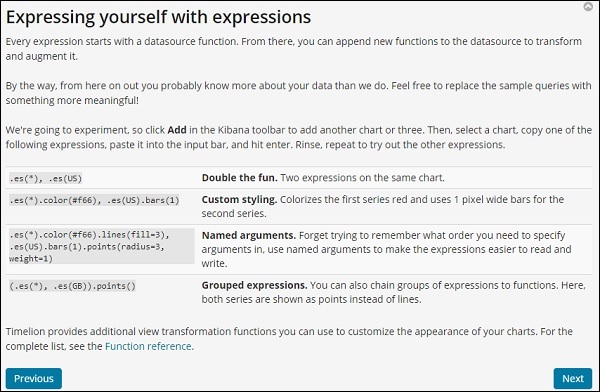
一旦您开始使用 Timelion,它会显示一条欢迎消息,如下所示。突出显示的部分,即跳转到函数参考,提供了可与 timelion 一起使用的所有函数的详细信息。
时狮欢迎词
Timelion 欢迎信息如下所示 –
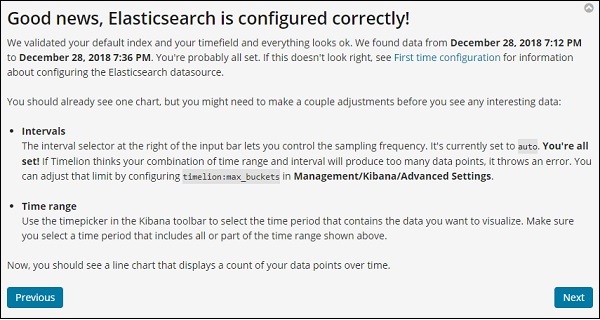
单击下一步按钮,它将引导您了解其基本功能和用法。现在,当您单击下一步时,您可以看到以下详细信息 –
![]()
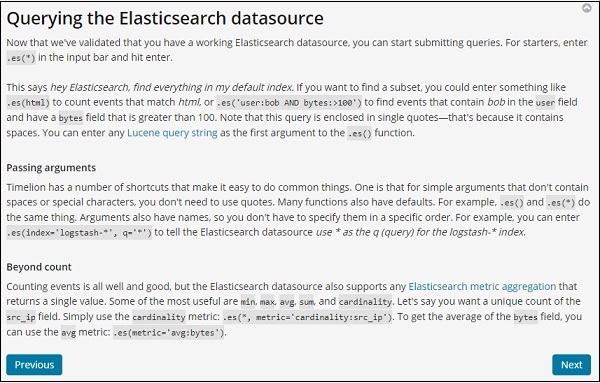
Timelion 函数参考
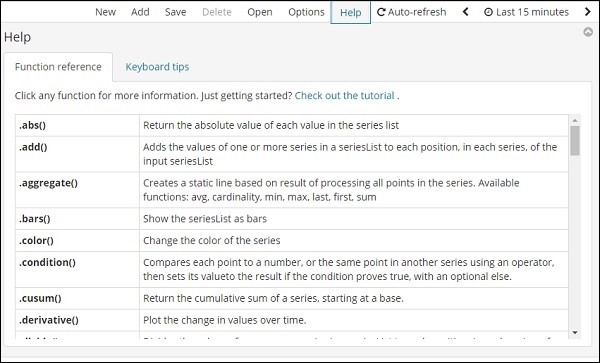
单击“帮助”按钮以获取可用于 Timelion 的函数参考的详细信息 –
Timelion 配置
timelion 的设置在 Kibana 管理 → 高级设置中完成。
单击高级设置并从类别中选择 Timelion
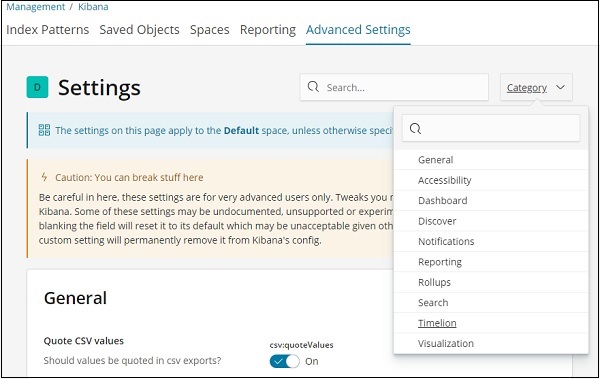
选择 Timelion 后,它将显示 timelion 配置所需的所有必要字段。
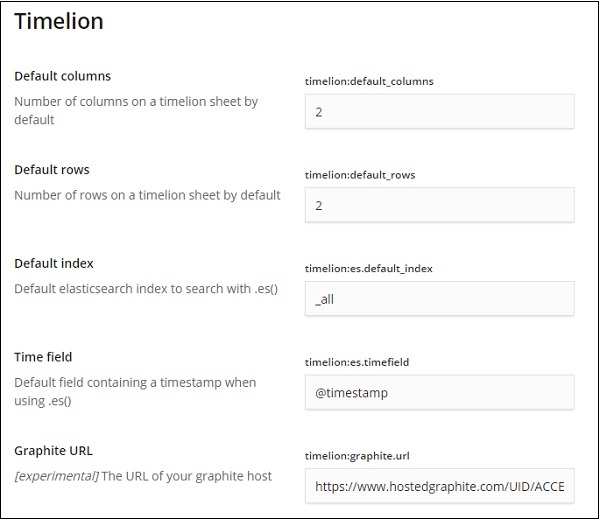
在以下字段中,您可以更改默认索引和要在索引上使用的时间字段 –
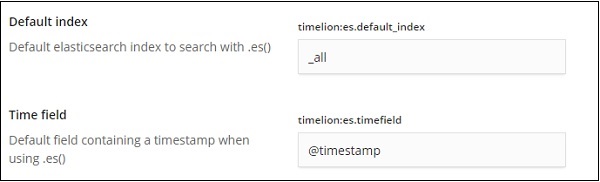
默认值为 _all,时间字段为 @timestamp。我们将保持原样并更改 timelion 本身中的索引和时间字段。
使用 Timelion 可视化数据
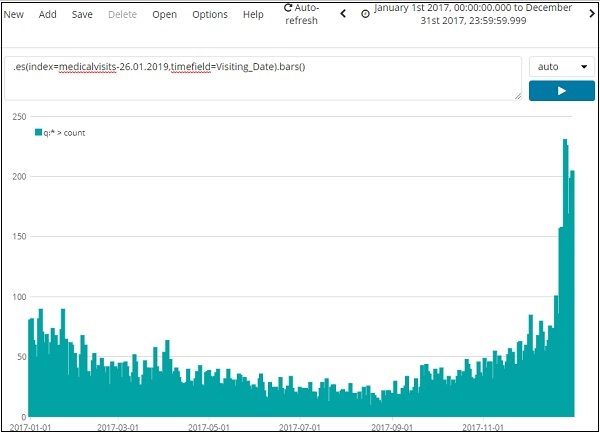
我们将使用索引:medicalvisits-26.01.2019。以下是timelion 2017年1月1日至2017年12月31日显示的数据 –
用于上述可视化的表达式如下 –
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).bars()
我们使用了索引medicalvisits-26.01.2019,该索引的时间字段是 Visiting_Date 并使用了 bar 函数。
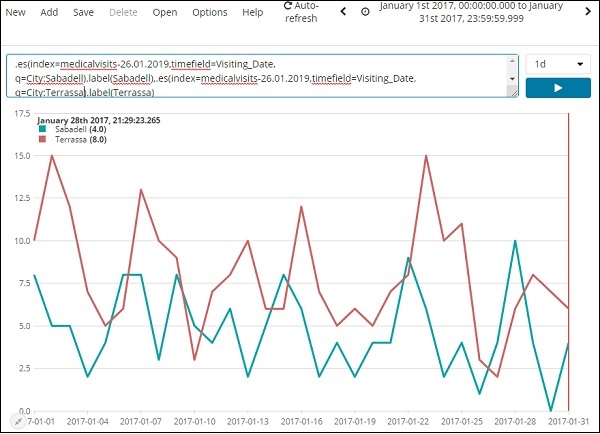
下面我们分析了 2017 年 1 月的 2 个城市,按天计算。
使用的表达式是 –
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date, q=City:Sabadell).label(Sabadell),.es(index=medicalvisits-26.01.2019, timefield=Visiting_Date, q=City:Terrassa).label(Terrassa)
此处显示了 2 天的时间线比较 –
表达
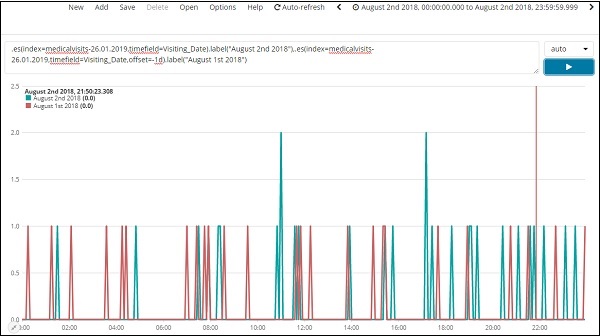
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).label("August 2nd 2018"),
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,offset=-1d).label("August 1st 2018")
这里我们使用了偏移量并给出了 1 天的差异。我们选择当前日期为 2018 年 8 月 2 日。因此它给出了 2018 年 8 月 2 日和 2018 年 8 月 1 日的数据差异。
2017 年 1 月前 5 名城市数据列表如下所示。我们在这里使用的表达式如下 –
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,split=City.keyword:5)
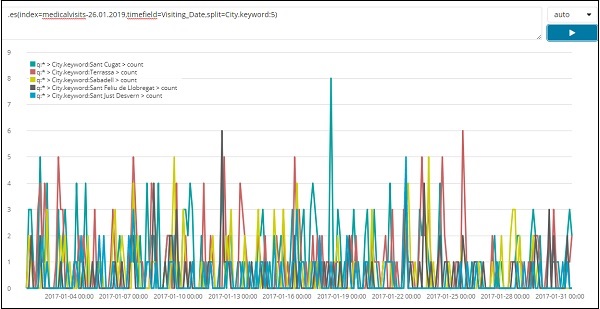
我们使用了 split 并将字段名称指定为 city 并且由于我们需要索引中的前五个城市,因此我们将其指定为split=City.keyword:5
它给出了每个城市的数量并列出了它们的名称,如绘制的图表所示。
Kibana – 开发工具
我们可以在 Elasticsearch 中使用 Dev Tools 上传数据,而无需使用 Logstash。我们可以使用 Dev Tools 在 Kibana 中发布、放置、删除、搜索我们想要的数据。
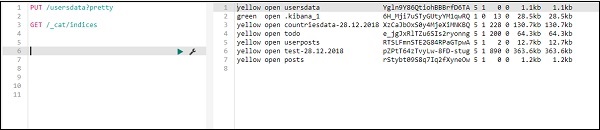
要在 Kibana 中创建新索引,我们可以在开发工具中使用以下命令 –
使用 PUT 创建索引
创建索引的命令如下所示 –
PUT /usersdata?pretty
执行此操作后,将创建一个空索引 userdata。
我们已经完成了索引的创建。现在将在索引中添加数据 –
使用 PUT 将数据添加到索引
您可以按如下方式将数据添加到索引中 –

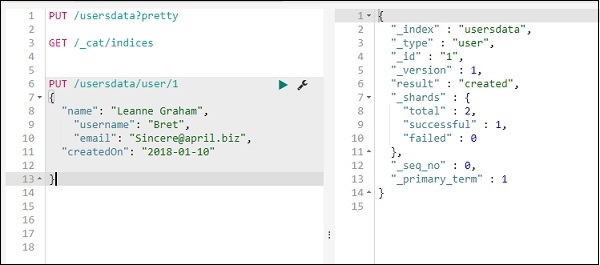
我们将在 usersdata 索引中再添加一条记录 –
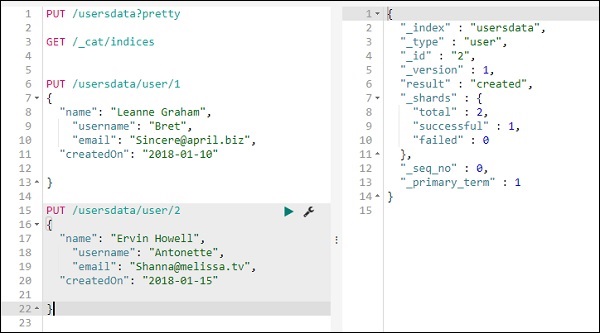
所以我们在 usersdata 索引中有 2 条记录。
使用 GET 从索引中获取数据
我们可以按如下方式获取记录 1 的详细信息 –
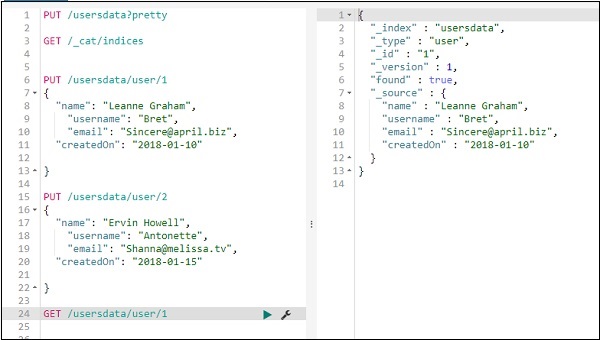
您可以按如下方式获取所有记录 –
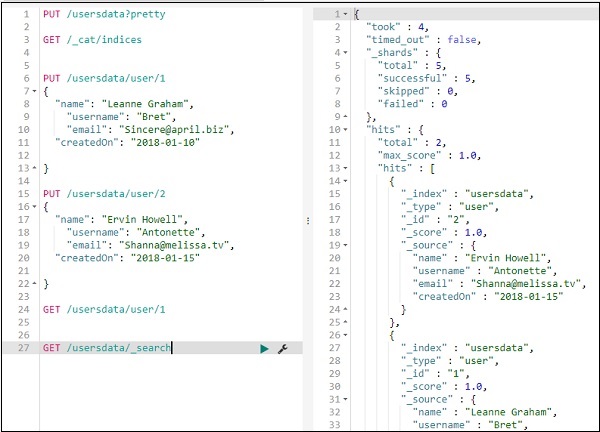
因此,我们可以从 usersdata 中获取所有记录,如上所示。
使用 PUT 更新索引中的数据
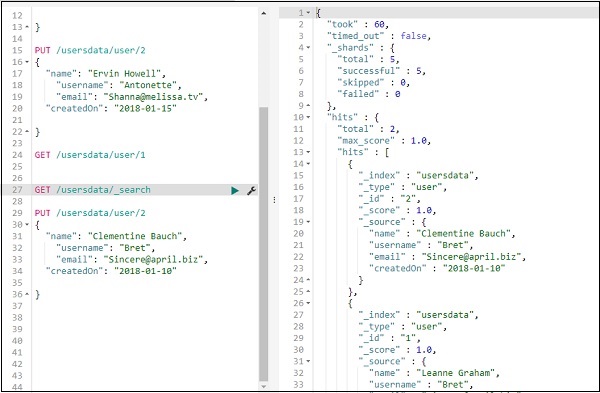
要更新记录,您可以执行以下操作 –
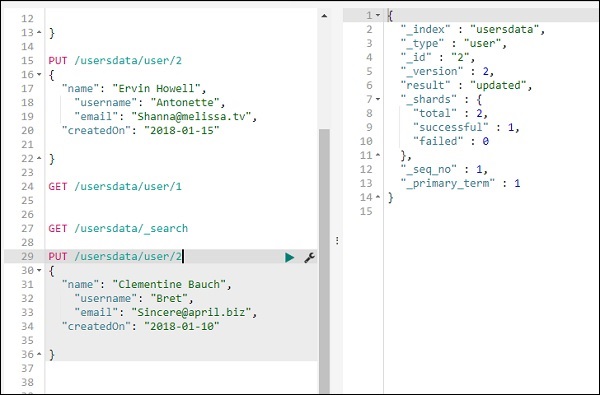
我们已将名称从“Ervin Howell”更改为“Clementine Bauch”。现在我们可以从索引中获取所有记录并查看更新后的记录如下 –
使用 DELETE 从索引中删除数据
您可以删除记录,如下所示 –
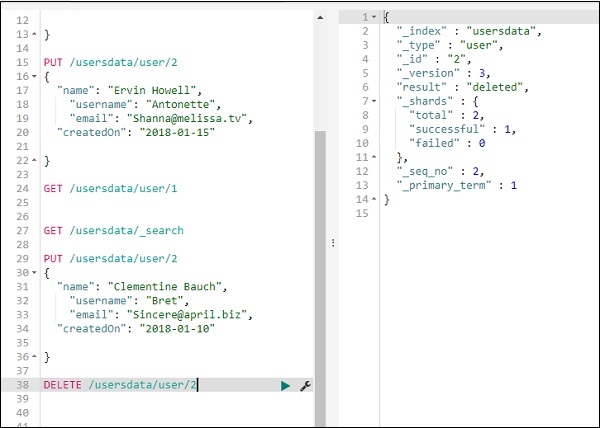
现在,如果您看到总记录,我们将只有一条记录 –
我们可以删除创建的索引如下 –
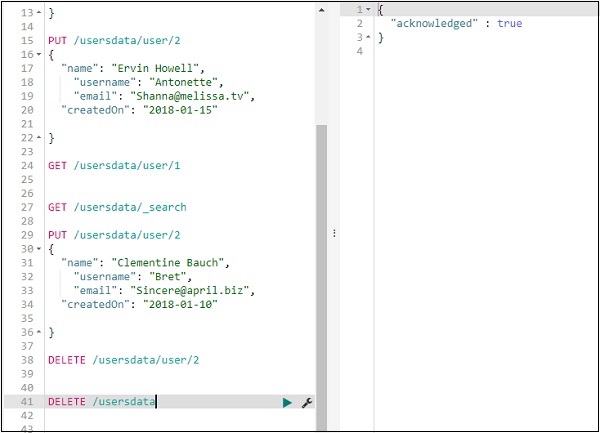
现在,如果您检查可用的索引,我们将不会在删除索引时将 usersdata 索引包含在其中。
Kibana – 监控
Kibana Monitoring 提供了有关 ELK 堆栈性能的详细信息。我们可以获得使用的内存、响应时间等的详细信息。
监控详情
要在 Kibana 中获取监控详细信息,请单击监控选项卡,如下所示 –
由于我们是第一次使用监控,我们需要保持开启。为此,单击按钮打开监控,如上所示。以下是 Elasticsearch 显示的详细信息 –
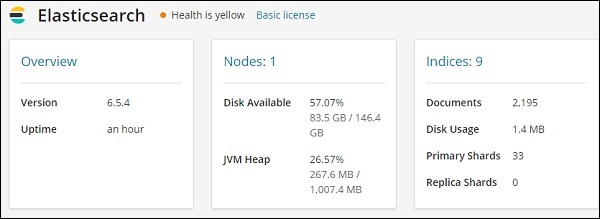
它提供了 elasticsearch 的版本、可用磁盘、添加到 elasticsearch 的索引、磁盘使用情况等。
Kibana 的监控详细信息显示在此处 –
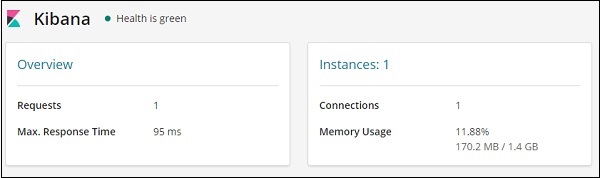
它给出了请求的请求和最大响应时间,以及运行的实例和内存使用情况。
Kibana – 使用 Kibana 创建报告
使用 Kibana UI 中提供的共享按钮可以轻松创建报告。
Kibana 中的报告有以下两种形式 –
- 永久链接
- CSV 报告
报告为永久链接
执行可视化时,您可以共享以下内容 –
使用共享按钮以嵌入代码或永久链接的形式与他人共享可视化。
在嵌入代码的情况下,您将获得以下选项 –
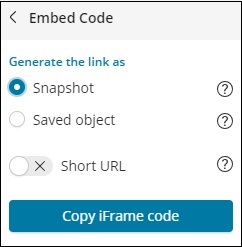
您可以将 iframe 代码生成为快照或已保存对象的短网址或长网址。快照不会提供最近的数据,用户将能够看到共享链接时保存的数据。以后所做的任何更改都不会反映出来。
在保存对象的情况下,您将获得对该可视化所做的最近更改。
长网址的快照 IFrame 代码 –
<iframe src="http://localhost:5601/app/kibana#/visualize/edit/87af cb60-165f-11e9-aaf1-3524d1f04792?embed=true&_g=()&_a=(filters:!(),linked:!f,query:(language:lucene,query:''), uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area),schema:metric,type:max),(enabled:!t,id:'2',p arams:(field:Country.keyword,missingBucket:!f,missingBucketLabel:Missing,order:desc,orderBy:'1',otherBucket:! f,otherBucketLabel:Other,size:10),schema:segment,type:terms)),params:(addLegend:!t,addTimeMarker:!f,addToo ltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,truncate:100),position:bottom,scale:(type:linear), show:!t,style:(),title:(),type:category)),grid:(categoryLines:!f,style:(color:%23eee)),legendPosition:right, seriesParams:!((data:(id:'1',label:'Max+Area'),drawLi nesBetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(), type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1, position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max+Area'),type:value))),title: 'countrywise_maxarea+',type:histogram))" height="600" width="800"></iframe>
短网址的快照 Iframe 代码 –
<iframe src="http://localhost:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4?embed=true" height="600" width="800"><iframe>
作为快照和拍摄网址。
使用短网址 –
http://localhost:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4
关闭短网址后,链接如下所示 –
http://localhost:5601/app/kibana#/visualize/edit/87afcb60-165f-11e9-aaf1-3524d1f04792?_g=()&_a=(filters:!( ),linked:!f,query:(language:lucene,query:''),uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area), schema:metric,type:max),(enabled:!t,id:'2',params:(field:Country.keyword,missingBucket:!f,missingBucketLabel: Missing,order:desc,orderBy:'1',otherBucket:!f,otherBucketLabel:Other,size:10),schema:segment,type:terms)), params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,trun cate:100),position:bottom,scale:(type:linear),show:!t,style:(),title:(),type:category)),grid:(categoryLine s:!f,style:(color:%23eee)),legendPosition:right,seriesParams:!((data:(id:'1',label:'Max%20Area'),drawLines BetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(), type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1, position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max%20Area'),type:value))),title:'countrywise_maxarea%20',type:histogram))
当您在浏览器中点击上述链接时,您将获得与上图相同的可视化效果。上面的链接是本地托管的,所以在本地环境之外使用是不会生效的。
CSV 报告
您可以在有数据的 Kibana 中获取 CSV 报告,这些数据主要位于“发现”选项卡中。
转到“发现”选项卡并获取您想要数据的任何索引。这里我们采用了index:countriesdata-26.12.2018。这是从索引显示的数据 –

您可以从上述数据创建表格数据,如下所示 –
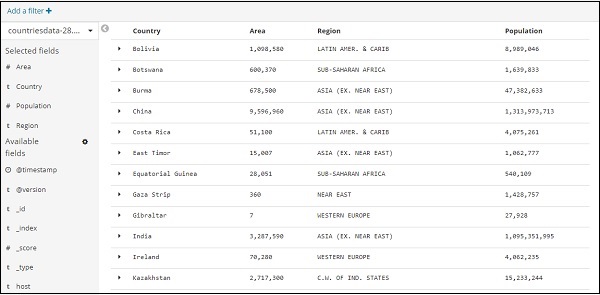
我们从可用字段中选择了字段,之前看到的数据将转换为表格格式。
您可以在 CSV 报告中获取上述数据,如下所示 –
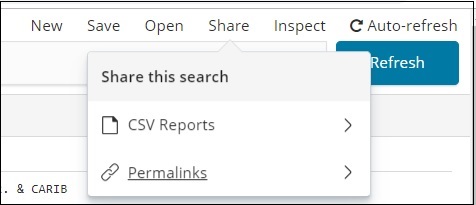
共享按钮具有用于 CSV 报告和永久链接的选项。您可以单击 CSV 报告并下载相同的报告。
请注意获取保存数据所需的 CSV 报告。
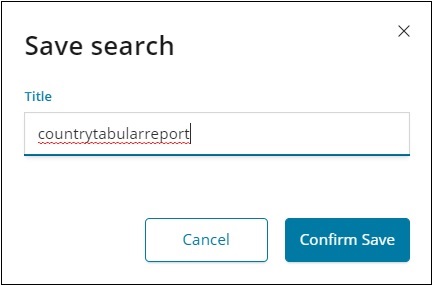
确认保存并单击共享按钮和 CSV 报告。您将获得以下显示 –
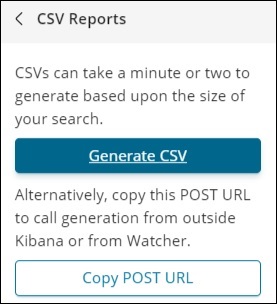
单击生成 CSV 以获取您的报告。完成后,它会指示您转到管理选项卡。
转到管理选项卡 → 报告
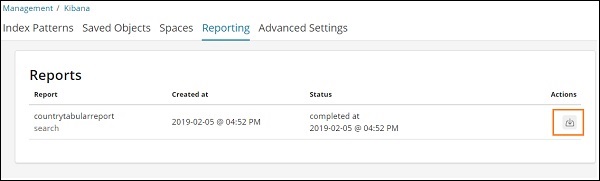
它显示报告名称、创建时间、状态和操作。您可以单击上面突出显示的下载按钮并获取您的 csv 报告。
我们刚刚下载的 CSV 文件如下所示 –