HSQLDB – 快速指南
HSQLDB – 快速指南
HSQLDB – 介绍
HyperSQL 数据库 (HSQLDB) 是一种现代关系数据库管理器,它紧密符合 SQL:2011 标准和 JDBC 4 规范。它支持所有核心功能和 RDBMS。HSQLDB 用于开发、测试和部署数据库应用程序。
HSQLDB 的主要和独特功能是标准合规性。它可以在用户的应用程序进程内、应用程序服务器内或作为单独的服务器进程提供数据库访问。
HSQLDB 的特点
-
HSQLDB 使用内存结构对数据库服务器进行快速操作。它根据用户的灵活性使用磁盘持久性,并具有可靠的崩溃恢复。
-
HSQLDB 也适用于商业智能、ETL 和其他处理大型数据集的应用程序。
-
HSQLDB 具有广泛的企业部署选项,例如 XA 事务、连接池数据源和远程身份验证。
-
HSQLDB 是用 Java 编程语言编写的,并在 Java 虚拟机 (JVM) 中运行。它支持用于数据库访问的 JDBC 接口。
HSQLDB 的组成部分
HSQLDB jar 包中有三个不同的组件。
-
HyperSQL RDBMS 引擎 (HSQLDB)
-
HyperSQL JDBC 驱动程序
-
数据库管理器(GUI 数据库访问工具,具有 Swing 和 AWT 版本)
HyperSQL RDBMS 和 JDBC 驱动程序提供核心功能。数据库管理器是通用数据库访问工具,可与任何具有 JDBC 驱动程序的数据库引擎一起使用。
另一个名为 sqltool.jar 的 jar 包含 Sql Tool,它是一个命令行数据库访问工具。这是一个通用命令。Line 数据库访问工具,也可以与其他数据库引擎一起使用。
HSQlDB – 安装
HSQLDB 是一个用纯 Java 实现的关系数据库管理系统。您可以使用 JDBC 轻松地将此数据库嵌入到您的应用程序中。或者您可以单独使用这些操作。
先决条件
遵循 HSQLDB 的必备软件安装。
验证 Java 安装
由于HSQLDB是纯Java实现的关系型数据库管理系统,所以在安装HSQLDB之前必须先安装JDK(Java Development Kit)软件。如果您的系统中已经安装了 JDK,请尝试以下命令来验证 Java 版本。
java –version
如果您的系统中成功安装了 JDK,您将获得以下输出。
java version "1.8.0_91" Java(TM) SE Runtime Environment (build 1.8.0_91-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
如果您的系统中没有安装 JDK,请访问以下链接以安装 JDK。
HSQLDB 安装
以下是安装 HSQLDB 的步骤。
步骤 1 – 下载 HSQLDB 包
从以下链接https://sourceforge.net/projects/hsqldb/files/下载最新版本的 HSQLDB 数据库。单击链接后,您将获得以下屏幕截图。
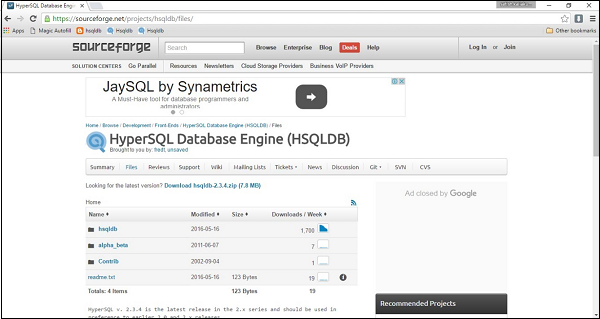
单击 HSQLDB,下载将立即开始。最后,您将获得名为hsqldb-2.3.4.zip的 zip 文件。
步骤 2 – 解压缩 HSQLDB zip 文件
解压缩 zip 文件并将其放入C:\目录。提取后,您将获得如下屏幕截图所示的文件结构。
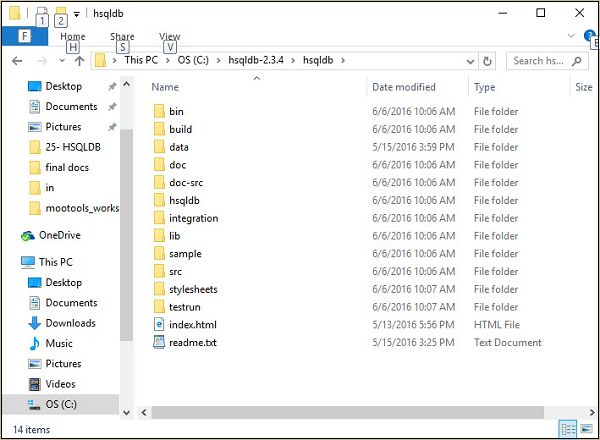
步骤 3 – 创建默认数据库
HSQLDB 没有默认的数据库,因此您需要为 HSQLDB 创建一个数据库。让我们创建一个名为server.properties的属性文件,它定义了一个名为demodb的新数据库。查看以下数据库服务器属性。
server.database.0 = file:hsqldb/demodb server.dbname.0 = testdb
将此 server.properties 文件放入 HSQLDB 主目录C:\hsqldb- 2.3.4\hsqldb\。
现在在命令提示符下执行以下命令。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server
执行上述命令后,您将收到如下图所示的服务器状态。
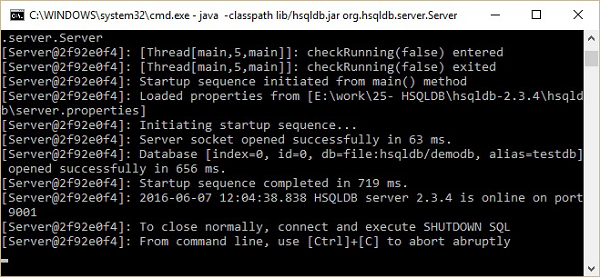
稍后,您将在 HSQLDB 主目录C:\hsqldb-2.3.4\hsqldb 中找到 hsqldb 目录的以下文件夹结构。这些文件是 HSQLDB 数据库服务器创建的 demodb 数据库的临时文件、lck 文件、日志文件、属性文件和脚本文件。
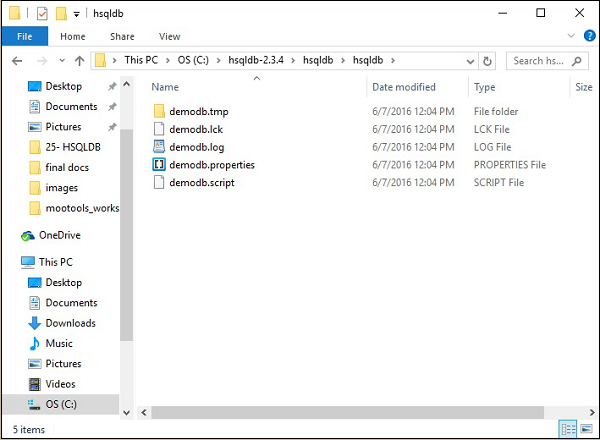
第 4 步 – 启动数据库服务器
完成创建数据库后,您必须使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
执行上述命令后,您将获得以下状态。
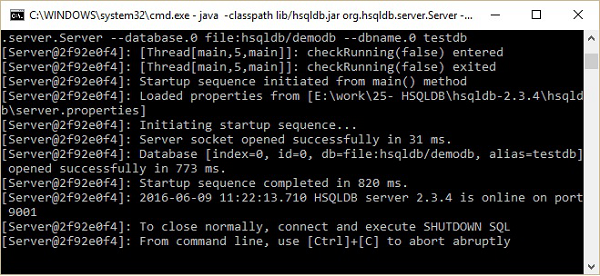
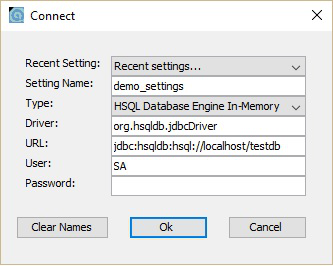
现在,您可以从C:\hsqldb-2.3.4\hsqldb\bin位置打开数据库主屏幕runManagerSwing.bat。这个 bat 文件将打开 HSQLDB 数据库的 GUI 文件。在此之前,它会通过对话框询问您进行数据库设置。看看下面的截图。在此对话框中,输入如上所示的设置名称、URL,然后单击确定。
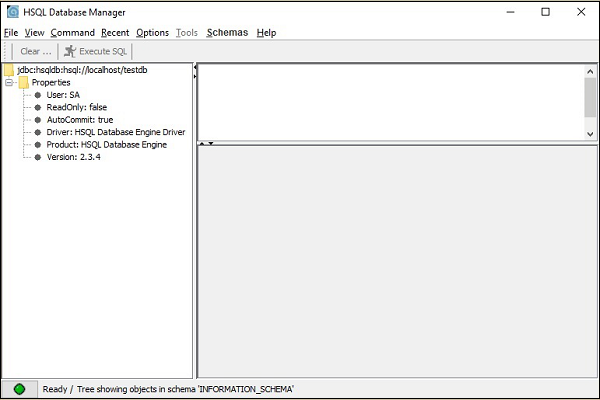
您将获得 HSQLDB 数据库的 GUI 屏幕,如下面的屏幕截图所示。
HSQlDB – 连接
在安装章节中,我们讨论了如何手动连接数据库。在本章中,我们将讨论如何以编程方式(使用 Java 编程)连接数据库。
看看下面的程序,它将启动服务器并在 Java 应用程序和数据库之间创建连接。
例子
import java.sql.Connection;
import java.sql.DriverManager;
public class ConnectDatabase {
public static void main(String[] args) {
Connection con = null;
try {
//Registering the HSQLDB JDBC driver
Class.forName("org.hsqldb.jdbc.JDBCDriver");
//Creating the connection with HSQLDB
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
if (con!= null){
System.out.println("Connection created successfully");
}else{
System.out.println("Problem with creating connection");
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
将此代码保存到ConnectDatabase.java文件中。您必须使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
您可以使用以下命令来编译和执行代码。
\>javac ConnectDatabase.java \>java ConnectDatabase
执行上述命令后,您将收到以下输出 –
Connection created successfully
HSQLDB – 数据类型
本章解释了 HSQLDB 的不同数据类型。HSQLDB 服务器提供六类数据类型。
精确数字数据类型
| Data Type | 从 | 至 |
|---|---|---|
| bigint | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| int | -2,147,483,648 | 2,147,483,647 |
| smallint | -32,768 | 32,767 |
| tinyint | 0 | 255 |
| bit | 0 | 1 |
| decimal | -10^38 +1 | 10^38 -1 |
| numeric | -10^38 +1 | 10^38 -1 |
| money | -922,337,203,685,477.5808 | +922,337,203,685,477.5807 |
| smallmoney | -214,748.3648 | +214,748.3647 |
近似数值数据类型
| Data Type | 从 | 至 |
|---|---|---|
| float | -1.79E + 308 | 1.79E + 308 |
| real | -3.40E + 38 | 3.40E + 38 |
日期和时间数据类型
| Data Type | 从 | 至 |
|---|---|---|
| datetime | 1753 年 1 月 1 日 | 9999 年 12 月 31 日 |
| smalldatetime | 1900 年 1 月 1 日 | 2079 年 6 月 6 日 |
| date | 存储日期,如 1991 年 6 月 30 日 | |
| time | 存储一天中的某个时间,例如下午 12:30 | |
注意– 在这里,日期时间的精度为 3.33 毫秒,而小日期时间的精度为 1 分钟。
字符串数据类型
| Data Type | 描述 |
|---|---|
| char | 最大长度为 8,000 个字符(定长非 Unicode 字符) |
| varchar | 最多 8,000 个字符(可变长度非 Unicode 数据) |
| varchar(max) | 最大长度为 231 个字符,可变长度的非 Unicode 数据(仅限 SQL Server 2005) |
| text | 可变长度非 Unicode 数据,最大长度为 2,147,483,647 个字符 |
Unicode 字符串数据类型
| Data Type | 描述 |
|---|---|
| nchar | 最大长度 4,000 个字符(固定长度 Unicode) |
| nvarchar | 最大长度为 4,000 个字符(可变长度 Unicode) |
| nvarchar(max) | 最大长度为 231 个字符(仅限 SQL Server 2005),(可变长度 Unicode) |
| ntext | 最大长度 1,073,741,823 个字符(可变长度 Unicode) |
二进制数据类型
| Data Type | 描述 |
|---|---|
| binary | 最大长度 8,000 字节(定长二进制数据) |
| varbinary | 最大长度 8,000 字节(可变长度二进制数据) |
| varbinary(max) | 最大长度为 231 字节(仅限 SQL Server 2005),(可变长度二进制数据) |
| image | 最大长度 2,147,483,647 字节(可变长度二进制数据) |
杂项数据类型
| Data Type | 描述 |
|---|---|
| sql_variant | 存储各种 SQL Server 支持的数据类型的值,文本、ntext 和时间戳除外 |
| timestamp | 存储数据库范围的唯一编号,每次更新行时都会更新该编号 |
| uniqueidentifier | 存储全局唯一标识符 (GUID) |
| xml | 存储 XML 数据。您可以将 xml 实例存储在列或变量中(仅限 SQL Server 2005) |
| cursor | 对游标对象的引用 |
| table | 存储结果集供以后处理 |
HSQLDB – 创建表
创建表的基本强制性要求是表名、字段名和这些字段的数据类型。或者,您还可以为表提供键约束。
句法
看看下面的语法。
CREATE TABLE table_name (column_name column_type);
例子
让我们创建一个名为 tutorials_tbl 的表,其中包含字段名称,例如 id、title、author 和 submit_date。看看下面的查询。
CREATE TABLE tutorials_tbl ( id INT NOT NULL, title VARCHAR(50) NOT NULL, author VARCHAR(20) NOT NULL, submission_date DATE, PRIMARY KEY (id) );
执行上述查询后,您将收到以下输出 –
(0) rows effected
HSQLDB – JDBC 程序
以下是用于在 HSQLDB 数据库中创建名为 tutorials_tbl 的表的 JDBC 程序。将程序保存到CreateTable.java文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class CreateTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("CREATE TABLE tutorials_tbl (
id INT NOT NULL, title VARCHAR(50) NOT NULL,
author VARCHAR(20) NOT NULL, submission_date DATE,
PRIMARY KEY (id));
");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table created successfully");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac CreateTable.java \>java CreateTable
执行上述命令后,您将收到以下输出 –
Table created successfully
HSQLDB – 删除表
删除现有的 HSQLDB 表非常容易。但是,删除任何现有表时需要非常小心,因为删除表后将无法恢复丢失的任何数据。
句法
以下是删除 HSQLDB 表的通用 SQL 语法。
DROP TABLE table_name;
例子
让我们考虑一个从 HSQLDB 服务器中删除名为 employee 的表的示例。以下是删除名为employee 的表的查询。
DROP TABLE employee;
执行上述查询后,您将收到以下输出 –
(0) rows effected
HSQLDB – JDBC 程序
以下是用于从 HSQLDB 服务器中删除表员工的 JDBC 程序。
将以下代码保存到DropTable.java文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DropTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("DROP TABLE employee");
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table dropped successfully");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac DropTable.java \>java DropTable
执行上述命令后,您将收到以下输出 –
Table dropped successfully
HSQLDB – 插入查询
您可以使用 INSERT INTO 命令在 HSQLDB 中实现插入查询语句。您必须按照表中的列字段顺序提供用户定义的数据。
句法
以下是插入查询的通用语法。
INSERT INTO table_name (field1, field2,...fieldN) VALUES (value1, value2,...valueN );
要将字符串类型数据插入表中,您必须使用双引号或单引号将字符串值提供到插入查询语句中。
例子
让我们考虑一个示例,该示例将一条记录插入到名为tutorials_tbl的表中,其值为 id = 100、title = Learn PHP、作者 = John Poul,提交日期为当前日期。
以下是给定示例的查询。
INSERT INTO tutorials_tbl VALUES (100,'Learn PHP', 'John Poul', NOW());
执行上述查询后,您将收到以下输出 –
1 row effected
HSQLDB – JDBC 程序
下面是 JDBC 程序,用于将记录插入到具有给定值的表中,id = 100,标题 = Learn PHP,作者 = John Poul,提交日期为当前日期。看看给定的程序。将代码保存到InserQuery.java文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class InsertQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("INSERT INTO tutorials_tbl
VALUES (100,'Learn PHP', 'John Poul', NOW())");
con.commit();
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" rows effected");
System.out.println("Rows inserted successfully");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac InsertQuery.java \>java InsertQuery
执行上述命令后,您将收到以下输出 –
1 rows effected Rows inserted successfully
尝试使用INSERT INTO命令将以下记录插入到tutorials_tbl表中。
| Id | 标题 | 作者 | 提交日期 |
|---|---|---|---|
| 101 | 学习 C | 亚斯旺斯 | 现在() |
| 102 | 学习 MySQL | 阿卜杜勒·S | 现在() |
| 103 | 学习Excel | 巴维亚卡纳 | 现在() |
| 104 | 学习 JDB | 阿吉特·库马尔 | 现在() |
| 105 | 学习 Junit | 萨蒂亚·穆蒂 | 现在() |
HSQLDB – 选择查询
SELECT 命令用于从 HSQLDB 数据库中获取记录数据。在这里,您需要在 Select 语句中提及必填字段列表。
句法
这是 Select 查询的通用语法。
SELECT field1, field2,...fieldN table_name1, table_name2... [WHERE Clause] [OFFSET M ][LIMIT N]
-
您可以在单个 SELECT 命令中获取一个或多个字段。
-
您可以指定星号 (*) 来代替字段。在这种情况下,SELECT 将返回所有字段。
-
您可以使用 WHERE 子句指定任何条件。
-
您可以使用 OFFSET 从 SELECT 开始返回记录的位置指定偏移量。默认情况下,偏移为零。
-
您可以使用 LIMIT 属性限制返回次数。
例子
这是一个从tutorials_tbl表中获取所有记录的 id、title 和 author 字段的示例。我们可以通过使用 SELECT 语句来实现这一点。以下是示例的查询。
SELECT id, title, author FROM tutorials_tbl
执行上述查询后,您将收到以下输出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 100 | Learn PHP | John Poul | | 101 | Learn C | Yaswanth | | 102 | Learn MySQL | Abdul S | | 103 | Learn Excell | Bavya kanna | | 104 | Learn JDB | Ajith kumar | | 105 | Learn Junit | Sathya Murthi | +------+----------------+-----------------+
HSQLDB – JDBC 程序
这是 JDBC 程序,它将从tutorials_tbl表中获取所有记录的 id、title 和 author 字段。将以下代码保存到SelectQuery.java文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class SelectQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl");
while(result.next()){
System.out.println(result.getInt("id")+" | "+
result.getString("title")+" | "+
result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述代码。
\>javac SelectQuery.java \>java SelectQuery
执行上述命令后,您将收到以下输出 –
100 | Learn PHP | John Poul 101 | Learn C | Yaswanth 102 | Learn MySQL | Abdul S 103 | Learn Excell | Bavya Kanna 104 | Learn JDB | Ajith kumar 105 | Learn Junit | Sathya Murthi
HSQLDB – Where 子句
通常,我们使用 SELECT 命令从 HSQLDB 表中获取数据。我们可以使用 WHERE 条件子句来过滤结果数据。使用 WHERE,我们可以指定选择标准以从表中选择所需的记录。
句法
以下是从 HSQLDB 表中获取数据的 SELECT 命令 WHERE 子句的语法。
SELECT field1, field2,...fieldN table_name1, table_name2... [WHERE condition1 [AND [OR]] condition2.....
-
您可以使用一个或多个由逗号分隔的表来包含使用 WHERE 子句的各种条件,但 WHERE 子句是 SELECT 命令的可选部分。
-
您可以使用 WHERE 子句指定任何条件。
-
您可以使用 AND 或 OR 运算符指定多个条件。
-
WHERE 子句也可以与 DELETE 或 UPDATE SQL 命令一起使用来指定条件。
我们可以使用条件过滤记录数据。我们在条件 WHERE 子句中使用不同的运算符。这是运算符列表,可与 WHERE 子句一起使用。
| Operator | 描述 | 例子 |
|---|---|---|
| = | 检查两个操作数的值是否相等,如果相等则条件成立。 | (A = B) 不正确 |
| != | 检查两个操作数的值是否相等,如果值不相等则条件成立。 | (A != B) 是真的 |
| > | 检查左操作数的值是否大于右操作数的值,如果是,则条件成立。 | (A > B) 不正确 |
| < | 检查左操作数的值是否小于右操作数的值,如果是,则条件成立。 | (A < B) 是真的 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立。 | (A >= B) 不是真的 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立。 | (A <= B) 为真 |
例子
这是一个检索详细信息的示例,例如 id、标题和名为“Learn C”的书的作者。可以通过在 SELECT 命令中使用 WHERE 子句来实现。以下是相同的查询。
SELECT id, title, author FROM tutorials_tbl WHERE title = 'Learn C';
执行上述查询后,您将收到以下输出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 101 | Learn C | Yaswanth | +------+----------------+-----------------+
HSQLDB – JDBC 程序
这是从标题为Learn C的表 tutorials_tbl 中检索记录数据的 JDBC 程序。将以下代码保存到WhereClause.java 中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class WhereClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl
WHERE title = 'Learn C'");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述代码。
\>javac WhereClause.java \>java WhereClause
执行上述命令后,您将收到以下输出。
101 | Learn C | Yaswanth
HSQLDB – 更新查询
无论何时要修改表的值,都可以使用 UPDATE 命令。这将修改任何 HSQLDB 表中的任何字段值。
句法
这是 UPDATE 命令的通用语法。
UPDATE table_name SET field1 = new-value1, field2 = new-value2 [WHERE Clause]
- 您可以一并更新一个或多个字段。
- 您可以使用 WHERE 子句指定任何条件。
- 您可以一次更新单个表中的值。
例子
让我们考虑一个示例,该示例将教程的标题从“Learn C”更新为“C 和数据结构”,id 为“101”。以下是更新的查询。
UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101;
执行上述查询后,您将收到以下输出。
(1) Rows effected
HSQLDB – JDBC 程序
这是 JDBC 程序,它将教程标题从Learn C更新为C 和具有 id 101 的数据结构。将以下程序保存到UpdateQuery.java文件中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class UpdateQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac UpdateQuery.java \>java UpdateQuery
执行上述命令后,您将收到以下输出 –
1 Rows effected
HSQLDB – 删除子句
每当您想从任何 HSQLDB 表中删除记录时,都可以使用 DELETE FROM 命令。
句法
以下是用于从 HSQLDB 表中删除数据的 DELETE 命令的通用语法。
DELETE FROM table_name [WHERE Clause]
-
如果未指定 WHERE 子句,则将从给定的 MySQL 表中删除所有记录。
-
您可以使用 WHERE 子句指定任何条件。
-
您可以一次删除单个表中的记录。
例子
让我们考虑一个示例,该示例从id 为105 的名为tutorials_tbl的表中删除记录数据。以下是实现给定示例的查询。
DELETE FROM tutorials_tbl WHERE id = 105;
执行上述查询后,您将收到以下输出 –
(1) rows effected
HSQLDB – JDBC 程序
这是实现给定示例的 JDBC 程序。将以下程序保存到DeleteQuery.java 中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DeleteQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"DELETE FROM tutorials_tbl WHERE id=105");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac DeleteQuery.java \>java DeleteQuery
执行上述命令后,您将收到以下输出 –
1 Rows effected
HSQLDB – LIKE 子句
RDBMS 结构中有一个 WHERE 子句。您可以使用带有等号 (=) 的 WHERE 子句,在我们想要进行精确匹配的地方。但是可能需要过滤掉作者姓名应包含“john”的所有结果。这可以使用 SQL LIKE 子句和 WHERE 子句来处理。
如果 SQL LIKE 子句与 % 字符一起使用,那么它会像 UNIX 中的元字符 (*) 一样工作,同时在命令提示符下列出所有文件或目录。
句法
以下是 LIKE 子句的通用 SQL 语法。
SELECT field1, field2,...fieldN table_name1, table_name2... WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'
-
您可以使用 WHERE 子句指定任何条件。
-
您可以将 LIKE 子句与 WHERE 子句一起使用。
-
您可以使用 LIKE 子句代替等号。
-
当 LIKE 子句与 % 符号一起使用时,它将像元字符搜索一样工作。
-
您可以使用 AND 或 OR 运算符指定多个条件。
-
WHERE…LIKE 子句可与 DELETE 或 UPDATE SQL 命令一起使用以指定条件。
例子
让我们考虑一个示例,该示例检索作者姓名以John开头的教程数据列表。以下是给定示例的 HSQLDB 查询。
SELECT * from tutorials_tbl WHERE author LIKE 'John%';
执行上述查询后,您将收到以下输出。
+-----+----------------+-----------+-----------------+ | id | title | author | submission_date | +-----+----------------+-----------+-----------------+ | 100 | Learn PHP | John Poul | 2016-06-20 | +-----+----------------+-----------+-----------------+
HSQLDB – JDBC 程序
以下是检索作者姓名以John开头的教程数据列表的 JDBC 程序。将代码保存到LikeClause.java 中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class LikeClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT * from tutorials_tbl WHERE author LIKE 'John%';");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author")+" |
"+result.getDate("submission_date"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述代码。
\>javac LikeClause.java \>java LikeClause
执行以下命令后,您将收到以下输出。
100 | Learn PHP | John Poul | 2016-06-20
HSQLDB – 排序结果
只要在检索和显示记录时需要遵循特定顺序,SQL SELECT 命令就会从 HSQLDB 表中获取数据。在这种情况下,我们可以使用ORDER BY子句。
句法
以下是 SELECT 命令的语法以及 ORDER BY 子句,用于对来自 HSQLDB 的数据进行排序。
SELECT field1, field2,...fieldN table_name1, table_name2... ORDER BY field1, [field2...] [ASC [DESC]]
-
您可以对任何字段的返回结果进行排序,前提是该字段被列出。
-
您可以对多个字段的结果进行排序。
-
您可以使用关键字 ASC 或 DESC 以升序或降序获取结果。默认情况下,它按升序排列。
-
您可以以通常的方式使用 WHERE…LIKE 子句来放置条件。
例子
让我们考虑一个示例,该示例通过按升序对作者姓名进行排序来获取并排序tutorials_tbl表的记录。以下是相同的查询。
SELECT id, title, author from tutorials_tbl ORDER BY author ASC;
执行上述查询后,您将收到以下输出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 102 | Learn MySQL | Abdul S | | 104 | Learn JDB | Ajith kumar | | 103 | Learn Excell | Bavya kanna | | 100 | Learn PHP | John Poul | | 105 | Learn Junit | Sathya Murthi | | 101 | Learn C | Yaswanth | +------+----------------+-----------------+
HSQLDB – JDBC 程序
下面是一个 JDBC 程序,它通过按作者姓名的升序对tutorials_tbl表的记录进行提取和排序。将以下程序保存到OrderBy.java 中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class OrderBy {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author from tutorials_tbl
ORDER BY author ASC");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令启动数据库。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令编译并执行上述程序。
\>javac OrderBy.java \>java OrderBy
执行上述命令后,您将收到以下输出。
102 | Learn MySQL | Abdul S 104 | Learn JDB | Ajith kumar 103 | Learn Excell | Bavya Kanna 100 | Learn PHP | John Poul 105 | Learn Junit | Sathya Murthi 101 | C and Data Structures | Yaswanth
HSQLDB – 联接
每当需要使用单个查询从多个表中检索数据时,您都可以使用 RDBMS 中的 JOINS。您可以在单个 SQL 查询中使用多个表。在 HSQLDB 中加入的行为是指将两个或多个表粉碎成一个表。
考虑以下客户和订单表。
Customer: +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+ Orders: +-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们尝试检索客户的数据和相应客户下的订单金额。这意味着我们正在从客户和订单表中检索记录数据。我们可以通过使用 HSQLDB 中的 JOINS 概念来实现这一点。以下是相同的 JOIN 查询。
SELECT ID, NAME, AGE, AMOUNT FROM CUSTOMERS, ORDERS WHERE CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下输出。
+----+----------+-----+--------+ | ID | NAME | AGE | AMOUNT | +----+----------+-----+--------+ | 3 | kaushik | 23 | 3000 | | 3 | kaushik | 23 | 1500 | | 2 | Khilan | 25 | 1560 | | 4 | Chaitali | 25 | 2060 | +----+----------+-----+--------+
联接类型
HSQLDB 中有不同类型的连接可用。
-
INNER JOIN – 当两个表都匹配时返回行。
-
LEFT JOIN – 返回左表中的所有行,即使右表中没有匹配项。
-
RIGHT JOIN – 返回右表中的所有行,即使左表中没有匹配项。
-
FULL JOIN – 当其中一个表匹配时返回行。
-
SELF JOIN – 用于将表连接到自身,就好像该表是两个表,临时重命名 SQL 语句中的至少一个表。
内部联接
最常用和最重要的连接是 INNER JOIN。它也称为 EQUIJOIN。
INNER JOIN 通过基于连接谓词组合两个表(table1 和 table2)的列值来创建一个新的结果表。该查询将 table1 的每一行与 table2 的每一行进行比较,以找到满足连接谓词的所有行对。当满足连接谓词时,每一对匹配的行 A 和 B 的列值组合成一个结果行。
句法
INNER JOIN 的基本语法如下。
SELECT table1.column1, table2.column2... FROM table1 INNER JOIN table2 ON table1.common_field = table2.common_field;
例子
考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 –
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们使用 INNER JOIN 查询连接这两个表,如下所示 –
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS INNER JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下输出。
+----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +----+----------+--------+---------------------+
左加入
HSQLDB LEFT JOIN 返回左表中的所有行,即使右表中没有匹配项。这意味着如果 ON 子句匹配右表中的 0(零)条记录,连接仍将在结果中返回一行,但右表中的每一列都为 NULL。
这意味着左连接返回左表中的所有值,加上右表中匹配的值,或者在没有匹配连接谓词的情况下返回 NULL。
句法
LEFT JOIN 的基本语法如下 –
SELECT table1.column1, table2.column2... FROM table1 LEFT JOIN table2 ON table1.common_field = table2.common_field;
这里给定的条件可以是基于您的要求的任何给定表达式。
例子
考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 –
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们使用 LEFT JOIN 查询连接这两个表,如下所示 –
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS LEFT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下输出 –
+----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | +----+----------+--------+---------------------+
右加入
HSQLDB RIGHT JOIN 返回右表中的所有行,即使左表中没有匹配项。这意味着如果 ON 子句匹配左表中的 0(零)条记录,连接仍将在结果中返回一行,但在左表中的每一列中都为 NULL。
这意味着右连接返回右表中的所有值,加上左表中匹配的值,或者在没有匹配连接谓词的情况下返回 NULL。
句法
RIGHT JOIN的基本语法如下 –
SELECT table1.column1, table2.column2... FROM table1 RIGHT JOIN table2 ON table1.common_field = table2.common_field;
例子
考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 –
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们使用 RIGHT JOIN 查询连接这两个表,如下所示 –
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS RIGHT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下结果。
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
完全加入
HSQLDB FULL JOIN 结合了左右外连接的结果。
连接表将包含来自两个表的所有记录,并为任一侧缺少的匹配项填充 NULL。
句法
FULL JOIN 的基本语法如下 –
SELECT table1.column1, table2.column2... FROM table1 FULL JOIN table2 ON table1.common_field = table2.common_field;
这里给定的条件可以是基于您的要求的任何给定表达式。
例子
考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 –
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
现在,让我们使用 FULL JOIN 查询连接这两个表,如下所示 –
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS FULL JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
执行上述查询后,您将收到以下结果。
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
自加入
SQL SELF JOIN 用于将表与自身连接,就好像该表是两个表一样,临时重命名 SQL 语句中的至少一个表。
句法
SELF JOIN 的基本语法如下 –
SELECT a.column_name, b.column_name... FROM table1 a, table1 b WHERE a.common_field = b.common_field;
在这里,WHERE 子句可以是基于您的要求的任何给定表达式。
例子
考虑以下两个表,一个名为 CUSTOMERS 表,另一个名为 ORDERS 表,如下所示 –
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
现在,让我们使用 SELF JOIN 查询加入该表,如下所示 –
SELECT a.ID, b.NAME, a.SALARY FROM CUSTOMERS a, CUSTOMERS b WHERE a.SALARY > b.SALARY;
执行上述查询后,您将收到以下输出 –
+----+----------+---------+ | ID | NAME | SALARY | +----+----------+---------+ | 2 | Ramesh | 1500.00 | | 2 | kaushik | 1500.00 | | 1 | Chaitali | 2000.00 | | 2 | Chaitali | 1500.00 | | 3 | Chaitali | 2000.00 | | 6 | Chaitali | 4500.00 | | 1 | Hardik | 2000.00 | | 2 | Hardik | 1500.00 | | 3 | Hardik | 2000.00 | | 4 | Hardik | 6500.00 | | 6 | Hardik | 4500.00 | | 1 | Komal | 2000.00 | | 2 | Komal | 1500.00 | | 3 | Komal | 2000.00 | | 1 | Muffy | 2000.00 | | 2 | Muffy | 1500.00 | | 3 | Muffy | 2000.00 | | 4 | Muffy | 6500.00 | | 5 | Muffy | 8500.00 | | 6 | Muffy | 4500.00 | +----+----------+---------+
HsqlDB – 空值
SQL NULL 是用于表示缺失值的术语。表中的 NULL 值是字段中显示为空白的值。每当我们尝试给出一个条件,将字段或列值与 NULL 进行比较时,它都无法正常工作。
我们可以通过使用这三样东西来处理 NULL 值。
-
IS NULL – 如果列值为 NULL,则运算符返回 true。
-
IS NOT NULL – 如果列值为 NOT NULL,则运算符返回 true。
-
<=> – 运算符比较值,即使对于两个 NULL 值也是如此(与 = 运算符不同)。
要查找 NULL 或 NOT NULL 的列,请分别使用 IS NULL 或 IS NOT NULL。
例子
让我们考虑一个示例,其中有一个表tcount_tbl,其中包含两列:author 和 tutorial_count。我们可以为 tutorial_count 提供 NULL 值,表示作者甚至没有发布一篇教程。因此,相应作者的 tutorial_count 值为 NULL。
执行以下查询。
create table tcount_tbl(author varchar(40) NOT NULL, tutorial_count INT);
INSERT INTO tcount_tbl values ('Abdul S', 20);
INSERT INTO tcount_tbl values ('Ajith kumar', 5);
INSERT INTO tcount_tbl values ('Jen', NULL);
INSERT INTO tcount_tbl values ('Bavya kanna', 8);
INSERT INTO tcount_tbl values ('mahran', NULL);
INSERT INTO tcount_tbl values ('John Poul', 10);
INSERT INTO tcount_tbl values ('Sathya Murthi', 6);
使用以下命令显示tcount_tbl表中的所有记录。
select * from tcount_tbl;
执行上述命令后,您将收到以下输出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Abdul S | 20 | | Ajith kumar | 5 | | Jen | NULL | | Bavya kanna | 8 | | mahran | NULL | | John Poul | 10 | | Sathya Murthi | 6 | +-----------------+----------------+
要查找 tutorial_count 列为 NULL 的记录,请执行以下查询。
SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;
执行查询后,您将收到以下输出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Jen | NULL | | mahran | NULL | +-----------------+----------------+
要查找 tutorial_count 列不是 NULL 的记录,请执行以下查询。
SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;
执行查询后,您将收到以下输出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Abdul S | 20 | | Ajith kumar | 5 | | Bavya kanna | 8 | | John Poul | 10 | | Sathya Murthi | 6 | +-----------------+----------------+
HSQLDB – JDBC 程序
这是 JDBC 程序,它从表 tcount_tbl 中分别检索记录,其中 tutorial_count 为 NULL,tutorial_count 为 NOT NULL。将以下程序保存到NullValues.java 中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class NullValues {
public static void main(String[] args) {
Connection con = null;
Statement stmt_is_null = null;
Statement stmt_is_not_null = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt_is_null = con.createStatement();
stmt_is_not_null = con.createStatement();
result = stmt_is_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;");
System.out.println("Records where the tutorial_count is NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
result = stmt_is_not_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;");
System.out.println("Records where the tutorial_count is NOT NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
使用以下命令编译并执行上述程序。
\>javac NullValues.java \>Java NullValues
执行上述命令后,您将收到以下输出。
Records where the tutorial_count is NULL Jen | 0 mahran | 0 Records where the tutorial_count is NOT NULL Abdul S | 20 Ajith kumar | 5 Bavya kanna | 8 John Poul | 10 Sathya Murthi | 6
HSQLDB – 正则表达式
HSQLDB 支持基于正则表达式和 REGEXP 运算符进行模式匹配操作的一些特殊符号。
以下是模式表,可与 REGEXP 运算符一起使用。
| Pattern | 模式匹配什么 |
|---|---|
| ^ | 字符串的开头 |
| $ | 字符串的结尾 |
| . | 任意单个字符 |
| […] | 方括号之间列出的任何字符 |
| [^…] | 方括号之间未列出的任何字符 |
| p1|p2|p3 | 交替;匹配任何模式 p1、p2 或 p3 |
| * | 前一个元素的零个或多个实例 |
| + | 前一元素的一个或多个实例 |
| {n} | 前一个元素的 n 个实例 |
| {m,n} | 前一个元素的 m 到 n 个实例 |
例子
让我们尝试不同的示例查询来满足我们的要求。看看以下给定的查询。
尝试此查询以查找名称以“^A”开头的所有作者。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^A.*');
执行上述查询后,您将收到以下输出。
+-----------------+ | author | +-----------------+ | Abdul S | | Ajith kumar | +-----------------+
尝试此查询以查找名称以“ul$”结尾的所有作者。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*ul$');
执行上述查询后,您将收到以下输出。
+-----------------+ | author | +-----------------+ | John Poul | +-----------------+
尝试此查询以查找名称包含“th”的所有作者。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*th.*');
执行上述查询后,您将收到以下输出。
+-----------------+ | author | +-----------------+ | Ajith kumar | | Abdul S | +-----------------+
尝试此查询以查找姓名以元音 (a, e, i, o, u) 开头的所有作者。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^[AEIOU].*');
执行上述查询后,您将收到以下输出。
+-----------------+ | author | +-----------------+ | Abdul S | | Ajith kumar | +-----------------+
HSQLDB – 事务
甲事务是数据库处理操作,其中执行,并视为一个单一的工作单元的顺序组。换句话说,当所有操作都成功执行后,整个交易才会完成。如果事务中的任何操作失败,那么整个事务都将失败。
交易属性
基本上,事务支持 4 个标准属性。它们可以称为 ACID 属性。
原子性– 事务中的所有操作都成功执行,否则事务将在失败点中止,并且先前的操作将回滚到先前的位置。
一致性– 数据库在成功提交事务后正确更改状态。
隔离– 它使交易能够独立运行并且彼此透明。
持久性– 在系统故障的情况下,提交事务的结果或影响仍然存在。
提交、回滚和保存点
这些关键字主要用于 HSQLDB 事务。
Commit – 始终应通过执行 COMMIT 命令来完成成功的事务。
回滚– 如果事务中发生故障,则应执行 ROLLBACK 命令以将事务中引用的每个表返回到其先前状态。
Savepoint – 在要回滚的事务组中创建一个点。
例子
以下示例解释了事务概念以及提交、回滚和保存点。让我们考虑包含列 id、姓名、年龄、地址和薪水的客户表。
| Id | 名称 | 年龄 | 地址 | 薪水 |
|---|---|---|---|---|
| 1 | 拉梅什 | 32 | 艾哈迈达巴德 | 2000.00 |
| 2 | 卡伦 | 25 | 德里 | 1500.00 |
| 3 | 考希克 | 23 | 哥打 | 2000.00 |
| 4 | 柴坦尼亚 | 25 | 孟买 | 6500.00 |
| 5 | 哈里什 | 27 | 博帕尔 | 8500.00 |
| 6 | 卡梅什 | 22 | 议员 | 1500.00 |
| 7 | 穆拉利 | 24 | 印多尔 | 10000.00 |
使用以下命令根据上述数据创建客户表。
CREATE TABLE Customer (id INT NOT NULL, name VARCHAR(100) NOT NULL, age INT NOT NULL, address VARCHAR(20), Salary INT, PRIMARY KEY (id)); Insert into Customer values (1, "Ramesh", 32, "Ahmedabad", 2000); Insert into Customer values (2, "Karun", 25, "Delhi", 1500); Insert into Customer values (3, "Kaushik", 23, "Kota", 2000); Insert into Customer values (4, "Chaitanya", 25, "Mumbai", 6500); Insert into Customer values (5, "Harish", 27, "Bhopal", 8500); Insert into Customer values (6, "Kamesh", 22, "MP", 1500); Insert into Customer values (7, "Murali", 24, "Indore", 10000);
提交示例
以下查询从表中删除年龄 = 25 的行,并使用 COMMIT 命令在数据库中应用这些更改。
DELETE FROM CUSTOMERS WHERE AGE = 25; COMMIT;
执行上述查询后,您将收到以下输出。
2 rows effected
成功执行上述命令后,通过执行以下给定命令检查客户表的记录。
Select * from Customer;
执行上述查询后,您将收到以下输出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000 | | 3 | kaushik | 23 | Kota | 2000 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
回滚示例
让我们考虑将相同的 Customer 表作为输入。
| Id | 名称 | 年龄 | 地址 | 薪水 |
|---|---|---|---|---|
| 1 | 拉梅什 | 32 | 艾哈迈达巴德 | 2000.00 |
| 2 | 卡伦 | 25 | 德里 | 1500.00 |
| 3 | 考希克 | 23 | 哥打 | 2000.00 |
| 4 | 柴坦尼亚 | 25 | 孟买 | 6500.00 |
| 5 | 哈里什 | 27 | 博帕尔 | 8500.00 |
| 6 | 卡梅什 | 22 | 议员 | 1500.00 |
| 7 | 穆拉利 | 24 | 印多尔 | 10000.00 |
这是通过从表中删除年龄 = 25 的记录然后回滚数据库中的更改来解释回滚功能的示例查询。
DELETE FROM CUSTOMERS WHERE AGE = 25; ROLLBACK;
成功执行以上两个查询后,可以使用以下命令查看Customer表中的记录数据。
Select * from Customer;
执行上述命令后,您将收到以下输出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000 | | 2 | Karun | 25 | Delhi | 1500 | | 3 | Kaushik | 23 | Kota | 2000 | | 4 | Chaitanya| 25 | Mumbai | 6500 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
删除查询删除年龄 = 25 岁的客户的记录数据。回滚命令回滚客户表上的这些更改。
保存点示例
保存点是事务中的一个点,当您可以将事务回滚到某个点而不回滚整个事务时。
让我们考虑将相同的 Customer 表作为输入。
| Id | 名称 | 年龄 | 地址 | 薪水 |
|---|---|---|---|---|
| 1 | 拉梅什 | 32 | 艾哈迈达巴德 | 2000.00 |
| 2 | 卡伦 | 25 | 德里 | 1500.00 |
| 3 | 考希克 | 23 | 哥打 | 2000.00 |
| 4 | 柴坦尼亚 | 25 | 孟买 | 6500.00 |
| 5 | 哈里什 | 27 | 博帕尔 | 8500.00 |
| 6 | 卡梅什 | 22 | 议员 | 1500.00 |
| 7 | 穆拉利 | 24 | 印多尔 | 10000.00 |
让我们考虑在此示例中,您计划从客户表中删除三个不同的记录。您希望在每次删除之前创建一个保存点,以便您可以随时回滚到任何保存点,将相应的数据恢复到其原始状态。
下面是一系列操作。
SAVEPOINT SP1; DELETE FROM CUSTOMERS WHERE ID = 1; SAVEPOINT SP2; DELETE FROM CUSTOMERS WHERE ID = 2; SAVEPOINT SP3; DELETE FROM CUSTOMERS WHERE ID = 3;
现在,您已经创建了三个保存点并删除了三个记录。在这种情况下,如果要回滚具有 Id 2 和 3 的记录,请使用以下回滚命令。
ROLLBACK TO SP2;
请注意,自从您回滚到 SP2 后,只发生了第一次删除。使用以下查询显示客户的所有记录。
Select * from Customer;
执行上述查询后,您将收到以下输出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 2 | Karun | 25 | Delhi | 1500 | | 3 | Kaushik | 23 | Kota | 2000 | | 4 | Chaitanya| 25 | Mumbai | 6500 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
释放保存点
我们可以使用 RELEASE 命令释放保存点。以下是通用语法。
RELEASE SAVEPOINT SAVEPOINT_NAME;
HsqlDB – 更改命令
每当需要更改表或字段的名称、更改字段的顺序、更改字段的数据类型或任何表结构时,都可以使用 ALTER 命令实现相同的目的。
例子
让我们考虑一个使用不同场景解释 ALTER 命令的示例。
使用以下查询创建一个名为testalter_tbl的表,其中包含字段的id和name。
//below given query is to create a table testalter_tbl table. create table testalter_tbl(id INT, name VARCHAR(10)); //below given query is to verify the table structure testalter_tbl. Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述查询后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
删除或添加列
每当您想从 HSQLDB 表中删除现有列时,您都可以将 DROP 子句与 ALTER 命令一起使用。
使用以下查询从表 testalter_tbl 中删除列 ( name )。
ALTER TABLE testalter_tbl DROP name;
成功执行上述查询后,您可以使用以下命令了解 name 字段是否从表 testalter_tbl 中删除。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述命令后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | +------------+-------------+------------+-----------+-----------+------------+
每当您想将任何列添加到 HSQLDB 表中时,您都可以将 ADD 子句与 ALTER 命令一起使用。
使用以下查询将名为NAME的列添加到表testalter_tbl。
ALTER TABLE testalter_tbl ADD name VARCHAR(10);
成功执行上述查询后,您可以使用以下命令了解名称字段是否添加到表testalter_tbl 中。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述查询后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
更改列定义或名称
每当需要更改列定义时,请将MODIFY或CHANGE子句与ALTER命令一起使用。
让我们考虑一个示例,该示例将解释如何使用 CHANGE 子句。表testalter_tbl包含两个字段 – id 和 name – 分别具有数据类型 int 和 varchar。现在让我们尝试将 id 的数据类型从 INT 更改为 BIGINT。以下是进行更改的查询。
ALTER TABLE testalter_tbl CHANGE id id BIGINT;
成功执行上述查询后,可以使用以下命令验证表结构。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述命令后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
现在让我们尝试将testalter_tbl表中列 NAME 的大小从 10 增加到 20 。以下是使用 MODIFY 子句和 ALTER 命令实现此目的的查询。
ALTER TABLE testalter_tbl MODIFY name VARCHAR(20);
成功执行上述查询后,可以使用以下命令验证表结构。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
执行上述命令后,您将收到以下输出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 20 | +------------+-------------+------------+-----------+-----------+------------+
HSQLDB – 索引
甲数据库索引是一种数据结构,提高了操作的速度在表中。可以使用一列或多列创建索引,为快速随机查找和对记录的访问进行有效排序提供基础。
创建索引时,应该考虑哪些列将用于进行 SQL 查询,并在这些列上创建一个或多个索引。
实际上,索引也是表的类型,它将主键或索引字段以及指向每个记录的指针保存到实际表中。
用户看不到索引。它们仅用于加快查询速度,数据库搜索引擎将使用它们来快速定位记录。
INSERT 和 UPDATE 语句在具有索引的表上花费更多时间,而 SELECT 语句在这些表上运行得更快。原因是在插入或更新时,数据库也需要插入或更新索引值。
简单唯一索引
您可以在表上创建唯一索引。一个唯一索引意味着两行不能有相同的索引值。以下是在表上创建索引的语法。
CREATE UNIQUE INDEX index_name ON table_name (column1, column2,...);
您可以使用一列或多列来创建索引。例如,使用tutorial_author 在tutorials_tbl 上创建索引。
CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author)
您可以在表上创建一个简单的索引。只需从查询中省略 UNIQUE 关键字即可创建一个简单的索引。一个简单的索引允许在表中重复的值。
如果要按降序索引列中的值,可以在列名后添加保留字 DESC。
CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author DESC)
添加和删除索引的 ALTER 命令
有四种类型的语句用于向表添加索引 –
-
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) – 该语句添加了一个 PRIMARY KEY,这意味着索引值必须是唯一的,不能为 NULL。
-
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list) – 此语句创建一个索引,其值必须是唯一的(NULL 值除外,它可能出现多次)。
-
ALTER TABLE tbl_name ADD INDEX index_name (column_list) – 这会添加一个普通索引,其中任何值都可能出现多次。
-
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list) – 这将创建一个特殊的 FULLTEXT 索引,用于文本搜索目的。
以下是在现有表中添加索引的查询。
ALTER TABLE testalter_tbl ADD INDEX (c);
您可以使用 DROP 子句和 ALTER 命令删除任何 INDEX。以下是删除上面创建的索引的查询。
ALTER TABLE testalter_tbl DROP INDEX (c);
显示索引信息
您可以使用 SHOW INDEX 命令列出与表关联的所有索引。垂直格式输出(由 \G 指定)通常与此语句一起使用,以避免长行回绕。
以下是显示有关表的索引信息的通用语法。
SHOW INDEX FROM table_name\G
