作为Write for DOnations计划的一部分,作者选择了免费和开源基金来接受捐赠。
介绍
Luigi是一个Python包,用于管理长时间运行的批处理,即批量项目的数据处理作业的自动运行。Luigi 允许您将数据处理作业定义为一组相关任务。例如,任务 B 取决于任务 A 的输出。任务 D 取决于任务 B 和任务 C 的输出。Luigi 自动计算出它需要运行哪些任务来完成请求的作业。
总的来说,Luigi 提供了一个框架来开发和管理数据处理管道。它最初是由Spotify开发的,他们用它来管理需要从各种来源获取和处理数据的任务集合。在 Luigi 中,Spotify 的开发人员构建了功能来帮助满足他们的批处理需求,包括故障处理、自动解决任务之间依赖关系的能力以及任务处理的可视化。Spotify 使用 Luigi 来支持批处理作业,包括向用户提供音乐推荐、填充内部仪表板以及计算热门歌曲列表。
在本教程中,您将构建一个数据处理管道来分析古腾堡计划中最流行的书籍中最常用的词。为此,您将使用 Luigi 包构建管道。您将使用 Luigi 任务、目标、依赖项和参数来构建您的管道。
先决条件
要完成本教程,您将需要以下内容:
- 使用具有
sudo特权的非 root 用户设置的 Ubuntu 服务器。按照使用 Ubuntu 20.04指南进行初始服务器设置。 - Python 3.6 或更高版本并
virtualenv已安装。按照如何在 Ubuntu 20.04 上安装 Python 3 和设置本地编程环境来配置 Python 并安装virtualenv. 您将在本教程中设置环境和项目文件夹。
第 1 步 — 安装 Luigi
在这一步中,您将为 Luigi 安装创建一个干净的沙箱环境。
首先,创建一个项目目录。对于本教程luigi-demo:
- mkdir luigi-demo
导航到新创建的luigi-demo目录:
- cd luigi-demo
创建一个新的虚拟环境luigi-venv:
- python3 -m venv luigi-venv
并激活新创建的虚拟环境:
- . luigi-venv/bin/activate
您会发现(luigi-venv)附加到终端提示的前面以指示哪个虚拟环境处于活动状态:
Output(luigi-venv) username@hostname:~/luigi-demo$
在本教程中,你将需要三个库:luigi,beautifulsoup4,和requests。该requests库简化了发出 HTTP 请求;您将使用它来下载 Project Gutenberg 书籍列表和要分析的书籍。该beautifulsoup4库提供了从网页中解析数据的函数;您将使用它来解析古腾堡计划网站上最受欢迎的书籍列表。
运行以下命令以使用 pip 安装这些库:
- pip install wheel luigi beautifulsoup4 requests
您将收到确认安装最新版本的库及其所有依赖项的响应:
OutputSuccessfully installed beautifulsoup4-4.9.1 certifi-2020.6.20 chardet-3.0.4 docutils-0.16 idna-2.10 lockfile-0.12.2 luigi-3.0.1 python-daemon-2.2.4 python-dateutil-2.8.1 requests-2.24.0 six-1.15.0 soupsieve-2.0.1 tornado-5.1.1 urllib3-1.25.10
您已经为您的项目安装了依赖项。现在,您将继续构建您的第一个 Luigi 任务。
步骤 2 — 创建 Luigi 任务
在这一步中,您将创建一个“Hello World”Luigi 任务来演示它们的工作原理。
Luigi任务是执行管道以及定义每个任务的输入和输出依赖项的地方。任务是您将从中创建管道的构建块。您在一个类中定义它们,其中包含:
- 甲
run()保持所述逻辑用于执行所述任务的方法。 output()返回由任务生成的工件的方法。该run()方法填充这些工件。- 一个可选
input()方法,返回管道中执行当前任务所需的任何其他任务。该run()方法使用这些来执行任务。
创建一个新文件hello-world.py:
- nano hello-world.py
现在将以下代码添加到您的文件中:
import luigi
class HelloLuigi(luigi.Task):
def output(self):
return luigi.LocalTarget('hello-luigi.txt')
def run(self):
with self.output().open("w") as outfile:
outfile.write("Hello Luigi!")
您可以HelloLuigi()通过向其中添加luigi.Task mixin来定义这是一个 Luigi 任务。
该output()方法定义Target了您的任务产生的一个或多个输出。在本例中,您定义了一个luigi.LocalTarget,它是一个本地文件。
注意: Luigi 允许您连接到各种常见数据源,包括AWS S3 存储桶、MongoDB 数据库和SQL 数据库。您可以在Luigi 文档 中找到支持的数据源的完整列表。
该run()方法包含要为管道阶段执行的代码。对于本示例,您将output()在写入模式下打开目标文件,self.output().open("w") as outfile:并"Hello Luigi!"使用outfile.write("Hello Luigi!").
要执行您创建的任务,请运行以下命令:
- python -m luigi --module hello-world HelloLuigi --local-scheduler
在这里,您使用python -m而不是luigi直接执行命令来运行任务;这是因为 Luigi 只能执行当前PYTHONPATH. 您也可以添加PYTHONPATH='.'到 Luigi 命令的前面,如下所示:
- PYTHONPATH='.' luigi --module hello-world HelloLuigi --local-scheduler
使用--module hello-world HelloLuigi标志,您可以告诉 Luigi 要执行哪个 Python 模块和 Luigi 任务。
该--local-scheduler标志告诉 Luigi 不要连接到 Luigi 调度程序,而是在本地执行此任务。(我们在第 4 步中解释了 Luigi 调度程序。)local-scheduler仅建议在开发工作中使用该标志运行任务。
Luigi 将输出已执行任务的摘要:
Output===== Luigi Execution Summary =====
Scheduled 1 tasks of which:
* 1 ran successfully:
- 1 HelloLuigi()
This progress looks :) because there were no failed tasks or missing dependencies
===== Luigi Execution Summary =====
它将创建一个hello-luigi.txt包含内容的新文件:
Hello Luigi!
您已经创建了一个生成文件的 Luigi 任务,然后使用 Luigi 执行它local-scheduler。现在,您将创建一个可以从网页中提取书籍列表的任务。
第 3 步 – 创建任务以提取书籍列表
在这一步中,您将创建一个 Luigi 任务并run()为该任务定义一个方法来下载古腾堡计划中最流行的书籍列表。您将定义一个output()方法来将这些书籍的链接存储在一个文件中。您将使用 Luigi 本地调度程序运行这些。
data在您的luigi-demo目录中创建一个新目录。这将是您存储output()任务方法中定义的文件的地方。您需要在运行任务之前创建目录——当您尝试将文件写入尚不存在的目录时,Python 会抛出异常:
- mkdir data
- mkdir data/counts
- mkdir data/downloads
创建一个新文件word-frequency.py:
- nano word-frequency.py
插入以下代码,这是一项 Luigi 任务,用于提取古腾堡计划中最常阅读的书籍的链接列表:
import requests
import luigi
from bs4 import BeautifulSoup
class GetTopBooks(luigi.Task):
"""
Get list of the most popular books from Project Gutenberg
"""
def output(self):
return luigi.LocalTarget("data/books_list.txt")
def run(self):
resp = requests.get("http://www.gutenberg.org/browse/scores/top")
soup = BeautifulSoup(resp.content, "html.parser")
pageHeader = soup.find_all("h2", string="Top 100 EBooks yesterday")[0]
listTop = pageHeader.find_next_sibling("ol")
with self.output().open("w") as f:
for result in listTop.select("li>a"):
if "/ebooks/" in result["href"]:
f.write("http://www.gutenberg.org{link}.txt.utf-8\n"
.format(
link=result["href"]
)
)
您定义output()文件目标"data/books_list.txt"来存储书籍列表。
在该run()方法中,您:
- 使用
requests图书馆下载古腾堡计划热门书籍页面的 HTML 内容。 - 使用
BeautifulSoup库来解析页面的内容。该BeautifulSoup库允许我们从网页中抓取信息。要了解有关使用 的更多信息BeautifulSoup library,请阅读如何使用 Beautiful Soup 和 Python 3教程抓取网页。 - 打开
output()方法中定义的输出文件。 - 遍历 HTML 结构以获取昨天排名前 100 的电子书列表中的所有链接。对于此页面,这是定位
<a>列表项中的所有链接<li>。对于这些链接中的每一个,如果它们链接到指向包含 的链接的页面/ebooks/,您可以假设它是一本书并将该链接写入您的output()文件。
完成后保存并退出文件。
使用以下命令执行此新任务:
- python -m luigi --module word-frequency GetTopBooks --local-scheduler
Luigi 将输出已执行任务的摘要:
Output===== Luigi Execution Summary =====
Scheduled 1 tasks of which:
* 1 ran successfully:
- 1 GetTopBooks()
This progress looks :) because there were no failed tasks or missing dependencies
===== Luigi Execution Summary =====
在data目录中,Luigi 将创建一个新文件 ( data/books_list.txt)。运行以下命令输出文件内容:
- cat data/books_list.txt
此文件包含从 Project Gutenberg 顶级项目列表中提取的 URL 列表:
Outputhttp://www.gutenberg.org/ebooks/1342.txt.utf-8
http://www.gutenberg.org/ebooks/11.txt.utf-8
http://www.gutenberg.org/ebooks/2701.txt.utf-8
http://www.gutenberg.org/ebooks/1661.txt.utf-8
http://www.gutenberg.org/ebooks/16328.txt.utf-8
http://www.gutenberg.org/ebooks/45858.txt.utf-8
http://www.gutenberg.org/ebooks/98.txt.utf-8
http://www.gutenberg.org/ebooks/84.txt.utf-8
http://www.gutenberg.org/ebooks/5200.txt.utf-8
http://www.gutenberg.org/ebooks/51461.txt.utf-8
...
您已经创建了一个可以从网页中提取书籍列表的任务。在下一步中,您将设置一个中央 Luigi 调度程序。
第 4 步 — 运行 Luigi 调度程序
现在,您将启动 Luigi 调度程序来执行和可视化您的任务。您将接受在步骤 3 中开发的任务并使用 Luigi 调度程序运行它。
到目前为止,您一直在使用--local-scheduler标签运行 Luigi 来在本地运行您的作业,而无需将工作分配给中央调度程序。这对开发很有用,但对于生产用途,建议使用 Luigi 调度程序。Luigi 调度程序提供:
- 执行任务的中心点。
- 任务执行的可视化。
要访问 Luigi 调度程序界面,您需要启用对端口的访问8082。为此,请运行以下命令:
- sudo ufw allow 8082/tcp
要运行调度程序,请执行以下命令:
- sudo sh -c ". luigi-venv/bin/activate ;luigid --background --port 8082"
注意:virtualenv在将 Luigi 调度程序作为后台任务启动之前,我们以 root 身份重新运行了activate 脚本。这是因为行驶时sudo的virtualenv环境变量和别名不结转。
如果不想以 root 身份运行,可以将 Luigi 调度程序作为当前用户的后台进程运行。此命令在后台运行 Luigi 调度程序并隐藏来自调度程序后台任务的消息。您可以在如何使用 Bash 的作业控制管理前台和后台进程中找到有关在终端中管理后台进程的更多信息:
- luigid --port 8082 > /dev/null 2> /dev/null &
打开浏览器以访问 Luigi 界面。这将是 at http://your_server_ip:8082,或者如果您已经为您的服务器设置了一个域http://your_domain:8082。这将打开 Luigi 用户界面。
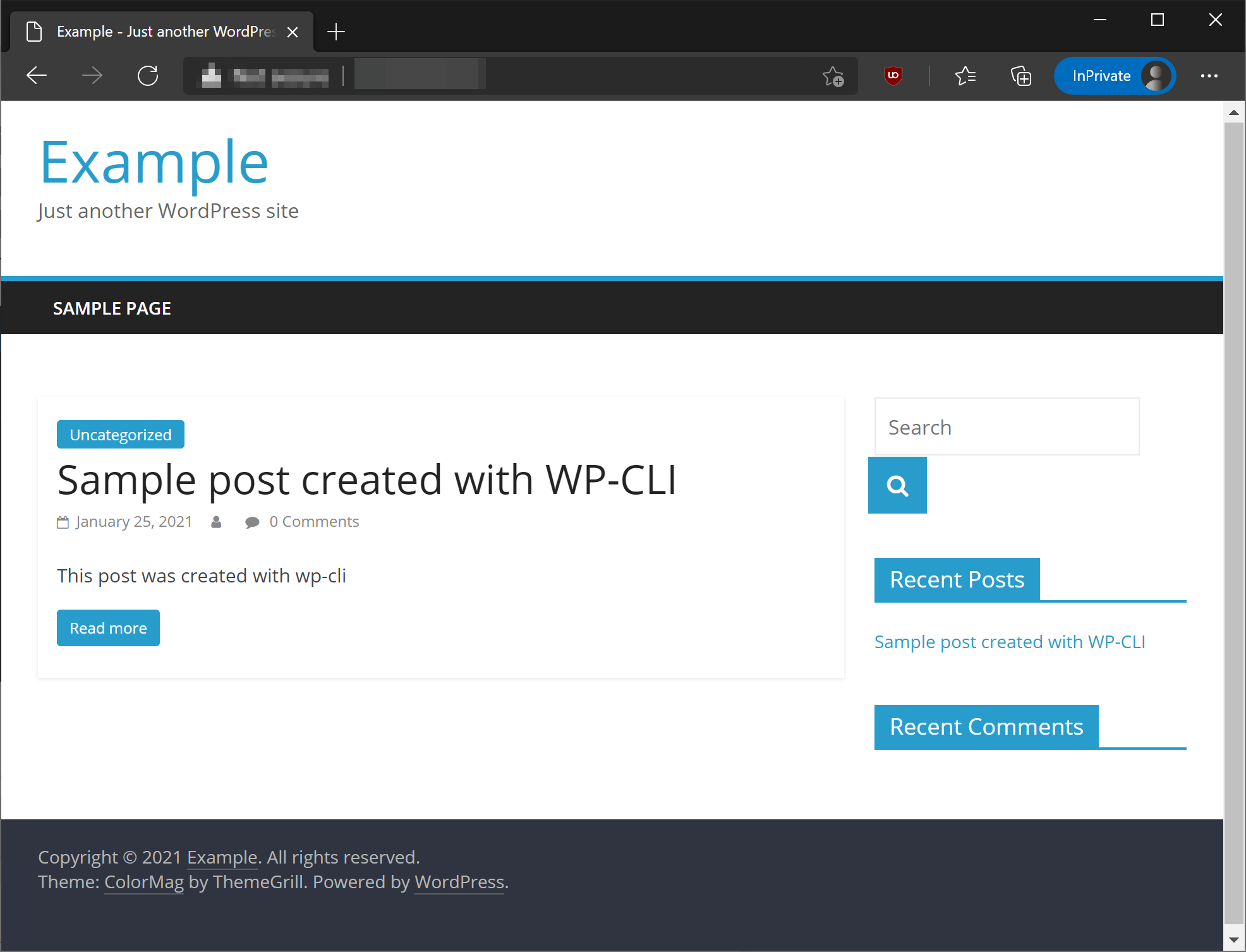
默认情况下,Luigi 任务使用 Luigi 调度程序运行。要使用 Luigi 调度程序运行您之前的任务之一,请省略--local-scheduler命令中的参数。使用以下命令重新运行步骤 3 中的任务:
- python -m luigi --module word-frequency GetTopBooks
刷新 Luigi 调度程序用户界面。您将找到添加到运行列表的GetTopBooks任务及其执行状态。
您将继续参考此用户界面来监控管道的进度。
注意:如果您想通过 HTTPS 保护您的 Luigi 调度程序,您可以通过 Nginx 为其提供服务。要使用 HTTPS 设置 Nginx 服务器,请执行以下操作:如何在 Ubuntu 20.04 上使用 Let’s Encrypt 保护 Nginx。有关将 Luigi 服务器连接到 Nginx 的合适 Nginx 配置的建议,请参阅Github – Luigi – Pull Request 2785。
您已经启动了 Luigi Scheduler 并使用它来可视化您执行的任务。接下来,您将创建一个任务来下载该GetTopBooks()任务输出的书籍列表。
第 5 步 — 下载书籍
在这一步中,您将创建一个 Luigi 任务来下载指定的书籍。您将定义这个新创建的任务与步骤 3 中创建的任务之间的依赖关系。
首先打开你的文件:
- nano word-frequency.py
使用以下代码GetTopBooks()在您的任务之后向word-frequency.py文件添加一个附加类:
. . .
class DownloadBooks(luigi.Task):
"""
Download a specified list of books
"""
FileID = luigi.IntParameter()
REPLACE_LIST = """.,"';_[]:*-"""
def requires(self):
return GetTopBooks()
def output(self):
return luigi.LocalTarget("data/downloads/{}.txt".format(self.FileID))
def run(self):
with self.input().open("r") as i:
URL = i.read().splitlines()[self.FileID]
with self.output().open("w") as outfile:
book_downloads = requests.get(URL)
book_text = book_downloads.text
for char in self.REPLACE_LIST:
book_text = book_text.replace(char, " ")
book_text = book_text.lower()
outfile.write(book_text)
在此任务中,您将引入一个Parameter; 在这种情况下,一个整数参数。Luigi参数是影响管道执行的任务的输入。这里引入了一个参数FileID来指定要获取的 URL 列表中的一行。
您为 Luigi 任务添加了一个额外的方法def requires();在此方法中,您可以定义需要输出的 Luigi 任务,然后才能执行此任务。您需要GetTopBooks()在步骤 3 中定义的任务的输出。
在该output()方法中,您定义目标。您可以使用该FileID参数为此步骤创建的文件创建名称。在这种情况下,您格式化data/downloads/{FileID}.txt.
在该run()方法中,您:
- 打开
GetTopBooks()任务中生成的书籍列表。 - 从参数指定的行中获取 URL
FileID。 - 使用
requests库从 URL 下载本书的内容。 - 过滤掉书中的任何特殊字符,例如
:,.?,这样它们就不会包含在您的单词分析中。 - 将文本转换为小写,以便您可以比较不同大小写的单词。
- 将过滤后的输出写入
output()方法中指定的文件。
保存并退出您的文件。
DownloadBooks()使用以下命令运行新任务:
- python -m luigi --module word-frequency DownloadBooks --FileID 2
在此命令中,您FileID使用--FileID参数设置参数。
注意:定义_名称中带有 的参数时要小心。要在 Luigi 中引用它们,您需要将 a 替换_为-。例如,当从终端调用任务时,File_ID将引用参数--File-ID。
您将收到以下输出:
Output===== Luigi Execution Summary =====
Scheduled 2 tasks of which:
* 1 complete ones were encountered:
- 1 GetTopBooks()
* 1 ran successfully:
- 1 DownloadBooks(FileID=2)
This progress looks :) because there were no failed tasks or missing dependencies
===== Luigi Execution Summary =====
请注意输出中 Luigi 检测到您已经生成GetTopBooks()并跳过运行该任务的输出。此功能允许您最大限度地减少必须执行的任务数量,因为您可以重复使用以前运行的成功输出。
您创建了一个任务,该任务使用另一个任务的输出并下载了一套书籍进行分析。在下一步中,您将创建一个任务来计算已下载书籍中最常见的单词。
第 6 步 – 计算单词并总结结果
在这一步中,您将创建一个 Luigi 任务来计算步骤 5 中下载的每本书中的单词频率。这将是您并行执行的第一个任务。
首先再次打开您的文件:
- nano word-frequency.py
将以下导入添加到 的顶部word-frequency.py:
from collections import Counter
import pickle
将以下任务添加到word-frequency.py,在您的DownloadBooks()任务之后。此任务获取DownloadBooks()指定书籍的前一个任务的输出,并返回该书籍中最常见的单词:
class CountWords(luigi.Task):
"""
Count the frequency of the most common words from a file
"""
FileID = luigi.IntParameter()
def requires(self):
return DownloadBooks(FileID=self.FileID)
def output(self):
return luigi.LocalTarget(
"data/counts/count_{}.pickle".format(self.FileID),
format=luigi.format.Nop
)
def run(self):
with self.input().open("r") as i:
word_count = Counter(i.read().split())
with self.output().open("w") as outfile:
pickle.dump(word_count, outfile)
当您定义时,requires()您将FileID参数传递给下一个任务。当您指定一个任务依赖于另一个任务时,您指定了执行依赖任务所需的参数。
在run()你的方法中:
- 打开
DownloadBooks()任务生成的文件。 - 使用库中的内置
Counter对象collections。这提供了一种分析书中最常用单词的简单方法。 - 使用
pickle库来存储 PythonCounter对象的输出,以便您可以在以后的任务中重用该对象。pickle是一个用于将 Python 对象转换为字节流的库,您可以将其存储并恢复到以后的 Python 会话中。您必须设置 的format属性luigi.LocalTarget以允许它写pickle入库生成的二进制输出。
保存并退出您的文件。
CountWords()使用以下命令运行新任务:
- python -m luigi --module word-frequency CountWords --FileID 2
在 Luigi 调度程序用户界面中打开CountWords任务图视图。

取消选择Hide Done选项,并取消选择Upstream Dependencies。您将从您创建的任务中找到执行流程。

您已经创建了一个任务来计算下载的书中最常见的单词,并可视化这些任务之间的依赖关系。接下来,您将定义可用于自定义任务执行的参数。
步骤 7 — 定义配置参数
在此步骤中,您将向管道添加配置参数。这些将允许您自定义要分析的书籍数量以及要包含在结果中的单词数。
当您想设置任务之间共享的参数时,您可以创建一个Config()类。其他流水线阶段可以引用Config()类中定义的参数;这些是在执行作业时由管道设置的。
将以下Config()类添加到word-frequency.py. 这将在您的管道中为要分析的书籍数量和要包含在摘要中的最常用单词的数量定义两个新参数:
class GlobalParams(luigi.Config):
NumberBooks = luigi.IntParameter(default=10)
NumberTopWords = luigi.IntParameter(default=500)
将以下类添加到word-frequency.py. 该类聚合所有CountWords()任务的结果以创建最常用词的摘要:
class TopWords(luigi.Task):
"""
Aggregate the count results from the different files
"""
def requires(self):
requiredInputs = []
for i in range(GlobalParams().NumberBooks):
requiredInputs.append(CountWords(FileID=i))
return requiredInputs
def output(self):
return luigi.LocalTarget("data/summary.txt")
def run(self):
total_count = Counter()
for input in self.input():
with input.open("rb") as infile:
nextCounter = pickle.load(infile)
total_count += nextCounter
with self.output().open("w") as f:
for item in total_count.most_common(GlobalParams().NumberTopWords):
f.write("{0: <15}{1}\n".format(*item))
在该requires()方法中,您可以提供一个列表,您希望一个任务在其中使用多个依赖任务的输出。您可以使用该GlobalParams().NumberBooks参数来设置需要进行字数统计的书籍数量。
在该output()方法中,您定义了一个data/summary.txt输出文件,该文件将成为管道的最终输出。
在run()你的方法中:
- 创建一个
Counter()对象来存储总计数。 - 打开文件并“解压”它(将它从文件转换回 Python 对象),对于
CountWords()方法中执行的每个计数 - 附加加载的计数并将其添加到总计数中。
- 将最常用的单词写入目标输出文件。
使用以下命令运行管道:
- python -m luigi --module word-frequency TopWords --GlobalParams-NumberBooks 15 --GlobalParams-NumberTopWords 750
Luigi 将执行生成热门词摘要所需的剩余任务:
Output===== Luigi Execution Summary =====
Scheduled 31 tasks of which:
* 2 complete ones were encountered:
- 1 CountWords(FileID=2)
- 1 GetTopBooks()
* 29 ran successfully:
- 14 CountWords(FileID=0,1,10,11,12,13,14,3,4,5,6,7,8,9)
- 14 DownloadBooks(FileID=0,1,10,11,12,13,14,3,4,5,6,7,8,9)
- 1 TopWords()
This progress looks :) because there were no failed tasks or missing dependencies
===== Luigi Execution Summary =====
您可以从 Luigi 调度程序可视化管道的执行。在任务列表中选择GetTopBooks任务,然后按查看图表按钮。

取消选择隐藏完成和上游依赖项选项。

它将显示 Luigi 中发生的处理流程。
打开data/summary.txt文件:
- cat data/summary.txt
您会发现计算出的最常用词:
Outputthe 64593
and 41650
of 31896
to 31368
a 25265
i 23449
in 19496
it 16282
that 15907
he 14974
...
在此步骤中,您已定义并使用参数来自定义任务的执行。您已经为一套书籍生成了最常用词的摘要。
在此存储库中查找本教程的所有代码。
结论
本教程向您介绍了使用 Luigi 数据处理管道及其主要功能,包括任务、参数、配置参数和 Luigi 调度程序。
Luigi 支持开箱即用地连接到大量常见数据源。您还可以扩展它以运行大型、复杂的数据管道。这提供了一个强大的框架来开始解决您的数据处理挑战。
如需更多教程,请查看我们的数据分析主题页面和Python 主题页面。
