Apache Derby – 快速指南
Apache Derby – 快速指南
Apache Derby – 简介
Apache Derby是一个ř elational d atabase中号anagement小号ystem,其完全基于(写入/中实现)的Java编程语言。它是由 Apache 软件基金会开发的开源数据库。
Oracle 发布了名为 JavaDB 的等效 Apache Derby。
Apache Derby 的特点
以下是 Derby 数据库的显着特点 –
-
平台独立– Derby 使用磁盘数据库格式,其中的数据库存储在磁盘中与数据库同名的目录中的文件中。
-
无修改数据– 因此,您可以将 derby 数据库移动到其他机器而无需修改数据。
-
事务支持– Derby 为确保数据完整性的事务提供完整的支持。
-
包含数据库– 您可以将预先构建/现有的数据库包含到您当前的 derby 应用程序中。
-
更少的空间– Derby 数据库占用空间小,即它占用的空间更少,并且易于使用和部署。
-
嵌入 Java 应用程序– Derby 提供了一个嵌入式数据库引擎,它可以嵌入到 Java 应用程序中,并且它将与应用程序在相同的 JVM 中运行。只需加载驱动程序即可启动数据库,并随着应用程序停止。
Apache Derby 的限制
以下是 Apache Derby 的限制 –
-
Derby 不支持数据类型(例如 BLOB 和 LONGVARCHAR)的索引。
-
如果 Derby 没有足够的磁盘空间,它将立即关闭。
数据存储
在存储数据时,Apache Derby 遵循称为conglomerate的概念。在这种情况下,表的数据将存储在单独的文件中。同理,表的每个索引也存放在一个单独的文件中。因此,数据库中的每个表或索引都有一个单独的文件。
Apache Derby 库/组件
Apache Derby 发行版提供了各种组件。在您下载的 apache 发行版的 lib 文件夹中,您可以观察代表各种组件的 jar 文件。
| Jar file | 成分 | 描述 |
|---|---|---|
| derby.jar | 数据库引擎和 JDBC 驱动程序 |
Apache Derby 的数据库引擎是一个支持 JDBC 和 SQL API 的嵌入式关系数据库引擎。 这也充当嵌入式驱动程序,使用它您可以使用 Java 应用程序与 Derby 进行通信。 |
| derbynet.jar derbyrun.jar | 网络服务器 |
Apache Derby 的网络服务器提供客户端服务器功能,客户端可以通过网络连接到 Derby 服务器。 |
| derbyclient.jar | 网络客户端 JDBC 驱动程序 | |
| derbytools.jar | 命令行工具 | 这个 jar 文件包含诸如sysinfo、ij和dblook 之类的工具。 |
| derbyoptionaltools.jar | 可选的命令行实用程序(工具) |
这个jar文件提供了可选工具:databaseMetaData可选工具、foreignViews可选工具、luceneSupport可选工具、rawDBReader可选工具、simpleJson可选工具等 |
| derbyLocale_XX.jar | 用于本地化消息的 Jar 文件 |
除了上面提到的jar文件,还可以看到几个derbyLocale_XX.jar(es、fr、hu、it、ja等)。使用这些,您可以本地化 Apache Derby 的消息。 |
Apache Derby – 部署模式
您可以在两种模式下部署apache derby,即嵌入式模式和服务器模式。
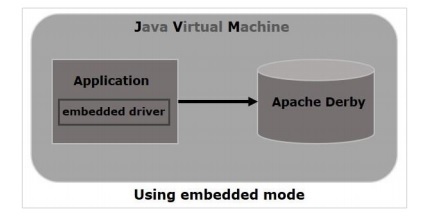
嵌入式模式
您可以使用 Java 应用程序(使用嵌入式驱动程序)以嵌入式模式运行 derby。如果您以嵌入式模式部署 Derby,那么数据库引擎将在与 Java 应用程序相同的 JVM 中运行。它随着应用程序开始和停止。您只能使用此应用程序访问数据库。
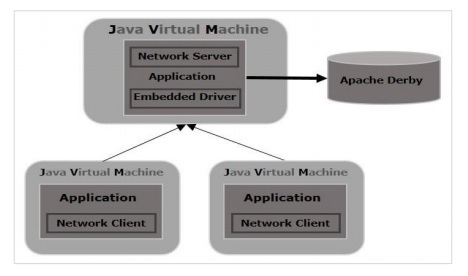
服务器模式
在服务器模式下,derby 将在应用服务器的 JVM 中运行,您可以在其中向服务器发送请求以访问它。与嵌入式模式不同,多个应用程序 (java) 可以向服务器发送请求并访问数据库。
Apache Derby – 环境设置
以下章节解释了如何下载和安装 Apache Derby。
下载 Apache Derby
访问 Apache Derby 主页https://db.apache.org/derby/ 的主页。单击下载选项卡。

选择并单击 Apache Derby 最新版本的链接。
单击所选链接后,您将被重定向到apache derby的Distributions页面。如果您在此处观察,则 derby 提供了发行版,即 db-derby-bin、db-derbylib.zip、db-derby-lib-debug.zip 和 db-derby-src.zip。
下载db-derby-bin文件夹。将其内容复制到要安装 Apache Derby 的单独文件夹中。(例如,说C:\Derby)
现在,为了与德比合作,
-
确保您已经通过传递 Java 安装文件夹的 bin 文件夹的位置来设置JAVA_HOME变量,并将JAVA_HOME/bin包含在 PATH 变量中。
-
创建一个新的环境变量DERBY_HOME,其值为 C:\Derby。
-
db-derby-bin 发行版的 bin 文件夹(我们将其更改为 C:\Derby\bin)包含所有必需的 jar 文件。
如前所述,Apache Derby 可以通过以下两种方式安装/部署 –
-
嵌入式模式– 在这种情况下,您需要使用嵌入式 Derby JDBC 驱动程序访问数据库。您可以通过 Java 应用程序启动和停止 derby。数据库引擎和您的应用程序都将在同一个 JVM 上运行。
-
网络服务器模式– 在此模式下,您可以以典型的客户端服务器方式访问 Derby,其中 Derby 嵌入在服务器系统中。然后,运行在不同JVM(服务器的JVM)中的客户端机器将向服务器发送请求,服务器响应这些请求。
客户端可以是服务器的同一系统机器中的另一个 JVM,也可以是来自远程系统的 Java 应用程序。
以嵌入式模式安装 Derby
要以嵌入模式安装 Apache Derby,请在 CLASSPATH 中包含 jar 文件derby.jar。
或者,您可以通过运行setEmbeddedCP
命令为所需的 jar 文件设置类路径。浏览Apache Derby的bin目录并运行此文件,如下所示 –
C:\Users\MYUSER>cd %DERBY_HOME%/bin C:\Derby\bin>setEmbeddedCP.bat C:\Derby\bin>SET DERBY_HOME=C:\Derby C:\Derby\bin>set CLASSPATH=C:\Derby\lib\derby.jar;C:\Derby\lib\derbytools.jar;C:\Derby/lib/derby optionaltools.jar;C:\Users\Tutorialspoint\Google Drive\Office\Derby\derby_zip\New folder\db-derby-10.12.1.1- bin\lib;C:\EXAMPLES_\Task\jars\*;C:\EXAMPLES\jars\mysql-connector-java-5.1.40- bin.jar;C:\Users\Tutorialspoint\Google Drive\Office.Junit Update\jars;C:\Program Files\Apache Software Foundation\Tomcat 8.5\lib\*;C:\Derby\lib\*;
设置 Apache Derby 后,要访问它,请使用嵌入式驱动程序运行 Java 程序。
确认
您可以使用ij工具验证设置,如下所示 –
C:\Derby\bin>ij ij version 10.14 ij> connect 'jdbc:derby:SampleDB;create=true'; ij>
在网络服务器模式下安装 Derby
要在网络服务器模式下安装 Apache Derby,您需要将derbynet.jar和derbytools.jar文件包含到 CLASSPATH 中。
或者,您可以通过运行setNetworkServerCP
命令来设置所需 jar 文件的类路径。浏览Apache Derby的bin目录并运行此文件,如下所示 –
C:\Users\MYUSER>cd %DERBY_HOME%/bin C:\Derby\bin>setNetworkServerCP.bat C:\Derby\bin>SET DERBY_INSTALL=C:\Derby C:\Derby\bin>set CLASSPATH=C:\Derby\lib\derbynet.jar;C:\Derby\lib\derbytools.jar;C:\Derby/lib/de rbyoptionaltools.jar;C:\Users\Tutorialspoint\Google Drive\Office\Derby\derby_zip\New folder\db-derby-10.12.1.1- bin\lib;C:\EXAMPLES_\Task\jars\*;C:\EXAMPLES\jars\mysql-connector-java-5.1.40- bin.jar;C:\Users\Tutorialspoint\Google Drive\Office.Junit Update\jars;C:\Program Files\Apache Software Foundation\Tomcat 8.5\lib\*;C:\Derby\lib\*;
在服务器模式下启动 Derby
您可以通过运行命令startNetworkServer来启动网络服务器。浏览Apache Derby的bin目录并运行此命令,如下所示 –
C:\Derby\bin>startNetworkServer Fri Jan 04 11:20:30 IST 2019 : Security manager installed using the Basic server security policy. Fri Jan 04 11:20:30 IST 2019 : Apache Derby Network Server - 10.14.2.0 - (1828579) started and ready to accept connections on port 1527
或者,您可以使用derbyrun.jar启动服务器,如下所示 –
C:\Users\MYUSER>cd %DERBY_HOME%/lib C:\Derby\lib>java -jar derbyrun.jar server start Fri Jan 04 11:27:20 IST 2019: Security manager installed using the Basic server security policy. Fri Jan 04 11:27:21 IST 2019: Apache Derby Network Server - 10.14.2.0 - (1828579) started and ready to accept connections on port 1527
网络客户端
在客户端中,将 jar 文件derbyclient.jar和derbytools.jar 添加到 CLASSPATH。或者,运行setNetworkClientCP命令,如下所示 –
C:\Users\MYUSER>cd %DERBY_HOME%/bin C:\Derby\bin>setNetworkClientCP C:\Derby\bin>SET DERBY_HOME=C:\Derby C:\Derby\bin>set CLASSPATH=C:\Derby\lib\derbyclient.jar;C:\Derby\lib\derbytools.jar;C:\Derby/lib /derbyoptionaltools.jar;C:\Derby\lib\derby.jar;C:\Derby\lib\derbytools.jar;C:\D erby/lib/derbyoptionaltools.jar;C:\Users\Tutorialspoint\Google Drive\Office\Derby\derby_zip\New folder\db-derby-10.12.1.1- bin\lib;C:\EXAMPLES_\Task\jars\*;C:\EXAMPLES\jars\mysql-connector-java-5.1.40- bin.jar;C:\Users\Tutorialspoint\Google Drive\Office.Junit Update\jars;C:\Program Files\Apache Software Foundation\Tomcat 8.5\lib\*;C:\Derby\lib\*;
然后从这个客户端,你可以向服务器发送请求。
确认
您可以使用ij工具验证设置,如下所示 –
C:\Derby\bin>ij ij version 10.14 ij> connect 'jdbc:derby://localhost:1527/SampleDB;create=true'; ij>
Apache Derby Eclipse 环境
在使用 Eclipse 时,您需要为所有必需的 jar 文件设置构建路径。
第一步:创建项目并设置构建路径
打开 eclipse 并创建一个示例项目。右键单击项目并选择选项
Build Path -> Configure Build Path 如下所示 –
在Libraries选项卡的Java Build Path框架中,单击Add External JARs。
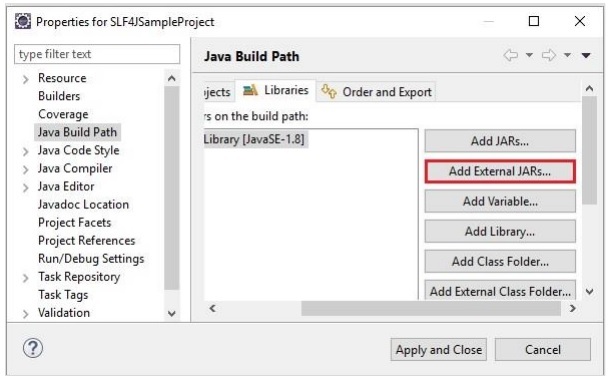
并在 Derby 安装文件夹的 lib 文件夹中选择所需的jar文件,然后单击Apply and Close。
Apache Derby – 工具
Apache Derby 为您提供了sysinfo、ij和dblook等工具。
系统信息工具
使用此工具,您可以获得有关 Java 和 Derby 环境的信息。
浏览 Derby 安装目录的 bin 文件夹并执行 sysinfo 命令,如下所示 –
C:\Users\MY_USER>cd %DERBY_HOME%/bin C:\Derby\bin>sysinfo
在执行时,它会为您提供有关 java 和 derby 的系统信息,如下所示 –
------------------ Java Information ------------------ Java Version: 1.8.0_101 Java Vendor: Oracle Corporation Java home: C:\Program Files\Java\jdk1.8.0_101\jre Java classpath: C:\Users\Tutorialspoint\Google Drive\Office\Derby\derby_zip\New folder\db-derby-10.12.1.1- bin\lib;C:\EXAMPLES_\Task\jars\*;C:\EXAMPLES\jars\mysql-connector-java-5.1.40- bin.jar;C:\Users\Tutorialspoint\Google Drive\Office.Junit Update\jars;C:\Program Files\Apache Software Foundation\Tomcat 8.5\lib\*;C:\Derby\lib\derby.jar;C:\Derby\lib\derbyclient.jar;C:\Derby\lib\derb yLocale_cs.jar;C:\Derby\lib\derbyLocale_de_DE.jar;C:\Derby\lib\derbyLocale_es.j ar;C:\Derby\lib\derbyLocale_fr.jar;C:\Derby\lib\derbyLocale_hu.jar;C:\Derby\lib \derbyLocale_it.jar;C:\Derby\lib\derbyLocale_ja_JP.jar;C:\Derby\lib\derbyLocale _ko_KR.jar;C:\Derby\lib\derbyLocale_pl.jar;C:\Derby\lib\derbyLocale_pt_BR.jar;C :\Derby\lib\derbyLocale_ru.jar;C:\Derby\lib\derbyLocale_zh_CN.jar;C:\Derby\lib\ derbyLocale_zh_TW.jar;C:\Derby\lib\derbynet.jar;C:\Derby\lib\derbyoptionaltools .jar;C:\Derby\lib\derbyrun.jar;C:\Derby\lib\derbytools.jar;;C:\Derby/lib/derby. jar;C:\Derby/lib/derbynet.jar;C:\Derby/lib/derbyclient.jar;C:\Derby/lib/derbyto ols.jar;C:\Derby/lib/derbyoptionaltools.jar OS name: Windows 10 OS architecture: amd64 OS version: 10.0 Java user name: Tutorialspoint Java user home: C:\Users\Tutorialspoint Java user dir: C:\Derby\bin java.specification.name: Java Platform API Specification java.specification.version: 1.8 java.runtime.version: 1.8.0_101-b13 --------- Derby Information -------- [C:\Derby\lib\derby.jar] 10.14.2.0 - (1828579) [C:\Derby\lib\derbytools.jar] 10.14.2.0 - (1828579) [C:\Derby\lib\derbynet.jar] 10.14.2.0 - (1828579) [C:\Derby\lib\derbyclient.jar] 10.14.2.0 - (1828579) [C:\Derby\lib\derbyoptionaltools.jar] 10.14.2.0 - (1828579) ------------------------------------------------------ ----------------- Locale Information ----------------- Current Locale : [English/United States [en_US]] Found support for locale: [cs] version: 10.14.2.0 - (1828579) Found support for locale: [de_DE] version: 10.14.2.0 - (1828579) Found support for locale: [es] version: 10.14.2.0 - (1828579) Found support for locale: [fr] version: 10.14.2.0 - (1828579) Found support for locale: [hu] version: 10.14.2.0 - (1828579) Found support for locale: [it] version: 10.14.2.0 - (1828579) Found support for locale: [ja_JP] version: 10.14.2.0 - (1828579) Found support for locale: [ko_KR] version: 10.14.2.0 - (1828579) Found support for locale: [pl] version: 10.14.2.0 - (1828579) Found support for locale: [pt_BR] version: 10.14.2.0 - (1828579) Found support for locale: [ru] version: 10.14.2.0 - (1828579) Found support for locale: [zh_CN] version: 10.14.2.0 - (1828579) Found support for locale: [zh_TW] version: 10.14.2.0 - (1828579) ------------------------------------------------------ ------------------------------------------------------
工具
使用此工具,您可以运行 apache Derby 的脚本和查询。
浏览 Derby 安装目录的 bin 文件夹并执行 ij 命令,如下所示 –
C:\Users\MY_USER>cd %DERBY_HOME%/bin C:\Derby\bin>ij
这将为您提供ij shell,您可以在其中执行 derby 命令和脚本,如下所示 –
ij version 10.14 ij>
使用help命令,您可以获取此 shell 支持的命令列表。
C:\Derby\bin>cd %DERBY_HOME%/bin
C:\Derby\bin>ij
ij version 10.14
ij> help;
Supported commands include:
PROTOCOL 'JDBC protocol' [ AS ident ];
-- sets a default or named protocol
DRIVER 'class for driver'; -- loads the named class
CONNECT 'url for database' [ PROTOCOL namedProtocol ] [ AS connectionName ];
-- connects to database URL
-- and may assign identifier
SET CONNECTION connectionName; -- switches to the specified connection
SHOW CONNECTIONS; -- lists all connections
AUTOCOMMIT [ ON | OFF ]; -- sets autocommit mode for the connection
DISCONNECT [ CURRENT | connectionName | ALL ];
-- drop current, named, or all connections;
-- the default is CURRENT
SHOW SCHEMAS; -- lists all schemas in the current database
SHOW [ TABLES | VIEWS | PROCEDURES | FUNCTIONS | SYNONYMS ] { IN schema };
-- lists tables, views, procedures, functions or
synonyms
SHOW INDEXES { IN schema | FROM table };
-- lists indexes in a schema, or for a table
SHOW ROLES; -- lists all defined roles in the database,
sorted
SHOW ENABLED_ROLES; -- lists the enabled roles for the current
-- connection (to see current role use
-- VALUES CURRENT_ROLE), sorted
SHOW SETTABLE_ROLES; -- lists the roles which can be set for the
-- current connection, sorted
DESCRIBE name; -- lists columns in the named table
COMMIT; -- commits the current transaction
ROLLBACK; -- rolls back the current transaction
PREPARE name AS 'SQL-J text'; -- prepares the SQL-J text
EXECUTE { name | 'SQL-J text' } [ USING { name | 'SQL-J text' } ] ;
-- executes the statement with parameter
-- values from the USING result set row
REMOVE name; -- removes the named previously prepared
statement
RUN 'filename'; -- run commands from the named file
ELAPSEDTIME [ ON | OFF ]; -- sets elapsed time mode for ij
MAXIMUMDISPLAYWIDTH integerValue;
-- sets the maximum display width for
-- each column to integerValue
ASYNC name 'SQL-J text'; -- run the command in another thread
WAIT FOR name; -- wait for result of ASYNC'd command
HOLDFORCONNECTION; -- sets holdability for a connection to HOLD
-- (i.e. ResultSet.HOLD_CURSORS_OVER_COMMIT)
NOHOLDFORCONNECTION; -- sets holdability for a connection to NO HOLD
-- (i.e. ResultSet.CLOSE_CURSORS_AT_COMMIT)
GET [SCROLL INSENSITIVE] [WITH { HOLD | NOHOLD }] CURSOR name AS 'SQL-J
query';
-- gets a cursor (JDBC result set) on the query
-- the default is a forward-only cursor with
holdability
NEXT name; -- gets the next row from the named cursor
FIRST name; -- gets the first row from the named scroll
cursor
LAST name; -- gets the last row from the named scroll
cursor
PREVIOUS name; -- gets the previous row from the named scroll
cursor
ABSOLUTE integer name; -- positions the named scroll cursor at the
absolute row number
-- (A negative number denotes position from the
last row.)
RELATIVE integer name; -- positions the named scroll cursor relative to
the current row
-- (integer is number of rows)
AFTER LAST name; -- positions the named scroll cursor after the
last row
BEFORE FIRST name; -- positions the named scroll cursor before the
first row
GETCURRENTROWNUMBER name; -- returns the row number for the current
position of the named scroll cursor
-- (0 is returned when the cursor is not
positioned on a row.)
CLOSE name; -- closes the named cursor
LOCALIZEDDISPLAY [ ON | OFF ];
-- controls locale sensitive data representation
EXIT; -- exits ij
HELP; -- shows this message
Any unrecognized commands are treated as potential SQL-J commands and executed
directly.
数据库查看工具
该工具用于生成数据定义语言。
浏览 Derby 安装目录的 bin 文件夹并执行dblook命令,如下所示 –
C:\Users\MY_USER>cd %DERBY_HOME%/bin C:\Derby\bin>dblook -d myURL
其中,myURL是需要生成 DDL 的数据库的连接 URL。
Apache Derby – 语法
本章为您提供了所有 Apache Derby SQL 语句的语法。
所有语句都以任何关键字开头,例如 SELECT、INSERT、UPDATE、DELETE、ALTER、DROP、CREATE、USE、SHOW,并且所有语句都以分号 (;) 结尾。
Apache Derby 的 SQL 语句区分大小写,包括表名。
创建语句
CREATE TABLE table_name ( column_name1 column_data_type1 constraint (optional), column_name2 column_data_type2 constraint (optional), column_name3 column_data_type3 constraint (optional) );
掉落表
DROP TABLE table_name;
插入语句
INSERT INTO table_name VALUES (column_name1, column_name2, ...);
SELECT 语句
SELECT column_name, column_name, ... FROM table_name;
更新声明
UPDATE table_name SET column_name = value, column_name = value, ... WHERE conditions;
DELETE 语句
DELETE FROM table_name WHERE condition;
DESCRIBE 声明
Describe table_name
SQL TRUNCATE TABLE 语句
TRUNCATE TABLE table_name;
ALTER 语句 – 添加列
ALTER TABLE table_name ADD COLUMN column_name column_type;
ALTER 语句 – 添加约束
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint (column_name);
ALTER 语句 – 删除列
ALTER TABLE table_name DROP COLUMN column_name;
ALTER 语句 – 删除约束
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
WHERE 条款
SELECT * from table_name WHERE condition; or, DELETE from table_name WHERE condition; or, UPDATE table_name SET column_name = value WHERE condition;
按条款分组
SELECT column1, column2, . . . table_name GROUP BY column1, column2, . . .;
按条款排序
SELECT * FROM table_name ORDER BY column_name ASC|DESC.
有条款
SELECT column1, column2 . . . from table_name GROUP BY column having condition;
创建索引
CTREATE INDEX index_name on table_name (column_name);
创建 UNIQUE 索引
CREATE UNIQUE INDEX index_name on table_name (column_name);
创建复合索引
CREATE INDEX index_name on table_name (column_name1, column_name2);
显示索引
SHOW INDEXES FROM table_name;
删除索引
DROP INDEX index_name;
Apache Derby – 数据类型
数据类型是指定任何对象的数据类型的属性。每个列、变量和表达式都有一个相关的数据类型。您可以在创建表时使用这些数据类型。您可以根据需要为表列选择数据类型。
Derby Server 提供多种数据类型供您使用,如下所列 –
整数数值数据类型
以下是整数数字数据类型的列表 –
| DATA TYPE | 尺寸 | 从 | 至 |
|---|---|---|---|
| SMALLINT | 2 字节 | -32768 | 32767 |
| INTEGER | 4字节 | -2,147,483,648 | 2,147,483,647 |
| BIGINT | 8 字节 | -9223372036854775808 | 9223372036854775808 |
近似数值数据类型
以下是近似数值数据类型的列表 –
| DATA TYPE | 尺寸 | 从 | 至 |
|---|---|---|---|
| REAL | 4字节 | -3.40E + 38 | 3.40E + 38 |
| DOUBLE PRECISION | 8 字节 | -1.79E + 308 | 1.79E + 308 |
| FLOAT | -1.79E + 308 | 1.79E + 308 |
精确数字数据类型
以下是确切数字数据类型的列表 –
| DATA TYPE | 从 | 至 |
|---|---|---|
| DECIMAL | -10^38 +1 | 10^38 -1 |
| NUMERIC | -10^38 +1 | 10^38 -1 |
Apache Derby – 创建表
CREATE TABLE 语句用于在 Derby 数据库中创建一个新表。
句法
以下是 CREATE 语句的语法。
CREATE TABLE table_name ( column_name1 column_data_type1 constraint (optional), column_name2 column_data_type2 constraint (optional), column_name3 column_data_type3 constraint (optional) );
在 Apache Derby 中创建表的另一种方法是您可以使用查询指定列名和数据类型。下面给出了这个语法 –
CREATE TABLE table_name AS SELECT * FROM desired_table WITH NO DATA;
例子
下面的 SQL 语句创建一个名为Student 的表,有四列,其中 id 是主键,它是自动生成的。
ij> CREATE TABLE Student ( Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, Age INT NOT NULL, First_Name VARCHAR(255), last_name VARCHAR(255), PRIMARY KEY (Id) ); > > > > > > > 0 rows inserted/updated/deleted
如果表存在,DESCRIBE 命令通过列出列及其详细信息来描述指定的表。您可以使用此命令来验证表是否已创建。
ij> DESCRIBE Student; COLUMN_NAME |TYPE_NAME |DEC&|NUM&|COLUM&|COLUMN_DEF|CHAR_OCTE&|IS_NULL& ------------------------------------------------------------------------------ ID |INTEGER |0 |10 |10 |AUTOINCRE&|NULL |NO AGE |INTEGER |0 |10 |10 |NULL |NULL |NO FIRST_NAME |VARCHAR |NULL|NULL|255 |NULL |510 |YES LAST_NAME |VARCHAR |NULL|NULL|255 |NULL |510 |YES 4 rows selected
使用JDBC程序创建表
本节教您如何使用 JDBC 应用程序在 Apache Derby 数据库中创建表。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/DATABASE_NAME;create=true;user=USER_NAME;password=PASSWORD”。
按照下面给出的步骤在 Apache Derby 中创建一个表 –
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类的forName()方法Class接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement 或 CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement() 和 prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()等INSERT,UPDATE方法执行查询,删除。该的executeQuery()方法的结果返回数据等使用了上述两种方法并执行先前创建的声明。
例子
以下 JDBC 示例演示了如何使用 JDBC 程序在 Apache Derby 中创建表。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class CreateTable {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Executing the query
String query = "CREATE TABLE Employees( "
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), "
+ "Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
stmt.execute(query);
System.out.println("Table created");
}
}
输出
在执行上述程序时,您将获得以下输出
Table created
Apache Derby – 删除表
DROP TABLE 语句用于删除现有表,包括其所有触发器、约束、权限。
句法
以下是 DROP TABLE 语句的语法。
ij> DROP TABLE table_name;
例子
假设您在数据库中有一个名为 Student 的表。以下 SQL 语句删除名为 Student 的表。
ij> DROP TABLE Student; 0 rows inserted/updated/deleted
由于如果我们试图描述它,我们已经删除了表格,我们将得到如下错误
ij> DESCRIBE Student; IJ ERROR: No table exists with the name STUDENT
使用JDBC程序删除表
本节教您如何使用 JDBC 应用程序删除 Apache Derby 数据库中的表。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/DATABASE_NAME;create=true;user=USER_NAME;password= PASSWORD “
按照下面给出的步骤在 Apache Derby 中删除一个表
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类Class的forName()方法接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement或CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement() 和 prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()方法执行查询状插入,更新,删除。该的executeQuery()方法的结果返回数据等使用了上述两种方法并执行先前创建的声明。
例子
以下 JDBC 示例演示了如何使用 JDBC 程序在 Apache Derby 中删除表。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DropTable {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Executing the query
String query = "DROP TABLE Employees";
stmt.execute(query);
System.out.println("Table dropped");
}
}
输出
在执行上述程序时,您将获得以下输出 –
Table dropped
Apache Derby – 插入数据
插入查询将数据:新记录插入表中。
句法
以下是 INSERT 语句的基本语法 –
ij>INSERT INTO table_name VALUES (column_name1, column_name2, ...);
其中 column1、column2 是要插入的行中的列值。
例子
下面的 SQL INSERT 语句在 Student 表中插入一个新行,它在列id、age、first name和last name 中插入值。
SQL> INSERT INTO Student VALUES (101, 20, 'Zara', 'Ali');
语法 2
或者,您可以通过提及列名来插入两个特定列,如下所示 –
ij>INSERT INTO table_name VALUES (column_name1, column_name2, ...) VALUES (value1, value2, ...);
注意– Apache Derby 自动计算生成列的值。例如,不需要为本教程前面创建的 student 表中的 id 列传递值。如果您的表生成了列,请使用syntax2。
例子
ij> INSERT INTO Student(Age, First_Name, Last_Name) VALUES (21, 'Sucharitha' , 'Tyagi'); 1 row inserted/updated/deleted
而且,您还可以使用一个语句插入两行,如下所示 –
ij>INSERT INTO Student(Age, First_Name, Last_Name) VALUES (20, 'Amit', 'Bhattacharya'), (22, 'Rahul', 'Desai'); 2 rows inserted/updated/deleted
您可以使用 SELECT 命令验证表的内容(我们将在本教程后面讨论这个命令)。
语法 3
您可以在插入语句中使用另一个查询作为 –
INSERT INTO table_Name Query
例子
假设,我们在数据库中有一个名为First_Year的表,如下所示,其列与 Student 表中的列相似 –
ID |AGE |FIRST_NAME |LAST_NAME ----------------------------------------------------------------- 1 |20 |Raju |Pendyala 2 |21 |Bhargav |Prayaga 3 |22 |Deepthi |Yerramilli
您可以使用上述语法将此表中的值插入到学生表中 –
ij> INSERT INTO Student (Age, First_Name, Last_Name) SELECT Age, First_Name, Last_Name FROM First_Year; > 3 rows inserted/updated/deleted
执行上述所有插入语句后,Student 表将如下所示 –
ID |AGE |FIRST_NAME |LAST_NAME ------------------------------------------------------------- 1 |21 |Sucharitha |Tyagi 2 |20 |Amit |Bhattacharya 3 |22 |Rahul |Desai 4 |20 |Raju |Pendyala 5 |21 |Bhargav |Prayaga 6 |22 |Deepthi |Yerramilli
使用JDBC程序插入数据
本节教您如何使用 JDBC 应用程序将数据插入到 Apache Derby 数据库中的表中。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/ DATABASE_NAME;创建=真;用户=用户名;密码=密码“
按照下面给出的步骤将数据插入到 Apache Derby 的表中 –
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类的forName()方法Class接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement 或 CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement()和prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。
所述的executeUpdate()等INSERT,UPDATE方法执行查询,删除。该的executeQuery()方法的结果返回数据等使用了上述两种方法并执行先前创建的声明。
例子
以下 JDBC 示例演示了如何使用 JDBC 程序将数据插入 Apache Derby 中的表中。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class InsertData {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:SampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating a table and populating
String query = "CREATE TABLE Employees("
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
//Executing the query
String query = "INSERT INTO Employees("
+ "Name, Salary, Location) VALUES "
+ "('Amit', 30000, 'Hyderabad'), "
+ "('Kalyan', 40000, 'Vishakhapatnam'), "
+ "('Renuka', 50000, 'Delhi'), "
+ "('Archana', 15000, 'Mumbai'), "
+ "('Trupthi', 45000, 'Kochin'), "
+ "('Suchatra', 33000, 'Pune'), "
+ "('Rahul', 39000, 'Lucknow'), "
+ "('Trupti', 45000, 'Kochin')";
stmt.execute(query);
System.out.println("Values inserted");
}
}
输出
在执行上述程序时,您将获得以下输出 –
Values inserted
Apache Derby – 检索数据
SELECT 语句用于从表中检索数据。这以称为结果集的表的形式返回数据。
句法
以下是 SELECT 语句的语法 –
ij> SELECT column_name, column_name, ... FROM table_name; Or, Ij>SELECT * from table_name
例子
假设我们在数据库中有一个名为 Employees 的表,如下所示 –
ij> CREATE TABLE Employees ( Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, Name VARCHAR(255), Salary INT NOT NULL, Location VARCHAR(255), PRIMARY KEY (Id) ); > > > > > > > 0 rows inserted/updated/deleted
并且,在其中插入四条记录,如下所示 –
ij> INSERT INTO Employees (Name, Salary, Location) VALUES
('Amit', 30000, 'Hyderabad'),
('Kalyan', 40000, 'Vishakhapatnam'),
('Renuka', 50000, 'Delhi'),
('Archana', 15000, 'Mumbai');
> > > > 4 rows inserted/updated/deleted
以下 SQL 语句检索表中所有员工的姓名、年龄和工资详细信息;
ij> SELECT Id, Name, Salary FROM Employees;
此查询的输出是 –
ID |NAME |SALARY ------------------------------------------------------------------------ 1 |Amit |30000 2 |Kalyan |40000 3 |Renuka |50000 4 |Archana|15000 4 rows selected
如果你想一次得到这个表的所有记录,用*代替列名。
ij> select * from Employees;
这将产生以下结果 –
ID |NAME |SALARY |LOCATION ------------------------------------------------------------------ 1 |Amit |30000 |Hyderabad 2 |Kalyan |40000 |Vishakhapatnam 3 |Renuka |50000 |Delhi 4 |Archana|15000 |Mumbai 4 rows selected
使用 JDBC 程序检索数据
本节教您如何使用 JDBC 应用程序从 Apache Derby 数据库中的表中检索数据。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/ DATABASE_NAME ;create=true;user= USER_NAME ;passw ord= PASSWORD “
按照下面给出的步骤从 Apache Derby 中的表中检索数据 –
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类Class的forName()方法接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement或CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement()和prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()等INSERT,UPDATE方法执行查询,删除。该的executeQuery()方法的结果返回数据等使用了上述两种方法并执行先前创建的声明。
例子
以下 JDBC 示例演示了如何使用 JDBC 程序从 Apache Derby 中的表中检索数据。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
所述的executeQuery()方法返回一个结果集对象保持该语句的结果。最初结果集指针将位于第一条记录,您可以使用其next()和getXXX()方法打印 ResultSet 对象的内容。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class RetrieveData {
public static void main(String args[]) throws SQLException,
ClassNotFoundException {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
4Statement stmt = conn.createStatement();
//Creating a table and populating it
String query = "CREATE TABLE Employees("
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
String query = "INSERT INTO Employees("
+ "Name, Salary, Location) VALUES "
+ "('Amit', 30000, 'Hyderabad'), "
+ "('Kalyan', 40000, 'Vishakhapatnam'), "
+ "('Renuka', 50000, 'Delhi'), "
+ "('Archana', 15000, 'Mumbai'), "
+ "('Trupthi', 45000, 'Kochin'), "
+ "('Suchatra', 33000, 'Pune'), "
+ "('Rahul', 39000, 'Lucknow'), "
+ "('Trupti', 45000, 'Kochin')";
//Executing the query
String query = "SELECT Id, Name, Salary FROM Employees";
ResultSet rs = stmt.executeQuery(query);
while(rs.next()) {
System.out.println("Id: "+rs.getString("Id"));
System.out.println("Name: "+rs.getString("Name"));
System.out.println("Salary: "+rs.getString("Salary"));
System.out.println(" ");
}
}
}
输出
在执行上述程序时,您将获得以下输出
Id: 1 Name: Amit Salary: 30000 Id: 2 Name: Kalyan Salary: 43000 Id: 3 Name: Renuka Salary: 50000 Id: 4 Name: Archana Salary: 15000 Id: 5 Name: Trupthi Salary: 45000 Id: 6 Name: Suchatra Salary: 33000 Id: 7 Name: Rahul Salary: 39000
Apache Derby – 更新数据
UPDATE 语句用于更新表中的数据。Apache Derby 提供了两种类型的更新(语法),即搜索更新和定位更新。
搜索到的 UPDATE 语句更新表的所有指定列。
句法
以下是 UPDATE 查询的语法 –
ij> UPDATE table_name SET column_name = value, column_name = value, ... WHERE conditions;
WHERE 子句可以使用比较运算符,例如 =、!=、<、>、<= 和 >=,以及 BETWEEN 和 LIKE 运算符。
例子
假设您在数据库中有一个表 Employee,其中有 4 条记录,如下所示 –
ID |NAME |SALARY |LOCATION ---------------------------------------------------------- 1 |Amit |30000 |Hyderabad 2 |Kalyan |40000 |Vishakhapatnam 3 |Renuka |50000 |Delhi 4 |Archana|15000 |Mumbai
以下 SQL UPDATE 语句更新名为 Kaylan 的员工的位置和薪水。
ij> UPDATE Employees SET Location = 'Chennai', Salary = 43000 WHERE Name = 'Kalyan'; 1 rows inserted/updated/deleted
如果获得了Employees 表的内容,则可以观察UPDATE 查询所做的更改。
ij> select * from Employees; ID |NAME |SALARY |LOCATION ---------------------------------------------------------- 1 |Amit |30000 |Hyderabad 2 |Kalyan |43000 |Chennai 3 |Renuka |50000 |Delhi 4 |Archana|15000 |Mumbai 4 rows selected
使用 JDBC 程序更新数据
本节说明如何使用 JDBC 应用程序更新 Apache Derby 数据库中表的现有记录。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/ DATABASE_NAME ;create=true;user= USER_NAME ;passw ord= PASSWORD “
按照下面给出的步骤更新 Apache Derby 中表的现有记录。
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类Class的forName()方法接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。Connection 类表示与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement 或 CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement()和prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()等INSERT,UPDATE方法执行查询,删除。所述的executeQuery()方法返回的数据。使用其中一种方法并执行先前创建的语句。
例子
以下 JDBC 示例演示了如何使用 JDBC 程序更新 Apache Derby 中表的现有记录。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class UpdateData {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating a table and populating it
String query = "CREATE TABLE Employees("
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
String query = "INSERT INTO Employees("
+ "Name, Salary, Location) VALUES "
+ "('Amit', 30000, 'Hyderabad'), "
+ "('Kalyan', 40000, 'Vishakhapatnam'), "
+ "('Renuka', 50000, 'Delhi'), "
+ "('Archana', 15000, 'Mumbai'), "
+ "('Trupthi', 45000, 'Kochin'), "
+ "('Suchatra', 33000, 'Pune'), "
+ "('Rahul', 39000, 'Lucknow'), "
+ "('Trupti', 45000, 'Kochin')";
//Executing the query
String query = "UPDATE Employees SET Location = 'Chennai', Salary = 43000 WHERE
Name = 'Kalyan'";
int num = stmt.executeUpdate(query);
System.out.println("Number of records updated are: "+num);
}
}
输出
在执行上述程序时,您将获得以下输出 –
Number of records updated are: 1
Apache Derby – 删除数据
DELETE 语句用于删除表的行。就像 UPDATE 语句一样,Apache Derby 提供了两种类型的删除(语法):搜索删除和定位删除。
searched delete 语句删除表的所有指定列。
句法
DELETE 语句的语法如下 –
ij> DELETE FROM table_name WHERE condition;
例子
让我们假设我们有一个名为employee 的表,其中有 5 条记录,如下所示 –
ID |NAME |SALARY |LOCATION ---------------------------------------------------------------------------- 1 |Amit |30000 |Hyderabad 2 |Kalyan |40000 |Vishakhapatnam 3 |Renuka |50000 |Delhi 4 |Archana|15000 |Mumbai 5 |Trupti |45000 |Kochin 5 rows selected
以下 SQL DELETE 语句删除名为 Trupti 的记录。
ij> DELETE FROM Employees WHERE Name = 'Trupti'; 1 row inserted/updated/deleted
如果您获得员工表的内容,您只能看到如下所示的四条记录 –
ID |NAME |SALARY |LOCATION ---------------------------------------------------------------------------- 1 |Amit |30000 |Hyderabad 2 |Kalyan |40000 |Vishakhapatnam 3 |Renuka |50000 |Delhi 4 |Archana|15000 |Mumbai 4 rows selected
要删除表中的所有记录,请执行不带 where 子句的相同查询。
ij> DELETE FROM Employees; 4 rows inserted/updated/deleted
现在,如果您尝试获取 Employee 表的内容,您将获得一个空表,如下所示 –
ij> select * from employees; ID |NAME |SALARY |LOCATION -------------------------------------------------------- 0 rows selected
使用JDBC程序删除数据
本节介绍如何使用 JDBC 应用程序删除 Apache Derby 数据库中表的现有记录。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/ DATABASE_NAME;创建=真;用户=用户名;密码=密码“。
按照下面给出的步骤删除 Apache Derby 中表的现有记录:/p>
第一步:注册驱动
首先,您需要注册驱动程序以与数据库进行通信。类Class的forName()方法接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement 或 CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement() 和 prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()等INSERT,UPDATE方法执行查询,删除。所述的executeQuery()方法的结果返回的数据。使用其中一种方法并执行先前创建的语句。
例子
以下 JDBC 示例演示了如何使用 JDBC 程序在 Apache Derby 中删除表的现有记录。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class DeleteData {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating a table and populating it
String query = "CREATE TABLE Employees("
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
String query = "INSERT INTO Employees("
+ "Name, Salary, Location) VALUES "
+ "('Amit', 30000, 'Hyderabad'), "
+ "('Kalyan', 40000, 'Vishakhapatnam'), "
+ "('Renuka', 50000, 'Delhi'), "
+ "('Archana', 15000, 'Mumbai'), "
+ "('Trupthi', 45000, 'Kochin'), "
+ "('Suchatra', 33000, 'Pune'), "
+ "('Rahul', 39000, 'Lucknow'), "
+ "('Trupthi', 45000, 'Kochin')";
//Executing the query
String query = "DELETE FROM Employees WHERE Name = 'Trupthi'";
int num = stmt.executeUpdate(query);
System.out.println("Number of records deleted are: "+num);
}
}
输出
在执行上述程序时,您将获得以下输出 –
Number of records deleted are: 1
Apache Derby – Where 子句
WHERE 子句在 SELECT、DELETE 或 UPDATE 语句中用于指定需要对其执行操作的行。通常,该子句后跟一个返回布尔值的条件或表达式,选择、删除或更新操作仅对满足给定条件的行执行。
ij> SELECT * from table_name WHERE condition; or, ij> DELETE from table_name WHERE condition; or, ij> UPDATE table_name SET column_name = value WHERE condition;
WHERE 子句可以使用比较运算符,例如 =、!=、<、>、<= 和 >=,以及 BETWEEN 和 LIKE 运算符。
例子
假设我们在数据库中有一个名为 Employees 的表,其中有 7 条记录,如下所示 –
ID |NAME |SALARY |LOCATION ----------------------------------------------------------------------------- 1 |Amit |30000 |Hyderabad 2 |Kalyan |40000 |Vishakhapatnam 3 |Renuka |50000 |Delhi 4 |Archana |15000 |Mumbai 5 |Trupthi |45000 |Kochin 6 |Suchatra |33000 |Pune 7 |Rahul |39000 |Lucknow
以下 SQL DELETE 语句获取工资超过 35000 的员工的记录 –
ij> SELECT * FROM Employees WHERE Salary>35000;
这将产生以下输出 –
ID |NAME |SALARY |LOCATION --------------------------------------------------- 2 |Kalyan |40000 |Vishakhapatnam 3 |Renuka |50000 |Delhi 5 |Trupthi|45000 |Kochin 7 |Rahul |39000 |Lucknow 4 rows selected
同样,您也可以使用此子句删除和更新记录。
以下示例更新工资低于 30000 的人的位置。
ij> UPDATE Employees SET Location = 'Vijayawada' WHERE Salary<35000; 3 rows inserted/updated/deleted
如果您验证表格的内容,您可以看到更新后的表格,如下所示 –
ij> SELECT * FROM Employees; ID |NAME |SALARY |LOCATION ------------------------------------------------------------------------------ 1 |Amit |30000 |Vijayawada 2 |Kalyan |40000 |Vishakhapatnam 3 |Renuka |50000 |Delhi 4 |Archana |15000 |Vijayawada 5 |Trupthi |45000 |Kochin 6 |Suchatra|33000 |Vijayawada 7 |Rahul |39000 |Lucknow 7 rows selected
where 子句 JDBC 示例
本节将教您如何使用 WHERE 子句并使用 JDBC 应用程序对 Apache Derby 数据库中的表执行 CURD 操作。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/ DATABASE_NAME ;create=true;user= USER_NAME; 密码=密码“。
按照下面给出的步骤使用 WHERE 子句并对 Apache Derby 中的表执行 CURD 操作
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类Class的forName()方法接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement或CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement() 和 prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()等INSERT,UPDATE方法执行查询,删除。所述的executeQuery()方法的结果返回的数据。使用其中一种方法并执行先前创建的语句。
例子
以下 JDBC 示例演示了如何使用 WHERE 子句并使用 JDBC 程序对 Apache Derby 中的表执行 CURD 操作。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.sql.ResultSet;
public class WhereClauseExample {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating a table and populating it
String query = "CREATE TABLE Employees("
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
String query = "INSERT INTO Employees("
+ "Name, Salary, Location) VALUES "
+ "('Amit', 30000, 'Hyderabad'), "
+ "('Kalyan', 40000, 'Vishakhapatnam'), "
+ "('Renuka', 50000, 'Delhi'), "
+ "('Archana', 15000, 'Mumbai'), "
+ "('Trupthi', 45000, 'Kochin'), "
+ "('Suchatra', 33000, 'Pune'), "
+ "('Rahul', 39000, 'Lucknow'), "
+ "('Trupti', 45000, 'Kochin')";
//Executing the query
String query = "SELECT * FROM Employees WHERE Salary>35000";
ResultSet rs = stmt.executeQuery(query);
while(rs.next()) {
System.out.println("Id: "+rs.getString("Id"));
System.out.println("Name: "+rs.getString("Name"));
System.out.println("Salary: "+rs.getString("Salary"));
System.out.println("Location: "+rs.getString("Location"));
System.out.println(" ");
}
}
}
输出
在执行上述程序时,您将获得以下输出 –
Id: 2 Name: Kalyan Salary: 43000 Location: Chennai Id: 3 Name: Renuka Salary: 50000 Location: Delhi Id: 5 Name: Trupthi Salary: 45000 Location: Kochin Id: 7 Name: Rahul Salary: 39000 Location: Lucknow
Apache Derby – GROUP BY 子句
GROUP BY 子句与 SELECT 语句一起使用。它用于在数据相同的情况下形成子集。通常,此子句后跟 ORDER BY 子句并放在 WHERE 子句之后。
句法
以下是 GROUP BY 子句的语法 –
ij>SELECT column1, column2, . . . table_name GROUP BY column1, column2, . . .;
例子
假设我们在数据库中有一个名为 Employees 的表,其中包含以下记录 –
ID |NAME |SALARY |LOCATION ------------------------------------------------------------------ 1 |Amit |30000 |Hyderabad 2 |Rahul |39000 |Lucknow 3 |Renuka |50000 |Hyderabad 4 |Archana |15000 |Vishakhapatnam 5 |Kalyan |40000 |Hyderabad 6 |Trupthi |45000 |Vishakhapatnam 7 |Raghav |12000 |Lucknow 8 |Suchatra|33000 |Vishakhapatnam 9 |Rizwan |20000 |Lucknow
以下带有 GROUP BY 子句的 SELECT 语句根据位置对表进行分组。它显示了在一个位置给予员工的工资总额。
ij> SELECT Location, SUM(Salary) from Employees GROUP BY Location;
这将生成以下输出 –
LOCATION |2 ------------------------------------------------------- Hyderabad |120000 Lucknow |71000 Vishakhapatnam |93000 3 rows selected
以同样的方式,以下查询查找员工在某个位置的平均花费作为工资。
ij> SELECT Location, AVG(Salary) from Employees GROUP BY Location;
这将生成以下输出 –
LOCATION |2 ----------------------------------------------------- Hyderabad |40000 Lucknow |23666 Vishakhapatnam |31000 3 rows selected
Group By 子句 JDBC 示例
本节教您如何使用 Group By 子句,并使用 JDBC 应用程序对 Apache Derby 数据库中的表执行 CURD 操作。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/ DATABASE_NAME;创建=真;用户=用户名;密码=密码“
按照下面给出的步骤使用 Group By 子句并对 Apache Derby 中的表执行 CURD 操作
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类Class的forName()方法接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement或CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement() 和 prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()方法用来执行状插入,更新,删除的查询。所述的executeQuery()方法返回的数据。使用其中一种方法并执行先前创建的语句。
例子
以下 JDBC 示例演示了如何使用Group By子句并使用 JDBC 程序对 Apache Derby 中的表执行 CURD 操作。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.sql.ResultSet;
public class GroupByClauseExample {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating a table and populating it
stmt.execute("CREATE TABLE EmployeesData( "
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), "
+ "Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))");
stmt.execute("INSERT INTO EmployeesData(Name, Salary, Location) "
+ "VALUES ('Amit', 30000, 'Hyderabad'), "
+ "('Rahul', 39000, 'Lucknow'), "
+ "('Renuka', 50000, 'Hyderabad'), "
+ "('Archana', 15000, 'Vishakhapatnam'), "
+ "('Kalyan', 40000, 'Hyderabad'), "
+ "('Trupthi', 45000, 'Vishakhapatnam'), "
+ "('Raghav', 12000, 'Lucknow'), "
+ "('Suchatra', 33000, 'Vishakhapatnam'), "
+ "('Rizwan', 20000, 'Lucknow')");
//Executing the query
String query = "SELECT Location, SUM(Salary) from EmployeesData GROUP BY Location";
ResultSet rs = stmt.executeQuery(query);
while(rs.next()) {
System.out.println("Location: "+rs.getString(1));
System.out.println("Sum of salary: "+rs.getString(2));
System.out.println(" ");
}
}
}
输出
在执行上述程序时,您将获得以下输出 –
Location: Hyderabad Sum of salary: 120000 Location: Lucknow Sum of salary: 71000 Location: Vishakhapatnam Sum of salary: 93000
Apache Derby – 按条款排序
ORDER BY 子句用于按照它使用关键字的顺序排列结果集的内容,ASC 表示升序,DESC 表示降序。如果您不提及其中任何一项,则默认情况下将按升序排列内容。
句法
以下是 ORDER BY 子句的语法 –
SELECT * FROM table_name ORDER BY column_name ASC|DESC.
例子
假设我们在数据库中有一个名为 Employees 的表,其中包含以下记录 –
ID |NAME |SALARY |LOCATION ------------------------------------------------------------------------------ 1 |Amit |30000 |Vijayawada 2 |Kalyan |40000 |Vishakhapatnam 3 |Renuka |50000 |Delhi 4 |Archana |15000 |Vijayawada 5 |Trupthi |45000 |Kochin 6 |Suchatra|33000 |Vijayawada 7 |Rahul |39000 |Lucknow
以下查询根据员工姓名按升序排列表的内容。
ij> SELECT * FROM Employees ORDER BY Name;
这将生成以下输出 –
ID |NAME |SALARY |LOCATION --------------------------------------------------------------- 1 |Amit |30000 |Hyderabad 4 |Archana |15000 |Mumbai 2 |Kalyan |40000 |Vishakhapatnam 7 |Rahul |39000 |Lucknow 3 |Renuka |50000 |Delhi 6 |Suchatra|33000 |Pune 5 |Trupthi |45000 |Kochin 7 rows selected
同样,以下查询根据员工的工资按降序排列表的内容 –
ij> SELECT * FROM Employees ORDER BY Salary DESC;
这将生成以下输出 –
ID |NAME |SALARY |LOCATION --------------------------------------------------------------- 3 |Renuka |50000 |Delhi 5 |Trupthi |45000 |Kochin 2 |Kalyan |40000 |Vishakhapatnam 7 |Rahul |39000 |Lucknow 6 |Suchatra |33000 |Pune 1 |Amit |30000 |Hyderabad 4 |Archana |15000 |Mumbai 7 rows selected
使用JDBC程序对数据进行排序
本节教您如何使用 JDBC 在 Derby 中对表的内容进行排序。您可以使用 ORDER BY 子句和关键字 ASC(表示升序)和 DSC(表示降序)按顺序排列记录。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/ DATABASE_NAME;创建=真;用户=用户名;密码=密码“。
按照下面给出的步骤对 Apache Derby 中的表的记录进行排序 –
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类Class的forName()方法接受一个表示类名的 String 值,将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement或CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement() 和 prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()等INSERT,UPDATE方法执行查询,删除。所述的executeQuery()方法返回的数据。使用其中一种方法并执行先前创建的语句。
例子
以下 JDBC 示例演示了如何使用 JDBC 程序在 Apache Derby 中对表的记录进行排序。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class SortData {
public static void main(String args[]) throws SQLException, ClassNotFoundException {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:SampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating a table and populating it
String query = "CREATE TABLE Employees("
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
String query = "INSERT INTO Employees("
+ "Name, Salary, Location) VALUES "
+ "('Amit', 30000, 'Hyderabad'), "
+ "('Kalyan', 40000, 'Vishakhapatnam'), "
+ "('Renuka', 50000, 'Delhi'), "
+ "('Archana', 15000, 'Mumbai'), "
+ "('Trupthi', 45000, 'Kochin'), "
+ "('Suchatra', 33000, 'Pune'), "
+ "('Rahul', 39000, 'Lucknow'), "
+ "('Trupti', 45000, 'Kochin')";
//Executing the query
String query = "SELECT Location, SUM(Salary) " + "from Employees GROUP BY Location";
ResultSet rs = stmt.executeQuery(query);
while(rs.next()) {
System.out.println("Salary: "+rs.getString(1));
System.out.println("Location: "+rs.getString(2));
System.out.println(" ");
}
}
}
输出
在执行上述程序时,您将获得以下输出 –
Salary: Chennai Location: 43000 Salary: Delhi Location: 50000 Salary: Hyderabad Location: 30000 Salary: Kochin Location: 45000 Salary: Lucknow Location: 39000 Salary: Mumbai Location: 15000 Salary: Pune Location: 33000
Apache Derby – 有条款
HAVING 子句使您能够指定条件来过滤哪些组结果出现在结果中。
WHERE 子句在选定的列上放置条件,而 HAVING 子句在由 GROUP BY 子句创建的组上放置条件。
句法
以下是 HAVING 子句的语法 –
ij> SELECT column1, column2 . . . from table_name GROUP BY column having condition;
例子
假设,我们在数据库中有一个名为 Employees 的表,其中有 13 条记录,如下所示 –
ID |NAME |SALARY |LOCATION ------------------------------------------------------------------ 1 |Amit |30000 |Hyderabad 2 |Rahul |39000 |Lucknow 3 |Kalyan |40000 |Vishakhapatnam 4 |Renuka |50000 |Hyderabad 5 |Archana |15000 |Vishakhapatnam 6 |Krishna |40000 |Hyderabad 7 |Trupthi |45000 |Vishakhapatnam 8 |Raghav |12000 |Lucknow 9 |Radha |50000 |Delhi 10 |Anirudh |15000 |Mumbai 11 |Tara |45000 |Kochin 12 |Sucharita|44000 |Kochin 13 |Rizwan |20000 |Lucknow
以下查询显示该位置至少有 3 名员工的员工的最高工资 –
ij> SELECT Location, MAX(Salary) from Employees GROUP BY Location having count(Location)>=3;
这会生成以下输出 –
LOCATION |2 ------------------------------------------------------------ Hyderabad |50000 Lucknow |39000 Vishakhapatnam |45000 3 rows selected
使用JDBC程序对数据进行排序
本节将教您如何使用 JDBC 应用程序在 Apache Derby 数据库中使用 Have a 子句。
如果要使用网络客户端请求 Derby 网络服务器,请确保服务器已启动并正在运行。网络客户端驱动程序的类名是 org.apache.derby.jdbc.ClientDriver,URL 是 jdbc:derby://localhost:1527/ DATABASE_NAME;创建=真;用户=用户名;密码=密码“
按照下面给出的步骤对 Apache Derby 中的表的记录进行排序
第一步:注册驱动
要与数据库进行通信,首先需要注册驱动程序。类Class的forName()方法接受一个表示类名的 String 值,并将其加载到内存中,内存会自动注册它。使用此方法注册驱动程序。
第 2 步:获取连接
通常,我们与数据库进行通信的第一步是与其连接。在连接类代表与数据库服务器的物理连接。您可以通过调用DriverManager类的getConnection()方法来创建连接对象。使用此方法创建连接。
第 3 步:创建语句对象
您需要创建Statement或PreparedStatement 或 CallableStatement对象以将 SQL 语句发送到数据库。您可以分别使用createStatement()、prepareStatement() 和 prepareCall()方法创建这些。使用适当的方法创建这些对象中的任何一个。
第 4 步:执行查询
创建语句后,您需要执行它。该声明类提供了各种方法来执行,如查询的execute()方法执行语句返回多个结果集。所述的executeUpdate()等INSERT,UPDATE方法执行查询,删除。所述的executeQuery()方法返回的数据。使用其中一种方法并执行先前创建的语句。
例子
以下 JDBC 示例演示了如何使用 Group By 子句并使用 JDBC 程序对 Apache Derby 中的表执行 CURD 操作。在这里,我们使用嵌入式驱动程序连接到名为 sampleDB 的数据库(如果它不存在将创建)。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.sql.ResultSet;
public class HavingClauseExample {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating a table and populating it
stmt.execute("CREATE TABLE EmployeesData( "
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), "
+ "Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))");
stmt.execute("INSERT INTO EmployeesData(Name, Salary, Location) "
+ "VALUES ('Amit', 30000, 'Hyderabad'), "
+ "('Rahul', 39000, 'Lucknow'), "
+ "('Renuka', 50000, 'Hyderabad'), "
+ "('Archana', 15000, 'Vishakhapatnam'), "
+ "('Kalyan', 40000, 'Hyderabad'), "
+ "('Trupthi', 45000, 'Vishakhapatnam'), "
+ "('Raghav', 12000, 'Lucknow'), "
+ "('Suchatra', 33000, 'Vishakhapatnam'), "
+ "('Rizwan', 20000, 'Lucknow')");
//Executing the query
String query = "SELECT Location, MAX(Salary) "
+ "from EmployeesData GROUP BY Location having "
+ "count(Location)>=3";
ResultSet rs = stmt.executeQuery(query);
while(rs.next()) {
System.out.println(rs.getString(1));
System.out.println(rs.getString(2));
System.out.println(" ");
}
}
}
输出
在执行上述程序时,您将获得以下输出 –
Hyderabad 50000 Lucknow 39000 Vishakhapatnam 45000
Apache Derby – 更改表语句
ALTER TABLE 语句允许您更改现有表。使用它,您可以执行以下操作 –
-
添加列,添加约束
-
删除列,删除约束
-
更改表的行级锁定
让我们假设我们已经创建了一个名为 Employees 的表,如下所示 –
ij> CREATE TABLE Employees ( Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, Name VARCHAR(255), Salary INT NOT NULL, Location VARCHAR(255), PRIMARY KEY (Id) );
并且,使用插入语句插入四条记录作为 –
ij> INSERT INTO Employees (Name, Salary, Location) VALUES
('Amit', 30000, 'Hyderabad'),
('Kalyan', 40000, 'Vishakhapatnam'),
('Renuka', 50000, 'Delhi'),
('Archana', 15000, 'Mumbai');
向表中添加列
以下是使用 ALTER 语句向表中添加列的语法。
ALTER TABLE table_name ADD COLUMN column_name column_type;
例子
使用 ALTER 语句,我们尝试添加一个名为 Age 且类型为 integer 的新列。
ALTER TABLE Employees ADD COLUMN Age INT; 0 rows inserted/updated/deleted
添加另一个名为 Phone_No 且类型为整数的列。
ALTER TABLE Employees ADD COLUMN Phone_No BIGINT; 0 rows inserted/updated/deleted
如果表存在,DESCRIBE 命令通过列出列及其详细信息来描述指定的表。如果您描述表员工,您可以观察新添加的列,如下所示 –
ij> DESCRIBE Employees; COLUMN_NAME |TYPE_NAME|DEC&|NUM&|COLUM&|COLUMN_DEF|CHAR_OCTE&|IS_NULL& ------------------------------------------------------------------------------ ID |INTEGER |0 |10 |10 |AUTOINCRE&|NULL |NO NAME |VARCHAR |NULL|NULL |255 |NULL | 510 |YES SALARY |INTEGER |0 |10 |10 |NULL |NULL |NO LOCATION |VARCHAR |NULL|NULL |255 |NULL | 510 |YES AGE |INTEGER |0 |10 |10 |NULL |NULL |YES PHONE_NO |INTEGER |0 |10 |10 |NULL |NULL |YES 6 rows selected
向表添加约束
以下是使用 ALTER 语句向表的列添加约束的语法。
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint (column_name);
其中约束可以是 NOT NULL、NULL、PRIMARY KEY、UNIQUE、FOREIGN KEY、CHECK。
例子
使用 ALTER 语句,我们尝试向Phone_No 列添加约束UNIQUE。
ij> ALTER TABLE Employees ADD CONSTRAINT New_Constraint UNIQUE(Phone_No); 0 rows inserted/updated/deleted
一次,您向一列添加 UNIQUE 约束,它不能有两行相同的值,即电话号码对于每个员工应该是唯一的。
如果您尝试添加具有相同电话号码的两列,则会出现如下所示的异常。
ij> INSERT INTO Employees (Name, Salary, Location, Age, Phone_No) VALUES
('Amit', 30000, 'Hyderabad', 30, 9848022338);
1 row inserted/updated/deleted
ij> INSERT INTO Employees (Name, Salary, Location, Age, Phone_No) VALUES
('Sumit', 35000, 'Chennai', 25, 9848022338);
ERROR 23505: The statement was aborted because it would have caused a duplicate
key value in a unique or primary key constraint or unique index identified by
'NEW_CONSTRAINT' defined on 'EMPLOYEES'.
从表中删除约束
以下是删除列约束的语法 –
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
例子
以下查询删除上面创建的列 Phone_No 上的约束名称 New_Constraint。
ij> ALTER TABLE Employees DROP CONSTRAINT New_Constraint; 0 rows inserted/updated/deleted
由于我们已经删除了 Phone_No 列上的 UNIQUE 约束,您可以添加具有相同电话号码的列。
ij> INSERT INTO Employees (Name, Salary, Location, Age, Phone_No) VALUES
('Sumit', 35000, 'Chennai', 25, 9848022338);
1 row inserted/updated/deleted
您可以验证表 ij> select * from Employees 的内容,如下所示 –
ID |NAME |SALARY |LOCATION |AGE |PHONE_NO ------------------------------------------------------------------------- 1 |Amit |30000 |Hyderabad|30 |9848022338 2 |Sumit|35000 |Chennai |25 |9848022338 2 rows selected
从表中删除一列
以下是删除一列中的一列的语法。
ALTER TABLE table_name DROP COLUMN column_name;
例子
以下查询删除名为员工年龄的列–
ij> ALTER TABLE Employees DROP COLUMN Age; 0 rows inserted/updated/deleted
如果你描述表,你只能看到 4 列。
ij> DESCRIBE Employees; COLUMN_NAME |TYPE_NAME|DEC&|NUM&|COLUM&|COLUMN_DEF|CHAR_OCTE&|IS_NULL& ------------------------------------------------------------------------------ ID |INTEGER |0 |10 |10 |AUTOINCRE&|NULL |NO NAME |VARCHAR |NULL|NULL|255 |NULL |510 |YES SALARY |INTEGER |0 |10 |10 |NULL |NULL |NO LOCATION |VARCHAR |NULL|NULL|255 |NULL |510 |YES PHONE_NO |BIGINT |0 |10 |19 |NULL |NULL |YES
使用JDBC程序更改表
以下是使用 ALTER 查询更改表的 JDBC 程序 –
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class AlterTableExample {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Executing the query
String createQuery = "CREATE TABLE Employees( "
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), "
+ "Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
stmt.execute(createQuery);
System.out.println("Table created");
System.out.println(" ");
//Executing the query
String insertQuery = "INSERT INTO Employees("
+ "Name, Salary, Location) VALUES "
+ "('Amit', 30000, 'Hyderabad'), "
+ "('Kalyan', 40000, 'Vishakhapatnam'), "
+ "('Renuka', 50000, 'Delhi'), "
+ "('Archana', 15000, 'Mumbai'), "
+ "('Trupti', 45000, 'Kochin')";
stmt.execute(insertQuery);
System.out.println("Values inserted");
System.out.println(" ");
//Executing the query
String selectQuery = "SELECT * FROM Employees";
ResultSet rs = stmt.executeQuery(selectQuery);
System.out.println("Contents of the table after inserting the table");
while(rs.next()) {
System.out.println("Id: "+rs.getString("Id"));
System.out.println("Name: "+rs.getString("Name"));
System.out.println("Salary: "+rs.getString("Salary"));
System.out.println("Location: "+rs.getString("Location"));
}
System.out.println(" ");
//Altering the table
stmt.execute("ALTER TABLE Employees ADD COLUMN Age INT");
stmt.execute("ALTER TABLE Employees ADD COLUMN Phone_No BigINT");
stmt.execute("ALTER TABLE Employees " + "ADD CONSTRAINT New_Constraint UNIQUE(Phone_No)");
stmt.execute("INSERT INTO Employees "
+ "(Name, Salary, Location, Age, Phone_No) "
+ "VALUES ('Amit', 30000, 'Hyderabad', 30, 9848022338)");
ResultSet alterResult = stmt.executeQuery("Select * from Employees");
System.out.println("Contents of the table after altering "
+ "the table and inserting values to it: ");
while(alterResult.next()) {
System.out.println("Id: "+alterResult.getString("Id"));
System.out.println("Name: "+alterResult.getString("Name"));
System.out.println("Salary: "+alterResult.getString("Salary"));
System.out.println("Location: "+alterResult.getString("Location"));
System.out.println("Age: "+alterResult.getString("Age"));
System.out.println("Phone_No: "+alterResult.getString("Phone_No"));
}
}
}
输出
在执行上述程序时,将生成以下输出 –
Table created Values inserted Contents of the table after inserting the table Id: 1 Name: Amit Salary: 30000 Location: Hyderabad Id: 2 Name: Kalyan Salary: 40000 Location: Vishakhapatnam Id: 3 Name: Renuka Salary: 50000 Location: Delhi Id: 4 Name: Archana Salary: 15000 Location: Mumbai Id: 5 Name: Trupti Salary: 45000 Location: Kochin Contents of the table after altering the table and inserting values to it: Id: 1 Name: Amit Salary: 30000 Location: Hyderabad Age: null Phone_No: null Id: 2 Name: Kalyan Salary: 40000 Location: Vishakhapatnam Age: null Phone_No: null Id: 3 Name: Renuka Salary: 50000 Location: Delhi Age: null Phone_No: null Id: 4 Name: Archana Salary: 15000 Location: Mumbai Age: null Phone_No: null Id: 5 Name: Trupti Salary: 45000 Location: Kochin Age: null Phone_No: null Id: 6 Name: Amit Salary: 30000 Location: Hyderabad Age: 30 Phone_No: 9848022338
Apache Derby – 德比索引
表中的索引只不过是指向其数据的指针。这些用于加速从表中检索数据。
如果我们使用索引,INSERT 和 UPDATE 语句会在较慢的阶段执行。而 SELECT 和 WHERE 在更短的时间内执行。
创建索引
CREATE INDEX 语句用于在 Derby 数据库的表中创建新索引。
句法
以下是 CREATE INDEX 语句的语法 –
CTREATE INDEX index_name on table_name (column_name);
例子
假设我们在 Apache Derby 中创建了一个名为 Employees 的表,如下所示。
CREATE TABLE Emp ( Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, Name VARCHAR(255), Salary INT NOT NULL, Location VARCHAR(255), Phone_Number BIGINT );
下面的 SQL 语句在雇员表中名为 Salary 的列上创建一个索引。
ij> CREATE INDEX example_index on Emp (Salary); 0 rows inserted/updated/deleted
创建 UNIQUE 索引
在 Apache Derby 中,UNIQUE 索引用于数据集成。在表中的列上创建 UNIQUE 索引后,它不允许重复值。
句法
以下是创建唯一索引的语法。
CREATE UNIQUE INDEX index_name on table_name (column_name);
例子
下面的示例在表 Employee 的列 Id 上创建一个 UNIQUE 索引。
ij> CREATE UNIQUE INDEX unique_index on Emp (Phone_Number); 0 rows inserted/updated/deleted
一旦在列上创建了唯一索引,就不能在另一行中为该列输入相同的值。简而言之,具有 UNIQE 索引的列将不允许重复值。
在 Emp 表中插入一行,如下所示
ij> INSERT INTO Emp(Name, Salary, Location, Phone_Number) VALUES ('Amit',
45000, 'Hyderabad', 9848022338);
1 row inserted/updated/deleted
由于我们在 Phone_No 列上创建了唯一索引,如果您输入与前一条记录相同的值,则会显示错误。
ij> INSERT INTO Emp(Name, Salary, Location, Phone_Number) VALUES ('Sumit',
35000, 'Chennai', 9848022338);
ERROR 23505: The statement was aborted because it would have caused a duplicate
key value in a unique or primary key constraint or unique index identified by
'UNIQUE_INDEX' defined on 'EMP'.
创建复合索引
您可以在两行上创建单个索引,它称为复合索引。
句法
以下是复合索引的语法。
CREATE INDEX index_name on table_name (column_name1, column_name2);
例子
以下索引在列名称和位置上创建一个复合索引。
ij> CREATE INDEX composite_index on Emp (Name, Location); 0 rows inserted/updated/deleted
显示索引
SHOW INDEXES 查询显示表上的索引列表。
句法
以下是 SHOW INDEXES 语句的语法 –
SHOW INDEXES FROM table_name;
例子
下面的例子,我显示了雇员表上的索引。
ij> SHOW INDEXES FROM Emp;
这会产生以下结果。
ij> SHOW INDEXES FROM Emp; TABLE_NAME |COLUMN_NAME |NON_U&|TYPE|ASC&|CARDINA&|PAGES ---------------------------------------------------------------------------- EMP |PHONE_NUMBER|false |3 |A |NULL |NULL EMP |NAME |true |3 |A |NULL |NULL EMP |LOCATION |true |3 |A |NULL |NULL EMP |SALARY |true |3 |A |NULL |NULL 4 rows selected
删除索引
Drop Index 语句删除/删除列上的给定索引。
句法
以下是 DROP INDEX 语句的语法。
DROP INDEX index_name;
例子
以下示例删除上面创建的名为composite_index 和unique_index 的索引。
ij> DROP INDEX composite_index; 0 rows inserted/updated/deleted ij>Drop INDEX unique_index; 0 rows inserted/updated/deleted
现在,如果您验证索引列表,您可以看到一列上的索引,因为我们已经删除了其余的列。
ij> SHOW INDEXES FROM Emp; TABLE_NAME |COLUMN_NAME |NON_U&|TYPE|ASC&|CARDINA&|PAGES ---------------------------------------------------------------------------- EMP |SALARY |true |3 |A |NULL |NULL 1 row selected
使用 JDBC 程序处理索引
以下 JDBC 程序演示了如何在表中的列上创建删除索引。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class IndexesExample {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:MYDATABASE;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating the Emp table
String createQuery = "CREATE TABLE Emp( "
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), "
+ "Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "Phone_Number BIGINT )";
stmt.execute(createQuery);
System.out.println("Table created");
System.out.println(" ");
//Creating an Index on the column Salary
stmt.execute("CREATE INDEX example_index on Emp (Salary)");
System.out.println("Index example_index inserted");
System.out.println(" ");
//Creating an Unique index on the column Phone_Number
stmt.execute("CREATE UNIQUE INDEX unique_index on Emp (Phone_Number)");
System.out.println("Index unique_index inserted");
System.out.println(" ");
//Creating a Composite Index on the columns Name and Location
stmt.execute("CREATE INDEX composite_index on Emp (Name, Location)");
System.out.println("Index composite_index inserted");
System.out.println(" ");
//listing all the indexes
System.out.println("Listing all the columns with indexes");
//Dropping indexes
System.out.println("Dropping indexes unique_index and, composite_index ");
stmt.execute("Drop INDEX unique_index");
stmt.execute("DROP INDEX composite_index");
}
}
输出
在执行时,这会生成以下结果
Table created Index example_index inserted Index unique_index inserted Index composite_index inserted Listing all the columns with indexes Dropping indexes unique_index and, composite_index
Apache Derby – 过程
本章教您如何在 Derby 中创建和删除过程。
创建过程
您可以使用 CREATE PROCEDURE 语句创建过程。
句法
以下是 CREATE PROCEDURE 语句的语法。
CREATE PROCEDURE procedure_name (parameter_type parameter_name1, parameter_type parameter_name2 . . . .) parameter_style;
例子
假设,我们在 Derby 中创建了一个表,如下所示。
CREATE TABLE Emp ( Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, Name VARCHAR(255), Salary INT NOT NULL, Location VARCHAR(255), Phone_Number BIGINT );
并在其中插入值如下 –
INSERT INTO Employees(Name, Salary, Location) VALUES
('Amit', 30000, 'Hyderabad'),
('Kalyan', 40000, 'Vishakhapatnam'),
('Renuka', 50000, 'Delhi'),
('Archana', 15000, 'Mumbai'),
('Trupthi', 45000, 'Kochin')";
以下示例创建一个名为 Update_Procedure 的过程,它接受 JAVA 参数。
ij> CREATE PROCEDURE Update_Procedure(IN id INTEGER, IN name VARCHAR(10)) PARAMETER STYLE JAVA READS SQL DATA LANGUAGE JAVA EXTERNAL NAME 'ProcedureExample.testProc'; > 0 rows inserted/updated/deleted
ProcedureExample 类看起来像 –
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class ProcedureExample {
public static void testProc(int salary, String name) throws Exception {
String connectionURL = "jdbc:derby:MYDATABASE;create=true";
Connection conn = DriverManager.getConnection(connectionURL);
String query = "UPDATE Employees SET SALARY = ? WHERE NAME = ?";
PreparedStatement pstmt = conn.prepareStatement(query);
pstmt.setInt(1, salary);
pstmt.setString (2, name);
pstmt.executeUpdate();
}
}
您可以使用SHOW PROCEDURES查询来验证过程列表。
ij> SHOW PROCEDURES; PROCEDURE_SCHEM |PROCEDURE_NAME |REMARKS ------------------------------------------------------------------------ APP |UPDATE_PROCEDURE |ProcedureExample.te& SALES |EXAMPLE_ PROCEDURE |com.example.sales.c& SQLJ |INSTALL_JAR |org.apache.derby.ca& SQLJ |REMOVE_JAR |org.apache.derby.ca& SQLJ |REPLACE_JAR |org.apache.derby.ca& SYSCS_UTIL |SYSCS_BACKUP_DATABASE |org.apache.derby.ca& . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
在这里您可以观察新创建的程序。
删除程序
您可以使用 DROP PROCEDURE 语句删除过程。
句法
以下是 DROP PROCEDURE 语句的语法。
DROP PROCEDURE procedure_name;
例子
以下示例删除了上面创建的名为 Update_Procedure 的过程。
ij> DROP PROCEDURE Update_Procedure; > 0 rows inserted/updated/deleted
Apache Derby – 模式
数据库模式是表示整个数据库逻辑视图的骨架结构。它定义了数据的组织方式以及它们之间的关系如何关联。它制定了要应用于数据的所有约束。
创建架构
您可以使用 CREATE SCHEMA 语句在 Apache Derby 中创建模式。
句法
以下是 CREATE SCHEMA 语句的语法。
CREATE SCHEMA schema_name AUTHORIZATION id
例子
以下示例在 Derby 数据库中创建名为 my_schema 的模式。
ij> CREATE SCHEMA AUTHORIZATION my_schema; 0 rows inserted/updated/deleted
然后,您可以在此架构中创建一个表,如下所示。
ij> CREATE TABLE my_schema.Emp ( Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, Name VARCHAR(255), Salary INT NOT NULL, Location VARCHAR(255), Phone_Number BIGINT ); > > > > > 0 rows inserted/updated/deleted
您可以使用 SHOW SCHEMAS 查询来验证架构列表,您可以在此处找到创建的架构列表。
ij> show schemas; TABLE_SCHEM ------------------------------ APP MY_SCHEMA NULLID SQLJ SYS SYSCAT SYSCS_DIAG SYSCS_UTIL SYSFUN SYSIBM SYSPROC SYSSTAT 12 rows selected
删除架构
您可以使用 DROP SCHEMA 语句删除现有模式。
句法
以下是 DROPS SCHEMA 语句的语法。
DROP SCHEMA my_schema RESTRICT;
例子
仅当架构中没有任何对象时,您才能删除架构。要删除架构,请删除其中的所有表并删除架构。
ij> DROP TABLE my_schema.Emp; 0 rows inserted/updated/deleted
以下示例删除上面创建的架构。
ij> DROP SCHEMA my_schema RESTRICT; 0 rows inserted/updated/deleted
JDBC 示例
以下 JDBC 示例创建和删除名为 my_schema 的模式。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class CreateSchemaExample {
public static void main(String args[]) throws Exception {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:sampleDB;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
stmt.execute("CREATE SCHEMA AUTHORIZATION my_schema");
//Executing the query
String query = "CREATE TABLE my_schema.Employees( "
+ "Id INT NOT NULL GENERATED ALWAYS AS IDENTITY, "
+ "Name VARCHAR(255), "
+ "Salary INT NOT NULL, "
+ "Location VARCHAR(255), "
+ "PRIMARY KEY (Id))";
stmt.execute(query);
System.out.println("Table created in schema");
stmt.execute("DROP TABLE my_schema.Employees");
stmt.execute("DROP SCHEMA my_schema RESTRICT");
System.out.println("Schema dropped");
}
}
输出
执行时,上述程序生成以下示例。
Table created in schema Schema dropped
Apache Derby – 触发器
在数据库中,触发器是在事件发生时执行的语句/代码。一旦为表上的特定事件创建触发器,每次发生事件时都会执行触发器中指定的代码。您可以在单个表上创建多个触发器。
本章教您如何使用 Apache Derby 创建和删除触发器。
创建触发器
您可以使用 CREATE TRIGGER 语句在 Derby 中创建触发器。
句法
以下是 CREATE TRIGGER 查询的语法。
CREATE TRIGGER trigger_name
{ NO CASCADE BEFORE | AFTER }
{INSERT [OR] | UPDATE [OR] | DELETE}[OF col_name]
ON table_name
[REFERENCING OLD AS o NEW AS n]
[FOR EACH ROW]
Statement
例子
假设,我们在 Derby 中创建了一个名为 Emp 的表,如下所示。
CREATE TABLE Emp ( Id INT NOT NULL, Name VARCHAR(255), Salary INT NOT NULL, Location VARCHAR(255) );
并在其中插入 5 行。
INSERT INTO Emp(Id, Name, Salary, Location) VALUES (1, 'Amit', 30000, 'Hyderabad'), (2, 'Kalyan', 40000, 'Vishakhapatnam'), (3,'Renuka', 50000, 'Delhi'), (4, 'Archana', 15000, 'Mumbai'), (5, 'Trupthi', 45000, 'Kochin');
如果我们有另一个名为 BackUp 的表,并且我们的目的是将 Emp 表中删除的行存储在这个表中。
CREATE TABLE BackUp ( Id INT NOT NULL, Name VARCHAR(255), Salary INT NOT NULL, Location VARCHAR(255) );
以下查询在名为Emp的 DELETE 查询表上创建触发器。它将删除的Emp行存储到表 Backup。
ij> CREATE TRIGGER my_trigger AFTER DELETE ON Emp REFERENCING OLD AS oldRow FOR EACH ROW MODE DB2SQL INSERT INTO BackUp VALUES (oldRow.Id, oldRow.Name, oldRow.Salary, oldRow.Location);
现在,从 Emp 表中删除一行作为 –
ij> Delete From Emp where Name = 'Kalyan'; 1 row inserted/updated/deleted ij> Delete From Emp where Name = 'Amit'; 1 row inserted/updated/deleted
如果您验证备份表,您可以观察其中已删除的行。
ij> select * from BackUp; ID |NAME |SALARY |LOCATION ------------------------------------------------------------------------- 2 |Kalyan |40000 |Vishakhapatnam 1 |Amit |30000 |Hyderabad 2 rows selected
删除触发器
您可以使用 DROP TRIGGER 语句在 Derby 中删除触发器。
句法
以下是 DROP TRIGGER 查询的语法 –
ij> Drop trigger tigger_name;
例子
以下示例删除上面创建的触发器 my_trigger –
ij> Drop trigger my_trigger; 0 rows inserted/updated/deleted
JDBC 示例
以下 JDBC 程序在 Derby 中创建和删除触发器。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class Triggers_Example {
public static void main(String args[]) throws SQLException, ClassNotFoundException {
//Registering the driver
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
//Getting the Connection object
String URL = "jdbc:derby:TestDataBase;create=true";
Connection conn = DriverManager.getConnection(URL);
//Creating the Statement object
Statement stmt = conn.createStatement();
//Creating the Emp table
stmt.execute("CREATE TABLE Emp ( "
+ "Id INT NOT NULL, "
+ "Name VARCHAR(255), "
+ "Salary INT NOT NULL, "
+ "Location VARCHAR(255))");
//Insert values in to the EMp table
String query = "INSERT INTO Emp(Id, Name, Salary, Location) VALUES \r\n"
+"(1, 'Amit', 30000, 'Hyderabad'), "
+ "(2, 'Kalyan', 40000, 'Vishakhapatnam'), "
+ "(3,'Renuka', 50000, 'Delhi'), "
+ "(4, 'Archana', 15000, 'Mumbai'), "
+ "(5, 'Trupthi', 45000, 'Kochin')";
stmt.execute(query);
//Creating the BackUp table
stmt.execute("CREATE TABLE BackUp ( "
+ "Id INT NOT NULL, "
+ "Name VARCHAR(255), "
+ "Salary INT NOT NULL, "
+ "Location VARCHAR(255))");
//Creating a trigger
String createTrigger = "CREATE TRIGGER my_trigger "
+ "AFTER DELETE ON Emp "
+ "REFERENCING OLD AS oldRow "
+ "FOR EACH ROW MODE DB2SQL "
+ "INSERT INTO BackUp "
+ "VALUES (oldRow.Id, oldRow.Name, oldRow.Salary, oldRow.Location)";
stmt.execute(createTrigger);
System.out.println("Trigger created");
//Deleting records from Emp table
stmt.executeUpdate("Delete From Emp where Name = 'Kalyan'");
stmt.executeUpdate("Delete From Emp where Name = 'Amit'");
//Getting the contents of BackUp table
ResultSet rs = stmt.executeQuery("SELECT * from BackUp");
while(rs.next()){
System.out.println(rs.getInt("Id"));
System.out.println(rs.getString("Name"));
System.out.println(rs.getString("Salary"));
System.out.println(rs.getString("Location"));
System.out.println(" ");
}
}
}
输出
在执行上述程序时,会生成以下输出 –
Trigger created 2 Kalyan 40000 Vishakhapatnam 1 Amit 30000 Hyderabad
