笔记列表:
ArangoDB-AQL示例查询
In this chapter, we will consider a few AQL Example Queries on an 演员和电影 Database. These queries are based on graphs.
问题
给定一组演员和一组电影,以及一个actIn edges集合(具有year属性)来连接顶点,如下所示−
[演员]<-演出->[电影]
我们怎么才能得到−
- 所有在“电影1”或“电影2”中演出的演员?
- 所有同时在“电影1”和“电影2”中演出的演员?
- 所有在“actor1”和“actor2”之间的普通电影?
- 所有在3部或3部以上电影中演出的演员?
- 所有有6个演员出演的电影?
- 电影演员的数量?
- 按演员分类的电影数量?
- 2005年到2010年间演员出演的电影有多少?
解决方案
在解决和获取上述查询的答案的过程中,我们将使用Arangosh创建数据集并对其运行查询。所有的AQL查询都是字符串,可以简单地复制到您最喜欢的驱动程序而不是Arangosh。
Let us start by creating a Test Dataset in Arangosh. First, download 此文件 −
# wget -O dataset.js https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharing
输出
... HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘dataset.js’ dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s 2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]
You can see in the output above that we have downloaded a JavaScript file 数据集.js。 This file contains the Arangosh commands to create the dataset in the database. Instead of copying and pasting the commands one by one, we will use the –javascript.execute文件 option on Arangosh to execute the multiple commands non-interactively. Consider it the life saver command!
现在在shell上执行以下命令−
$ arangosh --javascript.execute dataset.js
在提示时提供密码,如上面的屏幕截图所示。现在我们已经保存了数据,所以我们将构造AQL查询来回答本章开头提出的具体问题。
第一个问题
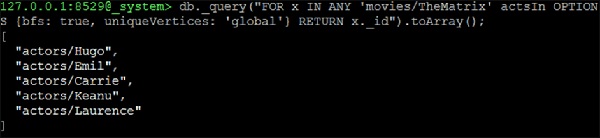
Let us take the first question: 所有在“电影1”或“电影2”中演出的演员. Suppose, we want to find the names of all the actors who acted in “TheMatrix” OR “TheDevilsAdvocate” −
我们将一次从一部电影开始,以获得演员的名字−
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();
输出
我们将收到以下输出−
[ "actors/Hugo", "actors/Emil", "actors/Carrie", "actors/Keanu", "actors/Laurence" ]
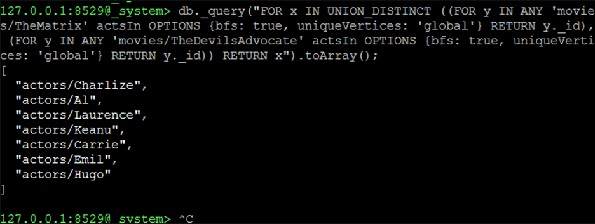
现在我们继续形成一个由两个相邻查询组成的联合,这将是解决方案−
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
输出
[ "actors/Charlize", "actors/Al", "actors/Laurence", "actors/Keanu", "actors/Carrie", "actors/Emil", "actors/Hugo" ]
第二个问题
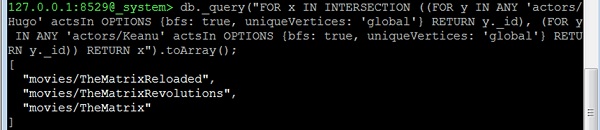
Let us now consider the second question: 所有在“电影1”和“电影2”中演出的演员. This is almost identical to the question above. But this time we are not interested in a UNION but in an INTERSECTION −
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();
输出
我们将收到以下输出−
[ "actors/Keanu" ]

第三个问题
Let us now consider the third question: “actor1”和“actor2”之间的所有普通电影. This is actually identical to the question about common actors in movie1 and movie2. We just have to change the starting vertices. As an example, let us find all the movies where Hugo Weaving (“Hugo”) and Keanu Reeves are co-starring −
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();
输出
我们将收到以下输出−
[ "movies/TheMatrixReloaded", "movies/TheMatrixRevolutions", "movies/TheMatrix" ]
第四个问题
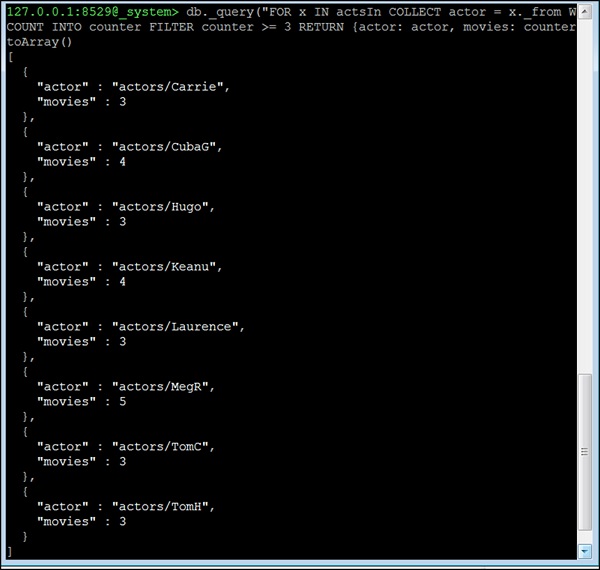
Let us now consider the fourth question. 所有在3部或3部以上电影中演出的演员. This question is different; we cannot make use of the neighbors function here. Instead we will make use of the edge-index and the COLLECT statement of AQL for grouping. The basic idea is to group all edges by their StartVertex公司 (which in this dataset is always the actor). Then we remove all actors with less than 3 movies from the result as here we have included the number of movies an actor has acted in −
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()
输出
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
对于剩下的问题,我们将讨论查询的形成,并且只提供查询。读者应该自己在Arangosh终端上运行查询。
第五个问题
Let us now consider the fifth question: 所有有6个演员出演的电影. The same idea as in the query before, but with the equality filter. However, now we need the movie instead of the actor, so we return the _属性 −
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()
电影演员的数量?
We remember in our dataset _至 on the edge corresponds to the movie, so we count how
often the same _至 appears. This is the number of actors. The query is almost identical to
the ones before but 收集后无过滤器 −
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()
第六个问题
Let us now consider the sixth question: 一个演员的电影数量.
我们为上述查询找到解决方案的方法也将帮助您找到此查询的解决方案。
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()
