提高交付管道每个阶段的透明度 – Devops监控
借助DevOps,我们期望在提高质量和削减成本的同时,加快开发速度,定期进行测试并更频繁地发布产品。为了帮助实现这一目标,DevOps监视工具可在规划,开发,集成和测试,部署以及运营的整个开发生命周期中提供自动化以及扩展的度量和可见性。
现代软件开发生命周期比以往任何时候都快,同时发生了多个开发和测试阶段。这催生了DevOps,从执行开发,测试和操作功能的孤立团队转变为执行所有功能并拥护“构建,运行”的统一团队(YBIYRI)。
由于现在经常更改代码,开发团队需要DevOps监控,以提供对生产环境的全面实时视图。
什么是DevOps监控?
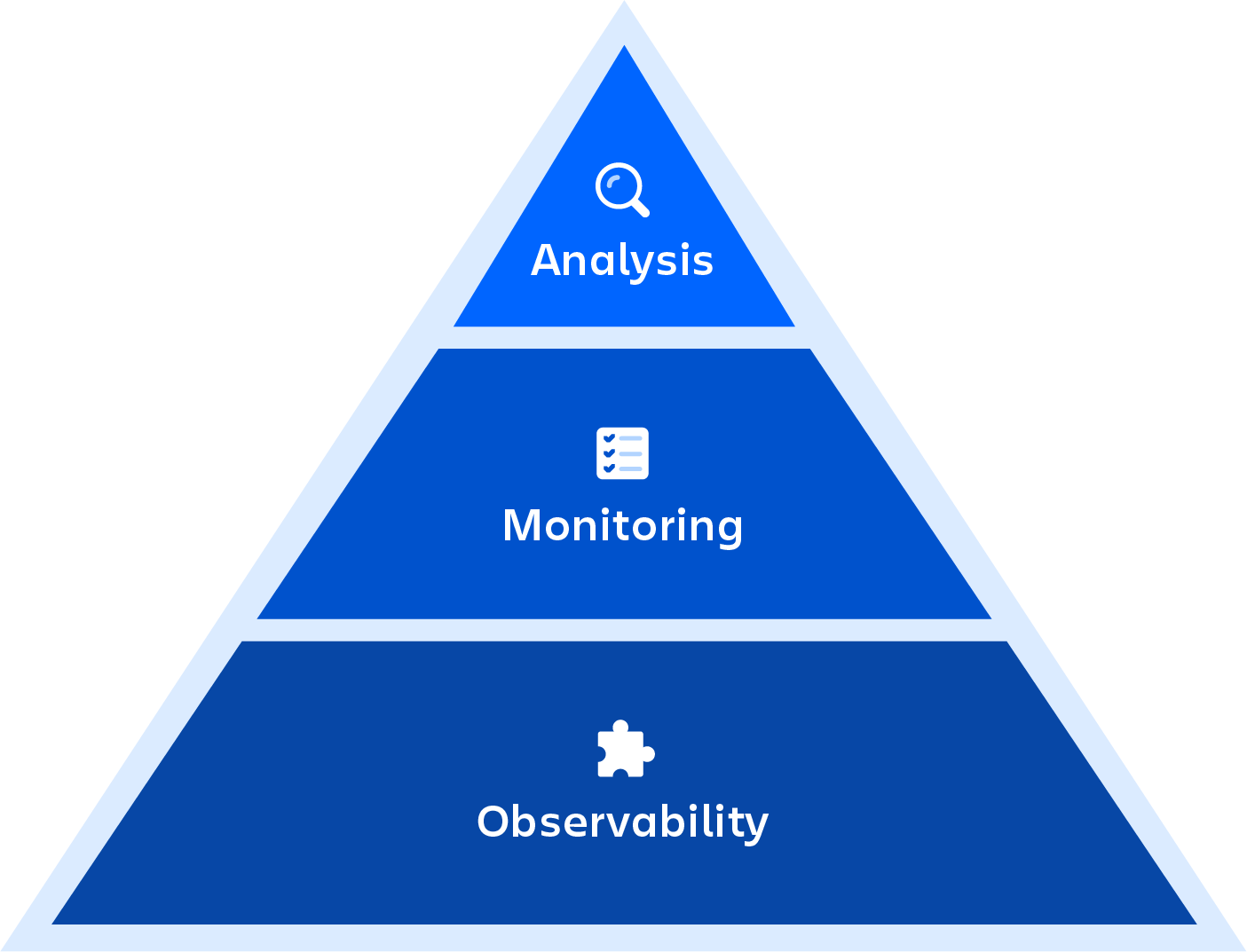
DevOps监视需要从计划,开发,集成和测试,部署以及运营来监督整个开发过程。它涉及生产环境中应用程序,服务和基础结构状态的完整实时视图。实时流,历史重播和可视化等功能是应用程序和服务监视的关键组件。
DevOps监控使团队可以快速,自动地响应客户体验的任何下降。更重要的是,它使团队可以“左移”到开发的早期阶段,并最大程度地减少生产变更。一个例子是更好的软件检测和错误检测工具,可以通过呼叫手动进行,也可以在可能时自动进行。
DevOps监控与可观察性
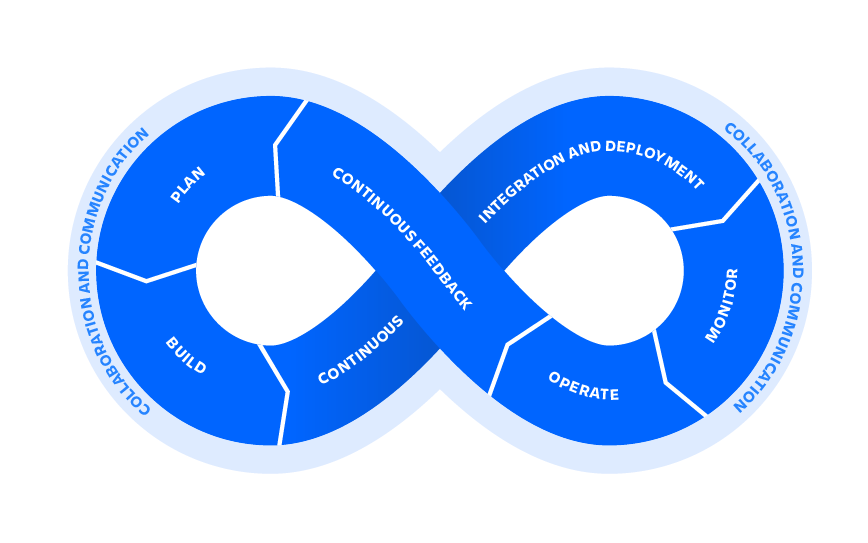
当您将无限循环的左侧视为产品侧而将右侧视为操作侧时,将新功能推入生产环境的产品经理会感兴趣地了解项目如何分解为任务和用户故事。项目左侧的开发人员需要查看如何将功能移入生产环境,包括项目票证,用户案例和依赖项。如果开发人员遵循“构建,运行”的DevOps原则,那么他们也对事件补救感兴趣。
转移到生命周期的运营方面,站点可靠性工程师需要了解可以测量和监视的服务,因此,如果出现问题,可以对其进行修复。如果您没有将所有这些流程联系在一起的DevOps工具链,那么您将拥有一个混乱,不相关,混乱的环境。如果您拥有完善的工具链,则可以更好地了解正在发生的事情。
DevOps监控的重要性
DevOps方法将连续监视扩展到阶段,测试甚至开发环境中。有许多原因。
频繁的代码更改需要可见性
由持续集成和部署驱动的频繁代码更改加快了更改速度,并使生产环境变得越来越复杂。随着微服务和微前端进入现代云原生环境,生产中正在运行成百上千种有时甚至数千种不同的工作负载,每种工作负载都具有不同的规模,延迟,冗余和安全性操作要求。
这推动了对更大可见度的需求。团队不仅需要检测并响应降级的客户体验,还需要以时间紧迫的方式进行响应。
自动化协作
DevOps隐式要求在团队中释放开发,运营和业务功能之间的更大协作。然而,由于工具之间缺乏集成,合作可能会受阻,这导致了与不同团队进行协调的挑战。
您可以通过诸如在编辑器中完整了解开发管道的做法来自动化协作。此外,设置自动化规则以侦听提交或请求,然后更新相关的Jira问题的状态并将消息发送到团队的Slack频道。此外,注意观察扫描,测试和分析报告。
实验性
在个性化和优化的转换渠道的推动下,需要优化产品来满足客户需求,这导致了不断的实验。生产环境可以运行数百个实验和功能标记,这使得监视系统很难传达降低体验的原因。
对始终在线的服务和应用程序的要求不断提高,以及严格的SLA承诺,可能会增加应用程序的漏洞。开发团队需要确保他们定义了要监视并采取行动的服务级别目标(SLO)和服务级别指标(SLI)。
更换管理层
由于大多数生产中断都是由变更引起的,因此变更管理至关重要,尤其是对于关键任务应用程序(例如金融和医疗保健行业的应用程序)。需要确定与变更相关的风险,并且需要根据变更的风险自动执行批准流程。
处理这些复杂性需要全面的理解和监控策略。这需要定义和采用监视实践,并具有一组对开发过程至关重要的丰富,灵活和高级的监视工具。
相关系统监控
分布式系统已经变得越来越普遍,通常由许多较小的跨公司服务组成。团队现在不仅需要监视他们构建的系统,还需要监视和管理从属系统的性能和可用性。亚马逊网络服务(AWS)提供175多种产品和服务,包括计算,存储,网络,数据库,分析,部署,管理,移动和开发人员工具。如果您在AWS上构建应用程序,则需要确保选择适合您应用程序需求的服务。您还需要仪器和策略来以分布式方式跟踪错误并处理从属系统的故障。
DevOps监控的关键功能
与DevOps的传统保持一致,制定和实施监视策略还需要注意核心实践和一组工具。
左移测试
在生命周期的早期执行左移测试有助于提高质量,缩短测试周期并减少错误。对于DevOps团队而言,扩展左移测试实践以监视预生产环境的运行状况非常重要。这样可确保尽早且经常进行监视,以保持整个生产过程的连续性,并保留监视警报的质量。测试和监视应该协同工作,早期监视有助于通过关键的用户旅程和交易来评估应用程序的行为。这也有助于在生产部署之前确定性能和可用性偏差。
警报和事件管理
在云原生世界中,事件和代码中的错误一样,都是生活中的事实。这些事件包括硬件和网络故障,配置错误,资源耗尽,数据不一致以及软件错误。DevOps团队应该接受事件,并配备高质量的监视器以对事件做出响应。
可以帮助解决此问题的一些最佳做法是:
- 建立协作文化,在开发过程中使用监视以及功能/功能和自动化测试
- 在开发过程中,在代码中构建适当的高质量警报,以最大程度地减少平均检测时间(MTTD)和平均隔离时间(MTTI)
- 构建监视器以确保相关服务按预期运行
- 分配时间来构建必需的仪表板并培训团队成员使用它们
- 计划服务的“战争游戏”,以确保监视器按预期运行并捕获丢失的监视器
- 在冲刺期间,计划从先前的事件审查中关闭操作,尤其是与构建缺少的监视器和自动化相关的操作
- 构建安全性检测器(升级/补丁/滚动凭证)
- 通过自动确定对检测到的警报的响应,培养“测量并监视一切”的心态
DevOps监控工具
与DevOps / YBIYRI文化保持一致的高级工具是对一系列健康监测实践的补充。除了众所周知的代码存储库,IDE,调试器,缺陷跟踪,持续集成工具和部署工具的开发人员工具之外,这还需要注意识别和实施监视工具。
监控面板可以提供各种应用程序,服务和基础结构依赖性的全面视图,不仅在生产过程中,而且在登台过程中。这样就可以配置,摄取,标记,查看和分析复杂分布式环境的运行状况。
应用程序性能监视对于确保监视特定于应用程序的性能指标(例如加载页面的时间,下游服务的延迟或过渡)以及基本系统指标(例如CPU和内存利用率)而言至关重要。SignalFX和NewRelic等工具非常适合实时观察指标数据。
在开发过程中实施不同类型的监视器,包括错误,事务,综合,心跳,警报,基础结构,容量和安全性。确保每个成员都在这些方面接受过培训。这些监视器通常是特定于应用程序的,需要根据每个应用程序的要求来实现。例如,我们的Opsgenie开发团队实施了综合监视器,这些监视器创建警报或事件,并检查警报流是否按预期执行(即,集成,路由和策略是否正常运行)。我们还为基础结构依赖项实现了综合监视器,这些监视器定期验证各种AWS服务的功能。
一种警报和事件管理系统,可与您的团队的工具(日志管理,崩溃报告等)无缝集成,因此很自然地适合您的团队的发展和运营节奏。该工具应以最低的延迟将重要的警报发送到您首选的通知渠道。它还应具有对警报进行分组以过滤大量警报的功能,尤其是当由于单个错误或故障而生成多个警报时。在Atlassian,我们不仅提供Opsgenie产品作为向客户提供这些功能的产品,而且还在内部使用它来确保我们拥有与我们的开发实践相集成的强大,灵活,可靠的警报和事件管理系统。
结论…
在采用DevOps的同时,重要的是要确保除了测试外还需要监视变更,并采用了实践和工具来实现将变更快速交付高质量的承诺。
